Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connecteur Amazon Athena pour Vertica
Vertica est une plateforme de base de données en colonnes qui peut être déployée dans le cloud ou sur site et qui prend en charge les entrepôts de données à l'échelle des exaoctets. Vous pouvez utiliser le connecteur Vertica d'Amazon Athena dans les requêtes fédérées pour interroger les sources de données Vertica depuis Athena. Par exemple, vous pouvez exécuter des requêtes analytiques sur un entrepôt de données sur Vertica et un lac de données sur Simple Storage Service (Amazon S3).
Ce connecteur n’utilise pas les connexions Glue pour centraliser les propriétés de configuration dans Glue. La configuration de la connexion s’effectue via Lambda.
Conditions préalables
Déployez le connecteur sur votre Compte AWS à l’aide de la console Athena ou du AWS Serverless Application Repository. Pour plus d’informations, consultez Création d’une connexion à une source de données ou Utilisez le AWS Serverless Application Repository pour déployer un connecteur de source de données.
Avant d’utiliser ce connecteur, configurez un VPC et un groupe de sécurité. Pour plus d’informations, consultez Création d'un VPC pour un connecteur ou une connexion à une source de données AWS Glue.
Limitations
-
Étant donné que le connecteur Athena pour Vertica lit les fichiers Parquet exportés depuis Amazon S3, les performances du connecteur peuvent être lentes. Lorsque vous interrogez des tables de grande taille, nous vous recommandons d’utiliser une requête CREATE TABLE AS (SELECT ...) et des prédicats SQL.
-
Actuellement, en raison d’un problème connu dans la requête fédérée d’Athena, le connecteur oblige Vertica à exporter toutes les colonnes de la table interrogée vers Amazon S3, mais seules les colonnes demandées sont visibles dans les résultats sur la console Athena.
-
Les opérations DDL d’écriture ne sont pas prises en charge.
-
Toutes les limites Lambda pertinentes. Pour plus d'informations, consultez la section Quotas Lambda du Guide du développeur AWS Lambda .
Flux de travail
Le diagramme suivant montre le flux de travail d’une requête qui utilise le connecteur Vertica.
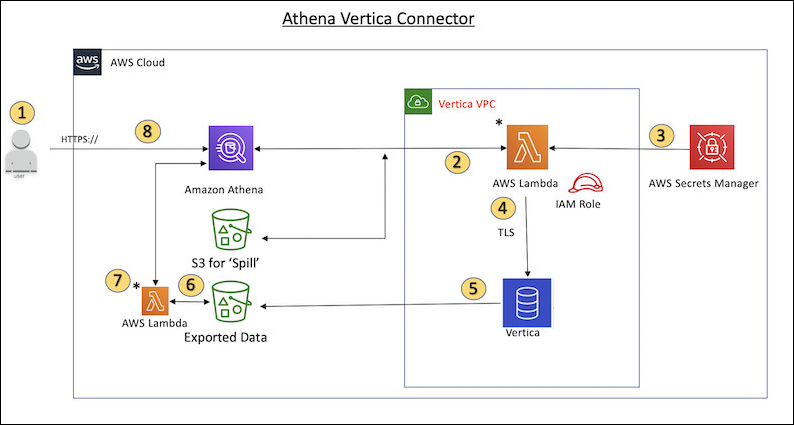
-
Une requête SQL est émise par rapport à une ou plusieurs tables dans Vertica.
-
Le connecteur analyse la requête SQL pour envoyer la partie appropriée à Vertica via la connexion JDBC.
-
Les chaînes de connexion utilisent le nom d'utilisateur et le mot de passe enregistrés AWS Secrets Manager pour accéder à Vertica.
-
Le connecteur enveloppe la requête SQL avec une commande
EXPORTVertica, comme dans l’exemple suivant.EXPORT TO PARQUET (directory = 's3://amzn-s3-demo-bucket/folder_name, Compression='Snappy', fileSizeMB=64) OVER() as SELECT PATH_ID, ... SOURCE_ITEMIZED, SOURCE_OVERRIDE FROM DELETED_OBJECT_SCHEMA.FORM_USAGE_DATA WHERE PATH_ID <= 5; -
Vertica traite la requête SQL et envoie l’ensemble de résultats à un compartiment Amazon S3. Pour un meilleur débit, Vertica utilise l’option
EXPORTpour paralléliser l’opération d’écriture de plusieurs fichiers Parquet. -
Athena analyse le compartiment Amazon S3 afin de déterminer le nombre de fichiers à lire pour l’ensemble de résultats.
-
Athena effectue plusieurs appels à la fonction Lambda et utilise un
ArrowReaderApache pour lire les fichiers Parquet à partir du jeu de données qui en résulte. Les appels multiples permettent à Athena de paralléliser la lecture des fichiers Amazon S3 et d’obtenir un débit pouvant atteindre 100 Go par seconde. -
Athena traite les données renvoyées par Vertica avec les données analysées depuis le lac de données et renvoie le résultat.
Termes
Les termes suivants se rapportent au connecteur Vertica.
-
Base de données – Toute instance d’une base de données Vertica déployée sur Amazon EC2.
-
Gestionnaire – Un gestionnaire Lambda qui accède à votre instance de base de données. Un gestionnaire peut être destiné aux métadonnées ou aux enregistrements de données.
-
Gestionnaire de métadonnées – Un gestionnaire Lambda qui extrait les métadonnées de votre instance de base de données.
-
Gestionnaire d’enregistrements – Un gestionnaire Lambda qui extrait les enregistrements de données de votre instance de base de données.
-
Gestionnaire de composites – Un gestionnaire Lambda qui extrait les métadonnées et les enregistrements de données de votre instance de base de données.
-
Propriété ou paramètre – Propriété de base de données utilisée par les gestionnaires pour extraire des informations de base de données. Vous configurez ces propriétés en tant que variables d’environnement Lambda.
-
Chaîne de connexion – Chaîne de texte utilisée pour établir une connexion à une instance de base de données.
-
Catalogue — Un AWS Glue non-catalogue enregistré auprès d'Athena qui est un préfixe obligatoire pour la propriété.
connection_string
Parameters
Utilisez les paramètres de cette section pour configurer le connecteur Vertica.
Nous vous recommandons de configurer un connecteur Vertica en utilisant un objet des connexions Glue. Pour ce faire, définissez la variable d’environnement glue_connection du connecteur Vertica Lambda sur le nom de la connexion Glue à utiliser.
Propriétés des connexions Glue
Utilisez la commande suivante afin d’obtenir le schéma d’un objet de connexion Glue. Ce schéma contient tous les paramètres que vous pouvez utiliser pour contrôler votre connexion.
aws glue describe-connection-type --connection-type VERTICA
Propriétés d’environnement Lambda
Les propriétés d'environnement Lambda suivantes s'appliquent uniquement lorsque vous utilisez le connecteur avec une fonction Lambda dans votre compte.
-
glue_connection : spécifie le nom de la connexion Glue associée au connecteur fédéré.
-
casing_mode (facultatif) : spécifie comment gérer la casse des noms de schéma et de table. Le paramètre
casing_modeutilise les valeurs suivantes pour spécifier le comportement de la casse :-
none : aucune modification de la casse dans les noms de schéma et de table indiqués. Il s’agit de la valeur par défaut pour les connecteurs auxquels une connexion Glue est associée.
-
upper : mise en majuscules de tous les noms de schéma et de table indiqués.
-
lower : mise en minuscules de tous les noms de schéma et de table indiqués.
-
Note
-
Tous les connecteurs qui utilisent une connexion AWS Glue Data Catalog fédérée doivent être utilisés AWS Secrets Manager pour stocker les informations d'identification.
-
Le connecteur Vertica créé à l'aide d'une connexion AWS Glue Data Catalog fédérée ne prend pas en charge l'utilisation d'un gestionnaire de multiplexage.
-
Le connecteur Vertica créé à l'aide d'une connexion AWS Glue Data Catalog fédérée ne prend en charge
ConnectionSchemaVersionque 2.
Le connecteur Vertica d’Amazon Athena expose des options de configuration par le biais de variables d’environnement Lambda. Vous pouvez utiliser les variables d’environnement Lambda suivantes pour configurer le connecteur.
-
AthenaCatalogName— Nom de la fonction Lambda
-
ExportBucket— Le compartiment Amazon S3 dans lequel les résultats des requêtes Vertica sont exportés.
-
SpillBucket— Le nom du compartiment Amazon S3 dans lequel cette fonction peut diffuser des données.
-
SpillPrefix— Le préfixe de l'
SpillBucketemplacement où cette fonction peut diffuser des données. -
SecurityGroupIds— Un ou plusieurs identifiants correspondant au groupe de sécurité qui doit être appliqué à la fonction Lambda (par exemple
sg1sg2, ousg3). -
SubnetIds— Un ou plusieurs ID de sous-réseau correspondant au sous-réseau que la fonction Lambda peut utiliser pour accéder à votre source de données (par exemple,
subnet1ou).subnet2 -
SecretNameOrPrefix— Le nom ou le préfixe d'un ensemble de noms dans Secrets Manager auquel cette fonction a accès (par exemple,
vertica-*) -
VerticaConnectionString— Les détails de connexion Vertica à utiliser par défaut si aucune connexion spécifique au catalogue n'est définie. La chaîne peut éventuellement utiliser AWS Secrets Manager la syntaxe (par exemple,
${secret_name}). -
ID de VPC – L’ID de VPC à associer à la fonction Lambda.
Chaîne de connexion
Utilisez une chaîne de connexion JDBC au format suivant pour vous connecter à une instance de base de données.
vertica://jdbc:vertica://host_name:port/database?user=vertica-username&password=vertica-password
Utilisation d’un gestionnaire de connexion unique
Vous pouvez utiliser les métadonnées de connexion unique et les gestionnaires d’enregistrements suivants pour vous connecter à une seule instance Vertica.
| Type de gestionnaire | Classe |
|---|---|
| Gestionnaire de composites | VerticaCompositeHandler |
| Gestionnaire de métadonnées | VerticaMetadataHandler |
| Gestionnaire d’enregistrements | VerticaRecordHandler |
Paramètres du gestionnaire de connexion unique
| Paramètre | Description |
|---|---|
default |
Obligatoire. Chaîne de connexion par défaut. |
Les gestionnaires de connexion unique prennent en charge une instance de base de données et doivent fournir un paramètre de connexion default. Toutes les autres chaînes de connexion sont ignorées.
Fourniture des informations d’identification
Pour fournir un nom d’utilisateur et un mot de passe pour votre base de données dans votre chaîne de connexion JDBC, vous pouvez utiliser les propriétés de la chaîne de connexion ou AWS Secrets Manager.
-
Chaîne de connexion – Un nom d'utilisateur et un mot de passe peuvent être spécifiés en tant que propriétés dans la chaîne de connexion JDBC.
Important
Afin de vous aider à optimiser la sécurité, n’utilisez pas d’informations d’identification codées en dur dans vos variables d’environnement ou vos chaînes de connexion. Pour plus d'informations sur le transfert de vos secrets codés en dur vers AWS Secrets Manager, voir Déplacer les secrets codés en dur vers AWS Secrets Manager dans le Guide de l'AWS Secrets Manager utilisateur.
-
AWS Secrets Manager— Pour utiliser la fonctionnalité Athena Federated Query, AWS Secrets Manager le VPC connecté à votre fonction Lambda doit disposer d'un accès Internet ou
d'un point de terminaison VPC pour se connecter à Secrets Manager. Vous pouvez insérer le nom d'un secret AWS Secrets Manager dans votre chaîne de connexion JDBC. Le connecteur remplace le nom secret par les valeurs
usernameetpasswordde Secrets Manager.Pour les instances de base de données Amazon RDS, cette prise en charge est étroitement intégrée. Si vous utilisez Amazon RDS, nous vous recommandons vivement d'utiliser une AWS Secrets Manager rotation des identifiants. Si votre base de données n’utilise pas Amazon RDS, stockez les informations d’identification au format JSON au format suivant :
{"username": "${username}", "password": "${password}"}
Exemple de chaîne de connexion avec des noms secrets
La chaîne suivante contient les noms secrets ${vertica-username} et ${vertica-password}.
vertica://jdbc:vertica://host_name:port/database?user=${vertica-username}&password=${vertica-password}
Le connecteur utilise le nom secret pour récupérer les secrets et fournir le nom d’utilisateur et le mot de passe, comme dans l’exemple suivant.
vertica://jdbc:vertica://host_name:port/database?user=sample-user&password=sample-password
Actuellement, le connecteur Vertica reconnaît les propriétés JDBC vertica-username et vertica-password.
Paramètres de déversement
Le kit SDK Lambda peut déverser des données vers Amazon S3. Toutes les instances de base de données accessibles par la même fonction Lambda déversent au même emplacement.
| Paramètre | Description |
|---|---|
spill_bucket |
Obligatoire. Nom du compartiment de déversement. |
spill_prefix |
Obligatoire. Préfixe de la clé du compartiment de déversement. |
spill_put_request_headers |
(Facultatif) Une carte codée au format JSON des en-têtes et des valeurs des demandes pour la demande putObject Amazon S3 utilisée pour le déversement (par exemple, {"x-amz-server-side-encryption" :
"AES256"}). Pour les autres en-têtes possibles, consultez le PutObjectmanuel Amazon Simple Storage Service API Reference. |
Prise en charge du type de données
Le tableau suivant indique les types de données pris en charge pour le connecteur Vertica.
| Booléen |
|---|
| BigInt |
| Court |
| Entier |
| Long |
| Float |
| Double |
| Date |
| Varchar |
| Octets |
| BigDecimal |
| TimeStamp dans le rôle de : Varchar |
Performance
La fonction Lambda procède à la transmission des projections pour réduire les données analysées par la requête. Les clauses LIMIT réduisent la quantité de données analysées, mais si vous ne fournissez pas de prédicat, vous devez vous attendre à ce que les requêtes SELECT avec une clause LIMIT analysent au moins 16 Mo de données. Le connecteur Vertica résiste à la limitation de à la simultanéité.
Requêtes de transmission
Le connecteur Vertica prend en charge les requêtes de transmission. Les requêtes de transmission utilisent une fonction de table pour transmettre votre requête complète à la source de données à des fins d’exécution.
Pour utiliser les requêtes de transmission avec Vertica, vous pouvez utiliser la syntaxe suivante :
SELECT * FROM TABLE( system.query( query => 'query string' ))
L’exemple de requête suivant transmet une requête à une source de données dans Vertica. La requête sélectionne toutes les colonnes dans la table customer, en limitant les résultats à 10.
SELECT * FROM TABLE( system.query( query => 'SELECT * FROM customer LIMIT 10' ))
Informations de licence
En utilisant ce connecteur, vous reconnaissez l'inclusion de composants tiers, dont la liste se trouve dans le fichier pom.xml
Ressources supplémentaires
Pour obtenir les informations les plus récentes sur la version du pilote JDBC, consultez le fichier pom.xml
Pour plus d'informations sur ce connecteur, consultez le site correspondant
