Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création de plans pour l’extraction
BDA vous permet de définir les champs de données spécifiques que vous souhaitez extraire de vos documents lors de la création d’un plan. Il s’agit d’un ensemble d’instructions qui guident BDA sur les informations à rechercher et sur la façon de les interpréter.
Définition de champs
Pour commencer, vous pouvez créer une propriété pour chaque champ nécessitant une extraction, telle que employee_id ou product_name. Pour chaque champ, vous devez fournir une description, un type de données et un type d’inférence.
Afin de définir un champ pour l’extraction, vous devez spécifier les paramètres suivants :
-
Nom du champ : fournit une explication lisible par l’homme de ce que représente le champ. Cette description aide à comprendre le contexte et l’objectif du champ, ce qui facilite l’extraction précise des données.
-
Instruction : fournit une explication en langage naturel de ce que représente le champ. Cette description aide à comprendre le contexte et l’objectif du champ, ce qui facilite l’extraction précise des données.
-
Type : spécifie le type de données de la valeur du champ. BDA prend en charge les types de données suivants :
-
chaîne : pour les valeurs textuelles
-
nombre : pour les valeurs numériques
-
booléen : pour les valeurs true/false
-
tableau : pour les champs qui peuvent avoir plusieurs valeurs du même type (par ex. un tableau de chaînes ou de nombres)
-
-
Type d’inférence : indique à BDA comment gérer l’extraction de la valeur du champ. Les types d’inférence pris en charge sont les suivants :
-
Explicite : BDA doit extraire la valeur directement du document.
-
Inféré : BDA doit déduire la valeur sur la base des informations présentes dans le document.
-
Voici un exemple de définition de champ avec tous les paramètres :
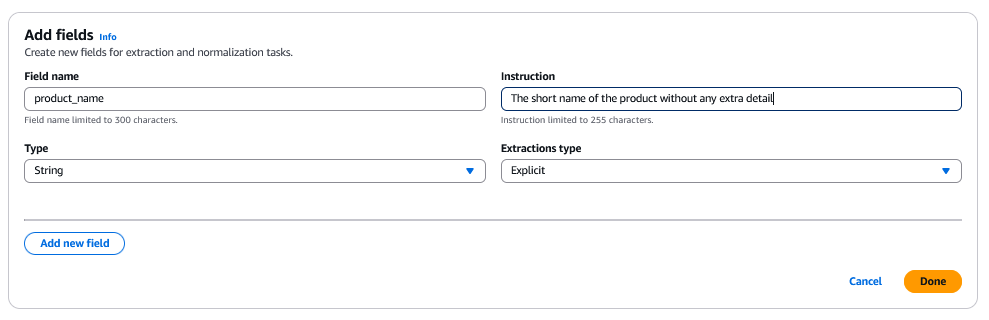
Dans cet exemple :
-
Le type est défini sur Chaîne, ce qui indique que la valeur du champ product_name doit être textuelle.
-
Le type d’inférence (inferenceType) est défini sur Explicite, ce qui indique à BDA d’extraire la valeur directement du document sans aucune transformation ni validation.
-
L’instruction fournit un contexte supplémentaire, en précisant que le champ doit contenir le nom abrégé du produit sans aucun détail supplémentaire.
En spécifiant ces paramètres pour chaque champ, vous fournissez à BDA les informations nécessaires pour extraire et générer les données désirées de vos documents.
| Champ | Instruction | Type d’extraction | Type |
|---|---|---|---|
|
ApplicantsName |
Nom complet du demandeur |
Explicite |
chaîne |
|
DateOfBirth |
Date de naissance de l’employé |
Explicite |
chaîne |
|
Ventes |
Recettes ou ventes brutes |
Explicite |
number |
|
Statement_starting_balance |
Solde en début de période |
Explicite |
number |
Multi-Valued Champs
Dans les cas où un champ peut contenir plusieurs valeurs, vous pouvez définir des tableaux ou des tables.
Liste de champs
Pour les champs contenant une liste de valeurs, vous pouvez définir un type de données Tableau.
Dans cet exemple, « OtherExpenses » est défini comme un tableau de chaînes, permettant à BDA d'extraire plusieurs postes de dépenses pour ce champ.
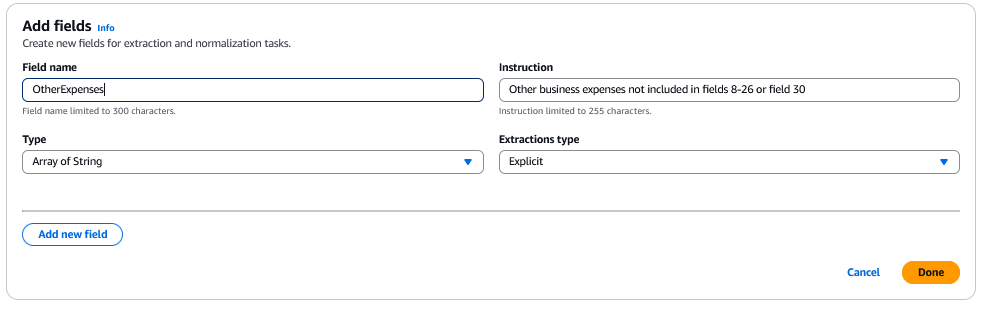
Tables
Si votre document contient des données tabulaires, vous pouvez définir une structure de tableau dans le schéma.
Dans cet exemple, « SERVICES_TABLE » est défini comme un type de table, avec des champs de colonne tels que le nom du produit, la description, la quantité, le prix unitaire et le montant.
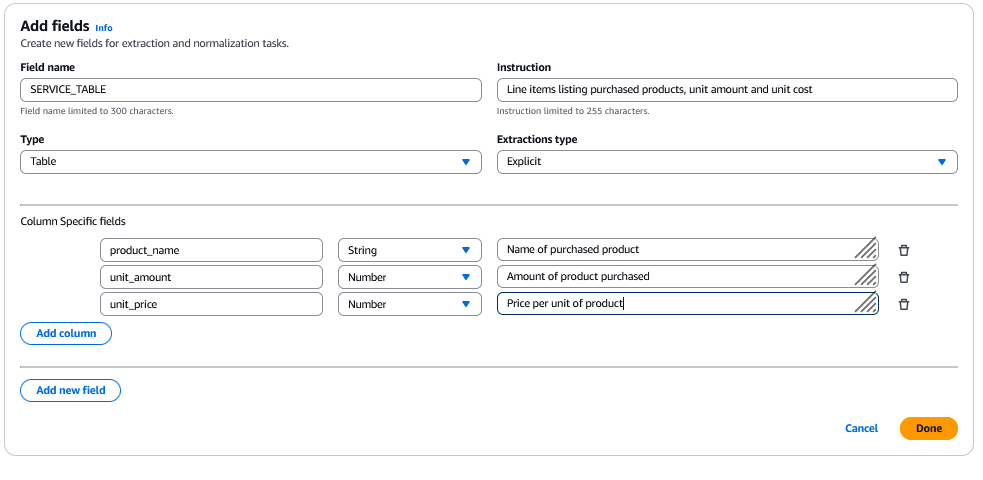
En définissant des schémas complets avec des descriptions de champs, des types de données et des types d’inférence appropriés, vous pouvez vous assurer que BDA extrait précisément les informations souhaitées de vos documents, quelles que soient les variations de mise en forme ou de représentation.
