Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Blocages distribués dans Aurora PostgreSQL Limitless Database
Dans un groupe de partitions de base de données, des blocages peuvent survenir entre des transactions distribuées entre différents routeurs et partitions. Par exemple, deux transactions distribuées simultanées couvrant deux partitions sont exécutées, comme illustré ci-après.
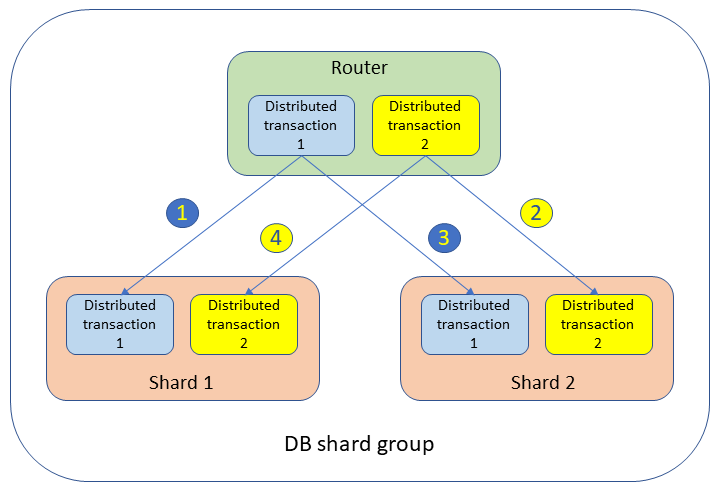
Les transactions verrouillent les tables et créent des événements d’attente dans les deux partitions comme suit :
-
Transaction distribuée 1 :
UPDATEtableSETvalue= 1 WHERE key = 'shard1_key';Cette transaction conserve un verrou sur la partition 1.
-
Transaction distribuée 2 :
UPDATEtableSETvalue= 2 WHERE key = 'shard2_key';Cette transaction conserve un verrou sur la partition 2.
-
Transaction distribuée 1 :
UPDATEtableSETvalue= 3 WHERE key = 'shard2_key';La transaction distribuée 1 est en attente sur la partition 2.
-
Transaction distribuée 2 :
UPDATEtableSETvalue= 4 WHERE key = 'shard1_key';La transaction distribuée 2 est en attente sur la partition 1.
Dans ce scénario, ni la partition 1 ni la partition 2 ne détectent le problème : la transaction 1 attend la transaction 2 sur la partition 2, tandis que la transaction 2 attend la transaction 1 sur la partition 1. D’un point de vue global, la transaction 1 attend la transaction 2, et la transaction 2 attend la transaction 1. Cette situation dans laquelle deux transactions sur deux partitions différentes s’attendent l’une l’autre est appelée blocage distribué.
Aurora PostgreSQL Limitless Database peut détecter et résoudre automatiquement les blocages distribués. Un routeur du groupe de partitions de base de données est averti lorsqu’une transaction met trop de temps à acquérir une ressource. Le routeur recevant la notification commence à collecter les informations nécessaires auprès de l’ensemble des routeurs et des partitions du groupe de partitions de base de données. Le routeur met ensuite fin aux transactions impliquées dans un blocage distribué, jusqu’à ce que les autres transactions du groupe de partitions de base de données puissent se poursuivre sans se bloquer mutuellement.
Lorsque le routeur met fin à une transaction impliquée dans un blocage distribué, le message d’erreur ci-dessous est envoyé :
ERROR: aborting transaction participating in a distributed deadlock
Le paramètre de rds_aurora.limitless_distributed_deadlock_timeout du cluster de bases de données définit la durée pendant laquelle chaque transaction attend une ressource avant de demander au routeur de vérifier s’il existe un blocage distribué. Vous pouvez augmenter la valeur du paramètre si votre charge de travail est moins susceptible de rencontrer des situations de blocage. La valeur par défaut est de 1000 millisecondes (1 seconde).
Le cycle de blocage distribué est publié dans les journaux PostgreSQL lorsqu’un blocage entre nœuds est détecté et résolu. Les informations relatives à chaque processus impliqué dans le blocage sont les suivantes :
-
Nœud coordinateur qui a lancé la transaction
-
ID de transaction virtuelle (xid) de la transaction sur le nœud coordinateur, au format
backend_id/backend_local_xid -
ID de session distribuée de la transaction
