Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Conception du schéma d’un système de gestion des réclamations dans DynamoDB
Cas d’utilisation métier d’un système de gestion des réclamations
DynamoDB est une base de données parfaitement adaptée à un cas d’utilisation de système de gestion des réclamations (ou centre de contact), car la plupart des modèles d’accès qui y sont associés sont des recherches transactionnelles basées sur des paires clé-valeur. Dans ce scénario, les modèles d’accès types consisteraient à :
-
Créer et mettre à jour des réclamations
-
Transmettre une réclamation à un échelon supérieur (escalade)
-
Créer et lire des commentaires sur une réclamation
-
Recueillir toutes les réclamations d’un client
-
Recueillir tous les commentaires d’un agent et toutes les escalades
Certains commentaires peuvent s’accompagner de pièces jointes décrivant la réclamation ou la solution. Bien que ces modèles d’accès soient tous de type clé-valeur, d’autres exigences peuvent s’ajouter, comme l’envoi de notifications lorsqu’un nouveau commentaire est ajouté à une réclamation ou l’exécution de requêtes analytiques pour déterminer la répartition hebdomadaire des réclamations par gravité (ou les performances des agents). La nécessité d’archiver les données relatives aux réclamations trois ans après l’enregistrement de la réclamation pourrait constituer une autre exigence liée à la gestion du cycle de vie ou à la conformité.
Diagramme de l’architecture du système de gestion des réclamations
Le schéma suivant illustre l’architecture du système de gestion des réclamations. Ce schéma montre les différentes Service AWS intégrations utilisées par le système de gestion des plaintes.

Outre les modèles d’accès transactionnel de type clé-valeur que nous traiterons ultérieurement dans la section sur la modélisation de données DynamoDB, nous sommes en présence de trois exigences non transactionnelles. Le diagramme d’architecture ci-dessus peut être décomposé en trois flux de travail distincts, à savoir :
-
Envoyer une notification lorsqu’un nouveau commentaire est ajouté à une réclamation
-
Exécuter des requêtes analytiques sur les données hebdomadaires
-
Archiver les données de plus de trois ans
Examinons de plus près chacun d’eux.
Envoyer une notification lorsqu’un nouveau commentaire est ajouté à une réclamation
Nous pouvons utiliser le flux de travail ci-dessous pour répondre à cette exigence :

Flux DynamoDB est un mécanisme de capture des modifications de données qui enregistre toutes les activités d’écriture de vos tables DynamoDB. Vous pouvez configurer des fonctions Lambda pour qu’elles se déclenchent pour tout ou partie de ces modifications. Un filtre d’événements peut être configuré au niveau des déclencheurs Lambda afin de filtrer les événements qui n’ont aucun rapport direct avec le cas d’utilisation. Dans ce cas, nous pouvons utiliser un filtre pour déclencher Lambda uniquement lorsqu’un nouveau commentaire est ajouté et envoyer une notification aux adresses e-mail voulues, qui peuvent être récupérées depuis AWS Secrets Manager ou tout autre magasin d’informations d’identification.
Exécuter des requêtes analytiques sur les données hebdomadaires
DynamoDB est adapté aux charges de travail principalement axées sur le traitement transactionnel en ligne (OLTP). Pour les 10 à 20 % de modèles d’accès restants soumis à des exigences analytiques, les données peuvent être exportées vers S3 à l’aide de la fonctionnalité gérée Exporter vers Amazon S3 sans que cela n’impacte le trafic en direct de la table DynamoDB. Examinez le flux de travail ci-dessous :
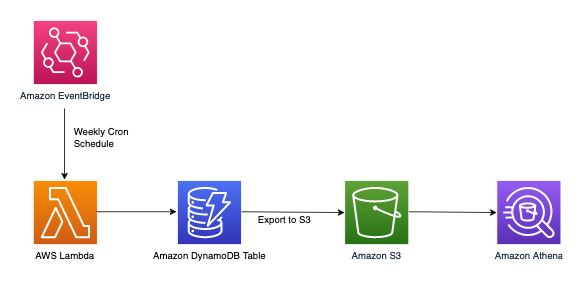
Amazon EventBridge peut être utilisé pour déclencher dans AWS Lambda les délais prévus : il vous permet de configurer une expression cron pour que l'appel Lambda ait lieu périodiquement. Lambda peut invoquer l’appel de l’API ExportToS3 et stocker les données DynamoDB dans S3. Un moteur SQL comme Amazon Athena peut ensuite accéder à ces données S3 afin d’exécuter des requêtes analytiques sur les données DynamoDB sans affecter la charge de travail transactionnelle en direct de la table. Voici un exemple de requête Athena qui vise à déterminer le nombre de réclamations par niveau de gravité :
SELECT Item.severity.S as "Severity", COUNT(Item) as "Count" FROM "complaint_management"."data" WHERE NOT Item.severity.S = '' GROUP BY Item.severity.S ;
Cette requête Athena renvoie le résultat suivant :

Archiver les données de plus de trois ans
Vous pouvez tirer parti de la fonctionnalité DynamoDB Durée de vie (TTL) pour supprimer les données obsolètes de votre table DynamoDB sans frais supplémentaires (sauf dans le cas des réplicas de tables globales pour la version (actuelle) 2019.11.21, où les suppressions TTL répliquées dans d’autres régions consomment de la capacité d’écriture). Ces données apparaissent et peuvent être utilisées par des flux DynamoDB pour être archivées dans Amazon S3. Voici comment se présente le flux de travail pour cette exigence :

Diagramme des relations entre entités du système de gestion des réclamations
Il s’agit du diagramme des relations entre entités (ERD) que nous allons utiliser pour la conception du schéma du système de gestion des réclamations.

Modèles d’accès du système de gestion des réclamations
Voici les modèles d’accès que nous allons prendre en considération pour la conception du schéma de gestion des réclamations.
-
createComplaint
-
updateComplaint
-
updateSeveritybyComplaintID
-
getComplaintByID de plainte
-
addCommentByID de plainte
-
getAllCommentsByComplaintID
-
getLatestCommentByComplaintID
-
obtenir un identifiant de IDAnd plainte AComplaintby du client
-
getAllComplaintsByCustomerID
-
escalateComplaintByID de plainte
-
getAllEscalatedRéclamations
-
getEscalatedComplaintsByAgentID (ordre du plus récent au plus ancien)
-
getCommentsByAgentID (entre deux dates)
Évolution de la conception du schéma du système de gestion des réclamations
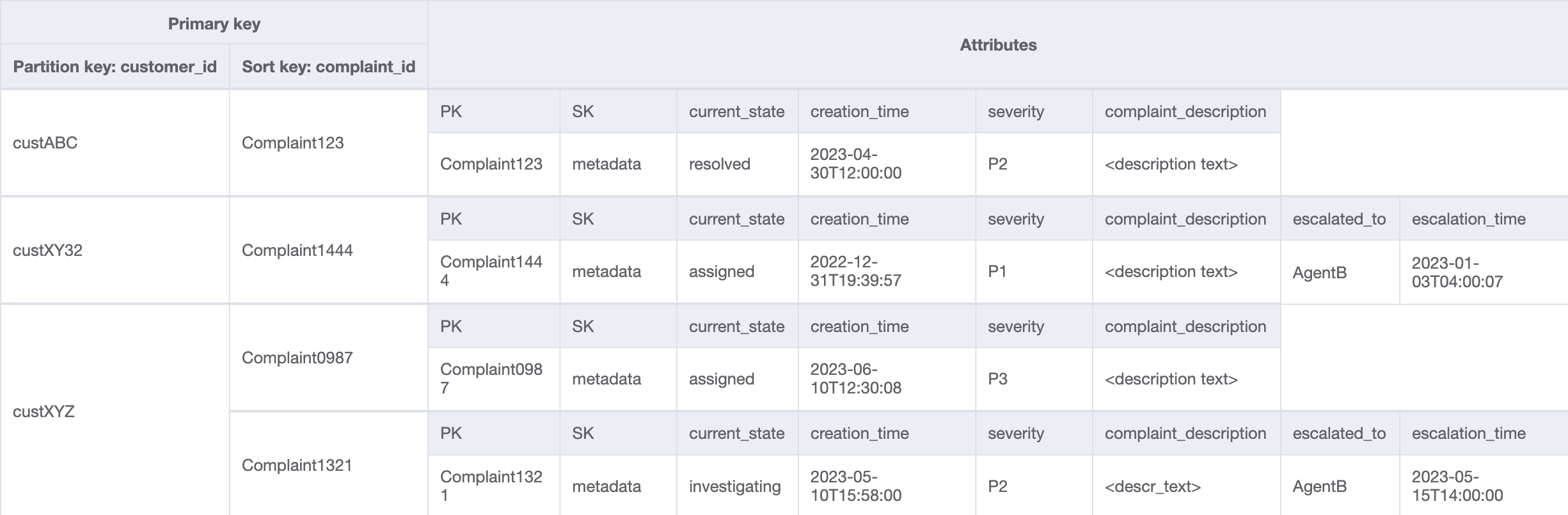
S’agissant d’un système de gestion des réclamations, la plupart des modèles d’accès sont centrés sur la réclamation en tant qu’entité principale. Du fait de sa cardinalité élevée, ComplaintID assurera une répartition uniforme des données dans les partitions sous-jacentes, et ce sera également le critère de recherche le plus courant pour nos modèles d’accès identifiés. Par conséquent, il est judicieux d’utiliser ComplaintID comme de clé de partition dans cet ensemble de données.
Étape 1 : Traitement des modèles d’accès 1 (createComplaint), 2 (updateComplaint), 3 (updateSeveritybyComplaintID) et 4 (getComplaintByComplaintID)
Nous pouvons utiliser une valeur de clé de tri générique appelée « metadata » (ou « AA ») pour stocker les informations propres aux réclamations, telles que CustomerID, State, Severity et CreationDate. Nous utilisons des opérations singleton avec PK=ComplaintID et SK=“metadata” pour effectuer les opérations suivantes :
-
PutItempour créer une nouvelle réclamation -
UpdateItempour mettre à jour la gravité ou d’autres champs dans les métadonnées de la réclamation -
GetItempour récupérer les métadonnées de la réclamation

Étape 2 : Traitement du modèle d’accès 5 (addCommentByComplaintID)
Ce modèle d'accès nécessite un modèle de one-to-many relation entre une plainte et les commentaires sur la plainte. Nous allons employer ici la technique du partitionnement vertical pour utiliser une clé de tri et créer une collection d’éléments avec différents types de données. Dans le cas des modèles d’accès 6 (getAllCommentsByComplaintID) et 7 (getLatestCommentByComplaintID), nous savons que les commentaires devront être triés par ordre chronologique. Nous savons également que plusieurs commentaires pourront être reçus simultanément, ce qui signifie que nous pouvons utiliser la technique de clé de tri composite pour ajouter l’heure et CommentID dans l’attribut de clé de tri.
Pour faire face à ce risque de collision de commentaires, il pourrait être envisagé d’accroître la granularité de l’horodatage ou d’ajouter un nombre incrémentiel en guise de suffixe à la place de Comment_ID. Dans ce cas, nous allons faire précéder la valeur de clé de tri du préfixe « comm# » pour les éléments correspondant aux commentaires afin de permettre les opérations basées sur une plage.
Nous devons également vérifier que currentState dans les métadonnées de la réclamation reflète l’état d’ajout d’un nouveau commentaire. L’ajout d’un commentaire peut indiquer que la réclamation a été affectée à un agent, qu’elle n’a pas été résolue, etc. Afin de regrouper l'ajout de commentaires et la mise à jour de l'état actuel dans les métadonnées de la plainte, nous utiliserons l'TransactWriteItemsAPI d'une all-or-nothing manière ou d'une autre. L’état de la table qui en résulte ressemble désormais à ceci :

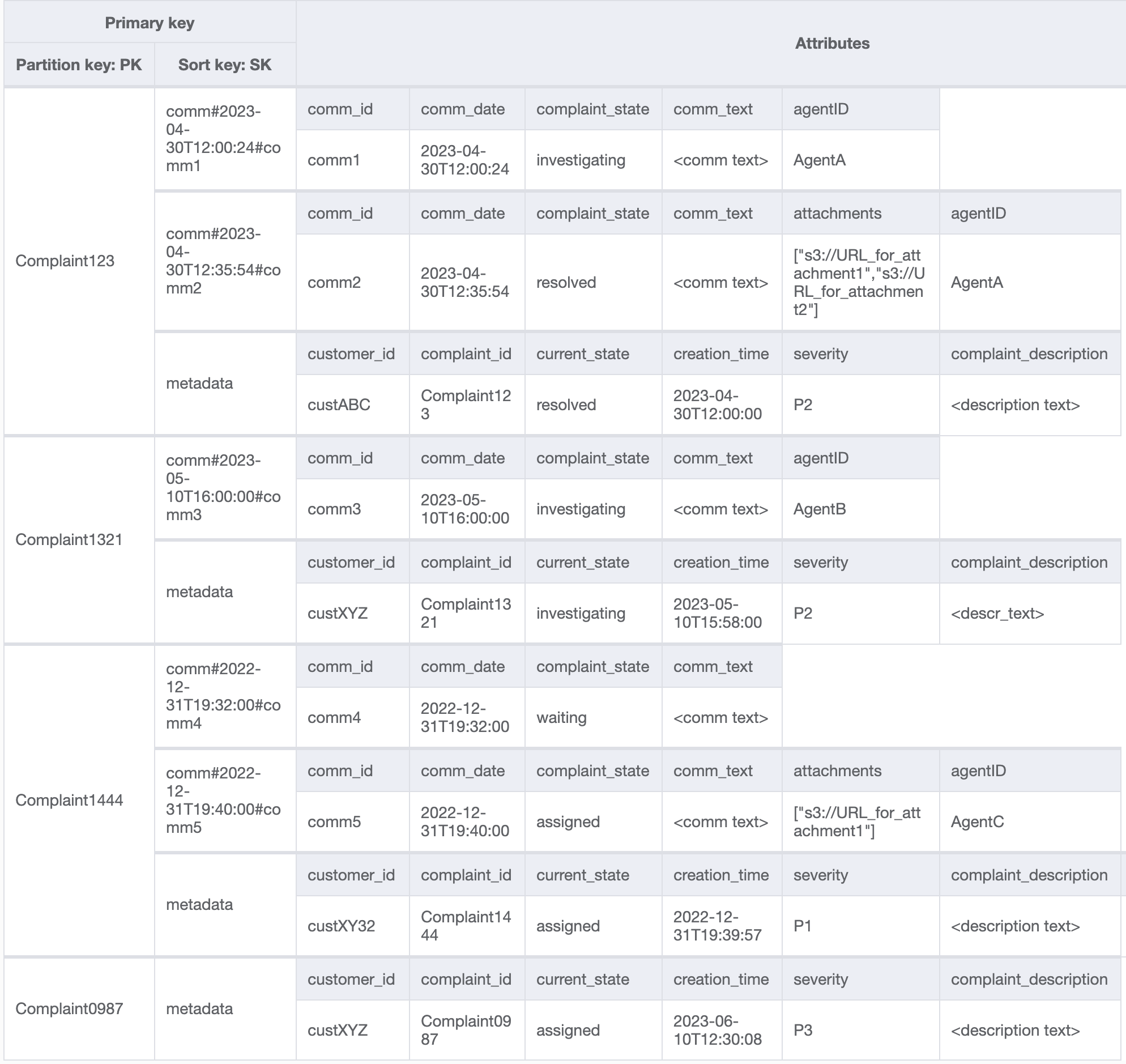
Ajoutons quelques données supplémentaires dans la table et ajoutons également ComplaintID sous la forme d’un champ distinct de notre PK pour pérenniser le modèle au cas où nous aurions besoin d’index supplémentaires sur ComplaintID. Notez également que certains commentaires peuvent contenir des pièces jointes que nous stockerons dans Amazon Simple Storage Service et conserverons uniquement leurs références ou URLs dans DynamoDB. Dans un souci d’optimisation des coûts et des performances, il est recommandé de garder la base de données transactionnelle aussi légère que possible. Les données ressemblent désormais à ceci :

Étape 3 : Traitement des modèles d’accès 6 (getAllCommentsByComplaintID) et 7 (getLatestCommentByComplaintID)
Pour obtenir tous les commentaires relatifs à une réclamation, nous pouvons utiliser l’opération de requête (query) avec la condition begins_with au niveau de la clé de tri. Plutôt que de consommer de la capacité de lecture supplémentaire pour lire l’entrée de métadonnées et d’avoir à filtrer les résultats pertinents, cette condition de clé de tri nous permet de lire uniquement ce dont nous avons besoin. Par exemple, une opération de requête avec PK=Complaint123 et SK begins_with comm# renverrait ce qui suit tout en ignorant l’entrée de métadonnées :

Puisque nous avons besoin du commentaire le plus récent concernant une réclamation du modèle 7 (getLatestCommentByComplaintID), utilisons deux paramètres de requête supplémentaires :
-
ScanIndexForwarddoit être défini sur False pour que les résultats soient triés par ordre décroissant -
Limitdoit être défini sur 1 pour obtenir le commentaire (unique) le plus récent
Comme pour le modèle d’accès 6 (getAllCommentsByComplaintID), nous ignorons l’entrée de métadonnées en utilisant begins_with comm# comme condition de clé de tri. Vous pouvez désormais exécuter le modèle d'accès 7 sur ce modèle à l'aide de l'opération de requête avec PK=Complaint123 et SK=begins_with comm#ScanIndexForward=False, et Limit 1. L’élément ciblé suivant est renvoyé en résultat :

Ajoutons d’autres données fictives au tableau.
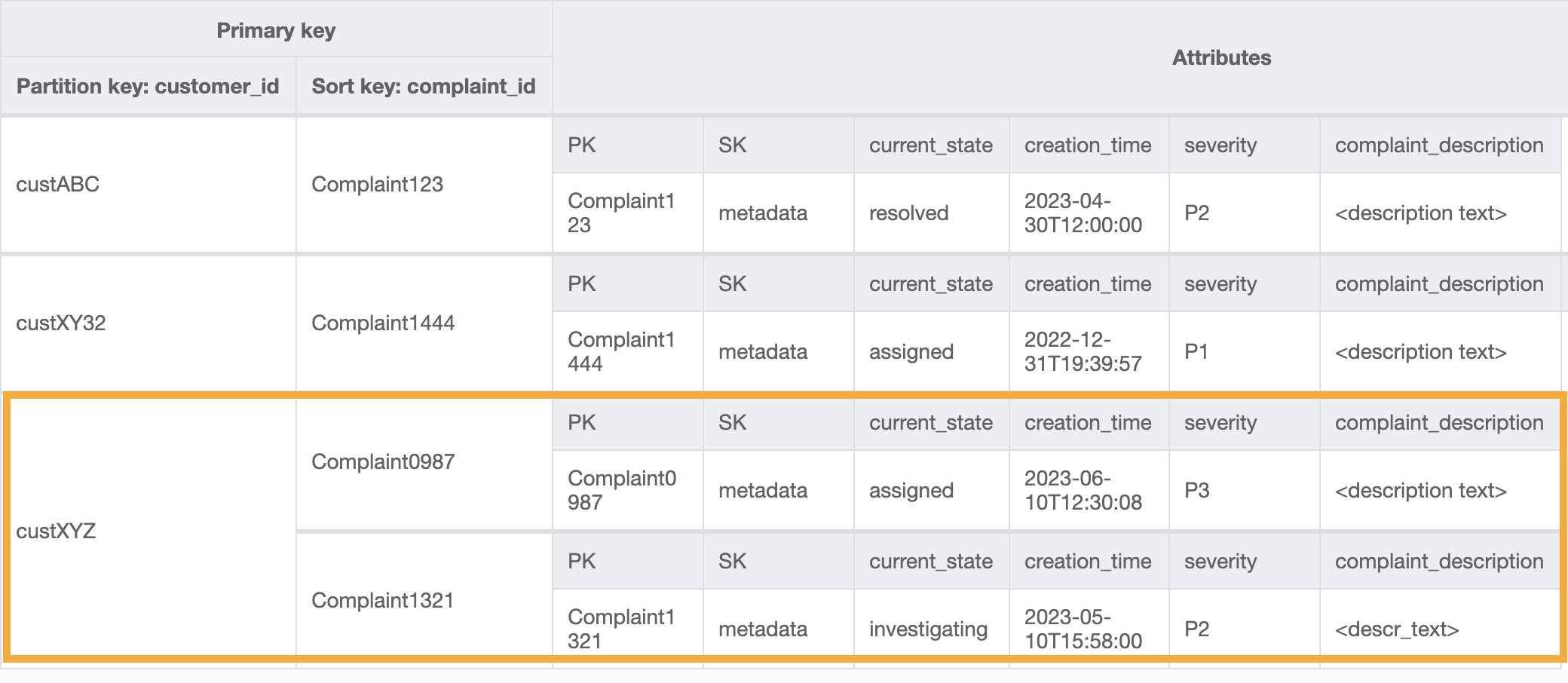
Étape 4 : Traitement des modèles d’accès 8 (getAComplaintbyCustomerIDAndComplaintID) et 9 (getAllComplaintsByCustomerID)
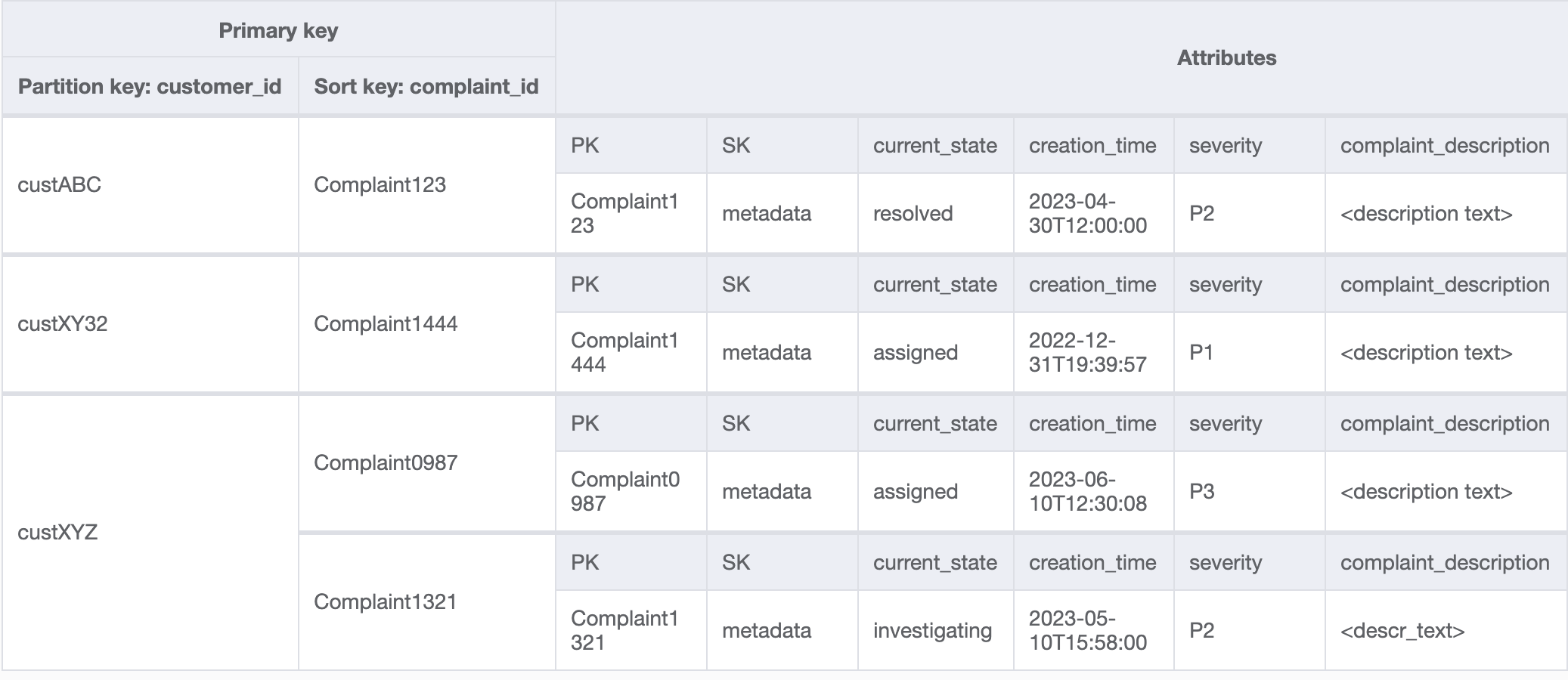
Les modèles d’accès 8 (getAComplaintbyCustomerIDAndComplaintID) et 9 (getAllComplaintsByCustomerID) introduisent un nouveau critère de recherche : CustomerID. Pour le récupérer à partir de la table existante, il faut passer par une opération Scan coûteuse afin de lire toutes les données et filtrer ensuite les éléments pertinents pour le CustomerID en question. Nous pouvons améliorer l’efficacité de cette recherche en créant un index secondaire global (GSI) avec CustomerID comme clé de partition. En tenant compte de la one-to-many relation entre le client et les plaintes ainsi que du modèle d'accès 9 (getAllComplaintsByCustomerID), ComplaintID ce serait le bon candidat pour la clé de tri.
Voici comment se présenteraient les données dans le GSI :
Voici un exemple de requête sur ce GSI pour le modèle d’accès 8 (getAComplaintbyCustomerIDAndComplaintID) : customer_id=custXYZ, sort key=Complaint1321. Le résultat serait le suivant :
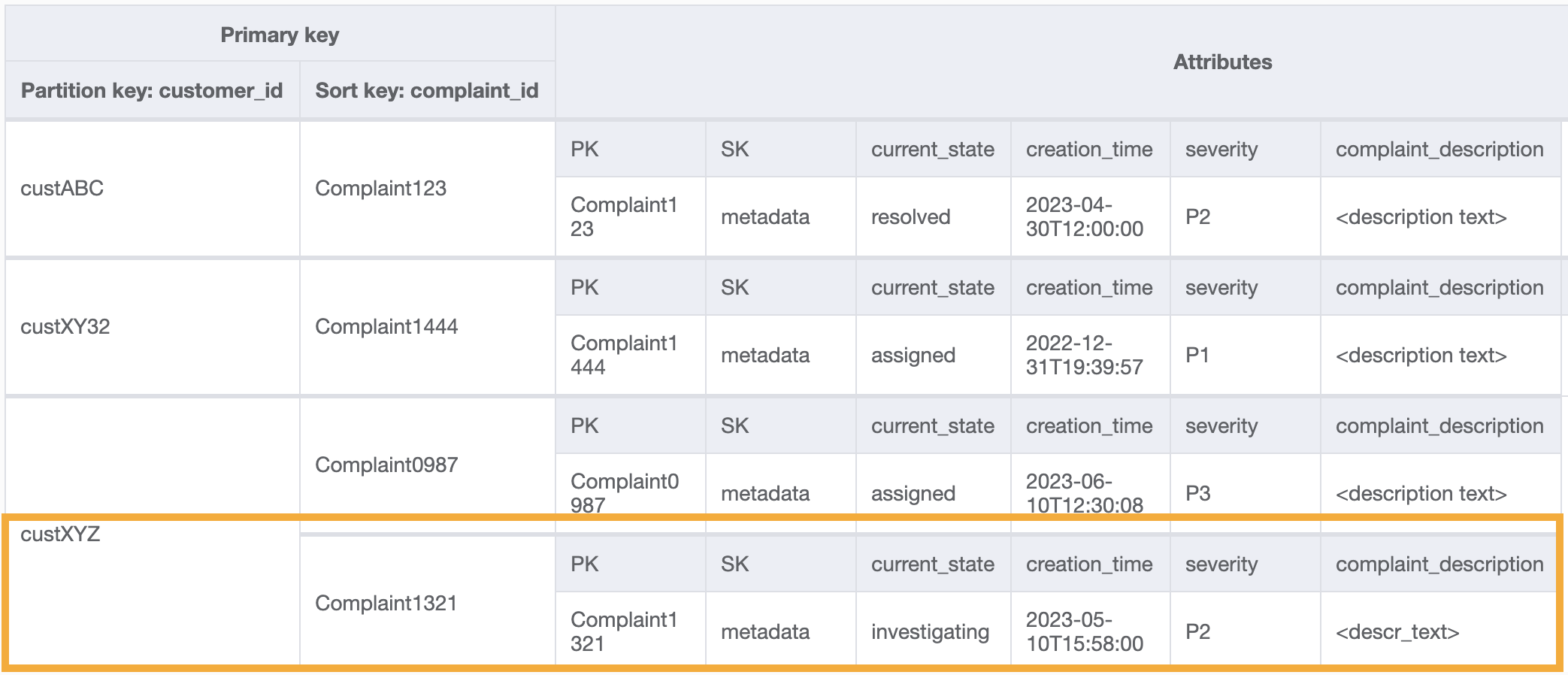
Pour obtenir toutes les réclamations d’un client pour le modèle d’accès 9 (getAllComplaintsByCustomerID), la requête sur le GSI serait customer_id=custXYZ comme condition de clé de partition. Le résultat serait le suivant :
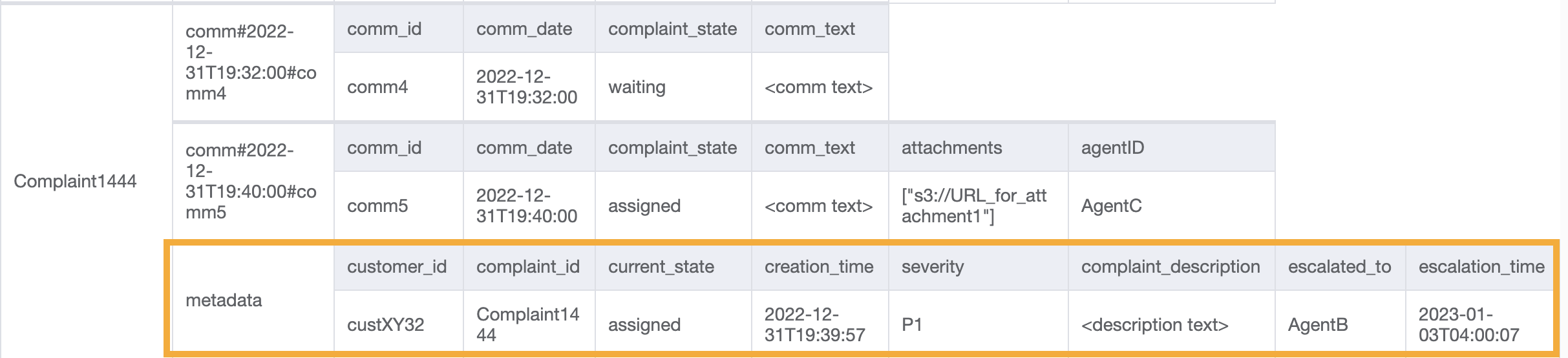
Étape 5 : Traitement du modèle d’accès 10 (escalateComplaintByComplaintID)
Cet accès introduit la notion d’escalade. Pour transmettre une plainte à un échelon supérieur, nous pouvons utiliser UpdateItem pour ajouter des attributs tels que escalated_to et escalation_time à l’élément de métadonnées de réclamation existant. DynamoDB offre une conception de schéma flexible, ce qui signifie qu’un ensemble d’attributs qui ne correspondent pas à une clé peut être uniforme ou discret entre différents éléments. Voici un exemple :
UpdateItem with PK=Complaint1444, SK=metadata
Étape 6 : Traitement des modèles d’accès 11 (getAllEscalatedComplaints) et 12 (getEscalatedComplaintsByAgentID)
Sur l’ensemble complet de données, seules quelques réclamations devraient faire l’objet d’une escalade. Par conséquent, la création d’un index sur les attributs liés à l’escalade aboutirait à des recherches efficaces et à un stockage GSI économique. Pour cela, nous pouvons tirer parti de la technique de l’index fragmenté. Voici à quoi ressemblerait le GSI avec la clé de partition escalated_to et la clé de tri escalation_time :

Pour obtenir toutes les réclamations ayant fait l’objet d’une escalade pour le modèle d’accès 11 (getAllEscalatedComplaints), il nous suffit d’analyser ce GSI. Notez que cette analyse sera performante et économique du fait de la taille du GSI. Pour obtenir les réclamations ayant fait l’objet d’une escalade pour un agent déterminé (modèle d’accès 12 (getEscalatedComplaintsByAgentID)), la clé de partition serait escalated_to=agentID et nous définirions ScanIndexForward sur False pour un ordre de tri du plus récent au plus ancien.
Étape 7 : Traitement du modèle d’accès 13 (getCommentsByAgentID)
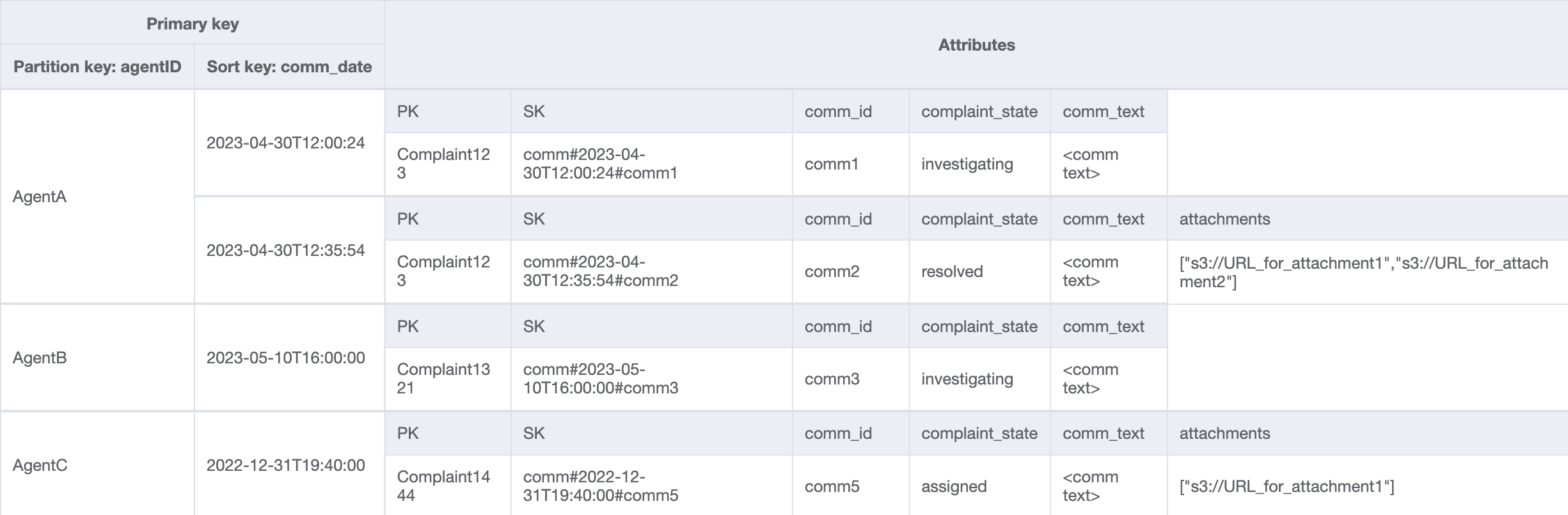
Pour le dernier modèle d’accès, nous devons effectuer une recherche selon une nouvelle dimension : AgentID. Nous avons également besoin d’un ordre chronologique pour lire les commentaires entre deux dates. Nous créons donc un GSI avec agent_id comme clé de partition et comm_date comme clé de tri. Voici comment se présentent les données dans ce GSI :
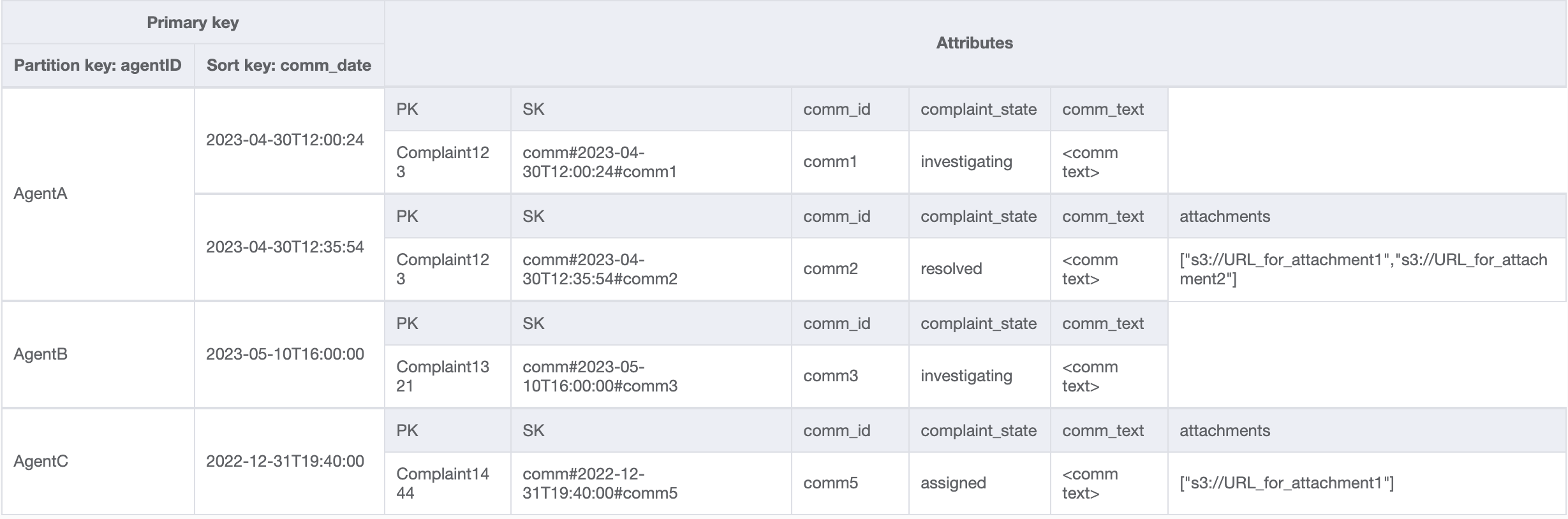
Voici un exemple de requête sur ce GSI : partition key agentID=AgentA et sort key=comm_date between (2023-04-30T12:30:00, 2023-05-01T09:00:00), et en voici le résultat :
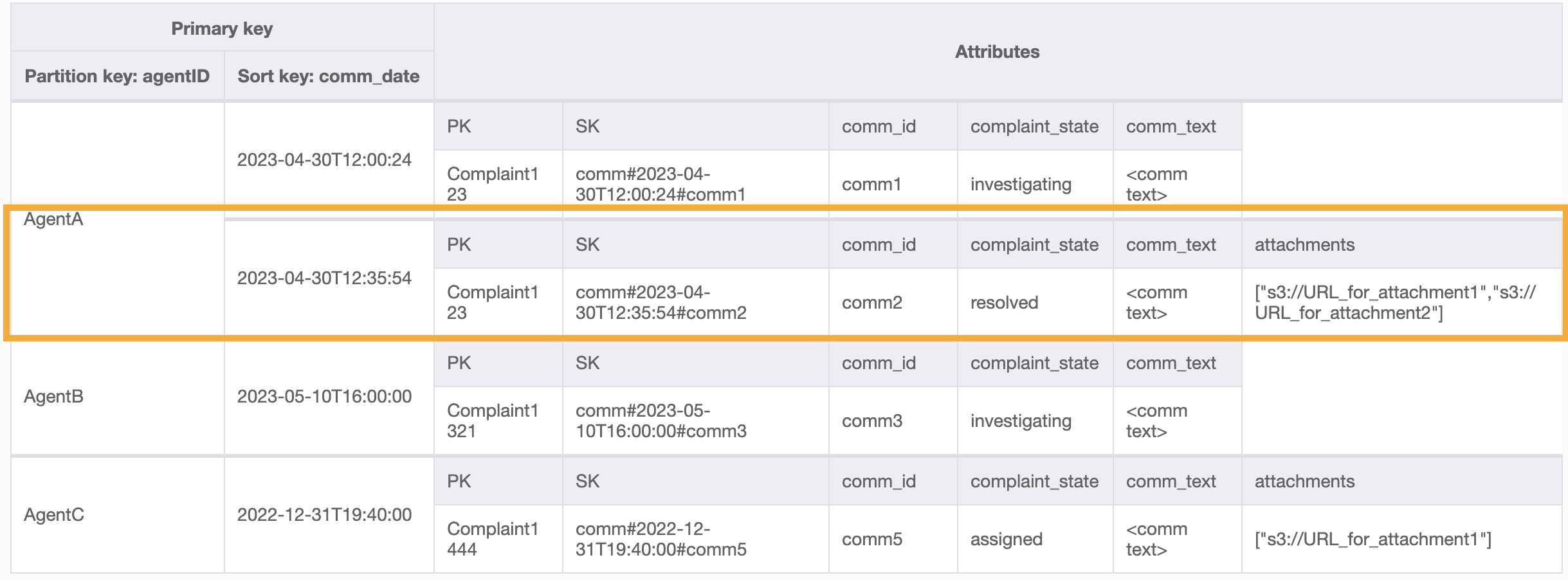
Tous les modèles d’accès et la façon dont ils sont traités par la conception du schéma sont résumés dans le tableau ci-dessous :
| Modèle d’accès | table/GSI/LSI de base | Opération | Valeur de la clé de partition | Valeur de clé de tri | Autres conditions/filtres |
|---|---|---|---|---|---|
| createComplaint | Table de base | PutItem | PK=complaint_id | SK=metadata | |
| updateComplaint | Table de base | UpdateItem | PK=complaint_id | SK=metadata | |
| updateSeveritybyComplaintID | Table de base | UpdateItem | PK=complaint_id | SK=metadata | |
| getComplaintByID de plainte | Table de base | GetItem | PK=complaint_id | SK=metadata | |
| addCommentByID de plainte | Table de base | TransactWriteItems | PK=complaint_id | SK=metadata, SK=comm#comm_date#comm_id | |
| getAllCommentsByComplaintID | Table de base | Query | PK=complaint_id | SK begins_with "comm#" | |
| getLatestCommentByComplaintID | Table de base | Query | PK=complaint_id | SK begins_with "comm#" | scan_index_forward=False, Limit 1 |
| obtenir un identifiant de IDAnd plainte AComplaintby du client | Customer_complaint_GSI | Query | customer_id=customer_id | complaint_id = complaint_id | |
| getAllComplaintsByCustomerID | Customer_complaint_GSI | Query | customer_id=customer_id | N/A | |
| escalateComplaintByID de plainte | Table de base | UpdateItem | PK=complaint_id | SK=metadata | |
| getAllEscalatedRéclamations | Escalations_GSI | Analyser | N/A | N/A | |
| getEscalatedComplaintsByAgentID (ordre du plus récent au plus ancien) | Escalations_GSI | Query | escalated_to=agent_id | N/A | scan_index_forward=False |
| getCommentsByAgentID (entre deux dates) | Agents_Comments_GSI | Query | agent_id=agent_id | SK between (date1, date2) |
Schéma final du système de gestion des réclamations
Voici les conceptions du schéma final. Pour télécharger cette conception de schéma sous forme de fichier JSON, consultez les exemples DynamoDB
Table de base

Customer_Complaint_GSI
Escalations_GSI

Agents_Comments_GSI
Utilisation de NoSQL Workbench avec cette conception de schéma
Vous pouvez importer ce schéma final dans NoSQL Workbench, un outil visuel qui fournit des fonctionnalités de modélisation des données, de visualisation des données et de développement des requêtes pour DynamoDB, afin d’explorer et de modifier davantage votre nouveau projet. Pour commencer, procédez comme suit :
-
Téléchargez NoSQL Workbench. Pour de plus amples informations, veuillez consulter Télécharger NoSQL Workbench pour DynamoDB.
-
Téléchargez le fichier de schéma JSON répertorié ci-dessus, qui est déjà au format du modèle NoSQL Workbench.
-
Importez le fichier de schéma JSON dans NoSQL Workbench. Pour de plus amples informations, veuillez consulter Importation d’un modèle de données existant.
-
Une fois que vous l’avez importé dans NoSQL Workbench, vous pouvez modifier le modèle de données. Pour de plus amples informations, veuillez consulter Modification d’un modèle de données existant.
