Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation d’un partitionnement d’écriture d’index secondaire global pour des requêtes de table sélectives dans DynamoDB
Lorsque vous devez interroger des données récentes dans un intervalle de temps spécifique, l’exigence pour DynamoDB de fournir une clé de partition pour la plupart des opérations de lecture peut constituer un défi. Pour résoudre ce scénario, vous pouvez mettre en œuvre un modèle de requête efficace en combinant le partitionnement en écriture et un index secondaire global (GSI).
Cette approche vous permet d’extraire et d’analyser efficacement les données urgentes sans effectuer une analyse complète des tables, qui peut être gourmande en ressources et coûteuses. En concevant de manière stratégique la structure et l’indexation de votre table, vous pouvez créer une solution flexible qui prend en charge l’extraction de données basée sur le temps, tout en maintenant des performances optimales.
Rubriques
Conception de modèle
Lorsque vous utilisez DynamoDB, vous pouvez surmonter les difficultés liées à l’extraction de données basée sur le temps en mettant en œuvre un modèle sophistiqué qui combine le partitionnement en écriture et les index secondaires globaux, afin de permettre des requêtes flexibles et efficaces dans les fenêtres de données récentes.
Structure de la table
Clé de partition (PK) : « Nom d’utilisateur »
Structure du GSI
Clé de partition GSI (PK_GSI) : « # » ShardNumber
Clé de tri GSI (SK_GSI) : horodatage ISO 8601 (par exemple, « 2030-04-01 ») T12:00:00Z

Stratégie de partition
En supposant que vous décidiez d’utiliser 10 partitions, le nombre de vos partitions peut être compris entre 0 et 9. Lorsque vous enregistrez une activité, vous devez calculer le nombre de partitions (par exemple, en utilisant une fonction de hachage sur l’ID utilisateur, puis en prenant le module du nombre de partitions) et l’ajouter à la clé de partition GSI. Cette méthode répartit les entrées sur différentes partitions, réduisant ainsi le risque de partition chaude.
Interrogation du GSI partitionné
L’interrogation de toutes les partitions à la recherche d’éléments se situant dans un intervalle de temps donné dans une table DynamoDB, où les données sont réparties entre plusieurs clés de partition, nécessite une approche différente de celle utilisée pour interroger une seule partition. Les requêtes DynamoDB étant limitées à une seule clé de partition à la fois, vous ne pouvez pas interroger directement plusieurs partitions en une seule opération de requête. Cependant, vous pouvez obtenir le résultat souhaité grâce à une logique au niveau de l’application en effectuant plusieurs requêtes, chacune ciblant une partition spécifique, puis en agrégeant les résultats. La procédure ci-dessous explique comment procéder.
Pour interroger et agréger des partitions
Identifiez la plage de numéros de partition utilisée dans votre stratégie de mise en partition. Par exemple, si vous avez 10 partitions, le nombre de vos partitions sera compris entre 0 et 9.
Pour chaque partition, construisez et exécutez une requête pour récupérer des éléments dans la plage de temps souhaitée. Ces requêtes peuvent être exécutées en parallèle pour améliorer l’efficacité. Utilisez la clé de partition avec le numéro de partition et la clé de tri, ainsi que votre plage de temps, pour ces requêtes. Voici un exemple de requête pour une seule partition :
aws dynamodb query \ --table-name "YourTableName" \ --index-name "YourIndexName" \ --key-condition-expression "PK_GSI = :pk_val AND SK_GSI BETWEEN :start_date AND :end_date" \ --expression-attribute-values '{ ":pk_val": {"S": "ShardNumber#0"}, ":start_date": {"S": "2024-04-01"}, ":end_date": {"S": "2024-04-30"} }'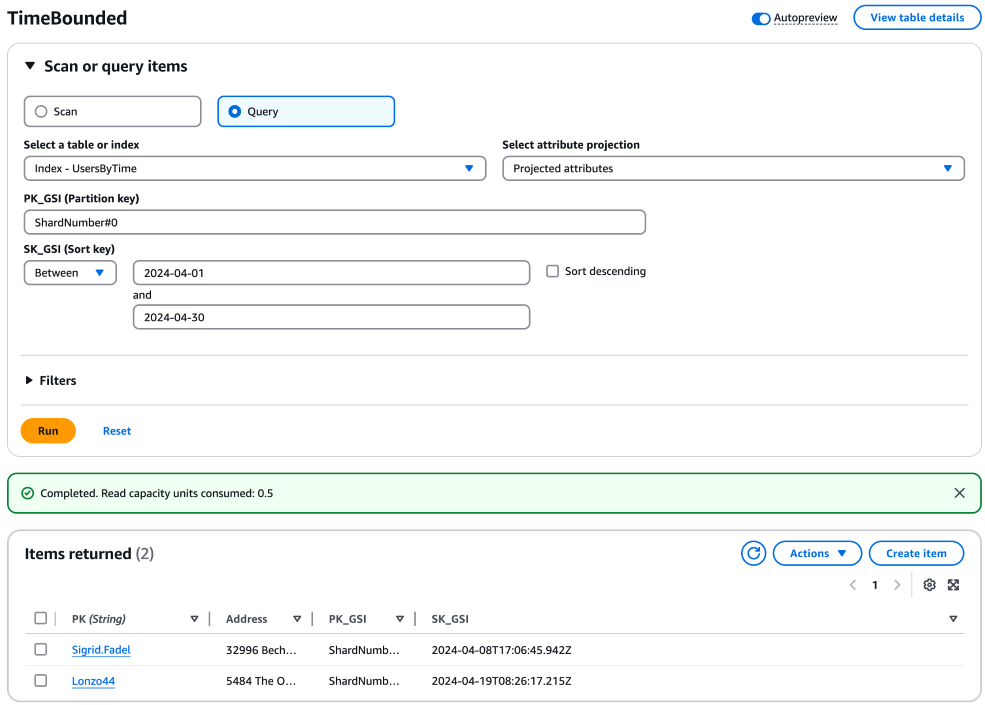
Vous devez répliquer cette requête pour chaque partition, en ajustant la clé de partition en conséquence (par exemple, "ShardNumber#1 «," ShardNumber #2 «,...," ShardNumber #9 «).
Agrégez les résultats de chaque requête une fois que toutes sont terminées. Effectuez cette agrégation dans le code de votre application, en combinant les résultats dans un jeu de données unique qui représente les éléments de toutes les partitions dans la plage de temps spécifiée.
Considérations relatives à l’exécution parallèle des requêtes
Chaque requête consomme la capacité de lecture de votre table ou de votre index. Si vous utilisez le débit provisionné, assurez-vous que votre table est dotée d’une capacité suffisante pour gérer le débordement de requêtes parallèles. Si vous utilisez une capacité à la demande, soyez conscient des implications financières potentielles.
Exemple de code
Pour exécuter des requêtes parallèles sur des partitions dans DynamoDB à l’aide de Python, vous pouvez utiliser la bibliothèque boto3, qui est le kit SDK Amazon Web Services pour Python. Cet exemple suppose que boto3 est installé et configuré avec les informations d'identification appropriées AWS .
Le code Python suivant montre comment effectuer des requêtes parallèles sur plusieurs partitions pour une plage de temps donnée. Il utilise des contrats à terme simultanés pour exécuter des requêtes en parallèle, réduisant ainsi le temps d’exécution global par rapport à une exécution séquentielle.
import boto3 from concurrent.futures import ThreadPoolExecutor, as_completed # Initialize a DynamoDB client dynamodb = boto3.client('dynamodb') # Define your table name and the total number of shards table_name = 'YourTableName' total_shards = 10 # Example: 10 shards numbered 0 to 9 time_start = "2030-03-15T09:00:00Z" time_end = "2030-03-15T10:00:00Z" def query_shard(shard_number): """ Query items in a specific shard for the given time range. """ response = dynamodb.query( TableName=table_name, IndexName='YourGSIName', # Replace with your GSI name KeyConditionExpression="PK_GSI = :pk_val AND SK_GSI BETWEEN :date_start AND :date_end", ExpressionAttributeValues={ ":pk_val": {"S": f"ShardNumber#{shard_number}"}, ":date_start": {"S": time_start}, ":date_end": {"S": time_end}, } ) return response['Items'] # Use ThreadPoolExecutor to query across shards in parallel with ThreadPoolExecutor(max_workers=total_shards) as executor: # Submit a future for each shard query futures = {executor.submit(query_shard, shard_number): shard_number for shard_number in range(total_shards)} # Collect and aggregate results from all shards all_items = [] for future in as_completed(futures): shard_number = futures[future] try: shard_items = future.result() all_items.extend(shard_items) print(f"Shard {shard_number} returned {len(shard_items)} items") except Exception as exc: print(f"Shard {shard_number} generated an exception: {exc}") # Process the aggregated results (e.g., sorting, filtering) as needed # For example, simply printing the count of all retrieved items print(f"Total items retrieved from all shards: {len(all_items)}")
Avant d’exécuter ce code, assurez-vous de remplacer YourTableName et YourGSIName par les noms de table et de GSI de votre configuration DynamoDB. Ajustez également les variables total_shards, time_start et time_end en fonction de vos besoins spécifiques.
Ce script interroge chaque partition à la recherche d’éléments dans la plage de temps spécifiée et agrège les résultats.
