Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connecteur Amazon Athena pour Azure Synapse
Le connecteur Amazon Athena pour Azure Synapse Analytics
Ce connecteur peut être enregistré auprès du Catalogue de données Glue en tant que catalogue fédéré. Il prend en charge les contrôles d’accès aux données définis dans Lake Formation aux niveaux catalogue, base de données, table, colonne, ligne et balise. Ce connecteur utilise les connexions Glue pour centraliser les propriétés de configuration dans Glue.
Conditions préalables
Déployez le connecteur sur votre Compte AWS à l’aide de la console Athena ou du AWS Serverless Application Repository. Pour plus d’informations, consultez Création d’une connexion à une source de données ou Utilisez le AWS Serverless Application Repository pour déployer un connecteur de source de données.
Limitations
-
Les opérations DDL d’écriture ne sont pas prises en charge.
-
Dans une configuration de multiplexeur, le compartiment de déversement et le préfixe sont partagés entre toutes les instances de base de données.
-
Toutes les limites Lambda pertinentes. Pour plus d'informations, consultez la section Quotas Lambda du Guide du développeur AWS Lambda .
-
Dans des conditions de filtre, vous devez lancer les types de données
DateetTimestampvers le type de données approprié. -
Pour rechercher des valeurs négatives de type
RealetFloat, utilisez l’opérateur<=ou>=. -
Les types de données
binary,varbinary,imageetrowversionne sont pas pris en charge.
Termes
Les termes suivants se rapportent au connecteur Synapse.
-
Base de données – Toute instance de base de données déployée sur site, sur Amazon EC2 ou sur Amazon RDS.
-
Gestionnaire – Un gestionnaire Lambda qui accède à votre instance de base de données. Un gestionnaire peut être destiné aux métadonnées ou aux enregistrements de données.
-
Gestionnaire de métadonnées – Un gestionnaire Lambda qui extrait les métadonnées de votre instance de base de données.
-
Gestionnaire d’enregistrements – Un gestionnaire Lambda qui extrait les enregistrements de données de votre instance de base de données.
-
Gestionnaire de composites – Un gestionnaire Lambda qui extrait les métadonnées et les enregistrements de données de votre instance de base de données.
-
Propriété ou paramètre – Propriété de base de données utilisée par les gestionnaires pour extraire des informations de base de données. Vous configurez ces propriétés en tant que variables d’environnement Lambda.
-
Chaîne de connexion – Chaîne de texte utilisée pour établir une connexion à une instance de base de données.
-
Catalogue — Un AWS Glue non-catalogue enregistré auprès d'Athena qui est un préfixe obligatoire pour la propriété.
connection_string -
Gestionnaire de multiplexage – Un gestionnaire Lambda qui peut accepter et utiliser plusieurs connexions de base de données.
Parameters
Utilisez les paramètres de cette section pour configurer le connecteur Synapse.
Note
Les connecteurs de source de données Athena créés le 3 décembre 2024 et les versions ultérieures utilisent AWS Glue des connexions.
Les noms et définitions de paramètres répertoriés ci-dessous concernent les connecteurs de source de données Athena créés avant le 3 décembre 2024. Ces noms et définitions peuvent différer de ceux des propriétés de connexion AWS Glue correspondantes. À compter du 3 décembre 2024, utilisez les paramètres ci-dessous uniquement lorsque vous déployez manuellement une version antérieure d’un connecteur de source de données Athena.
Nous vous recommandons de configurer un connecteur Synapse en utilisant un objet des connexions Glue. Pour ce faire, définissez la variable d’environnement glue_connection du connecteur Synapse Lambda sur le nom de la connexion Glue à utiliser.
Propriétés des connexions Glue
Utilisez la commande suivante afin d’obtenir le schéma d’un objet de connexion Glue. Ce schéma contient tous les paramètres que vous pouvez utiliser pour contrôler votre connexion.
aws glue describe-connection-type --connection-type SYNAPSE
Propriétés d’environnement Lambda
Les propriétés d'environnement Lambda suivantes s'appliquent uniquement lorsque vous utilisez le connecteur avec une fonction Lambda dans votre compte.
-
glue_connection : spécifie le nom de la connexion Glue associée au connecteur fédéré.
-
casing_mode (facultatif) : spécifie comment gérer la casse des noms de schéma et de table. Le paramètre
casing_modeutilise les valeurs suivantes pour spécifier le comportement de la casse :-
none : aucune modification de la casse dans les noms de schéma et de table indiqués. Il s’agit de la valeur par défaut pour les connecteurs auxquels une connexion Glue est associée.
-
upper : mise en majuscules de tous les noms de schéma et de table indiqués.
-
lower : mise en minuscules de tous les noms de schéma et de table indiqués.
-
Note
-
Tous les connecteurs qui utilisent une connexion AWS Glue Data Catalog fédérée doivent être utilisés AWS Secrets Manager pour stocker les informations d'identification.
-
Le connecteur Synapse créé à l'aide d'une connexion AWS Glue Data Catalog fédérée ne prend pas en charge l'utilisation d'un gestionnaire de multiplexage.
-
Le connecteur Synapse créé à l'aide d'une connexion AWS Glue Data Catalog fédérée ne prend en charge
ConnectionSchemaVersionque 2.
Chaîne de connexion
Utilisez une chaîne de connexion JDBC au format suivant pour vous connecter à une instance de base de données.
synapse://${jdbc_connection_string}
Utilisation d’un gestionnaire de multiplexage
Vous pouvez utiliser un multiplexeur pour vous connecter à plusieurs instances de base de données à l’aide d’une seule fonction Lambda. Les demandes sont acheminées par nom de catalogue. Utilisez les classes suivantes dans Lambda.
| Handler (Gestionnaire) | Classe |
|---|---|
| Gestionnaire de composites | SynapseMuxCompositeHandler |
| Gestionnaire de métadonnées | SynapseMuxMetadataHandler |
| Gestionnaire d’enregistrements | SynapseMuxRecordHandler |
Paramètres du gestionnaire de multiplexage
| Paramètre | Description |
|---|---|
$ |
Obligatoire. Chaîne de connexion d’instance de base de données. Préfixez la variable d'environnement avec le nom du catalogue utilisé dans Athena. Par exemple, si le catalogue enregistré auprès d’Athena est mysynapsecatalog, le nom de la variable d’environnement est alors mysynapsecatalog_connection_string. |
default |
Obligatoire. Chaîne de connexion par défaut. Cette chaîne est utilisée lorsque le catalogue est lambda:${ AWS_LAMBDA_FUNCTION_NAME}. |
Les exemples de propriétés suivants concernent une fonction Synapse MUX Lambda qui prend en charge deux instances de base de données :synapse1 (par défaut) et synapse2.
| Propriété | Value |
|---|---|
default |
synapse://jdbc:synapse://synapse1.hostname:port;databaseName= |
synapse_catalog1_connection_string |
synapse://jdbc:synapse://synapse1.hostname:port;databaseName= |
synapse_catalog2_connection_string |
synapse://jdbc:synapse://synapse2.hostname:port;databaseName= |
Fourniture des informations d’identification
Pour fournir un nom d’utilisateur et un mot de passe pour votre base de données dans votre chaîne de connexion JDBC, vous pouvez utiliser les propriétés de la chaîne de connexion ou AWS Secrets Manager.
-
Chaîne de connexion – Un nom d'utilisateur et un mot de passe peuvent être spécifiés en tant que propriétés dans la chaîne de connexion JDBC.
Important
Afin de vous aider à optimiser la sécurité, n’utilisez pas d’informations d’identification codées en dur dans vos variables d’environnement ou vos chaînes de connexion. Pour plus d'informations sur le transfert de vos secrets codés en dur vers AWS Secrets Manager, voir Déplacer les secrets codés en dur vers AWS Secrets Manager dans le Guide de l'AWS Secrets Manager utilisateur.
-
AWS Secrets Manager— Pour utiliser la fonctionnalité Athena Federated Query, AWS Secrets Manager le VPC connecté à votre fonction Lambda doit disposer d'un accès Internet ou
d'un point de terminaison VPC pour se connecter à Secrets Manager. Vous pouvez insérer le nom d'un secret AWS Secrets Manager dans votre chaîne de connexion JDBC. Le connecteur remplace le nom secret par les valeurs
usernameetpasswordde Secrets Manager.Pour les instances de base de données Amazon RDS, cette prise en charge est étroitement intégrée. Si vous utilisez Amazon RDS, nous vous recommandons vivement d'utiliser une AWS Secrets Manager rotation des identifiants. Si votre base de données n’utilise pas Amazon RDS, stockez les informations d’identification au format JSON au format suivant :
{"username": "${username}", "password": "${password}"}
Exemple de chaîne de connexion avec un nom secret
La chaîne suivante porte le nom secret $ {secret_name}.
synapse://jdbc:synapse://hostname:port;databaseName=<database_name>;${secret_name}
Le connecteur utilise le nom secret pour récupérer les secrets et fournir le nom d’utilisateur et le mot de passe, comme dans l’exemple suivant.
synapse://jdbc:synapse://hostname:port;databaseName=<database_name>;user=<user>;password=<password>
Utilisation d’un gestionnaire de connexion unique
Vous pouvez utiliser les métadonnées de connexion unique et les gestionnaires d’enregistrements suivants pour vous connecter à une seule instance Synapse.
| Type de gestionnaire | Classe |
|---|---|
| Gestionnaire de composites | SynapseCompositeHandler |
| Gestionnaire de métadonnées | SynapseMetadataHandler |
| Gestionnaire d’enregistrements | SynapseRecordHandler |
Paramètres du gestionnaire de connexion unique
| Paramètre | Description |
|---|---|
default |
Obligatoire. Chaîne de connexion par défaut. |
Les gestionnaires de connexion unique prennent en charge une instance de base de données et doivent fournir un paramètre de connexion default. Toutes les autres chaînes de connexion sont ignorées.
L’exemple de propriété suivant concerne une instance Synapse unique prise en charge par une fonction Lambda.
| Propriété | Value |
|---|---|
default |
synapse://jdbc:sqlserver://hostname:port;databaseName= |
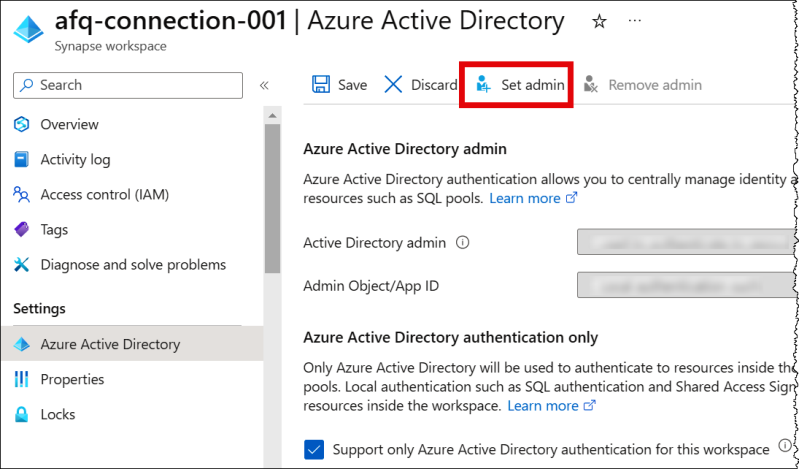
Configuration de l'authentification Active Directory
Le connecteur Amazon Athena Azure Synapse prend en charge l'authentification Microsoft Active Directory. Avant de commencer, vous devez configurer un utilisateur administratif sur le portail Microsoft Azure, puis l'utiliser AWS Secrets Manager pour créer un secret.
Pour configurer l'utilisateur administratif Active Directory
-
À l'aide d'un compte doté de privilèges administratifs, connectez-vous au portail Microsoft Azure à l'adresse https://portal.azure.com/
. -
Dans le champ de recherche, saisissez Azure Synapse Analytics, puis choisissez Azure Synapse Analytics.

-
Ouvrez le menu de gauche.

-
Dans le panneau de navigation, choisissez Azure Active Directory.
-
Dans l'onglet Définir l'administrateur, définissez l'administrateur Active Directory sur un utilisateur nouveau ou existant.
-
Dans AWS Secrets Manager, stockez le nom d'utilisateur et le mot de passe de l'administrateur. Pour plus d'informations sur la création d'un secret dans Secrets Manager, voir la rubrique Créer un secret AWS Secrets Manager.
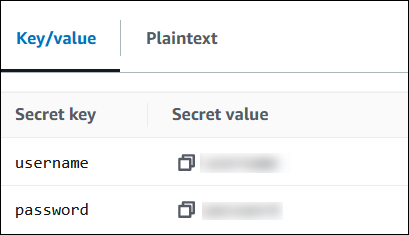
Visualisation de votre secret dans Secrets Manager
Ouvrez la console Secrets Manager à l'adresse https://console.aws.amazon.com/secretsmanager/
. -
Dans le volet de navigation, sélectionnez Secrets.
-
Sur la page Secrets, choisissez le lien vers votre secret.
-
Sur la page de détails de votre secret, sélectionnez Retrieve secret value (Récupérer la valeur du secret).
Modification de la chaîne de connexion
Pour activer l'authentification Active Directory pour le connecteur, modifiez la chaîne de connexion en utilisant la syntaxe suivante :
synapse://jdbc:synapse://hostname:port;databaseName=database_name;authentication=ActiveDirectoryPassword;{secret_name}
En utilisant ActiveDirectoryServicePrincipal
Le connecteur Amazon Athena Azure Synapse prend également en charge ActiveDirectoryServicePrincipal. Pour activer celui-ci, modifiez la chaîne de connexion comme suit.
synapse://jdbc:synapse://hostname:port;databaseName=database_name;authentication=ActiveDirectoryServicePrincipal;{secret_name}
Comme secret_name, spécifiez l'identifiant de l'application ou du client comme nom d'utilisateur et le secret de l'identité principale du service dans le mot de passe.
Paramètres de déversement
Le kit SDK Lambda peut déverser des données vers Amazon S3. Toutes les instances de base de données accessibles par la même fonction Lambda déversent au même emplacement.
| Paramètre | Description |
|---|---|
spill_bucket |
Obligatoire. Nom du compartiment de déversement. |
spill_prefix |
Obligatoire. Préfixe de la clé du compartiment de déversement. |
spill_put_request_headers |
(Facultatif) Une carte codée au format JSON des en-têtes et des valeurs des demandes pour la demande putObject Amazon S3 utilisée pour le déversement (par exemple, {"x-amz-server-side-encryption" :
"AES256"}). Pour les autres en-têtes possibles, consultez le PutObjectmanuel Amazon Simple Storage Service API Reference. |
Prise en charge du type de données
Le tableau suivant indique les types de données correspondants pour Synapse et Apache Arrow.
| Synapse | Flèche |
|---|---|
| bit | TINYINT |
| tinyint | SMALLINT |
| smallint | SMALLINT |
| int | INT |
| bigint | BIGINT |
| decimal | DECIMAL |
| numeric | FLOAT8 |
| smallmoney | FLOAT8 |
| money | DECIMAL |
| float[24] | FLOAT4 |
| float[53] | FLOAT8 |
| real | FLOAT4 |
| datetime | Date(MILLISECOND) |
| datetime2 | Date(MILLISECOND) |
| smalldatetime | Date(MILLISECOND) |
| date | Date(DAY) |
| time | VARCHAR |
| datetimeoffset | Date(MILLISECOND) |
| char[n] | VARCHAR |
| varchar [1] n/max | VARCHAR |
| nchar [n] | VARCHAR |
| navarchar [1] n/max | VARCHAR |
Partitions et déversements
Une partition est représentée par une seule colonne de partition de type varchar. Synapse prend en charge le partitionnement par plages. Le partitionnement est donc implémenté en extrayant la colonne de partition et la plage de partitions des tables de métadonnées Synapse. Ces valeurs de plage sont utilisées pour créer les divisions.
Performance
La sélection d'un sous-ensemble de colonnes ralentit considérablement l'exécution de la requête. Le connecteur présente une limitation importante due à la simultanéité.
Le connecteur Athena Synapse effectue une poussée vers le bas des prédicats pour réduire les données analysées par la requête. Des prédicats simples et des expressions complexes sont poussés vers le connecteur afin de réduire la quantité de données analysées et le délai d'exécution de la requête.
Prédicats
Un prédicat est une expression contenue dans la clause WHERE d'une requête SQL qui prend une valeur booléenne et filtre les lignes en fonction de plusieurs conditions. Le connecteur Athena Synapse peut combiner ces expressions et les pousser directement vers Synapse pour améliorer la fonctionnalité et réduire la quantité de données analysées.
Les opérateurs du connecteur Athena Synapse suivants prennent en charge la poussée vers le bas de prédicats :
-
Booléen : AND, OR, NOT
-
Égalité : EQUAL, NOT_EQUAL, LESS_THAN, LESS_THAN_OR_EQUAL, GREATER_THAN_OR_EQUAL, NULL_IF, IS_NULL
-
Arithmétique : ADD, SUBTRACT, MULTIPLY, DIVIDE, MODULUS, NEGATE
-
Autres : LIKE_PATTERN, IN
Exemple de poussée combinée vers le bas
Pour améliorer les capacités de requête, combinez les types de poussée vers le bas, comme dans l'exemple suivant :
SELECT * FROM my_table WHERE col_a > 10 AND ((col_a + col_b) > (col_c % col_d)) AND (col_e IN ('val1', 'val2', 'val3') OR col_f LIKE '%pattern%');
Requêtes de transmission
Le connecteur Synapse prend en charge les requêtes de transmission. Les requêtes de transmission utilisent une fonction de table pour transmettre votre requête complète à la source de données à des fins d’exécution.
Pour utiliser les requêtes de transmission avec Synapse, vous pouvez utiliser la syntaxe suivante :
SELECT * FROM TABLE( system.query( query => 'query string' ))
L’exemple de requête suivant transmet une requête à une source de données dans Synapse. La requête sélectionne toutes les colonnes dans la table customer, en limitant les résultats à 10.
SELECT * FROM TABLE( system.query( query => 'SELECT * FROM customer LIMIT 10' ))
Informations de licence
En utilisant ce connecteur, vous reconnaissez l'inclusion de composants tiers, dont la liste se trouve dans le fichier pom.xml
Ressources supplémentaires
-
Pour consulter un article expliquant comment utiliser Quick et Amazon Athena Federated Query pour créer des tableaux de bord et des visualisations à partir des données stockées dans les bases de données Microsoft Azure Synapse, voir Effectuer des analyses multicloud à l'aide de Quick, Amazon Athena Federated Query et Microsoft Azure Synapse sur le blog Big
Data.AWS Pour obtenir les dernières informations sur la version du pilote JDBC, consultez le fichier pom.xml
du connecteur Synapse activé. GitHub.com Pour plus d'informations sur ce connecteur, consultez le site correspondant
sur GitHub.com.
