Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Modes d’écriture avec des tables globales DynamoDB
Les tables globales sont toujours actives-actives au niveau de la table. Toutefois, en particulier pour les tables MREC, vous pouvez les traiter comme actives-passives en contrôlant la façon dont vous acheminez les demandes d’écriture. Par exemple, vous pouvez décider d’acheminer les demandes d’écriture vers une seule région afin d’éviter les éventuels conflits d’écriture qui peuvent se produire dans les tables MREC.
Il existe trois principaux modèles d’écriture gérés, comme l’expliquent les trois sections suivantes. Vous devez déterminer quel modèle d’écriture correspond à votre cas d’utilisation. Ce choix affecte la manière dont vous acheminez les demandes, évacuez une région et gérez la reprise après sinistre. Les instructions dans les sections suivantes dépendent du mode d’écriture de votre application.
Mode Écrire dans n’importe quelle région (non primaire)
Le mode Écrire dans n’importe quelle région, illustré dans le diagramme suivant, est entièrement actif-actif et n’impose aucune restriction quant à l’endroit où une écriture peut avoir lieu. Toute région peut accepter une écriture à tout moment. Il s’agit du mode le plus simple, mais il ne peut être utilisé qu’avec certains types d’applications. Ce mode convient à toutes les tables MRSC. Il convient également pour les tables MREC lorsque tous les rédacteurs sont idempotents et peut donc être répété en toute sécurité afin que les opérations d’écriture simultanées ou répétées entre les régions ne soient pas en conflit. Par exemple, lorsqu’un utilisateur met à jour ses coordonnées. Ce mode fonctionne également bien dans un cas particulier d’idempotent, à savoir un jeu de données à ajout uniquement où toutes les écritures sont des insertions uniques sous une clé primaire déterministe. Enfin, ce mode convient pour la MREC lorsque le risque d’écritures conflictuelles est acceptable.
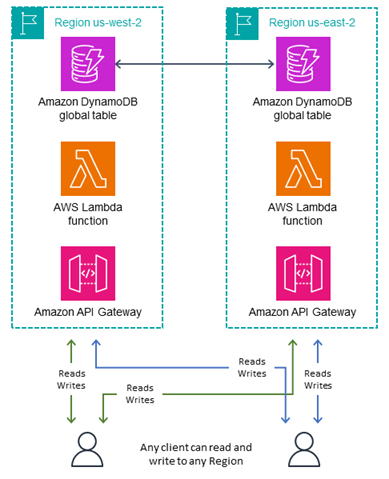
Le mode Écrire dans n’importe quelle région est l’architecture la plus simple à implémenter. Le routage est plus facile car n’importe quelle région peut être la cible d’écriture à tout moment. Le basculement est plus facile, car avec les tables MRSC, les éléments sont toujours synchronisés et toutes les écritures récentes peuvent être rejouées autant de fois que vous le souhaitez dans n’importe quelle région secondaire. Dans la mesure du possible, votre conception doit suivre ce mode d’écriture.
Par exemple, plusieurs services de streaming vidéo utilisent des tables globales pour suivre les favoris, les avis, les indicateurs du statut des visionnages, etc. Ces déploiements utilisent des tables MREC, car ils ont besoin de réplicas dispersés dans le monde entier, chaque réplica fournissant des opérations de lecture et d’écriture à faible latence. Ces déploiements peuvent utiliser l’écriture dans n’importe quelle région, à condition de s’assurer que chaque opération d’écriture est idempotente. C’est le cas si chaque mise à jour (par exemple, la définition d’un nouveau code horaire, l’attribution d’un nouvel avis ou la définition d’un nouveau statut de surveillance) attribue directement le nouvel état à l’utilisateur, et si la prochaine valeur correcte pour un article ne dépend pas de sa valeur actuelle. Si les demandes d’écriture de l’utilisateur sont acheminées vers différentes régions, la dernière opération d’écriture persiste et l’état global est réglé en fonction de la dernière attribution. Les opérations de lecture dans ce mode finissent par devenir cohérentes, après avoir été retardées par la dernière valeur de ReplicationLatency.
Autre exemple : une entreprise de services financiers utilise des tables globales dans le cadre d’un système visant à tenir à jour le décompte des achats par carte de débit pour chaque client, afin de calculer les remises en argent de ce client. Elle veut conserver un article RunningBalance par client. Ce mode d’écriture n’est pas naturellement idempotent, car au fur et à mesure que les transactions entrent, elles modifient l’équilibre en utilisant une expression ADD dans laquelle la nouvelle valeur correcte dépend de la valeur actuelle. En utilisant les tables MRSC, elles peuvent toujours écrire dans n’importe quelle région, car chaque appel ADD fonctionne toujours en fonction de la toute dernière valeur de l’article.
Un troisième exemple concerne une entreprise qui fournit des services de placement d’annonces en ligne. Cette entreprise a décidé qu’un faible risque de perte de données serait acceptable pour simplifier la conception du mode Écrire dans n’importe quelle région. Lorsqu’elle diffuse des publicités, elle ne dispose que de quelques millisecondes pour extraire suffisamment de métadonnées afin de déterminer la publicité à diffuser, puis enregistrer l’impression publicitaire afin que celle-ci ne soit pas répétée trop rapidement. Elle utilise des tables globales pour obtenir à la fois des opérations de lecture à faible latence pour les utilisateurs finaux du monde entier et des opérations d’écriture à faible latence. Elle enregistre toutes les impressions publicitaires d’un utilisateur au sein d’un seul élément, qui est représenté sous la forme d’une liste croissante. Elle utilise un seul élément au lieu de l’ajouter à une collection d’éléments, car elle peut ainsi supprimer les anciennes impressions publicitaires à chaque opération d’écriture sans avoir à payer une opération de suppression. Cette opération d’écriture n’est pas idempotente : si le même utilisateur final voit des publicités diffusées dans plusieurs régions à peu près au même moment, il est possible qu’une opération d’écriture pour une impression publicitaire remplace l’autre. Le risque est qu’un utilisateur voie une publicité se répéter de temps en temps. L’entreprise a décidé que cette situation était acceptable.
Écrire dans une région (primaire unique)
Le mode Écrire dans une région, illustré dans le diagramme suivant, est actif-passif et achemine toutes les écritures de table vers une seule région active. Notez que DynamoDB n’a pas la notion de région active unique ; le routage des applications en dehors de DynamoDB gère cela. Le mode Écrire dans une région est efficace pour les tables MREC qui doivent éviter les conflits d’écriture, en garantissant que les opérations d’écriture ne circulent que vers une région à la fois. Ce mode d’écriture est utile lorsque vous souhaitez utiliser des expressions conditionnelles et que vous ne pouvez pas utiliser la MRSC pour une raison quelconque, ou lorsque vous devez effectuer des transactions. Ces expressions ne sont possibles que si vous savez que vous agissez sur la base des données les plus récentes. Elles nécessitent donc d’envoyer toutes les demandes d’écriture vers une seule région disposant des données les plus récentes.
Lorsque vous utilisez une table MRSC, vous pouvez choisir d’écrire généralement vers une région pour des raisons de commodité. Par exemple, cela peut aider à minimiser le développement de votre infrastructure au-delà de DynamoDB. Le mode d’écriture resterait l’écriture dans n’importe quelle région, car avec la MRSC, vous pouvez écrire en toute sécurité dans n’importe quelle région à tout moment sans vous soucier de la résolution des conflits, ce qui obligerait les tables MREC à choisir d’écrire dans une région.
Les lectures éventuellement cohérentes peuvent aller vers n’importe quelle région de réplica pour réduire les latences. Les lectures fortement cohérentes doivent aller dans la seule région principale.
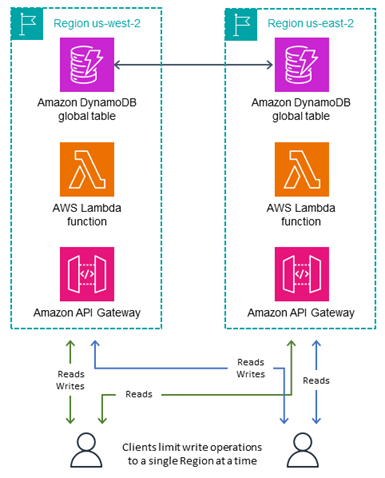
Il est parfois nécessaire de modifier la région active en réponse à une défaillance régionale. Certains utilisateurs modifient la région actuellement active selon un calendrier régulier, par exemple en mettant en œuvre un déploiement 24 h/24. Cela place la région active à proximité de la zone géographique la plus active (généralement là où il fait jour, d’où son nom), ce qui se traduit par les opérations de lecture et d’écriture avec le plus faible temps de latence. Il présente également l'avantage d'appeler le Region-changing code tous les jours et de s'assurer qu'il est bien testé avant toute reprise après sinistre.
La ou les régions passives peuvent conserver un ensemble réduit d’infrastructures autour de DynamoDB, qui ne se développe que si la région devient active. Ce guide ne couvre pas les modèles veilleuse et secours semi-automatique. Pour plus d'informations, voir Architecture de reprise après sinistre (DR) activée AWS, partie III : veilleuse et mode veille
L’utilisation du mode Écrire dans une région fonctionne bien lorsque vous utilisez des tables globales pour des opérations de lecture distribuées à l’échelle mondiale à faible latence. Prenons l’exemple d’une grande entreprise de médias sociaux qui doit disposer des mêmes données de référence dans toutes les régions du monde. Elle ne met pas souvent à jour les données, mais lorsqu’elle le fait, elle n’écrit que dans une seule région afin d’éviter tout conflit d’écriture potentiel. Les opérations de lecture sont toujours autorisées dans toutes les régions.
Autre exemple : le client du secteur des services financiers dont nous avons parlé précédemment, et qui a mis en œuvre le calcul de remise en argent quotidien. Il a utilisé le mode Écrire dans n’importe quelle région pour calculer le solde, mais aussi le mode Écrire dans une région pour suivre les paiements. Ce travail nécessite des transactions, qui ne sont pas prises en charge dans les tables MRSC. Il fonctionne donc mieux avec une table MREC séparée et le mode Écrire dans une région.
Écrire dans votre région (primaire mixte)
Le mode d’écriture Écrire dans votre région, illustré dans le schéma suivant, fonctionne avec les tables MREC. Il attribue différents sous-ensembles de données aux différentes régions d’origine et autorise les opérations d’écriture sur un élément uniquement via sa région d’origine. Ce mode est actif-passif, mais assigne la région active en fonction de l’élément. Chaque région est primaire pour son propre jeu de données qui ne se chevauche pas et les opérations d’écriture doivent être protégées pour garantir une localisation correcte.
Ce mode est similaire à Écrire dans une région, sauf qu’il permet des opérations d’écriture à faible latence, car les données associées à chaque utilisateur peuvent être placées dans un réseau plus près de cet utilisateur. Cela permet également de répartir l’infrastructure environnante de manière plus uniforme entre les régions et de réduire le travail de construction de l’infrastructure lors d’un scénario de basculement, car une partie de l’infrastructure de toutes les régions est déjà active.
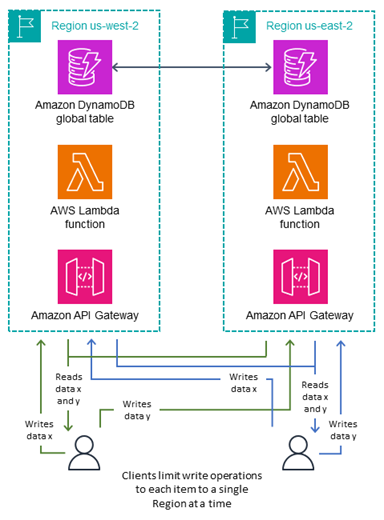
Vous pouvez déterminer la région d’origine des objets de plusieurs manières :
Intrinsèque : certains aspects des données, tels qu’un attribut spécial ou une valeur vectorisée dans leur clé de partition, indiquent clairement leur région d’origine. Cette technique est décrite dans l’article de blog Utiliser l’épinglage des régions pour définir une région d’origine pour les éléments d’une table globale Amazon DynamoDB
. Négocié : la région d’origine de chaque jeu de données est négociée de manière externe, par exemple avec un service global distinct qui gère les attributions. La mission peut avoir une durée limitée, après laquelle elle peut faire l’objet d’une renégociation.
Table-oriented: Au lieu de créer une seule table globale de réplication, vous créez le même nombre de tables globales que les régions de réplication. Le nom de chaque table indique sa région d’origine. Dans les opérations standard, toutes les données sont écrites dans la région d’origine tandis que les autres régions conservent une copie en lecture seule. Lors d’un basculement, une autre région adopte temporairement des fonctions d’écriture pour cette table.
Imaginons que vous travaillez pour une entreprise de jeux vidéo. Vous avez besoin d’opérations de lecture et d’écriture à faible latence pour tous les joueurs du monde entier. Vous attribuez à chaque joueur la région la plus proche de lui. Cette région prend en charge toutes ses opérations de lecture et d’écriture, garantissant ainsi une forte cohérence de lecture après écriture. Toutefois, lorsqu’un joueur voyage ou si sa région d’origine est en panne, une copie complète de ses données est disponible dans d’autres régions. Le joueur peut alors être attribué à une autre région d’origine.
Autre exemple, imaginez que vous travaillez pour une entreprise de visioconférence. À chaque téléconférence, des métadonnées sont attribuées à une région particulière. Les participants peuvent utiliser la région la plus proche d’eux pour minimiser la latence. En cas de panne d’une région, les tables globales permettent une restauration rapide, car le système peut déplacer le traitement de l’appel vers une autre région où il existe déjà une copie répliquée des données.
Récapitulatif
-
Le mode Écrire dans n’importe quelle région convient aux tables MRSC et aux appels idempotents vers les tables MREC.
-
Le mode Écrire dans une région convient aux appels non idempotents vers les tables MREC.
-
Le mode Écrire dans votre région convient aux appels non idempotents vers les tables MREC, où il est important que les clients écrivent dans une région proche d’eux.
