Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Configuration et personnalisation de la génération de requêtes et de réponses
Vous pouvez configurer et personnaliser l’extraction et la génération de réponses, afin d’améliorer encore la pertinence des réponses. Par exemple, vous pouvez appliquer des filtres aux métadonnées des documents fields/attributes afin d'utiliser les derniers documents mis à jour ou ceux dont la date de modification est récente.
Note
Toutes les configurations suivantes, à l’exception de Orchestration et génération, ne s’appliquent qu’aux sources de données non structurées.
Pour plus d’informations sur ces configurations dans la console ou l’API, sélectionnez l’une des rubriques suivantes :
Lorsque vous interrogez une base de connaissances, Amazon Bedrock renvoie par défaut jusqu’à cinq résultats dans la réponse. Chaque résultat correspond à un segment source.
Note
Le nombre réel de résultats dans la réponse peut être inférieur à la valeur numberOfResults spécifiée, car ce paramètre définit le nombre maximum de résultats à renvoyer. Si vous avez configuré le découpage hiérarchique pour votre stratégie de segmentation, le paramètre numberOfResults correspond au nombre de segments enfants que la base de connaissances extraira. Étant donné que les segments enfants qui partagent le même segment parent sont remplacés par le segment parent dans la réponse finale, le nombre de résultats renvoyés peut être inférieur au montant demandé.
Pour modifier le nombre maximum de résultats à renvoyer, choisissez l’onglet correspondant à votre méthode préférée, puis suivez les étapes :
Le type de recherche définit la manière dont les sources de données de la base de connaissances sont interrogées. Les types de recherche possibles sont les suivants :
Note
La recherche hybride n'est prise en charge que pour les magasins vectoriels Amazon RDS, Amazon OpenSearch Serverless et MongoDB contenant un champ de texte filtrable. Si vous utilisez un autre magasin de vecteurs ou si votre magasin de vecteurs ne contient pas de champ de texte filtrable, la requête utilise la recherche sémantique.
-
Par défaut : Amazon Bedrock décide de la stratégie de recherche à votre place.
-
Hybride : Combine la recherche de vectorisations (recherche sémantique) avec la recherche dans le texte brut.
-
Sémantique : recherche uniquement les vectorisations.
Pour apprendre à définir le type de recherche, choisissez l’onglet correspondant à votre méthode préférée, puis suivez les étapes :
Vous pouvez appliquer des filtres fields/attributes au document pour améliorer encore la pertinence des réponses. Vos sources de données peuvent inclure des métadonnées attributes/fields de document à filtrer et peuvent spécifier les champs à inclure dans les intégrations.
Par exemple, « epoch_modification_time » représente le temps en secondes écoulé depuis le 1er janvier 1970 (UTC), date à laquelle le document a été mis à jour pour la dernière fois. Vous pouvez filtrer les données en fonction des plus récentes, pour lesquelles « epoch_modification_time » est supérieur à un certain nombre. Ces documents les plus récents peuvent être utilisés pour la requête.
Pour utiliser des filtres lorsque vous interrogez une base de connaissances, vérifiez que celle-ci répond aux exigences suivantes :
-
Lorsque vous configurez votre connecteur de source de données, la plupart des connecteurs explorent les principaux champs de métadonnées de vos documents. Si vous utilisez un compartiment Amazon S3 comme source de données, le compartiment doit inclure au moins un
fileName.extension.metadata.jsonpour le fichier ou le document auquel il est associé. Consultez Champs de métadonnées du document dans Configuration de la connexion pour plus d’informations sur la configuration du fichier de métadonnées. -
Si l'index vectoriel de votre base de connaissances se trouve dans un magasin de vecteurs Amazon OpenSearch Serverless, vérifiez que l'index vectoriel est configuré avec le
faissmoteur. Si l’index vectoriel est configuré avec le moteurnmslib, vous devrez effectuer l’une des opérations suivantes :-
Créez une nouvelle base de connaissances dans la console et laissez Amazon Bedrock créer automatiquement un index vectoriel dans Amazon OpenSearch Serverless pour vous.
-
Créer un autre index vectoriel dans le magasin de vecteurs et sélectionner
faisscomme moteur Créer ensuite une base de connaissances et spécifier le nouvel index vectoriel
-
-
Si votre base de connaissances utilise un index vectoriel dans un compartiment vectoriel S3, vous ne pouvez pas utiliser les filtres
startsWithetstringContains. -
Si vous ajoutez des métadonnées à un index vectoriel existant dans un cluster de bases de données Amazon Aurora, nous vous recommandons de fournir le nom de champ de la colonne de métadonnées personnalisée afin de stocker toutes vos métadonnées dans une seule colonne. Lors de l’ingestion de données, cette colonne sera utilisée pour remplir toutes les informations contenues dans vos fichiers de métadonnées à partir de vos sources de données. Si vous choisissez de remplir ce champ, vous devez créer un index sur cette colonne.
-
Lorsque vous créez une nouvelle base de connaissances dans la console et que vous laissez Amazon Bedrock configurer votre base de données Amazon Aurora, il crée automatiquement une colonne unique pour vous et la remplit avec les informations de vos fichiers de métadonnées.
-
Lorsque vous choisissez de créer un autre index vectoriel dans le magasin de vecteurs, vous devez fournir le nom du champ de métadonnées personnalisé pour stocker les informations de vos fichiers de métadonnées. Si vous ne fournissez pas ce nom de champ, vous devez créer une colonne pour chaque attribut de métadonnées de vos fichiers et spécifier le type de données (texte, nombre ou booléen). Par exemple, si l’attribut
genreexiste dans votre source de données, vous devez ajouter une colonne nomméegenreet spécifiertextcomme type de données. Pendant l’ingestion, ces colonnes distinctes seront remplies avec les valeurs d’attribut correspondantes.
-
Si votre source de données contient des documents PDF et que vous utilisez Amazon OpenSearch Serverless ou Amazon Aurora pour votre boutique vectorielle : les bases de connaissances Amazon Bedrock génèrent des numéros de page de documents et les stockent dans des métadonnées field/attribute appelées x-amz-bedrock-kb-document-page-number. Notez que les numéros de page enregistrés dans un champ de métadonnées ne sont pas pris en charge si vous choisissez de ne pas segmenter vos documents.
Vous pouvez utiliser les opérateurs de filtrage suivants pour filtrer les résultats lorsque vous interrogez les éléments suivants :
| Opérateur | Console | Nom du filtre d’API | Types de données d’attribut pris en charge | Résultats filtrés |
|---|---|---|---|---|
| Égal à | = | equals | chaîne, nombre, booléen | L'attribut correspond à la valeur que vous fournissez |
| Non égal à | != | notEquals | chaîne, nombre, booléen | L’attribut ne correspond pas à la valeur que vous fournissez |
| Supérieur à | > | Plus grand que | number | L’attribut est supérieur à la valeur que vous fournissez |
| Supérieur ou égal à | >= | plus grand ThanOrEquals | number | L’attribut est supérieur ou égal à la valeur que vous fournissez |
| Inférieur à | < | Inférieur à | number | L’attribut est inférieur à la valeur que vous fournissez |
| Inférieur ou égal à | <= | moins ThanOrEquals | number | L’attribut est inférieur ou égal à la valeur que vous fournissez |
| Dans | : | in | liste de chaînes | L'attribut figure dans la liste que vous fournissez (actuellement, il est préférable de le prendre en charge avec les magasins OpenSearch vectoriels Amazon Serverless et Neptune Analytics GraphRag) |
| Pas dans | !: | Pas dedans | liste de chaînes | L'attribut ne figure pas dans la liste que vous fournissez (actuellement, il est préférable de le prendre en charge avec les magasins OpenSearch vectoriels Amazon Serverless et Neptune Analytics GraphRag) |
| La chaîne contient | Non disponible | stringContains | chaîne | L’attribut doit être une chaîne. Le nom de l'attribut correspond à la clé et sa valeur est une chaîne contenant la valeur que vous avez fournie sous forme de sous-chaîne, ou une liste dont un membre contient la valeur que vous avez fournie sous forme de sous-chaîne (actuellement, il est préférable de le prendre en charge avec le magasin vectoriel Amazon OpenSearch Serverless). Le magasin vectoriel GraphRag de Neptune Analytics prend en charge la variante de chaîne (mais pas la variante de liste de ce filtre). |
| La liste contient | Non disponible | listContains | chaîne | L’attribut doit être une liste de chaînes. Le nom de l'attribut correspond à la clé et sa valeur est une liste contenant la valeur que vous avez fournie en tant que membre (actuellement, il est préférable de le prendre en charge avec les boutiques vectorielles Amazon OpenSearch Serverless). |
Pour combiner les opérateurs de filtrage, vous pouvez utiliser les opérateurs logiques suivants :
Pour apprendre à filtrer les résultats à l’aide de métadonnées, choisissez l’onglet correspondant à votre méthode préférée, puis suivez les étapes :
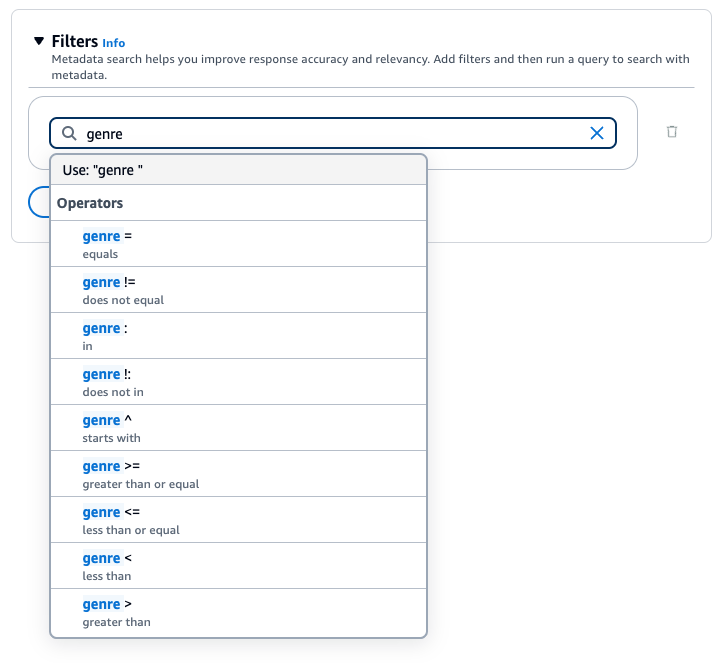

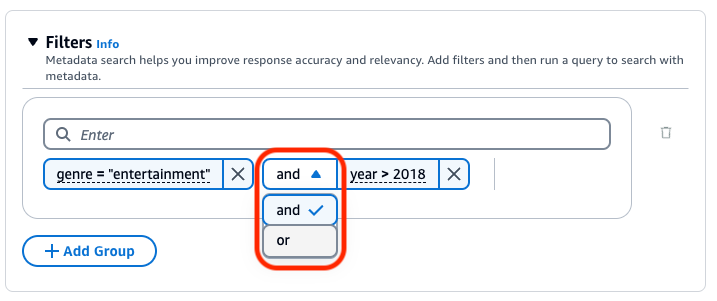
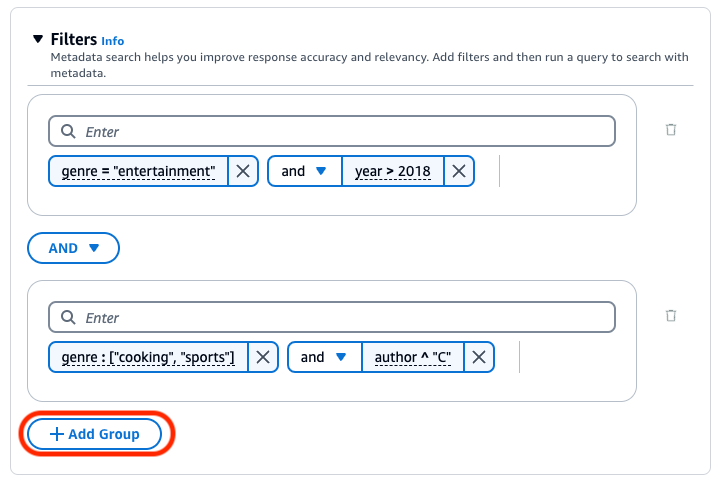
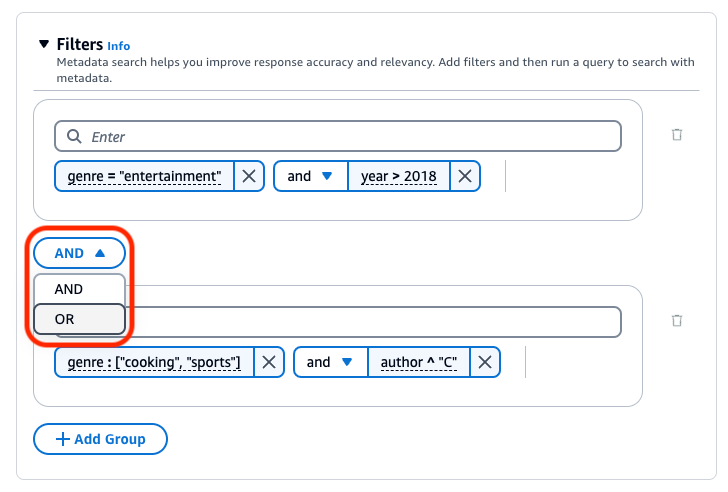
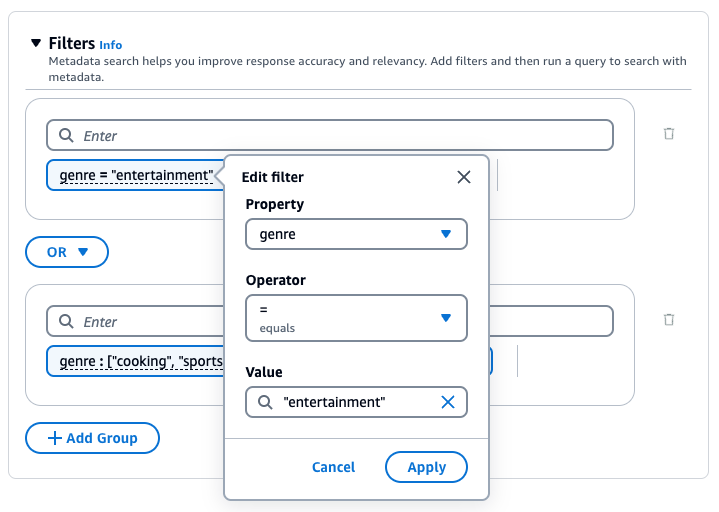
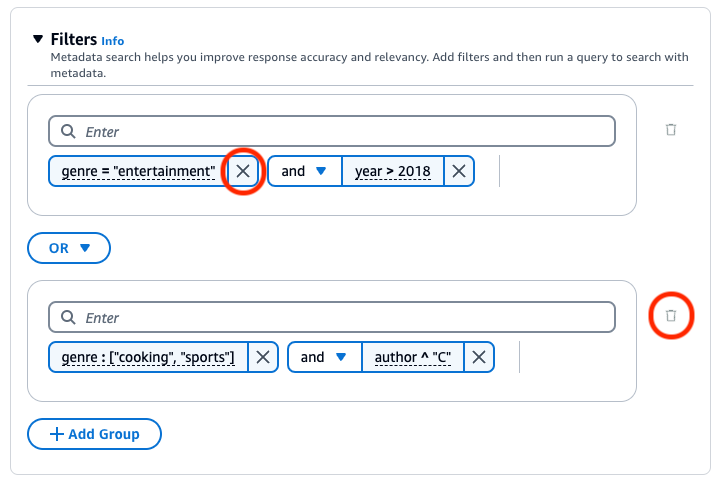
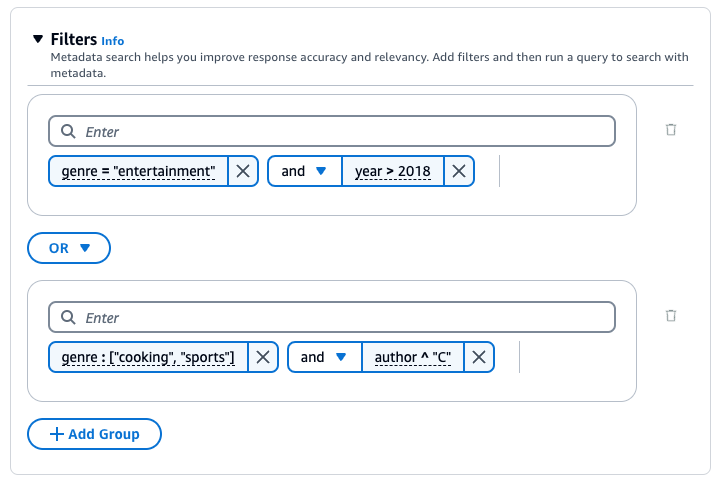
La base de connaissances Amazon Bedrock génère et applique un filtre d’extraction basé sur la requête utilisateur et un schéma de métadonnées.
Note
Le filtrage implicite des métadonnées est pris en charge par Anthropic Claude les modèles. Pour plus d'informations sur les modèles pris en charge, consultez la section Modèles en un coup d'œil.
implicitFilterConfiguration est spécifié dans le corps vectorSearchConfiguration de la demande Retrieve. Incluez les champs suivants :
-
metadataAttributes: dans ce tableau, fournissez des schémas décrivant les attributs de métadonnées pour lesquels le modèle générera un filtre. -
modelArn: ARN du modèle à utiliser.
Voici un exemple de schéma de métadonnées que vous pouvez ajouter à la matrice metadataAttributes.
[ { "key": "company", "type": "STRING", "description": "The full name of the company. E.g. `Amazon.com, Inc.`, `Alphabet Inc.`, etc" }, { "key": "ticker", "type": "STRING", "description": "The ticker name of a company in the stock market, e.g. AMZN, AAPL" }, { "key": "pe_ratio", "type": "NUMBER", "description": "The price to earning ratio of the company. This is a measure of valuation of a company. The lower the pe ratio, the company stock is considered chearper." }, { "key": "is_us_company", "type": "BOOLEAN", "description": "Indicates whether the company is a US company." }, { "key": "tags", "type": "STRING_LIST", "description": "Tags of the company, indicating its main business. E.g. `E-commerce`, `Search engine`, `Artificial intelligence`, `Cloud computing`, etc" } ]
Vous pouvez mettre en œuvre des mesures de protection pour votre base de connaissances, vos cas d’utilisation et les politiques d’IA responsables. Vous pouvez créer plusieurs barrières de protection adaptées à différents cas d’utilisation et les appliquer à de multiples conditions de demande et de réponse, afin d’offrir une expérience utilisateur cohérente et de standardiser les contrôles de sécurité dans votre base de connaissances. Vous pouvez configurer les sujets refusés pour interdire les sujets indésirables et les filtres de contenu pour bloquer le contenu préjudiciable dans les entrées et les réponses du modèle. Pour de plus amples informations, veuillez consulter Détection et filtrage des contenus préjudiciables à l’aide des barrières de protection Amazon Bedrock.
Note
L’utilisation de barrières de protection pour les bases de connaissances n’est actuellement pas prise en charge sur Claude 3, Sonnet et Haiku.
Pour les directives générales d’ingénierie de requête, consultez Concepts d’ingénierie de requête.
Choisissez l’onglet correspondant à votre méthode préférée, puis suivez les étapes :
Vous pouvez utiliser un modèle de reclassement pour reclasser les résultats d’une requête de la base de connaissances. Suivez les étapes de la console sur Interrogation d’une base de connaissances et extraction des données ouInterrogation d’une base de connaissances et génération de réponses basées sur les données récupérées. Lorsque vous ouvrez le volet Configurations, développez la section Reclassement. Sélectionnez un modèle de reclassement, mettez à jour les autorisations si nécessaire et modifiez les options supplémentaires. Entrez une invite et sélectionnez Exécuter pour tester les résultats après le reclassement.
La décomposition des requêtes est une technique utilisée pour décomposer une requête complexe en sous-requêtes plus petites et plus faciles à gérer. Cette approche peut aider à extraire des informations plus précises et pertinentes, en particulier lorsque la requête initiale comporte plusieurs facettes ou est trop large. L’activation de cette option peut entraîner l’exécution de plusieurs requêtes dans votre base de connaissances, ce qui peut contribuer à une réponse finale plus précise.
Par exemple, pour une question du type « Qui a obtenu le meilleur score lors de la Coupe du Monde de la FIFA 2022, l’Argentine ou la France ? », les bases de connaissances Amazon Bedrock peuvent d’abord générer les sous-requêtes suivantes, avant de générer une réponse finale :
-
Combien de buts l’Argentine a-t-elle marqués lors de la finale de la Coupe du Monde de la FIFA 2022 ?
-
Combien de buts la France a-t-elle marqués lors de la finale de la Coupe du Monde de la FIFA 2022 ?
Lorsque vous générez des réponses basées sur l’extraction d’informations, vous pouvez utiliser des paramètres d’inférence pour mieux contrôler le comportement du modèle pendant l’inférence et influencer les sorties du modèle.
Pour découvrir comment modifier les paramètres d’influence, choisissez l’onglet correspondant à votre méthode préférée, puis suivez les étapes :
Lorsque vous interrogez une base de données et demandez la génération d’une réponse, Amazon Bedrock utilise un modèle d’invite qui combine les instructions et le contexte avec la requête de l’utilisateur pour construire l’invite de génération qui est envoyée au modèle pour la génération de réponses. Vous pouvez également personnaliser l’invite d’orchestration, qui transforme l’invite de l’utilisateur en requête de recherche. Lorsque vous modifiez les modèles d’invite à l’aide des outils suivants :
-
Espaces réservés rapides : Pre-defined variables des bases de connaissances Amazon Bedrock qui sont renseignées dynamiquement lors de l'exécution lors de la requête de la base de connaissances. Dans l’invite du système, vous verrez ces espaces réservés entourés du symbole
$. La liste suivante décrit les espaces réservés que vous pouvez utiliser :Note
L’espace réservé
$output_format_instructions$est un champ obligatoire pour que les citations soient affichées dans la réponse.Variable Modèle d’invite Remplacé par Modèle Obligatoire ? $query$ Orchestration, génération Requête utilisateur envoyée à la base de connaissances. Anthropic Claude Instant, Anthropic Claude v2.x Oui Anthropic Claude 3 Sonnet Non (inclus automatiquement dans l’entrée du modèle) $search_results$ Génération Résultats extraits pour la requête utilisateur. Tous Oui $output_format_instructions$ Orchestration Instructions sous-jacentes pour le formatage de la génération de réponses et des citations. Diffère selon le modèle. Si vous définissez vos propres instructions de formatage, nous vous suggérons de supprimer cet espace réservé. Sans cet espace réservé, la réponse ne contiendra pas de citations. Tous Oui $current_time$ Orchestration, génération L’heure actuelle. Tous Non -
Balises XML : les modèles Anthropic prennent en charge l’utilisation de balises XML pour structurer et délimiter vos invites. Utilisez des noms de balises descriptifs pour des résultats optimaux. Par exemple, dans l’invite système par défaut, vous verrez la balise
<database>utilisée pour délimiter une base de données de questions précédemment posées). Pour plus d’informations, consultez Utiliser des balises XMLdans le Guide de l’utilisateur Anthropic .
Pour les directives générales d’ingénierie de requête, consultez Concepts d’ingénierie de requête.
Note
Lorsque vous ne fournissez pas de modèle d'invite personnalisé, Amazon Bedrock utilise une invite système par défaut qui inclut des exemples de contenu générique (tels que des exemples de questions et de réponses sur des sujets non liés) pour guider le formatage des réponses du modèle. Cette invite par défaut est visible dans les journaux d'appel des modèles. L'exemple de contenu de l'invite par défaut ne provient pas des données d'autres clients. Il s'agit d'un modèle statique fourni par Amazon Bedrock. Vous pouvez remplacer l'invite par défaut en spécifiant la vôtre. textPromptTemplate
Choisissez l’onglet correspondant à votre méthode préférée, puis suivez les étapes :
