Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Intégration de DynamoDB à Amazon Managed Streaming for Apache Kafka
Amazon Managed Streaming for Apache Kafka (Amazon MSK) facilite l’ingestion et le traitement des données de streaming en temps réel grâce à un service Apache Kafka entièrement géré.
Apache Kafka
Grâce à ces fonctionnalités, Apache Kafka est souvent utilisé pour créer des pipelines de données de streaming en temps réel. Un pipeline de données traite et déplace les données de manière fiable d’un système à un autre et peut jouer un rôle important dans l’adoption d’une stratégie de base de données sur mesure en facilitant l’utilisation de plusieurs bases de données qui prennent chacune en charge différents cas d’utilisation.
Amazon DynamoDB est une cible courante dans ces pipelines de données pour prendre en charge les applications qui utilisent des modèles de données clé-valeur ou des modèles de données de document et qui recherchent une capacité de mise à l’échelle illimitée avec des performances constantes à une milliseconde à un chiffre.
Rubriques
Comment ça marche
Une intégration entre Amazon MSK et DynamoDB utilise une fonction Lambda pour utiliser les enregistrements d’Amazon MSK et les écrire dans DynamoDB.
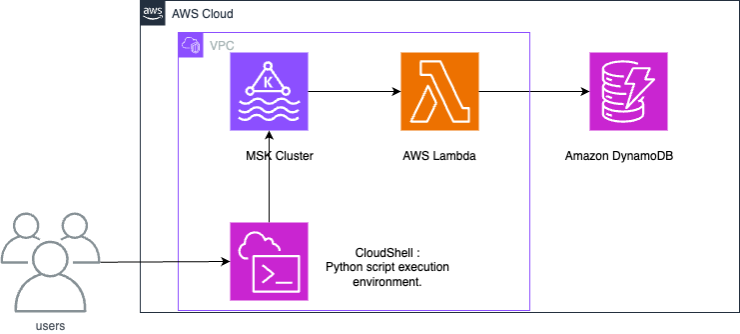
Lambda interroge en interne les nouveaux messages de la source d’événement, puis invoque de manière synchrone la fonction Lambda cible. Les données utiles des événements de la fonction Lambda contient des lots de messages provenant d’Amazon MSK. Pour l’intégration entre Amazon MSK et DynamoDB, la fonction Lambda écrit ces messages dans DynamoDB.
Configuration d’une intégration entre Amazon MSK et DynamoDB
Note
Vous pouvez télécharger les ressources utilisées dans cet exemple dans le GitHub référentiel
Les étapes ci-dessous montrent comment configurer un exemple d’intégration entre Amazon MSK et Amazon DynamoDB. L’exemple représente des données générées par des appareils IoT (Internet des objets) et ingérées dans Amazon MSK. Lorsque les données sont ingérées dans Amazon MSK, elles peuvent être intégrées à des services analytiques ou à des outils tiers compatibles avec Apache Kafka, ce qui permet divers cas d’utilisation de l’analytique. L’intégration de DynamoDB permet également de rechercher des valeurs clés dans des enregistrements de d’appareils individuels.
Cet exemple montre comment un script Python écrit les données des capteurs IoT sur Amazon MSK. Ensuite, une fonction Lambda écrit des éléments avec la clé de partition « deviceid » dans DynamoDB.
Le CloudFormation modèle fourni créera les ressources suivantes : un compartiment Amazon S3, un Amazon VPC, un cluster Amazon MSK et un AWS CloudShell pour tester les opérations de données.
Pour générer des données de test, créez une rubrique Amazon MSK, puis créez une table DynamoDB. Vous pouvez utiliser le gestionnaire de session depuis la console de gestion pour vous connecter au système CloudShell d'exploitation et exécuter des scripts Python.
Après avoir exécuté le CloudFormation modèle, vous pouvez terminer la création de cette architecture en effectuant les opérations suivantes.
-
Exécutez le CloudFormation modèle
S3bucket.yamlpour créer un compartiment S3. Pour tous les scripts ou opérations suivants, exécutez-les dans la même région. EntrezForMSKTestS3comme nom de CloudFormation pile.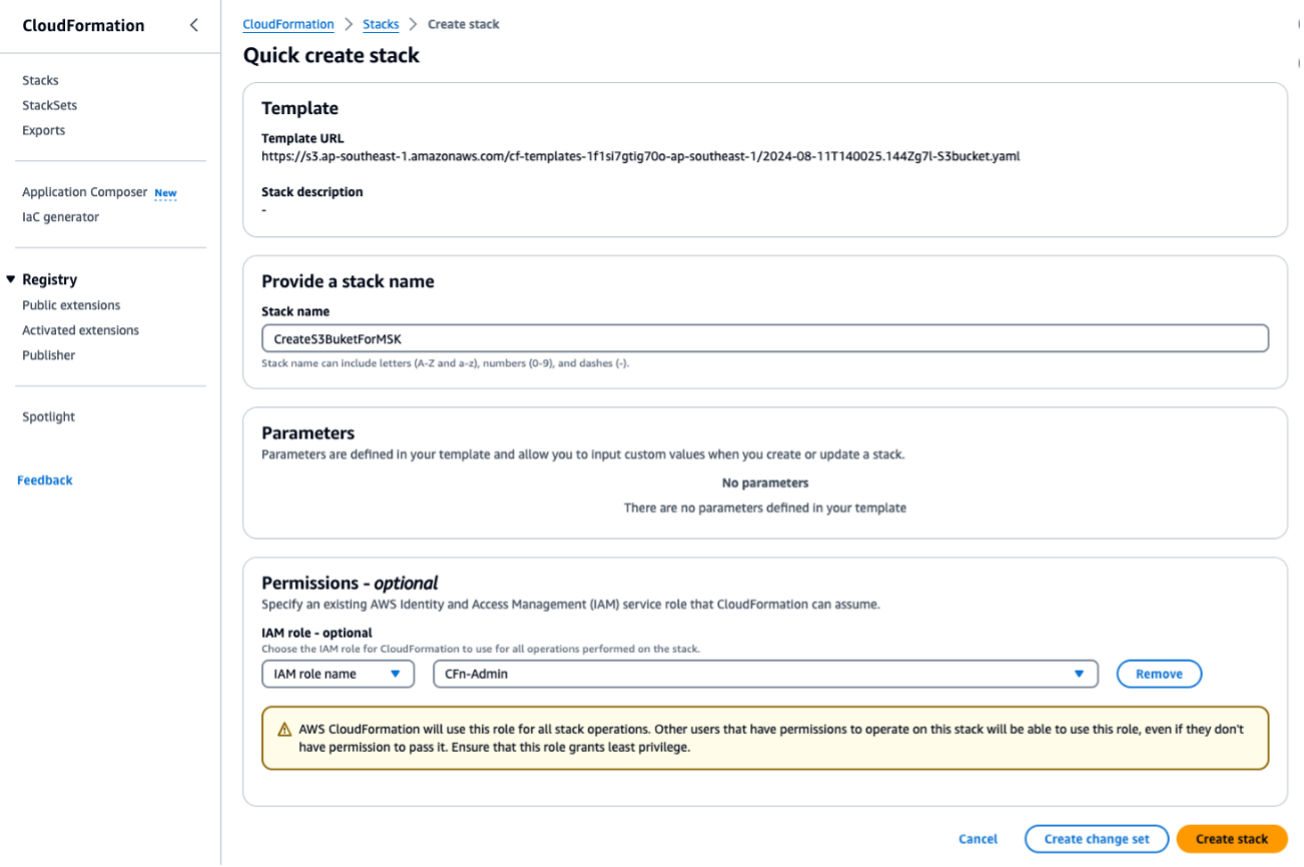
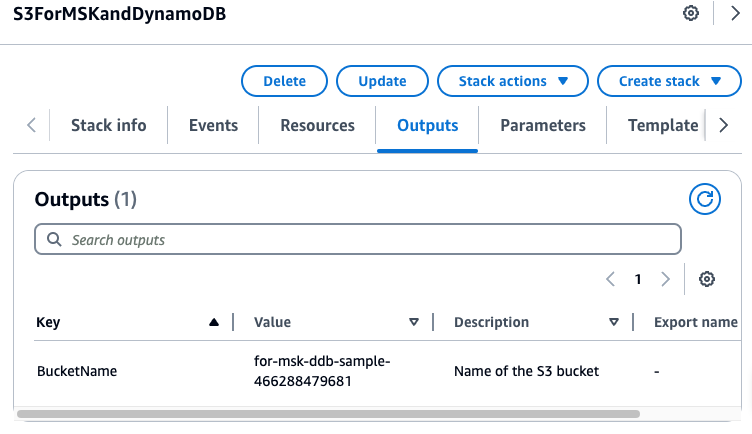
Une fois cette opération terminée, notez le nom du compartiment S3 affiché sous Sorties. Vous aurez besoin du nom à l’étape 3.
-
Chargez le fichier ZIP
fromMSK.ziptéléchargé dans le compartiment S3 que vous venez de créer.
-
Exécutez le CloudFormation modèle
VPC.yamlpour créer un VPC, un cluster Amazon MSK et une fonction Lambda. Sur l’écran de saisie des paramètres, entrez le nom du compartiment S3 que vous avez créé à l’étape 1 où il est demandé le compartiment S3. Définissez le nom de la CloudFormation pile surForMSKTestVPC.
-
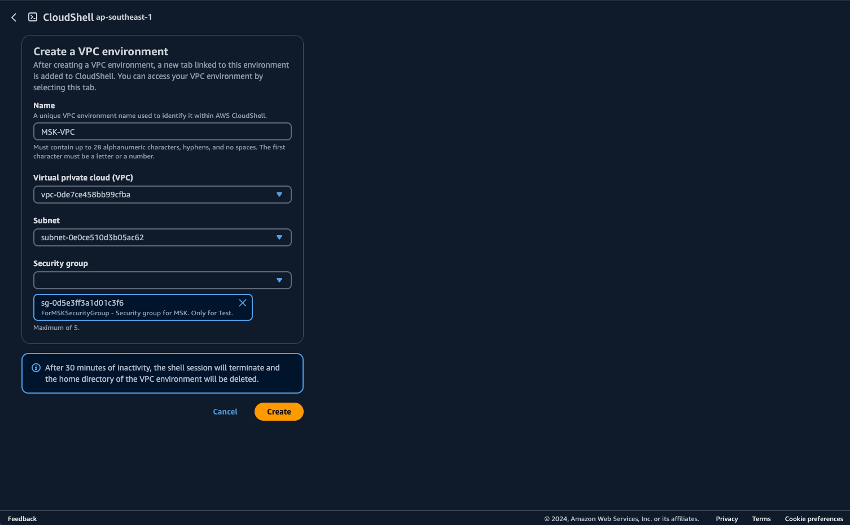
Préparez l'environnement dans lequel les scripts Python seront exécutés CloudShell. Vous pouvez utiliser CloudShell sur le AWS Management Console. Pour plus d'informations sur l'utilisation CloudShell, consultez Getting started with AWS CloudShell. Après avoir démarré CloudShell, créez un VPC appartenant au VPC CloudShell que vous venez de créer afin de vous connecter au cluster Amazon MSK. Créez-le CloudShell dans un sous-réseau privé. Remplissez les champs suivants :
-
Name : peut être défini sur n’importe quel nom. Voici un exemple : MSK-VPC.
-
VPC : sélectionnez MSKTest
-
Subnet : sélectionnez MSKTest Private Subnet (AZ1)
-
SecurityGroup- sélectionner ForMSKSecurityGroup

Une fois que l' CloudShell appartenance au sous-réseau privé a commencé, exécutez la commande suivante :
pip install boto3 kafka-python aws-msk-iam-sasl-signer-python -
-
Téléchargez des scripts Python à partir du compartiment S3.
aws s3 cp s3://[YOUR-BUCKET-NAME]/pythonScripts.zip ./ unzip pythonScripts.zip -
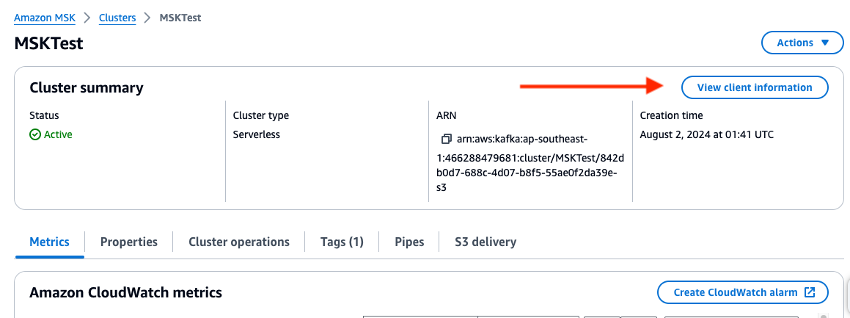
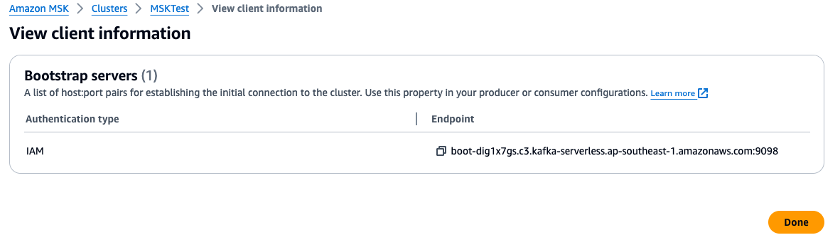
Vérifiez la console de gestion et définissez les variables d’environnement pour l’URL du courtier et la valeur de région dans les scripts Python. Vérifiez le point de terminaison du courtier de clusters Amazon MSK dans la console de gestion.
-
Définissez les variables d'environnement sur le CloudShell. Si vous utilisez USA Ouest (Oregon) :
export AWS_REGION="us-west-2" export MSK_BROKER="boot-YOURMSKCLUSTER.c3.kafka-serverless.ap-southeast-1.amazonaws.com:9098" -
Exécutez les script Python suivants.
Créez une rubrique Amazon MSK.
python ./createTopic.pyCréez une table DynamoDB.
python ./createTable.pyÉcrivez des données de test dans la rubrique Amazon MSK :
python ./kafkaDataGen.py -
Vérifiez les CloudWatch métriques des ressources Amazon MSK, Lambda et DynamoDB créées, et vérifiez les données stockées dans la
device_statustable à l'aide de l'explorateur de données DynamoDB pour vous assurer que tous les processus se sont exécutés correctement. Si chaque processus est exécuté sans erreur, vous pouvez vérifier que les données de test écrites depuis CloudShell Amazon MSK sont également écrites sur DynamoDB.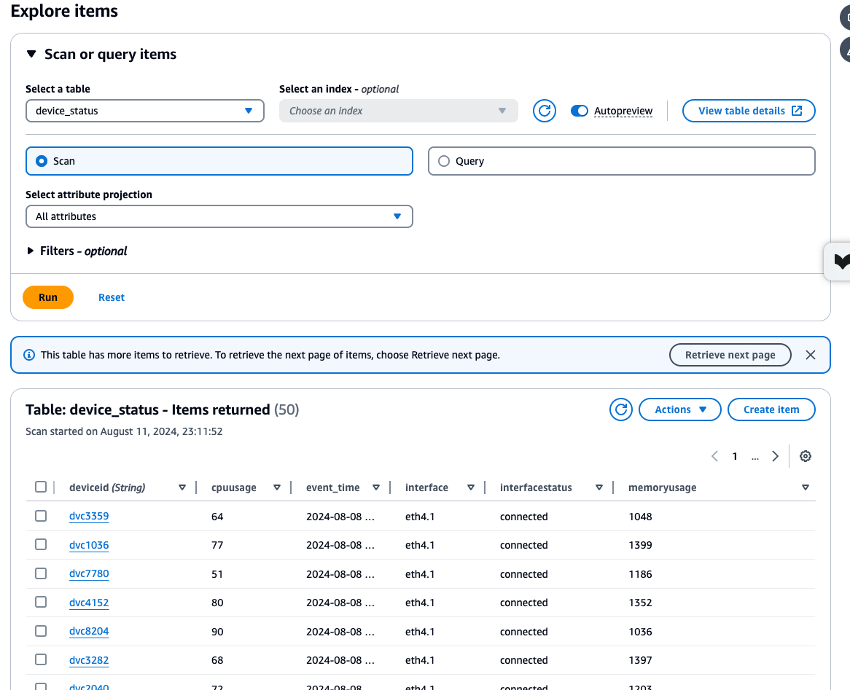
-
Lorsque vous avez terminé avec cet exemple, supprimez les ressources créées dans ce didacticiel. Supprimez les deux CloudFormation piles :
ForMSKTestS3et.ForMSKTestVPCSi la suppression de la pile aboutit, toutes les ressources seront supprimées.
Étapes suivantes
Note
Si vous avez créé des ressources en suivant cet exemple, pensez à les supprimer pour éviter des frais imprévus.
L’intégration a identifié une architecture qui lie Amazon MSK et DynamoDB afin de permettre aux données de flux de prendre en charge les charges de travail OLTP. À partir de là, des recherches plus complexes peuvent être effectuées en liant DynamoDB à Service OpenSearch . Envisagez l'intégration EventBridge pour les besoins plus complexes liés aux événements, et des extensions telles qu'Amazon Managed Service pour Apache Flink pour un débit plus élevé et des exigences de latence plus faibles.
