Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migration à partir d’une base de données relationnelle vers DynamoDB
La migration d’une base de données relationnelle vers DynamoDB nécessite une planification minutieuse pour garantir un résultat réussi. Ce guide vous aidera à comprendre le fonctionnement de ce processus, les outils dont vous disposez, puis comment évaluer les stratégies de migration potentielles et sélectionner celle qui répondra à vos besoins.
Rubriques
Raisons justifiant la migration vers DynamoDB
La migration vers Amazon DynamoDB présente de nombreux avantages intéressants pour les entreprises et les organisations. Voici quelques avantages clés qui font de DynamoDB un choix intéressant pour la migration de bases de données :
-
Capacité de mise à l’échelle : DynamoDB est conçu pour gérer des charges de travail massives et s’adapter facilement à l’augmentation des volumes de données et du trafic. Avec DynamoDB, vous pouvez facilement augmenter ou réduire verticalement votre base de données en fonction de la demande, afin que vos applications puissent gérer des pics de trafic soudains sans compromettre les performances.
-
Performances : DynamoDB offre un accès aux données à faible latence, ce qui permet aux applications de récupérer et de traiter les données à une vitesse exceptionnelle. Son architecture distribuée garantit que les opérations de lecture et d’écriture sont réparties sur plusieurs nœuds, et offre des temps de réponse constants de l’ordre de la milliseconde, même à des taux de demandes élevés.
-
Entièrement géré : DynamoDB est un service entièrement géré fourni par AWS. Cela signifie qu'il AWS gère les aspects opérationnels de la gestion des bases de données, notamment le provisionnement, la configuration, les correctifs, les sauvegardes et le dimensionnement. Cela vous permet de vous concentrer davantage sur le développement de vos applications et moins sur les tâches d’administration de base de données.
-
Architecture sans serveur : DynamoDB prend en charge un modèle sans serveur, appelé DynamoDB à la demande, dans lequel vous ne payez que pour les demandes de lecture et d’écriture réellement effectuées par votre application, sans qu’aucun provisionnement de capacité initial ne soit requis. Ce pay-per-request modèle offre une rentabilité et une charge opérationnelle minimale, car vous ne payez que pour les ressources que vous consommez sans avoir à provisionner et à surveiller les capacités.
-
Flexibilité NoSQL : contrairement aux bases de données relationnelles traditionnelles, DynamoDB suit un modèle de données NoSQL, offrant ainsi de la flexibilité dans la conception des schémas. Avec DynamoDB, vous pouvez stocker des données structurées, semi-structurées et non structurées, ce qui le rend parfaitement adapté à la gestion de types de données divers et évolutifs. Cette flexibilité permet d’accélérer les cycles de développement et de s’adapter plus facilement à l’évolution des besoins de l’entreprise.
-
Haute disponibilité et durabilité : DynamoDB réplique les données dans plusieurs zones de disponibilité au sein d’une région, garantissant ainsi une haute disponibilité et une durabilité des données. Il gère automatiquement la réplication, le basculement et la restauration, minimisant ainsi le risque de perte de données ou d’interruption de service. DynamoDB fournit un SLA de disponibilité allant jusqu’à 99,999 %.
-
Sécurité et conformité : DynamoDB s’intègre à Gestion des identités et des accès AWS pour le contrôle précis des accès. Il permet un chiffrement au repos et en transit, garantissant ainsi la sécurité de vos données. DynamoDB respecte également différentes normes de conformité (HIPAA, PCI DSS et RGPD, par exemple), ce qui vous permet de répondre aux exigences réglementaires.
-
Intégration à l' AWS écosystème : dans le cadre de l' AWS écosystème, DynamoDB s'intègre parfaitement à d' AWS autres services, AWS Lambda tels que CloudFormation, et. AWS AppSync Cette intégration vous permet de créer des architectures sans serveur, de tirer parti de l’infrastructure sous forme de code et de créer des applications pilotées par les données en temps réel.
Considérations relatives à la migration d’une base de données relationnelle vers DynamoDB
Les systèmes de gestion de bases de données relationnelles et les bases de données NoSQL ont chacun leurs forces et leurs faiblesses. Ces différences entraînent une conception des bases de données très différente d’un système à l’autre :
| Type de tâche | Base de données relationnelle | Base de données NoSQL |
|---|---|---|
| Interrogation de la base de données | Dans les bases de données relationnelle, les données peuvent être interrogées avec souplesse, mais les requêtes sont relativement coûteuses et ne sont pas bien mises à l’échelle dans les situations de trafic intense (consultez Premiers pas pour la modélisation des données relationnelles dans DynamoDB). Une application de base de données relationnelle peut implémenter une logique métier dans les procédures stockées, les sous-requêtes SQL, les requêtes de mise à jour en masse et les requêtes d’agrégation. | Dans une base de données NoSQL comme DynamoDB, les données peuvent être interrogées efficacement d’un nombre limité de façons, en dehors desquelles les requêtes peuvent être coûteuses et lentes. Les écritures dans DynamoDB sont des singletons. La logique métier des applications qui s'exécutait auparavant dans des procédures stockées doit être refactorisée pour s'exécuter en dehors de DynamoDB dans du code personnalisé exécuté sur un hôte tel qu'Amazon EC2 ou. AWS Lambda |
| Conception de la base de données | La conception se concentre avant tout sur la flexibilité, sans se préoccuper des détails de l’implémentation ni des performances. En général, l’optimisation des requêtes n’affecte pas la conception du schéma, mais la normalisation est très importante. | Votre schéma est conçu spécifiquement pour que les requêtes les plus courantes et les plus importantes soient aussi rapides et économiques que possible. Les structures de vos données sont adaptées aux exigences spécifiques de vos cas d’utilisation. |
La conception d’une base de données NoSQL nécessite un état d’esprit différent de celui de la conception d’un système de gestion de base de données relationnelle (SGBDR). Pour un SGBDR, vous pouvez créer un modèle de données normalisé sans réfléchir aux modèles d’accès. Vous pouvez l’étendre ultérieurement, pour répondre à de nouvelles questions et de nouveaux besoins d’interrogation. Vous pouvez organiser chaque type de données dans sa propre table.
Avec la conception NoSQL, vous pouvez concevoir votre schéma pour DynamoDB lorsque vous savez à quelle problématique celui-ci doit répondre. Il est essentiel d’identifier au préalable les problèmes métier et les modèles de lecture et d’écriture de l’application. Vous devez aussi essayer de gérer le moins de tables possible dans une application DynamoDB. Le fait d’avoir moins de tables rend les choses plus évolutives, nécessite moins de gestion des autorisations et réduit les frais généraux pour votre application DynamoDB. Cela peut également contribuer à maintenir des coûts de sauvegarde globalement plus faibles.
La tâche de modélisation des données relationnelles pour DynamoDB et la création d’une nouvelle version de l’application frontale font l’objet d’une rubrique distincte. Ce guide part du principe que vous disposez d’une nouvelle version de votre application conçue pour utiliser DynamoDB, mais vous devez tout de même déterminer la meilleure façon de migrer et de synchroniser les données historiques lors du basculement.
Considérations sur le dimensionnement
La taille maximale de chaque élément (rangée) que vous stockez dans une table DynamoDB est de 400 Ko. Pour de plus amples informations, veuillez consulter Quotas dans Amazon DynamoDB. La taille de l’élément est déterminée par la taille totale de tous les noms d’attributs et de toutes les valeurs d’attribut d’un élément. Pour de plus amples informations, veuillez consulter Tailles et formats d’élément DynamoDB.
Si votre application a besoin de stocker dans un élément davantage de données que ne le permet la limite de taille dans DynamoDB, scindez l’élément en une collection d’éléments, compressez les données de l’élément, ou stockez l’élément en tant qu’objet dans Amazon Simple Storage Service (Amazon S3), tout en stockant l’identifiant d’objet Amazon S3 dans votre élément DynamoDB. Consultez Bonnes pratiques de stockage d’éléments volumineux et d’attributs dans DynamoDB. Le coût de mise à jour d’un élément dépend de sa taille complète. Pour les charges de travail qui nécessitent des mises à jour fréquentes des éléments existants, la mise à jour de petits éléments d’un ou deux Ko coûtera moins cher que celle d’éléments plus volumineux. Pour plus d’informations sur les collections d’éléments, consultez Collections d'éléments : comment modéliser one-to-many les relations dans DynamoDB.
Lorsque vous choisissez les attributs de partition et de clé de tri, les autres paramètres de table, la taille et la structure des éléments, et si vous souhaitez créer des index secondaires, n’oubliez pas de consulter la documentation relative à la modélisation DynamoDB ainsi que le guide d’Optimisation des coûts sur les tables DynamoDB. Assurez-vous de tester votre plan de migration afin que votre solution DynamoDB soit rentable et réponde aux fonctionnalités et limites de DynamoDB.
Comprendre le fonctionnement d’une migration vers DynamoDB
Avant de passer en revue les outils de migration mis à notre disposition, réfléchissez à la manière dont les écritures sont traitées par DynamoDB.
L’opération d’écriture par défaut et la plus courante est une opération d’API PutItem unique. Vous pouvez effectuer une opération PutItem en boucle pour traiter des jeux de données. DynamoDB prend en charge un nombre pratiquement illimité de connexions simultanées. Par conséquent, en supposant que vous puissiez configurer et exécuter une routine de chargement massivement multithread telle MapReduce que ou Spark, la vitesse d'écriture n'est limitée que par la capacité de la table cible (qui est également généralement illimitée).
Lorsque vous chargez des données dans DynamoDB, il est important de comprendre la vitesse d’écriture de votre chargeur. Si les éléments (rangées) que vous chargez ont une taille inférieure ou égale à 1 Ko, cette vélocité correspond simplement au nombre d’éléments par seconde. La table cible peut ensuite être provisionnée avec suffisamment de WCU (unités de capacité d’écriture) pour gérer ce taux. Si votre chargeur dépasse la capacité provisionnée à chaque seconde, les demandes supplémentaires peuvent être limitées ou rejetées. Vous pouvez vérifier les limites dans les CloudWatch graphiques de l'onglet de surveillance de la console DynamoDB.
La deuxième opération qui peut être effectuée est avec une API associée appelée BatchWriteItem. BatchWriteItem vous permet de combiner jusqu’à 25 demandes d’écriture en un seul appel d’API. Elles sont reçues par le service et traitées comme des demandes PutItem distinctes adressées à la table. Actuellement, lors du choixBatchWriteItem, vous ne bénéficierez pas de l'avantage des nouvelles tentatives automatiques incluses dans le AWS SDK lorsque vous passez des appels singleton avec. PutItem Ainsi, s’il y a des erreurs (telles que des exceptions de limitation), vous devrez rechercher la liste des écritures ayant échoué dans l’appel de réponse à BatchWriteItem. Pour plus d'informations sur la gestion des avertissements de limitation au cas où ils seraient détectés dans les graphiques de CloudWatch régulation, voir. Résolution des problèmes de limitation dans Amazon DynamoDB
Le troisième type d’importation de données est possible grâce à la fonctionnalité DynamoDB Import from S3PutItem, aucun un processus en amont n’est nécessaire et les données sont écrites dans le format de votre choix dans un compartiment Amazon S3.
Outils permettant de migrer vers DynamoDB
Il existe plusieurs outils de migration et ETL courants que vous pouvez utiliser pour migrer des données vers DynamoDB.
Amazon fournit une multitude d’outils de données qui peuvent être utilisés pour la migration, notamment AWS Database Migration Service (DMS), AWS Glue, Amazon EMR et Amazon Managed Streaming for Apache Kafka. Tous ces outils peuvent être utilisés pour effectuer une migration pendant une durée d’indisponibilité, et ils peuvent tirer parti des fonctionnalités de capture des données modifiées (CDC) des bases de données relationnelles pour prendre en charge les migrations en ligne. Lorsque vous choisissez un outil, il est utile de prendre en compte les compétences et l’expérience de votre organisation avec chaque outil, ainsi que les fonctionnalités, les performances et le coût de chacun d’entre eux.
De nombreux clients choisissent d’écrire leurs propres scripts et tâches de migration afin de créer des transformations de données personnalisées pour le processus de migration. Si vous envisagez d’exploiter une table DynamoDB à volume élevé avec un trafic d’écriture important ou des tâches régulières de chargement en masse de grande taille, vous souhaiterez peut-être écrire vous-même le code de migration afin de vous familiariser avec le comportement de DynamoDB en cas de trafic d’écriture élevé. Des scénarios tels que la gestion des limitations et le provisionnement efficace des tables peuvent être expérimentés au début du projet lors d’une migration pratique.
Choix de la stratégie appropriée pour migrer vers DynamoDB
Une application de base de données relationnelle de grande taille peut s’étendre sur une centaine de tables ou plus et prendre en charge plusieurs fonctions d’application différentes. Lorsque vous vous apprêtez à effectuer une migration de grande envergure, pensez à diviser votre application en composants plus petits ou en microservices, et à migrer un petit ensemble de tables à la fois. Vous pouvez ensuite migrer des composants supplémentaires vers DynamoDB par vagues.
Lors du choix d’une stratégie de migration, différents facteurs peuvent vous orienter vers une solution ou une autre. Nous pouvons présenter ces options dans un arbre de décision afin de simplifier les options qui s’offrent à nous en fonction de nos besoins et des ressources disponibles. Les concepts sont brièvement mentionnés ici (mais seront abordés plus en détail plus loin dans le guide) :
-
Migration hors ligne : si votre application peut tolérer une certaine durée d’indisponibilité pendant la migration, cela simplifiera le processus de migration.
-
Migration hybride : cette approche permet une durée de fonctionnement partielle pendant une migration, par exemple en autorisant les lectures mais pas les écritures, ou en autorisant les lectures et les insertions mais pas les mises à jour et les suppressions.
-
Migration en ligne : les applications qui ne tolèrent aucune durée d’indisponibilité pendant la migration sont moins faciles à migrer et peuvent nécessiter une planification importante et un développement personnalisé. L’une des décisions clés consiste à estimer et à évaluer les coûts liés à la mise en place d’un processus de migration personnalisé par rapport au coût pour l’entreprise d’une durée d’indisponibilité pendant le basculement.
| If | Et | Then |
|---|---|---|
| Vous pouvez désactiver l’application pendant un certain temps pendant une période de maintenance pour effectuer la migration des données. Il s’agit d’une migration hors ligne. |
Utilisez AWS DMS et effectuez une migration hors ligne à l'aide d'une tâche de chargement complet. Préformez les données source à l’aide d’un code SQL |
|
| Vous pouvez exécuter l’application en mode lecture seule pendant la migration. Il s’agit d’une migration hybride. | Désactivez les écritures dans l’application ou la base de données source. Utilisez AWS DMS et effectuez une migration hors ligne à l'aide d'une tâche de chargement complet. | |
| Vous pouvez exécuter l’application avec des lectures et des insertions de nouveaux enregistrements, mais pas de mises à jour ni de suppressions pendant la migration. Il s’agit d’une migration hybride. | Vous avez des compétences en développement d’applications et pouvez mettre à jour l’application relationnelle existante pour effectuer des écritures doubles, y compris dans DynamoDB, pour tous les nouveaux enregistrements | Utilisez AWS DMS et effectuez une migration hors ligne à l'aide d'une tâche de chargement complet. Déployez simultanément une version de l’application existante qui autorise les lectures et effectue des écritures doubles. |
| Vous avez besoin d’une migration avec une durée d’indisponibilité minimale. Il s’agit d’une migration en ligne. |
|
AWS DMS À utiliser pour effectuer une migration de données en ligne. Exécutez une tâche de chargement en bloc suivie d’une tâche de synchronisation CDC. |
| Vous avez besoin d’une migration avec une durée d’indisponibilité minimale. Il s’agit d’une migration en ligne. |
|
Créez la table NoSQL Ready dans la base de données SQL. Remplissez-le et synchronisez-le à l'aide de déclencheurs JOINs UNIONs VIEWs, de procédures stockées. |
| Vous avez besoin d’une migration avec une durée d’indisponibilité minimale. Il s’agit d’une migration en ligne. |
|
Envisagez les approches de migration hybrides ou hors ligne. |
| Vous avez besoin d’une migration avec une durée d’indisponibilité minimale. Il s’agit d’une migration en ligne. | Vous pouvez ignorer la migration des données de transaction historiques ou les archiver dans Amazon S3 au lieu de les migrer. Il suffit de migrer quelques petites tables statiques. | Écrivez un script ou utilisez un outil ETL pour migrer les tables. Préformez les données source à l’aide d’un code SQL VIEW si vous le souhaitez. |
Réalisation d’une migration hors ligne vers DynamoDB
Les migrations hors ligne sont adaptées lorsque vous pouvez autoriser une durée d’indisponibilité pour effectuer la migration. Les bases de données relationnelles prennent généralement au moins une certaine durée d’indisponibilité arrêt par mois pour des raisons de maintenance et de correction, lesquelle peuvent être plus longues pour les mises à niveau matérielles ou les mises à niveau de versions majeures.
Amazon S3 peut être utilisé comme zone intermédiaire lors d’une migration. Les données stockées au format CSV (valeurs séparées par des virgules) ou DynamoDB JSON peuvent être automatiquement importées dans une nouvelle table DynamoDB à l’aide de la Fonctionnalité d’importation DynamoDB à partir de S3.
Vous souhaiterez peut-être combiner des tables pour tirer parti de modèles d’accès NoSQL uniques (par exemple, transformer quatre tables héritées en une seule table DynamoDB). Une demande de document contenant une valeur clé unique ou une requête pour une collection d’éléments pré-groupés est généralement renvoyée avec une latence supérieure à celle d’une base de données SQL qui effectue une jointure à plusieurs tables. Cela complique toutefois la tâche de migration. Une vue SQL peut effectuer le travail au sein de la base de données source pour préparer un jeu de données unique représentant les quatre tables d’un seul ensemble.
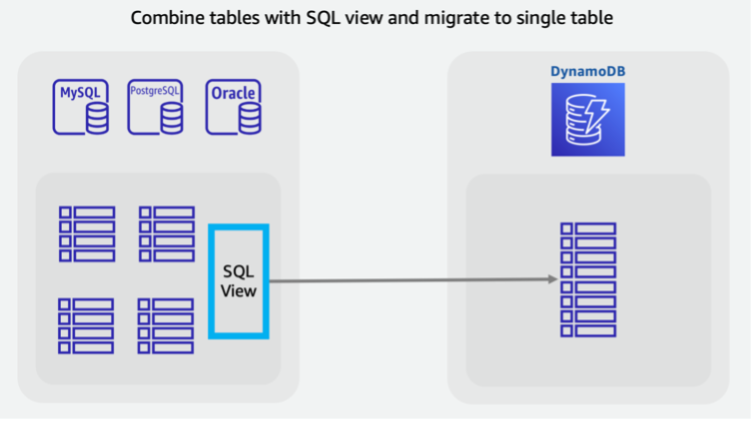
Cette vue permet de dénormaliser les tables JOIN ou de maintenir les entités normalisées et d’empiler les tables à l’aide d’une instruction SQL UNION. Les principales décisions relatives à la refonte des données relationnelles sont abordées dans cette vidéo
Planifier
Exécution d’une migration hors ligne à l’aide d’Amazon S3
Outils
-
Tâche ETL pour extraire et transformer des données SQL et les stocker dans un compartiment S3 tel que :
-
AWS Database Migration Service, service capable de charger des données historiques en bloc et de traiter les enregistrements CDC pour synchroniser les tables source et cible.
-
AWS Glue
-
Amazon EMR
-
Votre propre code personnalisé
-
-
Fonctionnalité d’importation DynamoDB à partir de S3
Étapes de migration hors ligne :
-
Créez une tâche ETL capable d’interroger la base de données SQL, de transformer les données des tables au format DynamoDB JSON ou CSV et de les enregistrer dans un compartiment S3.
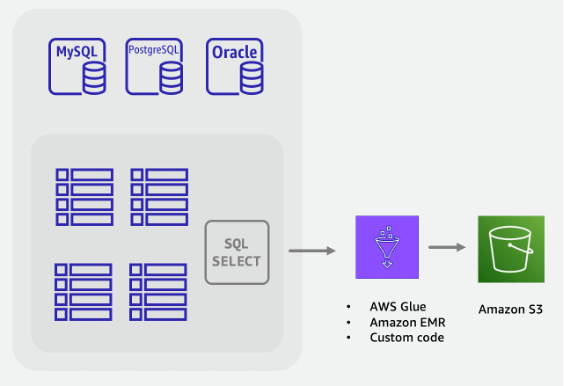
-
La fonctionnalité d’importation DynamoDB à partir de S3 est invoquée pour créer une nouvelle table et charger automatiquement les données depuis votre compartiment S3.
La migration entièrement hors ligne est simple et directe, mais elle risque de ne pas être populaire auprès des propriétaires et des utilisateurs d’applications. Les utilisateurs en tireraient bénéfice si l’application pouvait fournir des niveaux de service réduits pendant la migration, au lieu de ne pas fournir de service du tout.
Vous pouvez ajouter une fonctionnalité pour désactiver les écritures pendant la migration hors ligne, tout en permettant aux lectures de se poursuivre normalement. Les utilisateurs de l’application peuvent toujours parcourir et interroger en toute sécurité les données existantes pendant la migration des données relationnelles. Si c’est ce que vous recherchez, poursuivez votre lecture pour en savoir plus sur les migrations hybrides.
Exécution d’une migration hybride vers DynamoDB
Bien que toutes les applications de base de données exécutent des opérations de lecture et d’écriture, les types d’opérations d’écriture effectués doivent être pris en compte lors de la planification d’une migration hybride ou en ligne. Les écritures de base de données peuvent être classées en trois compartiments : insertions, mises à jour et suppressions. Certaines applications peuvent ne pas nécessiter le traitement immédiat des suppressions. Ces applications peuvent, par exemple, reporter les suppressions à un processus de nettoyage en bloc à la fin du mois. Ces types d’applications peuvent être plus simples à migrer tout en garantissant une durée de fonctionnement partielle.
Planifier
Effectuez une online/offline migration hybride avec deux écritures d'application
Outils
-
Tâche ETL pour extraire et transformer des données SQL et les stocker dans un compartiment S3 tel que :
-
AWS DMS
-
AWS Glue
-
Amazon EMR
-
Votre propre code personnalisé
-
Étapes de migration hybride :
-
Créez la table DynamoDB cible. Ce tableau recevra à la fois des données historiques en bloc et de nouvelles données en temps réel
-
Créez une version de l’application héritée dont les suppressions et les mises à jour sont désactivées tout en effectuant toutes les insertions sous forme de double écriture dans la base de données SQL et DynamoDB
-
Commencez le travail ou la AWS DMS tâche ETL pour compléter les données existantes et déployer la nouvelle version de l'application en même temps
-
Une fois le travail de remplissage terminé, DynamoDB disposera de tous les enregistrements existants et nouveaux et sera prêt pour le basculement des applications
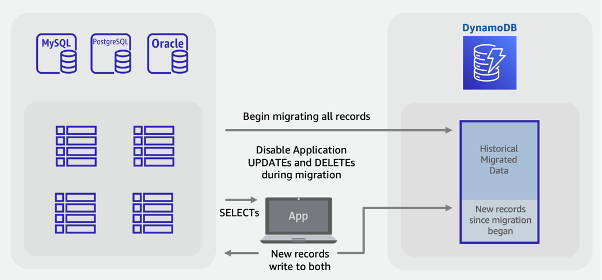
Note
La tâche de remplissage écrit directement depuis SQL vers DynamoDB. Nous ne pouvons pas utiliser la fonctionnalité d’importation S3 comme dans l’exemple de migration hors ligne, car cette fonctionnalité crée une nouvelle table qui ne sera active qu’après le chargement des données par DynamoDB.
Réalisation d’une migration en ligne vers DynamoDB en faisant migrer chaque table 1:1
De nombreuses bases de données relationnelles disposent d’une fonctionnalité appelée Change Data Capture (CDC), qui permet aux utilisateurs de demander une liste des modifications apportées à une table avant ou après un instant dans le passé. CDC utilise des journaux internes pour activer cette fonctionnalité et il n’est pas nécessaire que la table contienne une colonne d’horodatage pour fonctionner.
Lorsque vous migrez un schéma de tables SQL vers une base de données NoSQL, vous pouvez si vous le souhaitez combiner et remodeler vos données en un nombre réduit de tables. Cela vous permettra de collecter des données en un seul endroit et d’éviter d’avoir à joindre manuellement les données associées lors d’opérations de lecture en plusieurs étapes. Cependant, la mise en forme des données d’une seule table n’est pas toujours requise et vous devez parfois migrer des tables 1-vers-1 dans DynamoDB. Ces migrations de tables 1-vers-1 individuelles sont moins compliquées car vous pouvez tirer parti de la fonctionnalité CDC de la base de données source, en utilisant des outils ETL courants qui prennent en charge ce type de migration. Les données de chaque ligne peuvent toujours être transformées dans de nouveaux formats, mais la portée de chaque table reste la même.
Envisagez de migrer les tables SQL 1-vers-1 dans DynamoDB, tout en gardant à l’esprit que DynamoDB ne prend pas en charge les jointures côté serveur. Vous devez ajouter une logique à votre application pour combiner les données de plusieurs tables.
Planifier
Effectuez une migration en ligne de chaque table dans DynamoDB à l'aide de AWS DMS
Outils
Étapes de migration en ligne :
-
Identifiez les tables de votre schéma source qui seront migrées
-
Créez le même nombre de tables dans DynamoDB avec la même structure de clés que dans la source
-
Création d'un serveur de réplication AWS DMS et configuration des points de terminaison source et cible
-
Définissez toutes les transformations requises par ligne (telles que les colonnes concaténées ou la conversion des dates au format de chaîne ISO-8601)
-
Créez une tâche de migration pour chaque table pour le chargement complet et la capture des données de modification
-
Surveillez ces tâches jusqu’au début de la phase de réplication en cours
-
À ce stade, vous pouvez effectuer des audits de validation, puis transférer les utilisateurs vers l’application qui lit et écrit dans DynamoDB
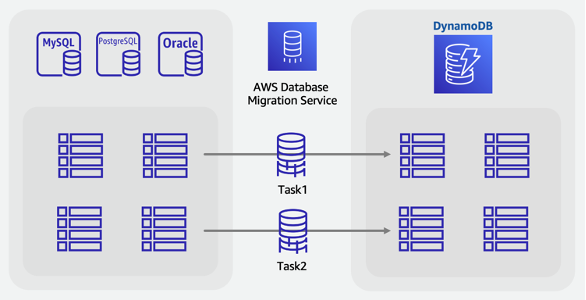
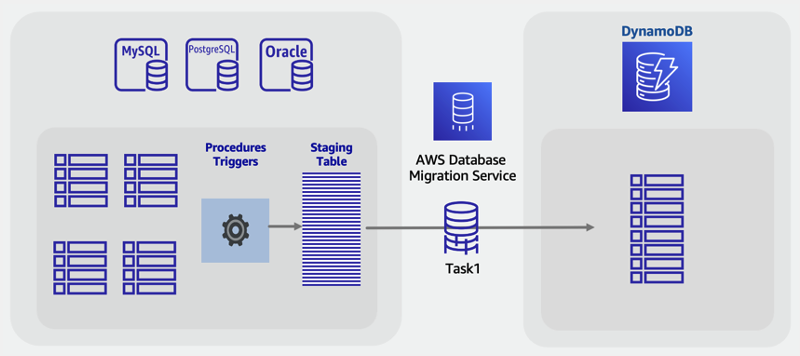
Réalisation d’une migration en ligne vers DynamoDB à l’aide d’une table intermédiaire personnalisée
Comme dans le scénario de migration hors ligne ci-dessus, vous pouvez choisir de combiner des tables pour tirer parti de modèles d’accès NoSQL uniques (par exemple, transformer quatre tables héritées en une seule table DynamoDB). Une instruction SQL VIEW peut effectuer le travail au sein de la base de données source pour préparer un jeu de données unique représentant les quatre tables d’un seul ensemble.
Toutefois, pour les migrations en ligne avec des données en temps réel et changeantes, vous ne pouvez pas tirer parti des fonctionnalités de CDC car elles ne sont pas prises en charge pour les VIEWs. Si vos tables incluent une colonne d’horodatage mise à jour pour la dernière fois et que celle-ci y est incorporée dans la VIEW, vous pouvez créer une tâche ETL personnalisée qui les utilise pour effectuer un chargement en bloc avec synchronisation.
Une nouvelle approche pour relever ce défi consiste à utiliser des fonctionnalités SQL standard, telles que les vues, les procédures stockées et les déclencheurs pour créer une nouvelle table SQL au format DynamoDB NoSQL final souhaité.
Si votre serveur de base de données dispose de la capacité inutilisée, il est possible de créer cette table intermédiaire unique avant le début de la migration. Pour ce faire, vous devez écrire une procédure stockée qui lira les données des tables existantes, transformera les données selon les besoins et écrira dans la nouvelle table intermédiaire. Vous pouvez ajouter un ensemble de déclencheurs pour répliquer les modifications apportées aux tables dans la table intermédiaire en temps réel. Si les déclencheurs ne sont pas autorisés conformément à la politique de l’entreprise, les modifications apportées aux procédures stockées peuvent produire le même résultat. Vous devez ajouter quelques lignes de code à toute procédure qui écrit des données, afin d’écrire en outre les mêmes modifications dans la table intermédiaire.
La mise en place de cette table intermédiaire entièrement synchronisée avec les tables héritées d’applications constitue un excellent point de départ pour une migration en direct. Les outils utilisant la base de données CDC pour effectuer des migrations dynamiques, tels que AWS DMS, peuvent désormais être utilisés par rapport à cette table. L’avantage de cette approche est qu’elle utilise des compétences SQL bien connues et des fonctionnalités disponibles dans le moteur de base de données relationnelle.
Planifier
Effectuez une migration en ligne à l'aide d'une table intermédiaire SQL en utilisant AWS DMS
Outils
-
Procédures stockées ou déclencheurs SQL personnalisés
Étapes de migration en ligne :
-
Dans le moteur de base de données relationnelle source, assurez-vous de disposer d’un espace disque et d’une capacité de traitement supplémentaires.
-
Créez une nouvelle table intermédiaire dans la base de données SQL, avec les horodatages ou les fonctionnalités CDC activées
-
Écriture et exécution d’une procédure stockée pour copier les données d’une table relationnelle existante dans la table intermédiaire
-
Déployez des déclencheurs ou modifiez les procédures existantes pour effectuer une double écriture dans la nouvelle table intermédiaire tout en effectuant des écritures normales dans les tables existantes
-
Exécutez AWS DMS pour migrer et synchroniser cette table source vers une table DynamoDB cible
Ce guide présentait plusieurs considérations et approches relatives à la migration des données de base de données relationnelle vers DynamoDB, en mettant l’accent sur la réduction des durées d’indisponibilité et l’utilisation d’outils et de techniques de base de données courants. Pour plus d’informations, consultez les ressources suivantes :
