Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Filtrage des données pour les intégrations zéro ETL Amazon RDS
Les intégrations zéro ETL Amazon RDS prennent en charge le filtrage des données, ce qui vous permet de contrôler quelles données sont répliquées depuis votre base de données Amazon RDS source vers votre entrepôt de données cible. Au lieu de répliquer l’intégralité de la base de données, vous pouvez appliquer un ou plusieurs filtres pour inclure ou exclure des tables spécifiques de manière sélective. Cela vous permet d’optimiser les performances de stockage et de requête en garantissant que seules les données pertinentes sont transférées. Actuellement, le filtrage est limité aux niveaux de base de données et de table. Le filtrage au niveau des colonnes et des lignes n’est pas pris en charge.
Le filtrage des données peut être utile lorsque vous souhaitez :
-
Joindre certaines tables provenant d’au moins deux clusters source différents, et vous n’avez pas besoin de données complètes provenant de l’un ou l’autre des clusters.
-
Réduisez les coûts en effectuant des opérations d’analytique en utilisant uniquement un sous-ensemble de tables plutôt qu’une flotte complète de bases de données.
-
Filtrez les informations sensibles, telles que les numéros de téléphone, les adresses ou les informations de carte de crédit, de certaines tables.
Vous pouvez ajouter des filtres de données à une intégration sans ETL à l' AWS Management Console aide de l' AWS Command Line Interface API,AWS CLI the () ou Amazon RDS.
Si l’intégration a un cluster provisionné comme cible, le cluster doit être sur le correctif 180 ou supérieur pour utiliser le filtrage des données.
Rubriques
Format d’un filtre de données
Vous pouvez définir plusieurs filtres pour une seule intégration. Chaque filtre inclut ou exclut les tables de base de données existantes et futures qui correspondent à l’un des modèles de l’expression du filtre. Les intégrations zéro ETL Amazon RDS utilisent la syntaxe du filtre Maxwell
Chaque filtre contient les éléments suivants :
| Element | Description |
|---|---|
| Type de filtre |
Un type de filtre |
| Expression de filtre |
Une liste de modèles séparée par des virgules. Les expressions doivent utiliser la syntaxe du filtre Maxwell |
| Modèle |
Un modèle de filtre au format NotePour RDS for MySQL, les expressions régulières sont prises en charge à la fois dans le nom de la base de données et dans le nom de la table. Pour RDS pour PostgreSQL, les expressions régulières ne sont prises en charge que dans le schéma et le nom de la table, et non dans le nom de la base de données. Vous ne pouvez pas inclure de filtres ou de listes de refus au niveau des colonnes. Une intégration unique peut avoir un maximum de 99 modèles. Dans la console, vous pouvez saisir des modèles dans une seule expression de filtre ou les répartir entre plusieurs expressions. La longueur d’un modèle unique ne peut pas dépasser 256 caractères. |
Important
Si vous sélectionnez une base de données RDS pour PostgreSQL source, vous devez spécifier au moins un modèle de filtre de données. Le modèle doit au minimum inclure une seule base de données (database-name.*.*
L’image suivante montre la structure des filtres de données RDS for MySQL dans la console :
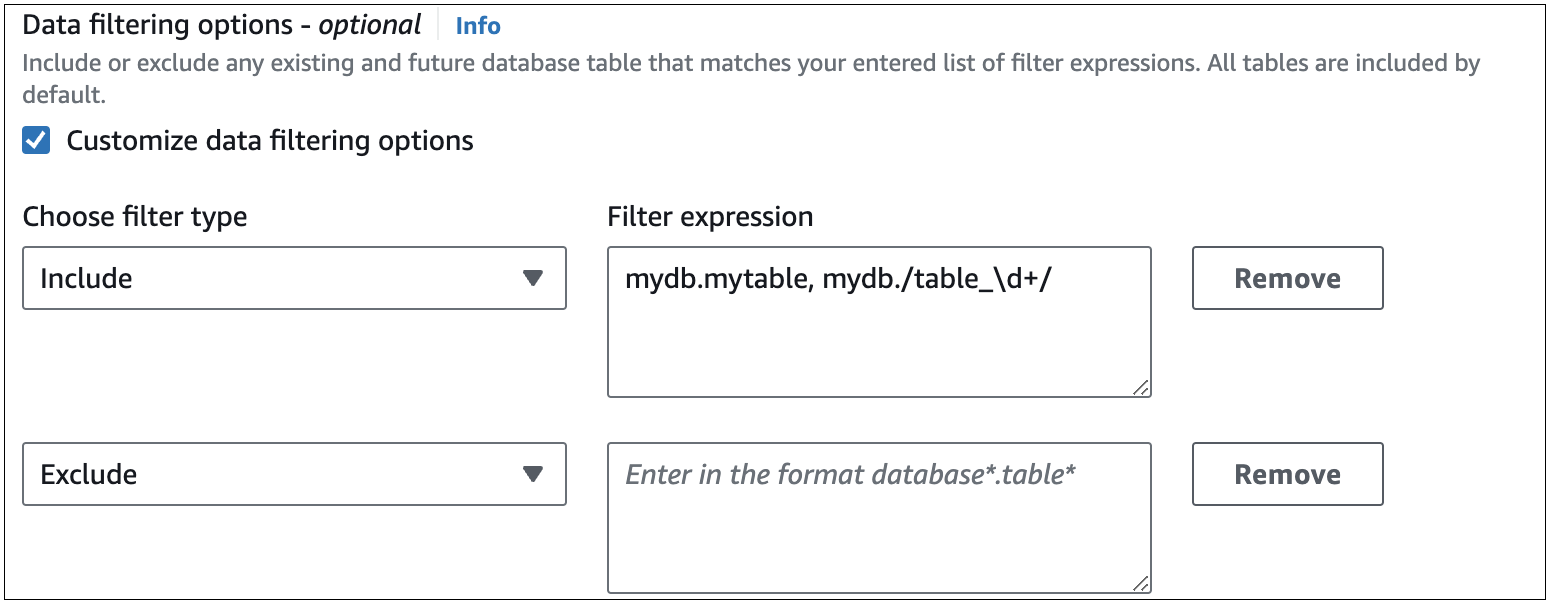
Important
N’incluez pas de données d’identification personnelle, confidentielles ou sensibles dans vos modèles de filtrage.
Filtres de données dans AWS CLI
Lorsque vous utilisez le AWS CLI pour ajouter un filtre de données, la syntaxe est légèrement différente de celle de la console. Vous devez attribuer un type de filtre (Include ou Exclude) à chaque modèle individuellement, afin de ne pas pouvoir regrouper plusieurs modèles sous un même type de filtre.
Par exemple, dans la console, vous pouvez regrouper les modèles suivants, séparés par des virgules, sous une seule instruction Include :
RDS for MySQL
mydb.mytable,mydb./table_\d+/
RDS pour PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
Toutefois, lorsque vous utilisez le AWS CLI, le même filtre de données doit être au format suivant :
RDS for MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
RDS pour PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
Logique de filtrage
Si vous ne spécifiez aucun filtre de données dans votre intégration, Amazon RDS suppose un filtre par défaut de include:*.*, qui réplique toutes les tables dans l’entrepôt de données cible. Toutefois, si vous ajoutez au moins un filtre, la logique par défaut passe à exclude:*.*, ce qui exclut toutes les tables par défaut. Cela vous permet de définir explicitement les bases de données et les tables à inclure dans la réplication.
Par exemple, si vous définissez le filtre suivant :
'include: db.table1, include: db.table2'
Amazon RDS évalue le filtre comme suit :
'exclude:*.*, include: db.table1, include: db.table2'
Par conséquent, Amazon RDS réplique uniquement table1 et table2 depuis la base de données nommée db vers l’entrepôt de données cible.
Ordre de priorité de filtre
Amazon RDS évalue les filtres de données dans l’ordre que vous spécifiez. Dans le AWS Management Console, il traite les expressions de filtre de gauche à droite et de haut en bas. Un second filtre ou un modèle individuel qui suit le premier peut le remplacer.
Par exemple, si le premier filtre est Include books.stephenking, il inclut uniquement la table stephenking de la base de données books. Toutefois, si vous ajoutez un second filtre, Exclude books.*, il remplace le premier filtre. Cela empêche la réplication des tables de l’index books vers l’entrepôt de données cible.
Lorsque vous spécifiez au moins un filtre, la logique commence par l’hypothèse exclude:*.* par défaut, ce qui exclut automatiquement toutes les tables de la réplication. Une bonne pratique consiste à définir des filtres du plus large au plus spécifique. Commencez par une ou plusieurs instructions Include pour spécifier les données à répliquer, puis ajoutez des filtres Exclude pour supprimer certaines tables de manière sélective.
Le même principe s’applique aux filtres que vous définissez à l’aide de l’ AWS CLI. Amazon RDS évalue ces modèles de filtre dans l’ordre dans lequel vous les spécifiez, de sorte qu’un modèle peut remplacer celui que vous avez spécifié avant lui.
Exemples RDS for MySQL
Les exemples suivants montrent comment fonctionne le filtrage des données pour intégrations zéro ETL Exemples RDS for MySQL :
-
Incluez toutes les bases de données et toutes les tables :
'include: *.*' -
Incluez toutes les tables de la base de données
books:'include: books.*' -
Excluez toutes les tables nommées
mystery:'include: *.*, exclude: *.mystery' -
Incluez deux tables spécifiques dans la base de données
books:'include: books.stephen_king, include: books.carolyn_keene' -
Incluez toutes les tables de la base de données
books, à l’exception de celles contenant la sous-chaînemystery:'include: books.*, exclude: books./.*mystery.*/' -
Incluez toutes les tables de la base de données
books, à l’exception de celles commençant parmystery:'include: books.*, exclude: books./mystery.*/' -
Incluez toutes les tables de la base de données
books, à l’exception de celles se terminant parmystery:'include: books.*, exclude: books./.*mystery/' -
Incluez toutes les tables de la base de données
booksqui commencent partable_, à l’exception de celle nomméetable_stephen_king. Par exemple,table_moviesoutable_booksserait répliqué, mais pastable_stephen_king.'include: books./table_.*/, exclude: books.table_stephen_king'
Exemples RDS pour PostgreSQL
Les exemples suivants montrent comment fonctionne le filtrage des données pour intégrations zéro ETL RDS for MySQL :
-
Incluez toutes les tables de la base de données
books:'include: books.*.*' -
Excluez toutes les tables nommées
mysteryde la base de donnéesbooks:'include: books.*.*, exclude: books.*.mystery' -
Incluez une table dans la base de données
booksdans le schémamystery, et une table dans la base de donnéesemployeedans le schémafinance:'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Incluez toutes les tables de la base de données
bookset le schémascience_fiction, à l’exception de celles contenant la sous-chaîneking:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
Incluez toutes les tables de la base de données
books, à l’exception de celles avec un nom de schéma commençant parsci:'include: books.*.*, exclude: books./sci.*/.*' -
Incluez toutes les tables de la base de données
books, à l’exception de celles dans le schémamysteryse terminant parking:'include: books.*.*, exclude: books.mystery./.*king/' -
Incluez toutes les tables de la base de données
booksqui commencent partable_, à l’exception de celle nomméetable_stephen_king. Par exemple,table_moviesdans le schémafictionettable_booksdans le schémamysterysont répliqués, mais pastable_stephen_kingdans l’un ou l’autre des schémas :'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
Exemples de RDS for Oracle
Les exemples suivants montrent comment fonctionne le filtrage des données pour intégrations zéro ETL RDS for Oracle :
-
Incluez toutes les tables de la base de données books :
'include: books.*.*' -
Excluez toutes les tables nommées mystery de la base de données books :
'include: books.*.*, exclude: books.*.mystery' -
Incluez une table dans la base de données books dans le schéma mystery, et une table dans la base de données employee dans le schéma finance :
'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Incluez toutes les tables du schéma mystery dans la base de données books :
'include: books.mystery.*'
Considérations sur la sensibilité à la casse
Oracle Database et Amazon Redshift gèrent la casse des noms d’objets différemment, ce qui affecte à la fois la configuration du filtre de données et les requêtes cibles. Notez ce qui suit :
-
Oracle Database stocke les noms des bases de données, des schémas et des objets en majuscules, sauf s’ils sont explicitement cités dans l’instruction
CREATE. Par exemple, si vous créezmytable(sans guillemets), le dictionnaire de données Oracle enregistre le nom de la table sous la formeMYTABLE. Si vous citez le nom de l’objet, le dictionnaire de données préserve la casse. -
Zero-ETL les filtres de données distinguent les majuscules et minuscules et doivent correspondre exactement aux noms d'objets tels qu'ils apparaissent dans le dictionnaire de données Oracle.
-
Les requêtes Amazon Redshift utilisent par défaut des noms d’objets en minuscules, sauf entre guillemets explicites. Par exemple, une requête
MYTABLE(sans guillemets) recherchemytable.
Tenez compte des différences de casses lorsque vous créez le filtre Amazon Redshift et que vous interrogez les données.
Création d’une intégration en majuscules
Lorsque vous créez une table sans indiquer le nom entre guillemets, la base de données Oracle enregistre le nom en majuscules dans le dictionnaire de données. Par exemple, vous pouvez créer MYTABLE à l’aide de l’une des instructions SQL suivantes.
CREATE TABLE REINVENT.MYTABLE (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reinvent.mytable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE REinvent.MyTable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reINVENT.MYtabLE (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Comme vous n’avez pas cité le nom de la table dans les instructions précédentes, la base de données Oracle enregistre le nom de l’objet en majuscules sous la forme MYTABLE.
Pour répliquer cette table sur Amazon Redshift, vous devez spécifier le nom en majuscules dans le filtre de données de votre commande create-integration. Le nom du Zero-ETL filtre et le nom du dictionnaire de données Oracle doivent correspondre.
aws rds create-integration \ --integration-name upperIntegration \ --data-filter "include: ORCL.REINVENT.MYTABLE" \ ...
Par défaut, Amazon Redshift stocke les données en minuscules. Pour effectuer une requête MYTABLE dans la base de données répliquée dans Amazon Redshift, vous devez citer le nom en majuscules MYTABLE afin qu’il corresponde aux majuscules du dictionnaire de données Oracle.
SELECT * FROM targetdb1."REINVENT"."MYTABLE";
Les requêtes suivantes n’utilisent pas le mécanisme de citation. Ils renvoient tous une erreur, car ils recherchent une table Amazon Redshift nommée mytable, qui utilise le nom en minuscules par défaut, mais la table est nommée MYTABLE dans le dictionnaire de données Oracle.
SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable; SELECT * FROM targetdb1."REINVENT".mytable;
Les requêtes suivantes utilisent le mécanisme de citation pour spécifier un nom composé de majuscules et minuscules. Les requêtes renvoient toutes une erreur, car elles recherchent une table Amazon Redshift dont le nom n’est MYTABLE.
SELECT * FROM targetdb1."REINVENT"."MYtablE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."mytable";
Création d’une intégration en minuscules
Dans l’exemple alternatif suivant, vous utilisez des guillemets pour enregistrer le nom de la table en minuscules dans le dictionnaire de données Oracle. Vous créez mytable comme suit.
CREATE TABLE REINVENT."mytable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
La base de données Oracle enregistre le nom de la table mytable en minuscules. Pour répliquer ce tableau sur Amazon Redshift, vous devez spécifier le mytable nom en minuscules dans votre filtre de données. Zero-ETL
aws rds create-integration \ --integration-name lowerIntegration \ --data-filter "include: ORCL.REINVENT.mytable" \ ...
Lorsque vous interrogez cette table dans la base de données répliquée dans Amazon Redshift, vous pouvez spécifier le nom en minuscules mytable. La requête aboutit, car elle recherche une table nommée mytable, qui est le nom de la table dans le dictionnaire de données Oracle.
SELECT * FROM targetdb1."REINVENT".mytable;
Comme Amazon Redshift utilise par défaut les noms d’objets en minuscules, les requêtes suivantes réussissent également à trouver mytable.
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable;
Les requêtes suivantes n’utilisent pas le mécanisme de citation pour le nom d’objet. Elles renvoient toutes une erreur, car elles recherchent une table Amazon Redshift dont le nom est différent de mytable.
SELECT * FROM targetdb1."REINVENT"."MYTABLE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."MYtablE";
Création d’une table avec intégration en casse mixte
Dans l’exemple suivant, vous utilisez des guillemets pour enregistrer le nom de la table en minuscules dans le dictionnaire de données Oracle. Vous créez MyTable comme suit.
CREATE TABLE REINVENT."MyTable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
La base de données Oracle stocke ce nom de table sous la forme MyTable avec une casse mixte. Pour répliquer cette table sur Amazon Redshift, vous devez spécifier le nom en casse mixte dans le filtre de données.
aws rds create-integration \ --integration-name mixedIntegration \ --data-filter "include: ORCL.REINVENT.MyTable" \ ...
Lorsque vous interrogez cette table dans la base de données répliquée dans Amazon Redshift, vous devez spécifier le nom en casse mixte MyTable en mettant le nom d’objet entre guillemets.
SELECT * FROM targetdb1."REINVENT"."MyTable";
Comme Amazon Redshift utilise par défaut les noms d’objets en minuscules, les requêtes suivantes ne trouvent pas l’objet, car elles recherchent le nom en minuscules mytable.
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".mytable;
Note
Vous ne pouvez pas utiliser d’expressions régulières dans la valeur du filtre pour le nom de base de données, le schéma ou le nom de table dans les intégrations RDS for Oracle.
Ajout de filtres de données à une intégration
Vous pouvez configurer le filtrage des données à l'aide de l' AWS Management Console API AWS CLI, de, ou de l'API Amazon RDS.
Important
Si vous ajoutez un filtre après avoir créé une intégration, Amazon RDS le traite comme s’il avait toujours existé. Il supprime toutes les données de l’entrepôt de données cible qui ne correspondent pas aux nouveaux critères de filtrage et resynchronise toutes les tables concernées.
Pour ajouter des filtres de données à une intégration zéro ETL
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Dans le volet de navigation, sélectionnez Zero-ETL Intégrations. Sélectionnez l’intégration à laquelle vous souhaitez ajouter des filtres de données, puis choisissez Modifier.
-
Sous Source, ajoutez une ou plusieurs instructions
IncludeetExclude.L’image suivante montre un exemple de filtres de données pour une intégration MySQL :
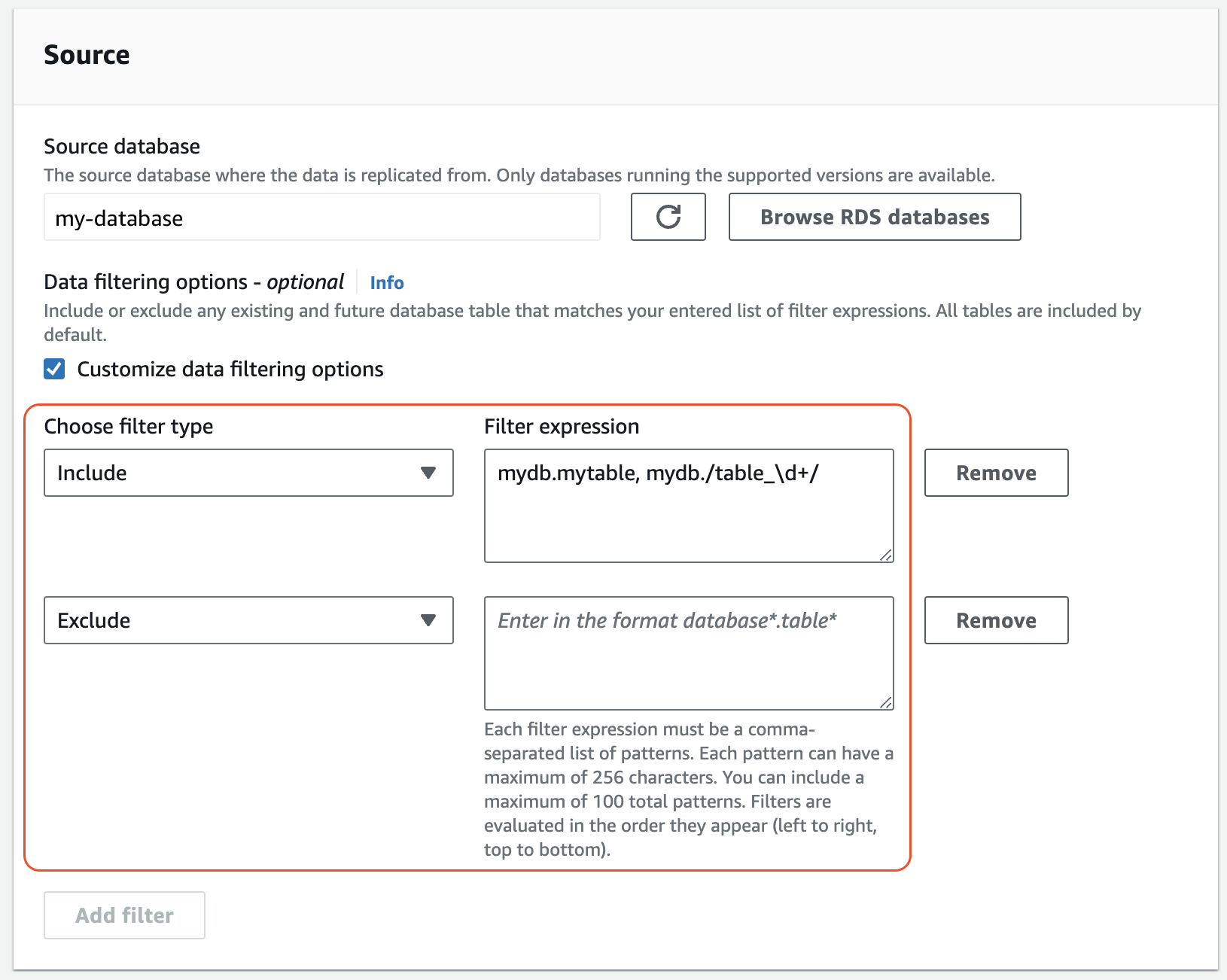
-
Lorsque vous êtes satisfait des modifications, choisissez Continuer et Enregistrer les modifications.
Pour ajouter des filtres de données à une intégration zéro ETL à l'aide de AWS CLI, appelez la commande modify-integration--data-filter à l’aide d’une liste séparée par des virgules de filtres Maxwell Include et Exclude.
Exemple
L’exemple suivant ajoute des modèles de filtre à my-integration.
Pour Linux, macOS ou Unix :
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Pour Windows :
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Pour modifier une intégration zéro ETL à l'aide de l'API RDS, appelez l'ModifyIntegrationopération. Spécifiez l’identifiant d’intégration et fournissez une liste de modèles de filtre séparée par des virgules.
Suppression des filtres de données d’une intégration
Lorsque vous supprimez un filtre de données d’une intégration, Amazon RDS réévalue les filtres restants comme si le filtre supprimé n’avait jamais existé. Il réplique ensuite toutes les données précédemment exclues qui répondent désormais aux critères dans l’entrepôt de données cible. Cela déclenche une resynchronisation de toutes les tables concernées.
