Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Limitations du langage DDL et autres informations relatives à Aurora PostgreSQL Limitless Database
Les sections suivantes décrivent les limitations ou apportent des informations supplémentaires concernant les commandes SQL DDL dans Aurora PostgreSQL Limitless Database.
Rubriques
ALTER TABLE
La commande ALTER TABLE est généralement prise en charge dans Aurora PostgreSQL Limitless Database. Pour plus d’informations, consultez ALTER TABLE
Limitations
ALTER TABLE présente les limitations suivantes pour les options prises en charge.
- Suppression d’une colonne
-
-
Vous ne pouvez pas supprimer les colonnes qui font partie de la clé de partition dans les tables partitionnées.
-
Vous ne pouvez pas supprimer les colonnes de clé primaire dans les tables de référence.
-
- Modification du type de données d’une colonne
-
-
L’expression
USINGn’est pas prise en charge. -
Vous ne pouvez pas modifier le type des colonnes qui font partie de la clé de partition dans les tables partitionnées.
-
- Ajout ou suppression d’une contrainte
-
Pour en savoir plus sur les fonctionnalités non prises en charge, consultez Constaintes.
- Modification de la valeur par défaut d’une colonne
-
Les valeurs par défaut sont prises en charge. Pour plus d’informations, consultez Valeurs par défaut.
Options non prises en charge
Certaines options ne sont pas prises en charge, car elles dépendent de fonctionnalités non prises en charge, telles que les déclencheurs.
Les options au niveau de la table suivantes pour ALTER TABLE ne sont pas prises en charge :
-
ALL IN TABLESPACE -
ATTACH PARTITION -
DETACH PARTITION -
Indicateur
ONLY -
RENAME CONSTRAINT
Les options au niveau de la colonne suivantes pour ALTER TABLE ne sont pas prises en charge :
-
ADD GENERATED
-
DROP EXPRESSION [ IF EXISTS ]
-
DROP IDENTITY [ IF EXISTS ]
-
RESET
-
RESTART
-
SET
-
SET COMPRESSION
-
SET STATISTICS
CREATE DATABASE
Dans Aurora PostgreSQL Limitless Database, seules les bases de données sans limite sont prises en charge.
Lors de l’exécution de CREATE DATABASE, les bases de données créées sur un ou plusieurs nœuds peuvent échouer sur d’autres nœuds, car la création d’une base de données est une opération non transactionnelle. Dans ce cas, les objets de base de données créés sont automatiquement supprimés de tous les nœuds dans un délai prédéterminé afin de maintenir la cohérence du groupe de partitions de base de données. Pendant ce temps, la recréation d’une base de données portant le même nom peut entraîner une erreur indiquant que la base de données existe déjà.
Les options suivantes sont prises en charge :
-
Classement :
CREATE DATABASEnameWITH [LOCALE =locale] [LC_COLLATE =lc_collate] [LC_CTYPE =lc_ctype] [ICU_LOCALE =icu_locale] [ICU_RULES =icu_rules] [LOCALE_PROVIDER =locale_provider] [COLLATION_VERSION =collation_version]; -
CREATE DATABASE WITH OWNER:CREATE DATABASEnameWITH OWNER =user_name;
Les options suivantes ne sont pas prises en charge :
-
CREATE DATABASE WITH TABLESPACE:CREATE DATABASEnameWITH TABLESPACE =tablespace_name; -
CREATE DATABASE WITH TEMPLATE:CREATE DATABASEnameWITH TEMPLATE =template;
CREATE INDEX
CREATE INDEX CONCURRENTLY est pris en charge pour les tables partitionnées :
CREATE INDEX CONCURRENTLYindex_nameONtable_name(column_name);
CREATE UNIQUE INDEX est pris en charge pour tous les types de tables :
CREATE UNIQUE INDEXindex_nameONtable_name(column_name);
CREATE UNIQUE INDEX CONCURRENTLY n’est pas pris en charge :
CREATE UNIQUE INDEX CONCURRENTLYindex_nameONtable_name(column_name);
Pour plus d’informations, consultez UNIQUE. Pour obtenir des informations générales sur la création d’index, consultez CREATE INDEX
- Affichage des index
-
Les index ne sont pas tous visibles sur les routeurs lorsque vous utilisez
\dou des commandes similaires. Utilisez plutôt la vuetable_namepg_catalog.pg_indexespour obtenir des index, comme illustré dans l’exemple suivant.SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"id"}'; CREATE TABLE items (id int PRIMARY KEY, val int); CREATE INDEX items_my_index on items (id, val); postgres_limitless=> SELECT * FROM pg_catalog.pg_indexes WHERE tablename='items'; schemaname | tablename | indexname | tablespace | indexdef ------------+-----------+----------------+------------+------------------------------------------------------------------------ public | items | items_my_index | | CREATE INDEX items_my_index ON ONLY public.items USING btree (id, val) public | items | items_pkey | | CREATE UNIQUE INDEX items_pkey ON ONLY public.items USING btree (id) (2 rows)
CREATE SCHEMA
CREATE SCHEMA avec un élément de schéma n’est pas pris en charge :
CREATE SCHEMAmy_schemaCREATE TABLE (column_nameINT);
Un erreur semblable à la suivante est générée :
ERROR: CREATE SCHEMA with schema elements is not supported
CREATE TABLE
Les relations dans les instructions CREATE TABLE ne sont pas prises en charge, par exemple :
CREATE TABLE orders (orderid int, customerId int, orderDate date) WITH (autovacuum_enabled = false);
Les colonnes IDENTITY ne sont pas prises en charge, par exemple :
CREATE TABLE orders (orderid INT GENERATED ALWAYS AS IDENTITY);
Aurora PostgreSQL Limitless Database prend en charge jusqu’à 54 caractères pour les noms de table partitionnées.
CREATE TABLE AS
Pour créer une table à l’aide de CREATE TABLE AS, vous devez utiliser la variable rds_aurora.limitless_create_table_mode. Pour les tables partitionnées, vous devez également utiliser la variable rds_aurora.limitless_create_table_shard_key. Pour plus d’informations, consultez Création de tables sans limite à l’aide de variables.
-- Set the variables. SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"a"}'; CREATE TABLE ctas_table AS SELECT 1 a; -- "source" is the source table whose columns and data types are used to create the new "ctas_table2" table. CREATE TABLE ctas_table2 AS SELECT a,b FROM source;
Vous ne pouvez pas les utiliser CREATE TABLE AS pour créer des tables de référence, car elles nécessitent des contraintes de clé primaire. CREATE TABLE
ASne propage pas les clés primaires vers les nouvelles tables.
Pour des informations générales, consultez CREATE TABLE AS
DROP DATABASE
Vous pouvez supprimer les bases de données que vous avez créées.
La commande DROP DATABASE s’exécute de manière asynchrone en arrière-plan. Durant l’exécution de la commande, une erreur s’affichera si vous essayez de créer une base de données portant le même nom.
SELECT INTO
SELECT INTO est fonctionnellement similaire à CREATE TABLE AS. Vous devez utiliser la variable rds_aurora.limitless_create_table_mode. Pour les tables partitionnées, vous devez également utiliser la variable rds_aurora.limitless_create_table_shard_key. Pour plus d’informations, consultez Création de tables sans limite à l’aide de variables.
-- Set the variables. SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"a"}'; -- "source" is the source table whose columns and data types are used to create the new "destination" table. SELECT * INTO destination FROM source;
Actuellement, l’opération SELECT INTO est effectuée via le routeur, et non directement via les partitions. Les performances peuvent donc être réduites.
Pour des informations générales, consultez SELECT INTO
Constaintes
Les limitations suivantes s’appliquent aux contraintes d’Aurora PostgreSQL Limitless Database.
- CHECK
-
Les contraintes simples qui utilisent des opérateurs de comparaison avec des littéraux sont prises en charge. Les expressions et contraintes plus complexes qui nécessitent des validations de fonctions ne sont pas prises en charge, comme le montrent les exemples suivants.
CREATE TABLE my_table ( id INT CHECK (id > 0) -- supported , val INT CHECK (val > 0 AND val < 1000) -- supported , tag TEXT CHECK (length(tag) > 0) -- not supported: throws "Expression inside CHECK constraint is not supported" , op_date TIMESTAMP WITH TIME ZONE CHECK (op_date <= now()) -- not supported: throws "Expression inside CHECK constraint is not supported" );Vous pouvez attribuer des noms explicites aux contraintes, comme illustré dans l’exemple suivant.
CREATE TABLE my_table ( id INT CONSTRAINT positive_id CHECK (id > 0) , val INT CONSTRAINT val_in_range CHECK (val > 0 AND val < 1000) );Vous pouvez utiliser une syntaxe de contrainte au niveau de la table avec la contrainte
CHECK, comme illustré dans l’exemple suivant.CREATE TABLE my_table ( id INT CONSTRAINT positive_id CHECK (id > 0) , min_val INT CONSTRAINT min_val_in_range CHECK (min_val > 0 AND min_val < 1000) , max_val INT , CONSTRAINT max_val_in_range CHECK (max_val > 0 AND max_val < 1000 AND max_val > min_val) ); - EXCLUDE
-
Les contraintes d’exclusion ne sont pas prises en charge dans Aurora PostgreSQL Limitless Database.
- FOREIGN KEY
-
Pour plus d’informations, consultez Clés étrangères.
- NOT NULL
-
Les contraintes
NOT NULLsont prises en charge sans aucune restriction. - PRIMARY KEY
-
Étant donné que la clé primaire impose des contraintes uniques, elle est soumise aux mêmes restrictions que celles des contraintes uniques. Autrement dit :
-
Si une table est convertie en table partitionnée, la clé de partition doit être un sous-ensemble de la clé primaire. C’est-à-dire que la clé primaire contient toutes les colonnes de la clé de partition.
-
Si une table est convertie en table de référence, elle doit comporter une clé primaire.
Les exemples suivants illustrent l’utilisation des clés primaires.
-- Create a standard table. CREATE TABLE public.my_table ( item_id INT , location_code INT , val INT , comment text ); -- Change the table to a sharded table using the 'item_id' and 'location_code' columns as shard keys. CALL rds_aurora.limitless_alter_table_type_sharded('public.my_table', ARRAY['item_id', 'location_code']);Tentative d’ajout d’une clé primaire qui ne contient pas de clé de partition :
-- Add column 'item_id' as the primary key. -- Invalid because the primary key doesnt include all columns from the shard key: -- 'location_code' is part of the shard key but not part of the primary key ALTER TABLE public.my_table ADD PRIMARY KEY (item_id); -- ERROR -- add column "val" as primary key -- Invalid because primary key does not include all columns from shard key: -- item_id and location_code iare part of shard key but not part of the primary key ALTER TABLE public.my_table ADD PRIMARY KEY (item_id); -- ERRORTentative d’ajout d’une clé primaire qui contient une clé de partition :
-- Add the 'item_id' and 'location_code' columns as the primary key. -- Valid because the primary key contains the shard key. ALTER TABLE public.my_table ADD PRIMARY KEY (item_id, location_code); -- OK -- Add the 'item_id', 'location_code', and 'val' columns as the primary key. -- Valid because the primary key contains the shard key. ALTER TABLE public.my_table ADD PRIMARY KEY (item_id, location_code, val); -- OKRemplacez une table standard par une table de référence.
-- Create a standard table. CREATE TABLE zipcodes (zipcode INT PRIMARY KEY, details VARCHAR); -- Convert the table to a reference table. CALL rds_aurora.limitless_alter_table_type_reference('public.zipcode');Pour plus d’informations sur la création de tables partitionnées et de tables de référence, consultez Création de tables Aurora PostgreSQL Limitless Database.
-
- UNIQUE
-
Dans les tables partitionnées, la clé unique doit contenir la clé de partition, c’est-à-dire que la clé de partition doit être un sous-ensemble de la clé unique. Cette vérification est effectuée lors du changement du type de table en table partitionnée. Aucune restriction n’est appliquée aux tables de référence.
CREATE TABLE customer ( customer_id INT NOT NULL , zipcode INT , email TEXT UNIQUE );Table-level
UNIQUEles contraintes sont prises en charge, comme indiqué dans l'exemple suivant.CREATE TABLE customer ( customer_id INT NOT NULL , zipcode INT , email TEXT , CONSTRAINT zipcode_and_email UNIQUE (zipcode, email) );L’exemple suivant montre l’utilisation conjointe d’une clé primaire et d’une clé unique. Les deux clés doivent inclure la clé de partition.
SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"p_id"}'; CREATE TABLE t1 ( p_id BIGINT NOT NULL, c_id BIGINT NOT NULL, PRIMARY KEY (p_id), UNIQUE (p_id, c_id) );
Pour plus d’informations, consultez Contraintes
Valeurs par défaut
Aurora PostgreSQL Limitless Database prend en charge les expressions dans les valeurs par défaut.
L’exemple suivant illustre l’utilisation des valeurs par défaut.
CREATE TABLE t ( a INT DEFAULT 5, b TEXT DEFAULT 'NAN', c NUMERIC ); CALL rds_aurora.limitless_alter_table_type_sharded('t', ARRAY['a']); INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c ---+-----+--- 5 | NAN | (1 row)
Les expressions sont prises en charge, comme illustré dans l’exemple suivant.
CREATE TABLE t1 (a NUMERIC DEFAULT random());
L’exemple suivant illustre l’ajout d’une nouvelle colonne qui présente la valeur NOT NULL et une valeur par défaut.
ALTER TABLE t ADD COLUMN d BOOLEAN NOT NULL DEFAULT FALSE; SELECT * FROM t; a | b | c | d ---+-----+---+--- 5 | NAN | | f (1 row)
L’exemple suivant illustre la modification d’une colonne existante avec une valeur par défaut.
ALTER TABLE t ALTER COLUMN c SET DEFAULT 0.0; INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c | d ---+-----+-----+----- 5 | NAN | | f 5 | NAN | 0.0 | f (2 rows)
L’exemple suivant illustre la suppression d’une valeur par défaut.
ALTER TABLE t ALTER COLUMN a DROP DEFAULT; INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c | d ---+-----+-----+----- 5 | NAN | | f 5 | NAN | 0.0 | f | NAN | 0.0 | f (3 rows)
Pour plus d’informations, consultez Valeurs par défaut
Extensions
Les fonctionnalités PostgreSQL suivantes sont prises en charge dans Aurora PostgreSQL Limitless Database :
-
aurora_limitless_fdw: cette extension est préinstallée. Vous ne pouvez pas la supprimer. -
aws_s3: le fonctionnement de cette extension est similaire dans Aurora PostgreSQL Limitless Database et dans Aurora PostgreSQL.Vous pouvez importer des données à partir d’un compartiment Amazon S3 vers un cluster de bases de données Aurora PostgreSQL Limitless Database ou exporter des données à partir d’un cluster de bases de données Aurora PostgreSQL Limitless Database vers un compartiment Amazon S3. Pour plus d’informations, consultez Importation de données Amazon S3 dans une d'un cluster de base de données Aurora PostgreSQL et Exportation de données à partir d’un cluster de bases de données Aurora PostgreSQL vers Amazon S3.
-
btree_gin -
citext -
ip4r -
pg_buffercache: cette extension se comporte différemment dans Aurora PostgreSQL Limitless Database par rapport à PostgreSQL communautaire. Pour plus d’informations, consultez Différences pg_buffercache dans Aurora PostgreSQL Limitless Database. -
pg_stat_statements -
pg_trgm -
pgcrypto -
pgstattuple: cette extension se comporte différemment dans Aurora PostgreSQL Limitless Database par rapport à PostgreSQL communautaire. Pour plus d’informations, consultez Différences pgstattuple dans Aurora PostgreSQL Limitless Database. -
pgvector -
plpgsql: cette extension est préinstallée, mais vous pouvez la supprimer. -
PostGIS: les transactions longues et les fonctions de gestion de tables ne sont pas prises en charge. La modification de la table de référence spatiale n’est pas prise en charge. -
unaccent -
uuid
La plupart des extensions PostgreSQL ne sont pas prises en charge dans Aurora PostgreSQL Limitless Database. Toutefois, vous pouvez toujours utiliser le paramètre de configuration shared_preload_libraries
Vous pouvez, par exemple, charger l’extension pg_hint_plan, mais son chargement ne garantit pas que les indications transmises dans les commentaires de requête soient prises en compte.
Note
Vous ne pouvez pas modifier les objets associés à l’extension pg_stat_statementspg_stat_statements, consultez limitless_stat_statements.
Vous pouvez utiliser les fonctions pg_available_extensions et pg_available_extension_versions pour rechercher les extensions prises en charge dans Aurora PostgreSQL Limitless Database.
Les DDL suivants sont compatibles avec les extensions :
- CREATE EXTENSION
-
Vous pouvez créer des extensions, comme dans PostgreSQL.
CREATE EXTENSION [ IF NOT EXISTS ]extension_name[ WITH ] [ SCHEMAschema_name] [ VERSIONversion] [ CASCADE ]Pour plus d’informations, consultez CREATE EXTENSION
dans la documentation PostgreSQL. - ALTER EXTENSION
-
Les DDL suivants sont pris en charge :
ALTER EXTENSIONnameUPDATE [ TOnew_version] ALTER EXTENSIONnameSET SCHEMAnew_schemaPour plus d’informations, consultez ALTER EXTENSION
dans la documentation PostgreSQL. - DROP EXTENSION
-
Vous pouvez supprimer des extensions, comme dans PostgreSQL.
DROP EXTENSION [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]Pour plus d’informations, consultez DROP EXTENSION
dans la documentation PostgreSQL.
Les DDL suivants ne sont pas compatibles avec les extensions :
- ALTER EXTENSION
-
Vous ne pouvez pas ajouter ou supprimer des objets membres des extensions.
ALTER EXTENSIONnameADDmember_objectALTER EXTENSIONnameDROPmember_object
Différences pg_buffercache dans Aurora PostgreSQL Limitless Database
Dans Aurora PostgreSQL Limitless Database, lorsque vous installez l’extension pg_buffercachepg_buffercache, vous ne recevez des informations relatives aux tampons que depuis le nœud auquel vous êtes actuellement connecté, à savoir le routeur. De même, l’utilisation de la fonction pg_buffercache_summary ou pg_buffercache_usage_counts ne fournit des informations que depuis le nœud connecté.
Il est possible que vous ayez plusieurs nœuds et que vous deviez consulter les informations sur les tampons depuis n’importe lequel d’entre eux afin de diagnostiquer efficacement les problèmes. Limitless Database fournit donc les fonctions suivantes :
-
rds_aurora.limitless_pg_buffercache(subcluster_id) -
rds_aurora.limitless_pg_buffercache_summary(subcluster_id) -
rds_aurora.limitless_pg_buffercache_usage_counts(subcluster_id)
En saisissant l’ID de sous-cluster de n’importe quel nœud, qu’il s’agisse d’un routeur ou d’une partition, vous pouvez facilement accéder aux informations sur les tampons spécifiques à ce nœud. Ces fonctions sont directement disponibles lorsque vous installez l’extension pg_buffercache dans la base de données sans limite.
Note
Aurora PostgreSQL Limitless Database prend en charge ces fonctions pour les versions 1.4 et ultérieures de l’extension pg_buffercache.
Les colonnes affichées dans la vue limitless_pg_buffercache sont légèrement différentes de celles de la vue pg_buffercache :
-
bufferid: similaire àpg_buffercache. -
relname: au lieu d’afficher le numéro de nœud de fichier tel qu’il est indiqué danspg_buffercache,limitless_pg_buffercacheprésente lerelnameassocié s’il est disponible dans la base de données actuelle ou dans les catalogues de systèmes partagés ; à défaut, il présente la valeurNULL. -
parent_relname: cette nouvelle colonne, absente danspg_buffercache, affiche lerelnameparent si la valeur de la colonnerelnamereprésente une table partitionnée (dans le cas de tables partitionnées). Dans le cas contraire, il présente la valeurNULL. -
spcname: au lieu d’afficher l’identifiant d’objet de l’espace de table (OID) comme danspg_buffercache,limitless_pg_buffercacheaffiche le nom de l’espace de table. -
datname: au lieu d’afficher l’OID de la base de données comme danspg_buffercache,limitless_pg_buffercacheaffiche le nom de la base de données. -
relforknumber: similaire àpg_buffercache. -
relblocknumber: similaire àpg_buffercache. -
isdirty: similaire àpg_buffercache. -
usagecount: similaire àpg_buffercache. -
pinning_backends: similaire àpg_buffercache.
Les colonnes des vues limitless_pg_buffercache_summary et limitless_pg_buffercache_usage_counts sont similaires à celles des vues standard pg_buffercache_summary et pg_buffercache_usage_counts, respectivement.
L’utilisation de ces fonction vous permet d’obtenir des informations détaillées sur les tampons de l’ensemble des nœuds de votre environnement Limitless Database, facilitant ainsi le diagnostic et la gestion de vos systèmes de base de données.
Différences pgstattuple dans Aurora PostgreSQL Limitless Database
Dans Aurora PostgreSQL, l’extension pgstattuple
Nous reconnaissons l’importance de cette extension pour l’obtention de statistiques au niveau des tuples, essentielles pour des tâches telles que la suppression du gonflement et la collecte d’informations de diagnostic. Par conséquent, Aurora PostgreSQL Limitless Database prend en charge l’extension pgstattuple dans des bases de données sans limite.
Aurora PostgreSQL Limitless Database inclut les fonctions suivantes dans le schéma rds_aurora :
- Tuple-level fonctions statistiques
-
rds_aurora.limitless_pgstattuple(relation_name)-
Objectif : extraire des statistiques au niveau des tuples pour les tables standard et leurs index
-
Entrée :
relation_name(texte) : le nom de la relation -
Sortie : colonnes cohérentes avec celles renvoyées par la fonction
pgstattupledans Aurora PostgreSQL
rds_aurora.limitless_pgstattuple(relation_name,subcluster_id)-
Objectif : extraire des statistiques au niveau des tuples pour les tables de référence, les tables partitionnées, les tables de catalogue et leurs index
-
Entrée :
-
relation_name(texte) : le nom de la relation -
subcluster_id(texte) : l’ID du sous-cluster du nœud où les statistiques doivent être extraites
-
-
Sortie :
-
Pour les tables de référence et de catalogue (y compris leurs index), les colonnes sont cohérentes avec celles d’Aurora PostgreSQL.
-
Pour les tables partitionnées, les statistiques représentent uniquement la partition de la table partitionnée résidant sur le sous-cluster spécifié.
-
-
- Fonctions de statistiques d’index
-
rds_aurora.limitless_pgstatindex(relation_name)-
Objectif : Extraire des statistiques pour les B-tree index sur les tables standard
-
Entrée :
relation_name(texte) — Le nom de l' B-tree index -
Sortie : toutes les colonnes sauf
root_block_nosont renvoyées. Les colonnes transmises sont cohérentes avec celles renvoyées par la fonctionpgstatindexdans Aurora PostgreSQL.
rds_aurora.limitless_pgstatindex(relation_name,subcluster_id)-
Objectif : Extraire des statistiques pour B-tree les index des tables de référence, des tables partitionnées et des tables de catalogue.
-
Entrée :
-
relation_name(texte) — Le nom de l' B-tree index -
subcluster_id(texte) : l’ID du sous-cluster du nœud où les statistiques doivent être extraites
-
-
Sortie :
-
Pour les index des tables de référence et de catalogue, toutes les colonnes (sauf
root_block_no) sont renvoyées. Les colonnes transmises sont cohérentes avec celles d’Aurora PostgreSQL. -
Pour les tables partitionnées, les statistiques représentent uniquement la partition de l’index de la table partitionnée résidant sur le sous-cluster spécifié. La colonne
tree_levelindique la moyenne de toutes les tranches de table du sous-cluster demandé.
-
rds_aurora.limitless_pgstatginindex(relation_name)-
Objectif : extraire les statistiques des index inversés généralisés (GIN) sur les tables standard
-
Entrée :
relation_name(texte) : le nom du GIN -
Sortie : colonnes cohérentes avec celles renvoyées par la fonction
pgstatginindexdans Aurora PostgreSQL
rds_aurora.limitless_pgstatginindex(relation_name,subcluster_id)-
Objectif : extraire les statistiques des index GIN sur les tables de référence, les tables partitionnées et les tables de catalogue.
-
Entrée :
-
relation_name(texte) : le nom de l’index -
subcluster_id(texte) : l’ID du sous-cluster du nœud où les statistiques doivent être extraites
-
-
Sortie :
-
Pour les index GIN des tables de référence et de catalogue, les colonnes sont cohérentes avec celles d’Aurora PostgreSQL.
-
Pour les tables partitionnées, les statistiques représentent uniquement la partition de l’index de la table partitionnée résidant sur le sous-cluster spécifié.
-
rds_aurora.limitless_pgstathashindex(relation_name)-
Objectif : extraire les statistiques des index de hachage sur des tables standard
-
Entrée :
relation_name(texte) : le nom de l’index de hachage -
Sortie : colonnes cohérentes avec celles renvoyées par la fonction
pgstathashindexdans Aurora PostgreSQL
rds_aurora.limitless_pgstathashindex(relation_name,subcluster_id)-
Objectif : extraire les statistiques des index de hachage sur les tables de référence, des tables partitionnées et des tables de catalogue.
-
Entrée :
-
relation_name(texte) : le nom de l’index -
subcluster_id(texte) : l’ID du sous-cluster du nœud où les statistiques doivent être extraites
-
-
Sortie :
-
Pour les index de hachage des tables de référence et de catalogue, les colonnes sont cohérentes avec celles d’Aurora PostgreSQL.
-
Pour les tables partitionnées, les statistiques représentent uniquement la partition de l’index de la table partitionnée résidant sur le sous-cluster spécifié.
-
-
- Fonctions de comptage de pages
-
rds_aurora.limitless_pg_relpages(relation_name)-
Objectif : extraire le nombre de pages pour les tables standard et leurs index
-
Entrée :
relation_name(texte) : le nom de la relation -
Sortie : nombre de pages de la relation spécifiée
rds_aurora.limitless_pg_relpages(relation_name,subcluster_id)-
Objectif : extraire le nombre de pages pour les tables de référence, les tables partitionnées et les tables de catalogue (y compris leurs index)
-
Entrée :
-
relation_name(texte) : le nom de la relation -
subcluster_id(texte) : l’ID du sous-cluster du nœud où le nombre de page doit être extrait
-
-
Sortie : pour les tables partitionnées, le nombre de pages correspond à la somme des pages de toutes les tranches de tableau du sous-cluster spécifié.
-
- Fonctions de statistiques approximatives au niveau des tuples
-
rds_aurora.limitless_pgstattuple_approx(relation_name)-
Objectif : extraire des statistiques approximatives au niveau des tuples pour les tables standard et leurs index
-
Entrée :
relation_name(texte) : le nom de la relation -
Sortie : colonnes cohérentes avec celles renvoyées par la fonction pgstattuple_approx dans Aurora PostgreSQL
rds_aurora.limitless_pgstattuple_approx(relation_name,subcluster_id)-
Objectif : extraire des statistiques approximatives au niveau des tuples pour les tables de référence, les tables partitionnées et les tables de catalogue (y compris leurs index)
-
Entrée :
-
relation_name(texte) : le nom de la relation -
subcluster_id(texte) : l’ID du sous-cluster du nœud où les statistiques doivent être extraites
-
-
Sortie :
-
Pour les tables de référence et de catalogue (y compris leurs index), les colonnes sont cohérentes avec celles d’Aurora PostgreSQL.
-
Pour les tables partitionnées, les statistiques représentent uniquement la partition de la table partitionnée résidant sur le sous-cluster spécifié.
-
-
Note
Actuellement, Aurora PostgreSQL Limitless Database ne prend pas en charge l’extension pgstattuple sur les vues matérialisées, les tables TOAST ou les tables temporaires.
Dans Aurora PostgreSQL Limitless Database, vous devez fournir l’entrée sous forme de texte, bien qu’Aurora PostgreSQL prenne en charge d’autres formats.
Clés étrangères
Les contraintes de clé étrangère (FOREIGN KEY) sont prises en charge avec certaines restrictions :
-
CREATE TABLEavecFOREIGN KEYest pris en charge uniquement pour les tables standard. Pour créer une table partitionnée ou de référence avecFOREIGN KEY, créez d’abord la table sans contrainte de clé étrangère. Modifiez-la ensuite à l’aide de l’instruction suivante :ALTER TABLE ADD CONSTRAINT; -
La conversion d’une table standard en table partitionnée ou en table de référence n’est pas prise en charge lorsque la table est soumise à une contrainte de clé étrangère. Supprimez la contrainte, puis ajoutez-la après la conversion.
-
Les limitations suivantes concernent les types de tables comportant des contraintes de clé étrangère :
-
Une table standard peut être soumise à une contrainte de clé étrangère vers une autre table standard.
-
Une table partitionnée peut être soumise à une contrainte de clé étrangère lorsque les tables parente et enfant sont colocalisées et que la clé étrangère constitue un sur-ensemble de la clé de partition.
-
Une table partitionnée peut être soumise à une contrainte de clé étrangère vers une table de référence.
-
Une table de référence peut être soumise à une contrainte de clé étrangère vers une autre table de référence.
-
Rubriques
Options à clé étrangère
Les clés étrangères sont prises en charge dans Aurora PostgreSQL Limitless Database pour certaines options DDL. Le tableau suivant répertorie les options prises en charge et non prises en charge entre les tables Aurora PostgreSQL Limitless Database.
| Option DDL | Référence à référence | Partitionnée à partitionnée (colocalisée) | Partitionnée à référence | Standard à standard |
|---|---|---|---|---|
|
|
Oui | Oui | Oui | Oui |
|
|
Oui | Oui | Oui | Oui |
|
|
Oui | Oui | Oui | Oui |
|
|
Oui | Oui | Oui | Oui |
|
|
Non | Non | Non | Non |
|
|
Oui | Oui | Oui | Oui |
|
|
Oui | Oui | Oui | Oui |
|
|
Oui | Non | Non | Oui |
|
|
Oui | Oui | Oui | Oui |
|
|
Oui | Oui | Oui | Oui |
|
|
Oui | Oui | Oui | Oui |
|
|
Non | Non | Non | Non |
|
|
Oui | Non | Non | Oui |
|
|
Non | Non | Non | Oui |
|
|
Oui | Oui | Oui | Oui |
|
|
Oui | Oui | Oui | Oui |
|
|
Non | Non | Non | Non |
|
|
Oui | Non | Non | Oui |
Exemples
-
Standard à standard :
set rds_aurora.limitless_create_table_mode='standard'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer REFERENCES products (product_no), quantity integer ); SELECT constraint_name, table_name, constraint_type FROM information_schema.table_constraints WHERE constraint_type='FOREIGN KEY'; constraint_name | table_name | constraint_type -------------------------+-------------+----------------- orders_product_no_fkey | orders | FOREIGN KEY (1 row) -
Partitionnée à partitionnée (colocalisée) :
set rds_aurora.limitless_create_table_mode='sharded'; set rds_aurora.limitless_create_table_shard_key='{"product_no"}'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); set rds_aurora.limitless_create_table_shard_key='{"order_id"}'; set rds_aurora.limitless_create_table_collocate_with='products'; CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no); -
Partitionnée à référence :
set rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); set rds_aurora.limitless_create_table_mode='sharded'; set rds_aurora.limitless_create_table_shard_key='{"order_id"}'; CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no); -
Référence à référence :
set rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no);
Fonctions
Les fonctions sont prises en charge dans Aurora PostgreSQL Limitless Database.
Les DDL suivants sont pris en charge pour les fonctions :
- CREATE FUNCTION
-
Il est possible de créer des fonctions comme dans Aurora PostgreSQL, toutefois, la volatilité ne peut pas être changée lors d’un remplacement.
Pour plus d’informations, consultez CREATE FUNCTION
dans la documentation PostgreSQL. - ALTER FUNCTION
-
Vous pouvez modifier des fonctions, comme dans Aurora PostgreSQL, à l’exception du changement de leur volatilité.
Pour plus d’informations, consultez ALTER FUNCTION
dans la documentation PostgreSQL. - DROP FUNCTION
-
Vous pouvez supprimer des fonctions, comme dans Aurora PostgreSQL.
DROP FUNCTION [ IF EXISTS ]name[ ( [ [argmode] [argname]argtype[, ...] ] ) ] [, ...] [ CASCADE | RESTRICT ]Pour plus d’informations, consultez DROP FUNCTION
dans la documentation PostgreSQL.
Répartition des fonctions
Lorsque toutes les instructions d’une fonction sont ciblées sur une seule partition, il est avantageux de transférer l’ensemble de la fonction vers la partition cible. Le résultat est simplement renvoyé au routeur, sans que la fonction y soit déroulée. La fonctionnalité de poussée vers le bas des fonctions et procédures stockées est utile pour les clients qui souhaitent exécuter leur fonction ou procédure stockée au plus près de la source de données, c’est-à-dire de la partition.
Pour distribuer une fonction, commencez par la créer avant d’appeler la procédure rds_aurora.limitless_distribute_function en vue de la distribuer. Cette fonction utilise la syntaxe suivante :
SELECT rds_aurora.limitless_distribute_function('function_prototype', ARRAY['shard_key'], 'collocating_table');
La fonction présente les paramètres suivants :
-
function_prototypeSi l’un des arguments est défini en tant que paramètres
OUT, n’incluez pas son type dans les argumentsfunction_prototype. -
ARRAY[': la liste des arguments de fonction identifiés comme étant la clé de partition de la fonction.shard_key'] -
collocating_table
Pour identifier la partition sur laquelle pousser cette fonction vers la bas, le système utilise l’argument ARRAY[', calcule sa valeur de hachage, puis recherche la partition dans shard_key']collocating_table
- Restrictions
-
Lorsque vous distribuez une fonction ou une procédure, elle ne traite que les données délimitées par la plage de clés de cette partition. Dans les cas où la fonction ou la procédure essaie d’accéder aux données d’une autre partition, les résultats renvoyés par la fonction ou procédure distribuée seront différents de ceux renvoyés par une fonction ou procédure non distribuée.
Par exemple, vous créez une fonction contenant des requêtes qui toucheront plusieurs partitions, puis vous appelez la procédure
rds_aurora.limitless_distribute_functionpour la distribuer. Lorsque vous invoquez cette fonction en fournissant des arguments pour une clé de partition, il est probable que les résultats de son exécution seront limités par les valeurs présentes dans cette partition. Ces résultats diffèrent de ceux obtenus lorsque la fonction n’est pas distribuée. - Exemples
-
Prenons l’exemple de la fonction
funcsuivante, avec la table partitionnéecustomerset la clé de partitioncustomer_id.postgres_limitless=> CREATE OR REPLACE FUNCTION func(c_id integer, sc integer) RETURNS int language SQL volatile AS $$ UPDATE customers SET score = sc WHERE customer_id = c_id RETURNING score; $$;Nous distribuons cette fonction :
SELECT rds_aurora.limitless_distribute_function('func(integer, integer)', ARRAY['c_id'], 'customers');Voici quelques exemples de plans de requête.
EXPLAIN(costs false, verbose true) SELECT func(27+1,10); QUERY PLAN -------------------------------------------------- Foreign Scan Output: (func((27 + 1), 10)) Remote SQL: SELECT func((27 + 1), 10) AS func Single Shard Optimized (4 rows)EXPLAIN(costs false, verbose true) SELECT * FROM customers,func(customer_id, score) WHERE customer_id=10 AND score=27; QUERY PLAN --------------------------------------------------------------------- Foreign Scan Output: customer_id, name, score, func Remote SQL: SELECT customers.customer_id, customers.name, customers.score, func.func FROM public.customers, LATERAL func(customers.customer_id, customers.score) func(func) WHERE ((customers.customer_id = 10) AND (customers.score = 27)) Single Shard Optimized (10 rows)L’exemple suivant illustre une procédure utilisant les paramètres
INetOUTen tant qu’arguments.CREATE OR REPLACE FUNCTION get_data(OUT id INTEGER, IN arg_id INT) AS $$ BEGIN SELECT customer_id, INTO id FROM customer WHERE customer_id = arg_id; END; $$ LANGUAGE plpgsql;L’exemple suivant illustre la distribution de la procédure utilisant uniquement les paramètres
IN.EXPLAIN(costs false, verbose true) SELECT * FROM get_data(1); QUERY PLAN ----------------------------------- Foreign Scan Output: id Remote SQL: SELECT customer_id FROM get_data(1) get_data(id) Single Shard Optimized (6 rows)
Volatilité des fonctions
Vous pouvez déterminer si une fonction est immuable, stable ou volatile en vérifiant la valeur provolatile dans la vue pg_procprovolatile indique si le résultat de la fonction dépend uniquement de ses arguments d’entrée ou s’il est affecté par des facteurs extérieurs.
La valeur est l’une des suivantes :
-
i: fonctions immuables, qui fournissent toujours le même résultat pour les mêmes entrées -
s: fonctions stables, dont les résultats (pour les entrées fixes) ne changent pas au cours d’un scan -
v: fonctions volatiles, dont les résultats peuvent changer à tout moment. Utilisez égalementvpour les fonctions présentant des effets secondaires, de sorte que leurs appels ne puissent pas être optimisés.
Les exemples suivants présentent des fonctions volatiles.
SELECT proname, provolatile FROM pg_proc WHERE proname='pg_sleep'; proname | provolatile ----------+------------- pg_sleep | v (1 row) SELECT proname, provolatile FROM pg_proc WHERE proname='uuid_generate_v4'; proname | provolatile ------------------+------------- uuid_generate_v4 | v (1 row) SELECT proname, provolatile FROM pg_proc WHERE proname='nextval'; proname | provolatile ---------+------------- nextval | v (1 row)
La modification de la volatilité d’une fonction existante n’est pas prise en charge dans Aurora PostgreSQL Limitless Database. Cela s’applique à la fois aux commandes ALTER FUNCTION et CREATE OR REPLACE FUNCTION, comme indiqué dans les exemples suivants.
-- Create an immutable function CREATE FUNCTION immutable_func1(name text) RETURNS text language plpgsql AS $$ BEGIN RETURN name; END; $$IMMUTABLE; -- Altering the volatility throws an error ALTER FUNCTION immutable_func1 STABLE; -- Replacing the function with altered volatility throws an error CREATE OR REPLACE FUNCTION immutable_func1(name text) RETURNS text language plpgsql AS $$ BEGIN RETURN name; END; $$VOLATILE;
Nous vous recommandons vivement d’attribuer les volatilités appropriées aux fonctions. Par exemple, si votre fonction utilise SELECT à partir de plusieurs tables ou fait référence à des objets de la base de données, ne la définissez pas sur IMMUTABLE. Si le contenu de la table change, l’immuabilité est rompue.
Aurora PostgreSQL permet l’utilisation de SELECT dans les fonctions immuables, toutefois les résultats obtenus risquent d’être inexacts. Aurora PostgreSQL Limitless Database peut renvoyer à la fois des erreurs et des résultats incorrects. Pour plus d’informations sur la volatilité des fonctions, consultez Catégories de volatilité des fonctions
Séquences
Les séquences nommées sont des objets de base de données qui génèrent des nombres uniques dans un ordre croissant ou décroissant. CREATE SEQUENCE crée un nouveau générateur de numéros de séquence. L’unicité des valeurs de séquence est garantie.
Lorsque vous créez une séquence nommée dans Aurora PostgreSQL Limitless Database, un objet de séquence distribuée est créé. Aurora PostgreSQL Limitless Database distribue ensuite des fragments de valeurs de séquence non superposés sur tous les routeurs de transactions distribués (routeurs). Les fragments sont représentés sous forme d’objets de séquence locaux sur les routeurs ; par conséquent, les opérations de séquence telles que nextval et currval sont exécutées localement. Les routeurs fonctionnent indépendamment et demandent de nouveaux fragments à partir de la séquence distribuée en cas de besoin.
Pour plus d’informations sur les séquences, consultez CREATE SEQUENCE
Rubriques
Demande d’un nouveau fragment
La taille des fragments alloués sur les routeurs peut être configurée à l’aide du paramètre rds_aurora.limitless_sequence_chunk_size. La valeur par défaut est 250000. Chaque routeur présente initialement deux fragments : actif et réservé. Les fragments actifs sont utilisés pour configurer les objets de séquence locaux (paramètre minvalue et maxvalue), et les fragments réservés sont stockés dans une table de catalogue interne. Lorsqu’un fragment actif atteint la valeur minimale ou maximale, il est remplacé par le segment réservé. Pour ce faire, ALTER SEQUENCE est utilisé en interne, ce qui signifie que AccessExclusiveLock est acquis.
Des processus en arrière-plan s’exécutent toutes les 10 secondes sur les nœuds des routeurs afin de rechercher les séquences dont les fragments réservés ont été utilisés. Si un fragment utilisé est trouvé, le processus demande un nouveau fragment à partir de la séquence distribuée. Assurez-vous de définir une taille de fragment suffisamment grande pour que les processus en arrière-plan aient suffisamment de temps pour en demander de nouveaux. Les demandes à distance ne s’exécutent jamais dans le contexte des sessions utilisateur ; vous ne pouvez donc pas demander directement une nouvelle séquence.
Limitations
Les limitations suivantes s’appliquent aux séquences dans Aurora PostgreSQL Limitless Database :
-
Le catalogue
pg_sequence, la fonctionpg_sequenceset l’instructionSELECT * FROMaffichent tous uniquement l’état local de la séquence, et non son état distribué.sequence_name -
Les valeurs d’une séquence sont garanties uniques et monotones au sein d’une même session. Toutefois, l’ordre des valeurs peut différer de celui des instructions
nextvalexécutées dans d’autres sessions connectées à d’autres routeurs. -
Assurez-vous que la taille de séquence (nombre de valeurs disponibles) est suffisamment grande pour être répartie sur tous les routeurs. Utilisez le paramètre
rds_aurora.limitless_sequence_chunk_sizepour configurerchunk_size. (Chaque routeur comporte deux fragments.) -
L’option
CACHEest prise en charge, mais le cache doit être inférieur àchunk_size.
Options non prises en charge
Les options suivantes ne sont pas prises en charge dans Aurora PostgreSQL Limitless Database.
- Fonctions de manipulation de séquence
-
La fonction
setvaln’est pas prise en charge. Pour plus d’informations, consultez Fonctions de manipulation de séquencedans la documentation PostgreSQL. - CREATE SEQUENCE
-
Les options suivantes ne sont pas prises en charge.
CREATE [{ TEMPORARY | TEMP} | UNLOGGED] SEQUENCE [[ NO ] CYCLE]Pour plus d’informations, consultez CREATE SEQUENCE
dans la documentation PostgreSQL. - ALTER SEQUENCE
-
Les options suivantes ne sont pas prises en charge.
ALTER SEQUENCE [[ NO ] CYCLE]Pour plus d’informations, consultez ALTER SEQUENCE
dans la documentation PostgreSQL. - ALTER TABLE
-
La commande
ALTER TABLEn’est pas compatible avec les séquences.
Exemples
- CREATE/DROP SÉQUENCE
-
postgres_limitless=> CREATE SEQUENCE s; CREATE SEQUENCE postgres_limitless=> SELECT nextval('s'); nextval --------- 1 (1 row) postgres_limitless=> SELECT * FROM pg_sequence WHERE seqrelid='s'::regclass; seqrelid | seqtypid | seqstart | seqincrement | seqmax | seqmin | seqcache | seqcycle ----------+----------+----------+--------------+--------+--------+----------+---------- 16960 | 20 | 1 | 1 | 10000 | 1 | 1 | f (1 row) % connect to another router postgres_limitless=> SELECT nextval('s'); nextval --------- 10001 (1 row) postgres_limitless=> SELECT * FROM pg_sequence WHERE seqrelid='s'::regclass; seqrelid | seqtypid | seqstart | seqincrement | seqmax | seqmin | seqcache | seqcycle ----------+----------+----------+--------------+--------+--------+----------+---------- 16959 | 20 | 10001 | 1 | 20000 | 10001 | 1 | f (1 row) postgres_limitless=> DROP SEQUENCE s; DROP SEQUENCE - ALTER SEQUENCE
-
postgres_limitless=> CREATE SEQUENCE s; CREATE SEQUENCE postgres_limitless=> ALTER SEQUENCE s RESTART 500; ALTER SEQUENCE postgres_limitless=> SELECT nextval('s'); nextval --------- 500 (1 row) postgres_limitless=> SELECT currval('s'); currval --------- 500 (1 row) - Fonctions de manipulation de séquence
-
postgres=# CREATE TABLE t(a bigint primary key, b bigint); CREATE TABLE postgres=# CREATE SEQUENCE s minvalue 0 START 0; CREATE SEQUENCE postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# SELECT * FROM t; a | b ---+--- 0 | 0 1 | 1 (2 rows) postgres=# ALTER SEQUENCE s RESTART 10000; ALTER SEQUENCE postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# SELECT * FROM t; a | b -------+------- 0 | 0 1 | 1 10000 | 10000 (3 rows)
Vues de séquence
Aurora PostgreSQL Limitless Database propose les vues suivantes pour les séquences.
- rds_aurora.limitless_distributed_sequence
-
Cette vue montre l’état et la configuration d’une séquence distribuée. Les colonnes
minvalue,maxvalue,start,incetcacheont la même signification que dans la vue pg_sequenceset indiquent les options avec lesquelles la séquence a été créée. La colonne lastvalindique la dernière valeur allouée ou réservée dans un objet de séquence distribuée. Cela ne signifie pas que la valeur a déjà été utilisée, puisque les routeurs conservent les fragments de séquence localement.postgres_limitless=> SELECT * FROM rds_aurora.limitless_distributed_sequence WHERE sequence_name='test_serial_b_seq'; schema_name | sequence_name | lastval | minvalue | maxvalue | start | inc | cache -------------+-------------------+---------+----------+------------+-------+-----+------- public | test_serial_b_seq | 1250000 | 1 | 2147483647 | 1 | 1 | 1 (1 row) - rds_aurora.limitless_sequence_metadata
-
Cette vue montre les métadonnées de séquence distribuée et agrège les métadonnées de séquence provenant des nœuds du cluster. Elle utilise les colonnes suivantes :
-
subcluster_id: l’ID du nœud du cluster qui possède un fragment. -
Fragment actif : fragment d’une séquence en cours d’utilisation (
active_minvalue,active_maxvalue). -
Fragment réservé : le fragment local qui sera utilisé ensuite (
reserved_minvalue,reserved_maxvalue). -
local_last_value: la dernière valeur observée à partir d’une séquence locale. -
chunk_size: la taille d’un fragment, telle qu’elle a été configurée lors de la création.
postgres_limitless=> SELECT * FROM rds_aurora.limitless_sequence_metadata WHERE sequence_name='test_serial_b_seq' order by subcluster_id; subcluster_id | sequence_name | schema_name | active_minvalue | active_maxvalue | reserved_minvalue | reserved_maxvalue | chunk_size | chunk_state | local_last_value ---------------+-------------------+-------------+-----------------+-----------------+-------------------+-------------------+------------+-------------+------------------ 1 | test_serial_b_seq | public | 500001 | 750000 | 1000001 | 1250000 | 250000 | 1 | 550010 2 | test_serial_b_seq | public | 250001 | 500000 | 750001 | 1000000 | 250000 | 1 | (2 rows) -
Résolution des problèmes liés aux séquences
Les problèmes suivants peuvent survenir avec les séquences.
- La taille des fragments est insuffisante
-
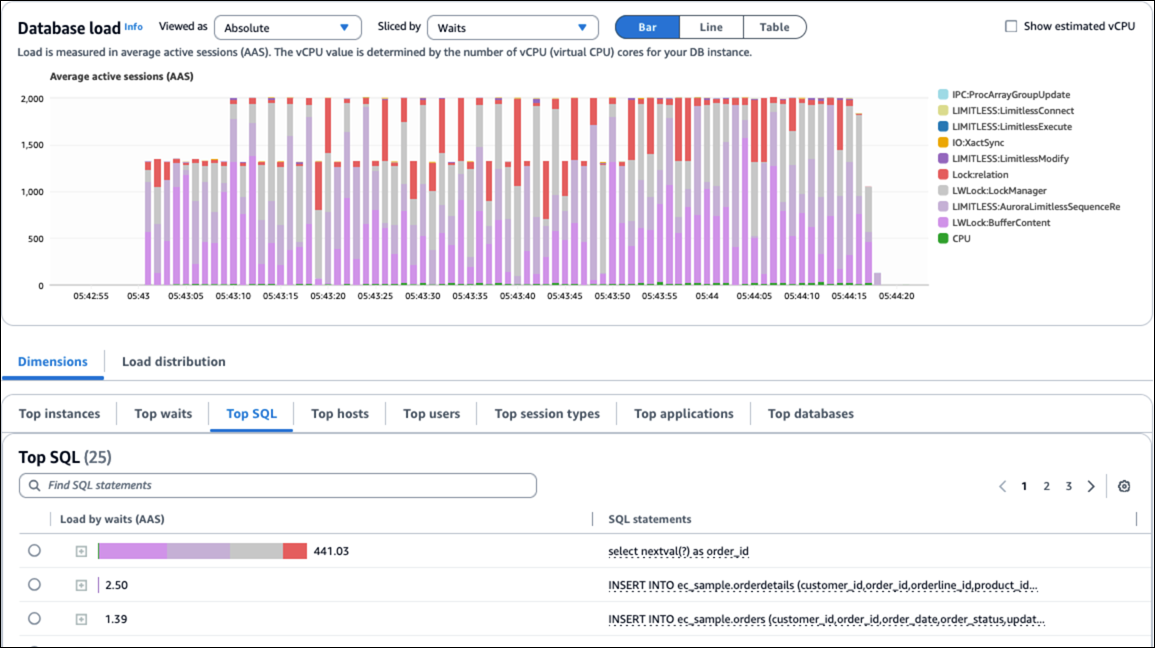
Si la taille des fragments n’est pas suffisamment grande et que le taux de transactions est élevé, les processus en arrière-plan risquent de ne pas avoir le temps de demander de nouveaux fragments avant que les fragments actifs ne soient épuisés. Cela peut entraîner une contention et des événements d’attente tels que
LIMITLESS:AuroraLimitlessSequenceReplace,LWLock:LockManager,LockrelationetLWlock:bufferscontent.Augmentez la valeur du paramètre
rds_aurora.limitless_sequence_chunk_size. - Le cache de séquence défini est trop élevé
-
Dans PostgreSQL, la mise en cache des séquences s’effectue au niveau de la session. Chaque session alloue des valeurs de séquence successives lors d’un accès à l’objet de séquence et augmente la
last_valuede l’objet de la séquence en conséquence. Par la suite, les utilisations denextvalau sein de la même session retournent directement les valeurs préallouées, sans interaction avec l’objet de séquence.Tous les numéros alloués mais non utilisés au cours d’une session sont perdus à la fin de cette dernière, ce qui entraîne des « trous » dans la séquence. Cette situation peut provoquer une consommation rapide du sequence_chunk et générer des contentions et événements d’attente comme
LIMITLESS:AuroraLimitlessSequenceReplace,LWLock:LockManager,LockrelationetLWlock:bufferscontent.Réduisez le paramètre de mise en cache des séquences.
La figure suivante montre les événements d’attente provoqués par des problèmes de séquence.