Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation d’index secondaire globaux pour les requêtes de regroupement matérialisé dans DynamoDB
La gestion des regroupements et des métriques clés presque en temps réel sur des données qui changent rapidement s’avère de plus en plus utile que les entreprises puissent prendre des décisions rapides. Par exemple, une bibliothèque musicale peut vouloir présenter ses chansons les plus téléchargées en temps quasi réel, ou une plateforme de commerce électronique peut avoir besoin d'afficher les produits tendance par catégorie.
DynamoDB ne prenant pas en charge de manière native les opérations d'agrégation SUM telles que COUNT ou entre des éléments, le calcul de ces valeurs au moment de la lecture nécessiterait de scanner un grand nombre d'éléments, ce qui peut être lent et coûteux. Au lieu de cela, vous pouvez précalculer les agrégations à mesure que les données changent et stocker les résultats sous forme d'éléments réguliers dans votre tableau. Ce modèle est appelé agrégation matérialisée.
Rubriques
Exemple de scénario et de modèles d'accès
Envisagez une application de bibliothèque musicale répondant aux exigences suivantes :
L'application enregistre les téléchargements de chansons individuelles à un volume élevé (des milliers par seconde).
Les utilisateurs doivent voir les chansons les plus téléchargées pendant un mois donné avec une latence d'un chiffre en millisecondes.
L'application doit également prendre en charge des requêtes telles que « les 10 meilleures chansons du mois » et « toutes les chansons téléchargées au cours d'un mois donné ».
Calculer le nombre de téléchargements au moment de la lecture en scannant tous les enregistrements de téléchargement peut s'avérer coûteux à cette échelle. Au lieu de cela, vous pouvez maintenir un nombre cumulé qui se met à jour à chaque téléchargement et le stocker de manière à permettre des requêtes efficaces.
Pourquoi précalculer les agrégations
Il existe plusieurs approches pour calculer les agrégations. Le tableau suivant compare les alternatives les plus courantes et explique pourquoi l'agrégation matérialisée dans DynamoDB est souvent la meilleure solution pour ce type de cas d'utilisation.
| Approche | Compromis | Quand l’utiliser |
|---|---|---|
| Numériser et compter au moment de la lecture | Nécessite la lecture de tous les enregistrements de téléchargement pour chaque requête. La latence augmente avec le volume de données et consomme une capacité de lecture importante. | Convient uniquement aux très petits ensembles de données où la latence n'est pas un problème. |
| Boutique d'agrégation externe (par exemple, Amazon ElastiCache) | Renforce la complexité opérationnelle grâce à un service distinct à gérer. Nécessite une logique de synchronisation entre DynamoDB et le cache. | Lorsque vous avez besoin de lectures inférieures à la milliseconde ou d'une logique d'agrégation complexe qui va au-delà des simples comptages. |
| Application-level agrégation à l'écriture | Couple la logique d'agrégation au chemin d'écriture. Si l'application échoue après avoir enregistré le téléchargement mais avant de mettre à jour le décompte, l'agrégation devient incohérente. | Lorsque vous avez besoin d'une agrégation synchrone et hautement cohérente et que vous pouvez tolérer une latence d'écriture accrue. |
| Agrégation matérialisée avec Streams et Lambda | Découple l'agrégation du chemin d'écriture. L'agrégation est finalement cohérente (généralement quelques secondes de retard). Ajoute les coûts d'invocation Lambda. | Lorsque vous avez besoin d'agrégations en temps quasi réel avec une faible latence de lecture et que vous pouvez tolérer une éventuelle cohérence. Il s'agit de l'approche décrite sur cette page. |
L'approche d'agrégation matérialisée simplifie le chemin d'écriture (il suffit d'enregistrer le téléchargement), décharge l'agrégation vers un processus asynchrone et stocke le résultat dans DynamoDB où il peut être interrogé avec une latence d'un chiffre en millisecondes.
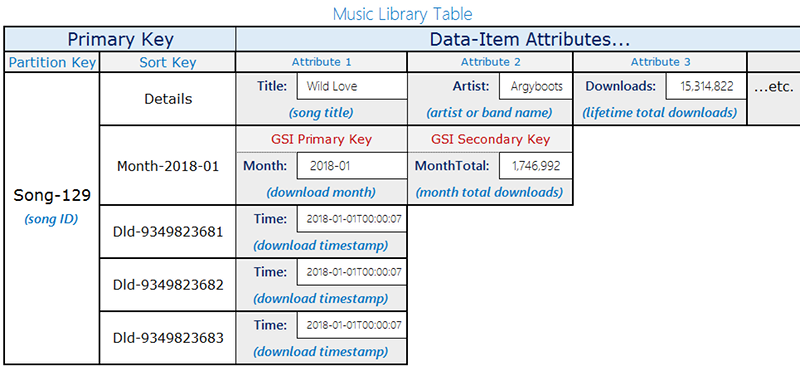
Conception d’une table
Cette conception utilise une seule table avec deux types d'éléments qui partagent la même clé de partition (songID) mais utilisent des modèles de clés de tri différents pour les distinguer :
Enregistrements de téléchargement — Événements de téléchargement individuels. La clé de tri est le
DownloadID(un identifiant unique pour chaque téléchargement).Éléments d'agrégation mensuels : nombre de Pre-computed téléchargements par chanson et par mois. La clé de tri est le
YYYY-MMformat du mois (par exemple,2018-01). Ces éléments contiennent également unDownloadCountattribut indiquant le total cumulé.
Seuls les éléments d'agrégation mensuels contiennent l'Monthattribut. Cette distinction est importante pour le design GSI clairsemé décrit plus loin.
Le schéma suivant montre la disposition du tableau avec les deux types d'éléments :
| Type d'élément | Clé de partition (SongID) | Clé de tri | Attributs supplémentaires |
|---|---|---|---|
| Télécharger l'enregistrement | song1 |
download-abc123 |
UserID, Timestamp |
| Agrégation mensuelle | song1 |
2018-01 |
Month=2018-01,
DownloadCount=1,746,992 |
Pipeline d'agrégation avec Streams et AWS Lambda
Le pipeline d'agrégation fonctionne comme suit :
Lorsqu'une chanson est téléchargée, l'application écrit un nouvel élément dans le tableau avec
Partition-Key=songIDetSort-Key=DownloadID.DynamoDB Streams capture cette écriture sous forme d'enregistrement de flux.
Une fonction Lambda, attachée au flux, traite le nouvel enregistrement. Il identifie le mois
songIDet le mois en cours, puis met à jour l'élément d'agrégation mensuel correspondant en incrémentant l'DownloadCountattribut.L'élément d'agrégation mis à jour est ensuite disponible pour être interrogé via le GSI clairsemé.
La fonction Lambda utilise un UpdateItem appel avec une ADD expression pour incrémenter de manière atomique le nombre de téléchargements. Cela permet d'éviter les conditions de course en lecture-modification-écriture :
import boto3 dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('MusicLibrary') def handler(event, context): for record in event['Records']: if record['eventName'] == 'INSERT': new_image = record['dynamodb']['NewImage'] song_id = new_image['songID']['S'] # Derive the month from the download timestamp timestamp = new_image['Timestamp']['S'] month = timestamp[:7] # Extract YYYY-MM table.update_item( Key={ 'songID': song_id, 'SK': month }, UpdateExpression='ADD DownloadCount :inc SET #m = :month', ExpressionAttributeNames={ '#m': 'Month' }, ExpressionAttributeValues={ ':inc': 1, ':month': month } )
Note
Si une exécution Lambda échoue après avoir écrit la valeur d'agrégation mise à jour, l'enregistrement du flux peut être réessayé. Comme l'ADDopération augmente le nombre à chaque exécution, une nouvelle tentative augmente le nombre plusieurs fois pour le même téléchargement, ce qui vous donne une valeur approximative. Pour la plupart des cas d'utilisation des analyses et des classements, cette faible marge d'erreur est acceptable. Si vous avez besoin de chiffres exacts, pensez à ajouter une logique d'idempuissance, par exemple en utilisant une expression de condition qui vérifie si le résultat spécifique DownloadID a déjà été traité.
Conception GSI clairsemée
Pour interroger efficacement les résultats agrégés, créez un index secondaire global avec le schéma de clé suivant :
Clé de partition GSI :
Month(chaîne)Clé de tri GSI :
DownloadCount(Numéro)
Ce GSI est clairsemé car seuls les éléments d'agrégation mensuels contiennent l'Monthattribut. Les enregistrements de téléchargement individuels ne possèdent pas cet attribut, ils sont donc automatiquement exclus de l'index. Cela signifie que le GSI ne contient que les éléments d'agrégation précalculés, soit une petite fraction du total des éléments du tableau.
Un GSI clairsemé présente deux avantages essentiels :
Réduction des coûts : comme seuls les éléments d'agrégation sont répliqués dans l'index, vous consommez beaucoup moins de capacité d'écriture et de stockage par rapport à un index qui inclut tous les éléments de la table.
Requêtes plus rapides : l'index ne contient que les données dont vous avez besoin pour effectuer des requêtes. Les lectures sont donc efficaces et renvoient des résultats avec une latence d'un chiffre en millisecondes.
Pour plus d'informations sur le fonctionnement des index épars, consultez. Tirer profit des index partiellement alloués
Interrogation du GSI
Avec le GSI clairsemé en place, vous pouvez répondre efficacement à plusieurs types de requêtes :
Obtenez la chanson la plus téléchargée au cours d'un mois donné :
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 1
Le paramètre ScanIndexForward permet de false trier les résultats par DownloadCount ordre décroissant et de ne Limit=1 renvoyer que le titre le plus populaire.
Découvrez les 10 meilleures chansons d'un mois donné :
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 10
Téléchargez toutes les chansons au cours d'un mois donné (triées par nombre de téléchargements) :
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false
Considérations
Tenez compte des points suivants lors de la mise en œuvre de ce modèle :
Cohérence éventuelle — Les valeurs d'agrégation sont mises à jour de manière asynchrone via DynamoDB Streams et Lambda. Il y a généralement un délai de quelques secondes entre l'enregistrement d'un téléchargement et la mise à jour de l'agrégation. Cela signifie que le GSI reflète des données en temps quasi réel, et non des données en temps réel.
Concurrence Lambda : si le volume d'écriture de votre table est élevé, plusieurs appels Lambda peuvent tenter de mettre à jour le même élément d'agrégation simultanément. L'
ADDopération atomique gère cela en toute sécurité, mais vous devez surveiller les métriques de simultanéité et de limitation Lambda pour vous assurer que votre fonction peut suivre le flux.Capacité d'écriture GSI : étant donné que le GSI clairsemé ne contient que des éléments d'agrégation, il nécessite une capacité d'écriture nettement inférieure à celle de la table de base. Toutefois, vous devez toujours prévoir une capacité suffisante (ou utiliser le mode à la demande) pour gérer le taux de mises à jour d'agrégation.
Nombre approximatif — Comme indiqué précédemment, les nouvelles tentatives Lambda peuvent entraîner un léger surcomptage des nombres. Pour les cas d'utilisation nécessitant des dénombrements exacts, implémentez des contrôles d'idempotencie dans la fonction Lambda.
