Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Supervision de la réplication en lecture
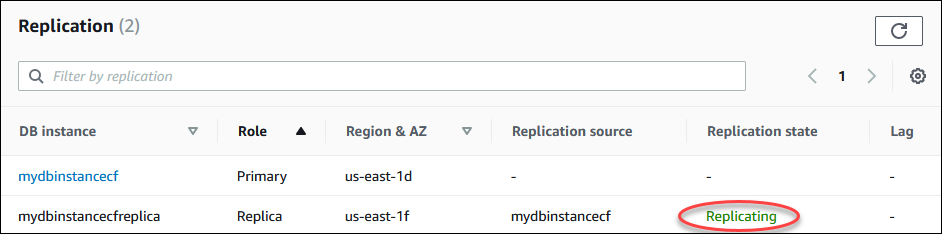
Vous pouvez superviser le statut d'un réplica en lecture de différentes manières. La console Amazon RDS affiche le statut d'un réplica en lecture dans la section Replication (Réplication) de l'onglet Connectivity & security (Connectivité et sécurité), dans les détails du réplica en lecture. Pour consulter les détails d'un réplica en lecture, cliquez sur son nom dans la liste des instances de base de données de la console Amazon RDS.
Vous pouvez également consulter l'état d'une réplique lue à l'aide de la AWS CLI
describe-db-instances commande ou de l'DescribeDBInstancesopération d'API Amazon RDS.
Le statut d'un réplica en lecture peut avoir les valeurs suivantes :
-
replicating (réplication en cours) – Le réplica en lecture réplique correctement.
-
réplication dégradée (SQL Server et PostgreSQL uniquement) : les réplicas reçoivent des données de l'instance principale, mais une ou plusieurs bases de données peuvent ne pas recevoir de mises à jour. Cela peut se produire, par exemple, lorsqu'un réplica est en train de configurer des bases de données nouvellement créées. Cela peut également se produire lorsque des modifications de DDL non prises en charge ou d'objets volumineux sont apportées dans l'environnement bleu d'un blue/green déploiement.
L'état ne passe pas de
replication degradedàerror, à moins qu'une erreur ne se produise pendant l'état dégradé. -
error (erreur) – Une erreur s'est produite dans le cadre de la réplication. Examinez le champ Replication Error (Erreur de réplication) dans la console Amazon RDS ou le journal des événements pour déterminer l'erreur exacte. Pour plus d'informations sur la résolution d'une erreur de réplication, consultez Résolution d'un problème de réplica en lecture MySQL.
-
terminated (arrêté) (MariaDB, MySQL ou PostgreSQL uniquement) – La réplication est arrêtée. Cela se produit si la réplication est arrêtée pendant plus de trente jours consécutifs, manuellement ou en raison d'une erreur de réplication. Dans ce cas, Amazon RDS met fin à la réplication entre l'instance de base de données principale et tous les réplicas en lecture. Amazon RDS fait cela pour éviter l'augmentation des besoins en stockage sur l'instance de base de données source et de longs délais de basculement.
Une réplication interrompue peut affecter le stockage, car les journaux peuvent croître en taille et en nombre en raison du volume élevé des messages d'erreur consignés dans le journal. Une réplication interrompue peut également affecter la récupération en cas de défaillance en raison du temps dont a besoin Amazon RDS pour conserver et traiter le grand nombre de journaux au cours de la récupération.
-
terminated (arrêté) (Oracle uniquement) – La réplication est arrêtée. Cela se produit si la réplication est arrêtée pendant plus de 8 heures car l'espace de stockage restant sur le réplica en lecture est insuffisant. Dans ce cas, Amazon RDS met fin à la réplication entre l'instance de base de données principale et les réplicas en lecture affectés. Ce statut est un état terminal et le réplica en lecture doit être recréé.
-
stopped (interrompue) (MariaDB ou MySQL uniquement) – La réplication s'est interrompue en raison d'une demande initiée par le client.
-
replication stop point set (point d'arrêt de réplication réglé) (MySQL uniquement) – Un point d'arrêt de réplication a été réglé par le client à l'aide de la procédure stockée et la réplication est en cours.
-
replication stop point reached (point d'arrêt de réplication atteint) (MySQL uniquement) – Un point d'arrêt de réplication a été réglé par le client à l'aide de la procédure stockée et la réplication est arrêtée, car le point d'arrêt est atteint.
Vous pouvez voir où une instance de base de données est répliquée et, le cas échéant, vérifier son état de réplication. Sur la page Bases de données de la console RDS, elle affiche Primaire dans la colonne Rôle . Choisissez son nom d'instance de base de données. Sur sa page détaillée, dans l'onglet Connectivité et sécurité, son état de réplication se trouve sous Réplication.
Surveillance du retard de réplication
Vous pouvez surveiller le délai de réplication dans Amazon CloudWatch en consultant la ReplicaLag métrique Amazon RDS.
Pour Db2, la métrique ReplicaLag correspond au retard maximal des bases de données qui ont pris du retard, en secondes. Par exemple, si deux bases de données accusent respectivement un retard de 5 secondes et 10 secondes, ReplicaLag a pour valeur 10 secondes. Les bases de données dont le statut HADR (High Availability Disaster Recovery) n’est pas disponible ne sont pas incluses dans le calcul.
Pour MySQL et MariaDB, la métrique ReplicaLag contient la valeur du champ Seconds_Behind_Master de la commande SHOW REPLICA STATUS. Les causes courantes du retard de réplication pour MySQL et MariaDB sont les suivantes :
-
Une indisponibilité du réseau.
-
L'écriture dans des tables avec des index sur un réplica en lecture. Si le paramètre
read_onlyn'a pas pour valeur 0 sur le réplica en lecture, il peut interrompre la réplication. -
Utilisation d'un moteur de stockage non transactionnel tel que MyISAM. La réplication est prise en charge uniquement pour le moteur de stockage InnoDB sur MySQL et pour le moteur de stockage XtraDB sur MariaDB.
Note
Les versions précédentes de MariaDB utilisaient SHOW SLAVE STATUS à la place de SHOW REPLICA STATUS. Si vous utilisez une version de MariaDB antérieure à 10.5, utilisez SHOW SLAVE STATUS.
Lorsque la métrique ReplicaLag atteint 0, le réplica a rattrapé l'instance de bases de données principale. Si la métrique ReplicaLag retourne -1, la réplication n'est actuellement pas active. ReplicaLag = -1 est équivalent à Seconds_Behind_Master = NULL.
Pour Oracle, la métrique ReplicaLag correspond à la somme de la valeur Apply
Lag et à la différence entre la durée actuelle et la valeur DATUM_TIME du retard appliqué. La valeur DATUM_TIME correspond à la dernière heure à laquelle le réplica en lecture a reçu des données de son instance de base de données source. Pour plus d’informations, consultez V$DATAGUARD_STATS
Pour SQL Server, la métrique ReplicaLag correspond au décalage maximal des bases de données qui ont pris du retard, en secondes. Par exemple, si vous avez deux bases de données qui accusent respectivement un retard de 5 secondes et 10 secondes, alors ReplicaLag a pour valeur 10 secondes. La métrique ReplicaLag renvoie la valeur de la requête suivante.
SELECT MAX(secondary_lag_seconds) max_lag FROM sys.dm_hadr_database_replica_states;
Pour plus d’informations, consultez secondary_lag_seconds
ReplicaLag renvoie -1 si RDS ne peut pas déterminer le retard, par exemple lors de la configuration du réplica, ou lorsque le réplica en lecture est à l'état error.
Note
Les nouvelles bases de données ne sont pas incluses dans le calcul du retard tant qu'elles ne sont pas accessibles sur le réplica en lecture.
Pour PostgreSQL, la métrique ReplicaLag renvoie la valeur de la requête suivante.
SELECT extract(epoch from now() - pg_last_xact_replay_timestamp()) AS reader_lag
PostgreSQL versions 9.5.2 et ultérieures utilise des emplacements physiques de réplication pour gérer la rétention WAL (Write Ahead Log) sur l'instance source. Pour chaque instance de réplica en lecture entre régions, Amazon RDS crée un emplacement de réplication physique et l'associe à l'instance. Deux CloudWatch indicateurs Amazon, Oldest Replication Slot Lag etTransaction
Logs Disk Usage, montrent à quel point la réplique la plus en retard se situe en termes de données WAL reçues et de quantité de stockage utilisée pour les données WAL. La valeur Transaction
Logs Disk Usage peut considérablement augmenter lorsqu'un réplica en lecture entre régions présente un retard important.
Pour plus d'informations sur la surveillance d'une instance de base de données avec CloudWatch, consultezContrôle Amazon RDS statistiques avec Amazon CloudWatch.
