Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Réalisation d’une démonstration de faisabilité avec Amazon Aurora
Vous trouverez ci-après une explication de la manière de configurer et d’exécuter une démonstration de faisabilité pour Aurora. Une démonstration de faisabilité est une investigation que vous faites pour voir si Aurora convient bien à votre application. La démonstration de faisabilité peut vous aider à comprendre les fonctions d’Aurora dans le contexte de vos propres applications de base de données, ainsi qu’à comparer Aurora à votre environnement de base de données actuel. Elle peut également vous montrer le niveau d’effort dont vous avez besoin pour déplacer les données, transposer le code SQL, ajuster les performances et adapter vos procédures de gestion actuelles.
Dans cette rubrique, vous trouverez une présentation et une description pas à pas des décisions et des procédures de haut niveau impliquées dans l’exécution d’une démonstration de faisabilité, répertoriées ci-après. Pour obtenir des instructions détaillées, vous pouvez suivre les liens vers la documentation complète pour des sujets spécifiques.
Présentation d’une démonstration de faisabilité Aurora
Lorsque vous réalisez une démonstration de faisabilité pour Amazon Aurora, vous voyez ce qu’il faut faire pour déplacer vos données et vos applications SQL existantes vers Aurora. Vous étudiez les aspects importants d’Aurora à grande échelle, en utilisant un volume de données et d’activités représentatif de votre environnement de production. L’objectif est de prendre confiance dans le fait que les points forts d’Aurora concordent bien avec les défis qui vous amènent à dépasser votre infrastructure de base de données précédente. À la fin d’une démonstration de faisabilité, vous disposez d’un plan concret pour effectuer des tests d’application et une comparaison des performances à plus grande échelle. À ce stade, vous comprenez les principaux éléments de travail qui vous attendent sur le chemin d’un déploiement en production.
Les conseils qui vous seront donnés sur les bonnes pratiques peuvent vous éviter des erreurs courantes qui posent problème lors des essais comparatifs. Toutefois, cette rubrique ne couvre pas les processus pas à pas de réalisation des essais comparatifs ni d’ajustement des performances. Ces procédures varient selon votre charge de travail et les fonctions Aurora que vous utilisez. Pour obtenir des informations détaillées, consultez la documentation relative aux performances, telle que Gestion des performances et dimensionnement des clusters de bases de données Aurora, Améliorations des performances Amazon Aurora MySQL, Performance et mise à l’échelle d’Amazon Aurora PostgreSQL et Surveillance de la charge de la base de données avec Performance Insights sur .
Les informations de cette rubrique s’appliquent principalement aux applications dans lesquelles votre organisation écrit du code et conçoit un schéma, et qui prennent en charge les moteurs de bases de données open source MySQL et PostgreSQL. Si vous testez une application commerciale ou du code généré par une infrastructure d’application, vous n’avez peut-être pas la flexibilité d’appliquer toutes les consignes. Dans de tels cas, contactez votre AWS représentant pour savoir s'il existe des meilleures pratiques ou des études de cas Aurora correspondant à votre type d'application.
1. Identifier vos objectifs
Lorsque vous évaluez Aurora dans le cadre d’une démonstration de faisabilité, vous choisissez les mesures à effectuer et la manière d’évaluer la réussite de l’exercice.
Vous devez vous assurez que toutes les fonctionnalités de votre application sont compatibles avec Aurora. Les versions majeures d’Aurora étant compatibles avec les versions majeures correspondantes de MySQL et PostgreSQL, la plupart des applications développées pour ces moteurs sont également compatibles avec Aurora. Toutefois, vous devez encore valider la compatibilité application par application.
Par exemple, certains choix de configuration que vous faites lorsque vous configurez un cluster Aurora influencent le fait que vous puissiez ou deviez utiliser des fonctions de base de données particulières. Vous pouvez commencer avec le type de cluster Aurora à l’usage le plus général, appelé provisionné. Vous pouvez alors décider si une configuration spécialisée, telle qu’une requête parallèle ou sans serveur, offre des avantages pour votre charge de travail.
Utilisez les questions suivantes pour mieux identifier et quantifier vos objectifs :
-
Aurora prend-il en charge tous les cas d’utilisation fonctionnels de votre charge de travail ?
-
Quels niveau de charge ou taille de jeu de données voulez-vous ? Pouvez-vous effectuer une mise à l’échelle pour atteindre ce niveau ?
-
Quelles sont vos besoins spécifiques en matière de latence et de débit de requêtes ? Pouvez-vous parvenir à les satisfaire ?
-
Quelles sont les durées d’indisponibilité planifiées et non planifiées minimum acceptables pour votre charge de travail ? Pouvez-vous parvenir à cela ?
-
Quelles sont les métriques nécessaires pour assurer l’efficacité opérationnelle ? Pouvez-vous les surveiller avec précision ?
-
Aurora prend-il en charge vos objectifs professionnels spécifiques, tels que la réduction des coûts, la croissance du déploiement ou la vitesse de mise en service ? Avez-vous une possibilité de quantifier ces objectifs ?
-
Pouvez-vous satisfaire toutes les exigences de sécurité et de compatibilité pour votre charge de travail ?
Prenez le temps d’acquérir les connaissances nécessaires sur les capacités de plateforme et les moteurs de base de données Aurora, et passez en revue la documentation du service. Prenez bonne note de toutes les fonctionnalités qui peuvent vous aider à atteindre les résultats que vous souhaitez. L'une d'entre elles pourrait être la consolidation des charges de travail, décrite dans le billet AWS de blog sur la base de données Comment planifier et optimiser la compatibilité d'Amazon Aurora avec MySQL pour les charges de travail consolidées
2. Comprendre les caractéristiques de votre charge de travail
Évaluez Aurora dans le contexte du cas d’utilisation que vous envisagez. Aurora est un choix judicieux pour les charges de travail de traitement de transaction en ligne (OLTP). Vous pouvez également exécuter des rapports sur le cluster qui détient les données OLTP en temps réel sans mettre en service un cluster d’entrepôt de données séparé. Vous pouvez déterminer si votre cas d’utilisation appartient à l’une de ces catégories en recherchant les caractéristiques suivantes :
-
Haute simultanéité avec des dizaines, des centaines ou des milliers de clients simultanés.
-
Grand volume de requêtes à faible latence (de quelques millisecondes à quelques secondes).
-
Transactions brèves en temps réel.
-
Modèles de requêtes hautement sélectifs avec recherches basées sur les index.
-
Pour HTAP, requêtes analytiques qui peuvent tirer profit des requêtes parallèles d’Aurora.
L’un des facteurs clés affectant vos choix de base de données est la vitesse des données. Une grande vitesse implique des insertions et des mises à jour très fréquentes des données. Un tel système peut compter des milliers de connexions et des centaines de milliers de requêtes simultanées de lecture et d’écriture dans une base de données. Dans les systèmes à grande vitesse, les requêtes affectent habituellement un nombre relativement faible de lignes et accèdent généralement à plusieurs colonnes d’une même ligne.
Aurora est conçu pour traiter les données à grande vitesse. Selon la charge de travail, un cluster Aurora doté d’une instance de base de données r4.16xlarge individuelle peut traiter plus de 600 000 instructions SELECT par seconde. Toujours en fonction de la charge de travail, un tel cluster peut traiter 200 000 instructions INSERT, UPDATE et DELETE par seconde. Aurora est une base de données de stockage de lignes parfaitement adaptée aux charges de travail OLTP à volume élevé, à haut débit et hautement parallélisées.
Aurora peut également exécuter des requêtes de rapport sur le cluster qui traite la charge de travail OLTP. Aurora prend en charge jusqu’à 15 réplicas, chacun intervenant en moyenne à 10–20 millisecondes de l’instance principale. Les analystes peuvent interroger les données OLTP en temps réel sans copier les données dans un cluster d’entrepôt de données séparé. Avec les clusters Aurora qui utilisent la fonction de requête parallèle, vous pouvez décharger une grande partie du travail de traitement, de filtrage et d’agrégation dans le sous-système de stockage Aurora distribué massivement.
Utilisez cette phase de planification pour vous familiariser avec les fonctionnalités d'Aurora, AWS des autres services AWS Management Console, du et du AWS CLI. De plus, vérifiez comment ces éléments fonctionnent avec les autres outils que vous envisagez d’utiliser dans la démonstration de faisabilité.
3. Entraînez-vous avec le AWS Management Console ou AWS CLI
Ensuite, entraînez-vous avec le AWS Management Console ou le AWS CLI, pour vous familiariser avec ces outils et avec Aurora.
Entraînez-vous avec AWS Management Console
Les activités initiales suivantes avec les clusters de bases de données Aurora visent principalement à vous familiariser avec l' AWS Management Console environnement et à vous entraîner à configurer et à modifier des clusters Aurora. Si vous utilisez les moteurs PostgreSQL-compatible de base de données MySQL-compatible et avec Amazon RDS, vous pouvez tirer parti de ces connaissances lorsque vous utilisez Aurora.
En tirant profit du modèle de stockage partagé Aurora et de fonctions telles que la réplication et les instantanés, vous pouvez traiter des clusters de bases de données complets comme un autre type d’objet que vous pouvez manipuler librement. Vous pouvez configurer, supprimer et modifier fréquemment la capacité des clusters Aurora au cours de la démonstration de faisabilité. Vous n’êtes pas tenu de conserver vos choix précoces en matière de capacité, de paramètres de base de données et de disposition de données physiques.
Pour commencer, configurez un cluster Aurora vide. Choisissez le type de capacité provisionné et un emplacement régional pour vos expériences initiales.
Connectez-vous à ce cluster en utilisant un programme client tel que l’application de ligne de commande SQL. Au départ, vous vous connectez à l’aide du point de terminaison de cluster. Vous vous connectez à ce point de terminaison pour effectuer toutes les opérations d’écriture, telles que les instructions en langage de manipulation de données (DDL) et les processus d’extraction, de transformation et de chargement. Ultérieurement dans la démonstration de faisabilité, vous connectez des sessions impliquant beaucoup de requêtes à l’aide du point de terminaison de lecteur, lequel distribue la charge de travail des requêtes entre plusieurs instances de base de données dans le cluster.
Effectuez une montée en charge du cluster en ajoutant d’autres réplicas Aurora. Pour ces procédures, consultez Réplication avec Amazon Aurora. Augmentez ou diminuez les instances de base de données en modifiant la classe d' AWS instance. Découvrez comment Aurora simplifie ces types d’opérations, de sorte que si vos estimations initiales de capacité système sont inexactes, vous pouvez effectuer des ajustements ultérieurs sans tout recommencer.
Créez un instantané et restaurez-le dans un cluster différent.
Examinez les métriques du cluster pour voir ses activités au fil du temps et la manière dont ces métriques s’appliquent aux instances de base de données dans le cluster.
Il est utile de se familiariser avec la façon de faire ces choses dès AWS Management Console le début. Une fois que vous comprenez ce que vous pouvez faire avec Aurora, vous pouvez progresser et automatiser ces opérations à l’aide de AWS CLI. Dans les sections suivantes, vous trouverez plus de détails sur les procédures et les bonnes pratiques relatives à ces activités, à effectuer au cours de la période de démonstration de faisabilité.
Entraînez-vous avec AWS CLI
Nous recommandons l’automatisation des procédures de déploiement et de gestion, même dans un paramétrage de démonstration de faisabilité. Pour ce faire, familiarisez-vous avec le AWS CLI si ce n'est pas déjà fait. Si vous utilisez les moteurs PostgreSQL-compatible de base de données MySQL-compatible et avec Amazon RDS, vous pouvez tirer parti de ces connaissances lorsque vous utilisez Aurora.
Aurora implique généralement des groupes d’instances de base de données organisés en clusters. Ainsi, de nombreuses opérations impliquent de déterminer quelles instances de base de données sont associées à un cluster, puis d’effectuer les opérations administratives dans une boucle pour toutes ces instances.
Par exemple, vous pouvez automatiser des étapes telles que la création de clusters Aurora, puis leur mise à l’échelle ascendante avec des classes d’instance plus grandes ou leur montée en charge avec des instances de base de données supplémentaires. Cela vous aidera à répéter des phases quelconques de votre démonstration de faisabilité et à explorer des scénarios hypothétiques avec différents types de configuration de clusters Aurora.
Découvrez les capacités et les limites d’outils de déploiement d’infrastructure tels qu AWS CloudFormation. Vous pouvez constater que des activités que vous effectuez dans le contexte d’une démonstration de faisabilité ne sont pas adaptées à une utilisation en production. Par exemple, le CloudFormation comportement de modification consiste à créer une nouvelle instance et à supprimer l'instance actuelle, y compris ses données. Pour plus de détails sur ce comportement, consultez Comportements de mise à jour des ressources d’une pile dans le Guide de l’utilisateur AWS CloudFormation .
4. Créer votre cluster Aurora
Avec Aurora, vous pouvez explorer des scénarios hypothétiques en ajoutant des instances de base de données au cluster et en effectuant une mise à l’échelle ascendante des instances de base de données vers des classes d’instance plus puissantes. Vous pouvez également créer des clusters avec différents paramètres de configuration pour exécuter côte à côte la même charge de travail. Avec Aurora, vous disposez d’une grande flexibilité pour configurer, supprimer et reconfigurer des clusters de bases de données. Partant de là, il est utile de pratiquer ces techniques dans les premières phases du processus de démonstration de faisabilité. Pour découvrir les procédures générales permettant de créer des clusters Aurora, consultez Création d’un cluster de bases de données Amazon Aurora.
Là où cela est possible, commencez avec un cluster en utilisant les paramètres suivants. Ignorez cette étape seulement si vous avez certains cas d’utilisation spécifiques en tête. Par exemple, vous pouvez ignorer cette étape si votre cas d’utilisation requiert un type de cluster Aurora spécialisé. Vous pouvez également l’ignorer si vous avez besoin d’une combinaison particulière de version et de moteur de base de données.
-
Désactivez Easy create (Création facile). Pour la démonstration de faisabilité, nous vous recommandons d’être conscient de tous les paramètres que vous choisissez afin de pouvoir créer ultérieurement des clusters identiques ou légèrement différents.
-
Utilisez une version de moteur de base de données récente. Ces combinaisons de version et de moteur de base de données présentent une compatibilité étendue avec les autres fonctionnalités Aurora, ainsi qu’une utilisation importante des clients pour les applications de production.
-
Aurora MySQL version 3.x (compatible avec MySQL 8.0)
-
Aurora PostgreSQL version 15.x ou 16.x
-
-
Choisissez le modèle Dev/Test. Ce choix n’est pas significatif pour vos activités de démonstration de faisabilité.
-
Pour DB instance class (Classe d’instance de base de données), choisissez Memory optimized classes (Classes à mémoire optimisée) et l’une des classes d’instance xlarge. Vous pouvez ajuster la classe d’instance ultérieurement, vers le haut ou le bas.
-
Sous Multi-AZ Déploiement, choisissez Créer un nœud Aurora Replica ou Reader dans une autre AZ. Un grand nombre des aspects les plus utiles d’Aurora impliquent des clusters de plusieurs instances de base de données. Il est judicieux de toujours commencer avec au moins deux instances de base de données dans tout nouveau cluster. L’utilisation d’une autre zone de disponibilité pour la seconde instance de base de données permet de mieux tester les différents scénarios à haute disponibilité.
-
Lorsque vous sélectionnez des noms pour les instances de base de données, utilisez une convention de nommage générique. Ne faites référence à aucune instance de base de données de cluster en tant qu’« enregistreur », car différentes instances de base de données assument ces rôles, selon les besoins. Nous vous recommandons d’utiliser quelque chose comme
clustername-az-serialnumber, par exemplemyprodappdb-a-01. Ces éléments identifient de manière unique l’instance de base de données et son placement. -
Définissez une valeur élevée de conservation des sauvegardes pour le cluster Aurora. Avec une longue période de conservation, vous pouvez effectuer une reprise ponctuelle sur une période de 35 jours. Vous pouvez réinitialiser votre base de données à un état connu après l’exécution de tests impliquant des instructions DDL et DML (langage de manipulation de données). Vous pouvez également effectuer une récupération si vous supprimez ou modifiez des données par erreur.
-
Activez des fonctions de récupération, de journalisation et de surveillance supplémentaires à la création du cluster. Activez toutes les options disponibles sous Retour en arrière, Performance Insights, Surveillance et Exportations des journaux. Lorsque ces fonctions sont activées, vous pouvez tester l’adéquation de fonctions telles que le retour en arrière, la surveillance améliorée et Performance Insights pour votre charge de travail. Vous pouvez facilement étudier les performances et effectuer une résolution des problèmes au cours de la démonstration de faisabilité.
5. Configurer votre schéma
Sur le cluster Aurora, configurez des bases de données, des tables, des index, des clés étrangères et d’autres objets de schéma pour votre application. Si vous passez d'un autre système MySQL-compatible ou d'un système PostgreSQL-compatible de base de données, attendez-vous à ce que cette étape soit simple et directe. Vous utilisez les mêmes ligne de commande et syntaxe SQL, ou d’autres applications clientes qui vous sont familières pour votre moteur de base de données.
Pour exécuter les instructions SQL sur votre cluster, recherchez son point de terminaison de cluster et fournissez cette valeur en tant que paramètre de connexion à votre application cliente. Vous trouverez le point de terminaison de cluster dans l’onglet Connectivity (Connectivité) de la page de détails de votre cluster. Le point de terminaison de cluster est celui intitulé Writer (Rédacteur). L’autre point de terminaison, intitulé Reader (Lecteur), représente une connexion en lecture seule que vous pouvez fournir aux utilisateurs finaux qui exécutent des rapports ou d’autres requêtes en lecture seule. Pour obtenir de l’aide face à des problèmes de connexion à votre cluster, consultez Connexion à un cluster de bases de données Amazon Aurora.
Si vous déplacez votre schéma et vos données à partir d’un système de base de données différent, préparez-vous à apporter à ce stade certaines modifications à votre schéma. Ces modifications de schéma doivent correspondre à la syntaxe SQL et aux capacités disponibles dans Aurora. Vous pouvez exclure certains déclencheurs, colonnes, contraintes ou autres objets de schéma à ce stade. Cela peut s’avérer utile, notamment si ces objets nécessitent des adaptations pour la compatibilité d’Aurora et ne sont pas significatifs pour vos objectifs en matière de démonstration de faisabilité.
Si vous migrez depuis un système de base de données doté d'un moteur sous-jacent différent de celui d'Aurora, pensez à utiliser le AWS Schema Conversion Tool (AWS SCT) pour simplifier le processus. Pour plus de détails, consultez le Guide de l’utilisateur AWS Schema Conversion Tool. Pour obtenir des informations générales sur les activités de migration et de portage, consultez le AWS livre blanc sur la migration de vos bases de données vers Amazon Aurora
Au cours de cette phase, vous pouvez évaluer la présence ou l’absence d’inefficacités dans votre configuration de schéma, par exemple dans votre stratégie d’indexation ou dans d’autres structures de table, telles que les tables partitionnées. De telles inefficacités peuvent être amplifiées lorsque vous déployez votre application sur un cluster doté de plusieurs instances de base de données et d’une charge de travail importante. Déterminez si vous pouvez optimiser actuellement de tels aspects de performances, ou durant des activités ultérieures, telles qu’un test complet d’évaluation.
6. Importer vos données
Durant la démonstration de faisabilité, vous étudiez les données, ou un échantillon représentatif, provenant de votre système de base de données antérieur. Si possible, configurez au moins certaines données dans chacune de vos tables. Cela vous aide à tester la compatibilité de tous les types de données et fonctions de schéma. Après vous être exercé à l’utilisation des fonctions Aurora de base, effectuez une mise à l’échelle ascendante de la quantité de données. D’ici la fin de votre démonstration de faisabilité, vous devez tester vos outils ETL, les requêtes et la charge de travail globale avec un jeu de données suffisamment grand pour pouvoir en tirer des conclusions précises.
Vous pouvez utiliser plusieurs techniques pour apporter des données de sauvegarde physique ou logique dans Aurora. Pour obtenir des détails, consultez Migration de données vers un cluster de bases de données Amazon Aurora MySQL ou Migration des données vers Amazon Aurora avec compatibilité PostgreSQL selon le moteur de base de données que vous utilisez dans la démonstration de faisabilité.
Faites des expériences avec les technologies et les outils ETL que vous prenez en considération. Déterminez ce qui répond le mieux à vos besoins. Prenez en compte à la fois le débit et la flexibilité. Par exemple, certains outils ETL effectuent un transfert en une seule fois, alors que d’autres impliquent une réplication continue à partir de l’ancien système vers Aurora.
Si vous migrez d'un MySQL-compatible système vers Aurora MySQL, vous pouvez utiliser les outils de transfert de données natifs. Il en va de même si vous migrez d'un PostgreSQL-compatible système vers Aurora PostgreSQL. Si vous migrez depuis un système de base de données qui utilise un moteur sous-jacent différent de celui d'Aurora, vous pouvez tester le AWS Database Migration Service (AWS DMS). Pour plus de détails AWS DMS, consultez le guide de AWS Database Migration Service l'utilisateur.
Pour plus de détails sur les activités de migration et de portage, consultez le AWS livre blanc sur le manuel de migration Aurora
7. Déplacer votre code SQL
Essayer les applications SQL et associées requiert différents niveaux d’effort, selon les cas. En particulier, le niveau d'effort dépend du fait que vous quittez un PostgreSQL-compatible système MySQL-compatible ou un autre.
-
Si vous effectuez un déplacement à partir de RDS for MySQL ou RDS pour PostgreSQL, les modifications SQL sont suffisamment petites pour que vous puissiez essayer d’utiliser le code SQL d’origine avec Aurora et d’incorporer manuellement les modifications nécessaires.
-
De même, si vous effectuez un déplacement à partir d’une base de données locale compatible avec MySQL ou PostgreSQL, vous pouvez essayer d’utiliser le code SQL d’origine et d’incorporer manuellement les modifications.
-
Si vous partez d’une base de données commerciale différente, les modifications SQL requises sont trop importantes. Dans ce cas, pensez à utiliser le AWS SCT.
Au cours de cette phase, vous pouvez évaluer la présence ou l’absence d’inefficacités dans votre configuration de schéma, par exemple dans votre stratégie d’indexation ou dans d’autres structures de table, telles que les tables partitionnées. Déterminez si vous pouvez optimiser actuellement de tels aspects de performances, ou durant des activités ultérieures, telles qu’un test complet d’évaluation.
Vous pouvez vérifier la logique de connexion de base de données dans votre application. Pour tirer profit du traitement distribué d’Aurora, vous pouvez avoir besoin d’utiliser des connexions distinctes pour les opérations de lecture et d’écriture, et d’utiliser des sessions relativement courtes pour les opérations de requête. Pour obtenir des informations sur les connexions, consultez 9. Se connecter à Aurora.
Réfléchissez aux concessions et compromis éventuels que vous avez dû faire pour contourner les problèmes dans votre base de données de production. Prévoyez du temps dans votre calendrier de démonstration de faisabilité pour apporter des améliorations à vos requêtes et à la conception de votre schéma. Pour juger si vous pouvez obtenir des victoires faciles en matière de performances, de coût d’exploitation et d’évolutivité, essayez les applications d’origine et modifiées côte à côte sur différents clusters Aurora.
Pour plus de détails sur les activités de migration et de portage, consultez le AWS livre blanc sur le manuel de migration Aurora
8. Spécifier les paramètres de configuration
Vous pouvez également passer en revue vos paramètres de configuration de base de données dans le cadre de l’exercice de démonstration de faisabilité d’Aurora. Vos paramètres de configuration MySQL ou PostgreSQL sont peut-être déjà réglés pour favoriser les performances et l’évolutivité dans votre environnement actuel. Le sous-système de stockage d’Aurora est adapté et réglé pour un environnement distribué basé sur le cloud avec un sous-système de stockage à grande vitesse. Par conséquent, de nombreux anciens paramètres de moteur de base de données ne s’appliquent pas. Nous vous recommandons de conduire vos expériences initiales avec les paramètres de configuration Aurora par défaut. Réappliquez les paramètres de votre environnement actuel seulement si vous rencontrez des goulots d’étranglement de performances et d’évolutivité. Si cela vous intéresse, vous pouvez approfondir ce sujet dans la section Présentation du moteur de stockage Aurora
Aurora favorise la réutilisation des paramètres de configuration optimaux pour une application particulière ou un cas d’utilisation particulier. Au lieu de modifier un fichier de configuration distinct pour chaque instance de base de données, vous gérez des ensembles de paramètres que vous assignez à des clusters entiers ou à des instances de base de données spécifiques. Par exemple, le paramètre de fuseau horaire s’applique à toutes les instances de base de données du cluster, et vous pouvez ajuster le paramètre de taille du cache de page pour chaque instance de base de données.
Vous commencez avec l’un des ensembles de paramètres par défaut et appliquez les modifications aux seuls paramètres dont vous devez optimiser le réglage. Pour obtenir des détails sur l’utilisation des groupes de paramètres, consultez Paramètres de cluster de bases de données et d’instance de base de données Amazon Aurora. Pour découvrir les paramètres de configuration qui sont applicables ou non aux clusters Aurora, consultez Paramètres de configuration d’Aurora MySQL ou Paramètres Amazon Aurora PostgreSQL. selon votre moteur de base de données.
9. Se connecter à Aurora
Comme vous pouvez le constater en effectuant votre configuration initiale de schéma et de données et en exécutant des exemples de requête, vous pouvez vous connecter à différents points de terminaison dans un cluster Aurora. Le point de terminaison à utiliser varie selon que l’opération correspond à une lecture, telle qu’une instruction SELECT, ou à une écriture, telle qu’une instruction CREATE ou INSERT. Lorsque vous augmentez la charge de travail sur un cluster Aurora et essayez les fonctions Aurora, il est important pour votre application d’affecter chaque opération au point de terminaison approprié.
En utilisant le point de terminaison du cluster pour les opérations d'écriture, vous vous connectez toujours à une instance de base de données du cluster qui en a la read/write capacité. Par défaut, une seule instance de base de données dans un cluster Aurora est read/write capable. Cette instance de base de données est appelée instance principale. Si l’instance principale d’origine devient non disponible, Aurora active un mécanisme de basculement et une autre instance de base de données prend la relève comme instance principale.
De même, en dirigeant les instructions SELECT vers le point de terminaison de lecteur, vous répartissez le travail de traitement des requêtes entre les instances de base de données du cluster. Chaque connexion de lecteur est assignée à une instance de base de données différente au moyen de la résolution DNS de type tourniquet (round-robin). La réalisation de la plus grande partie du travail de requête sur les réplicas Aurora de base de données en lecture seule réduit la charge qui s’exerce sur l’instance principale, ce qui libère cette dernière pour traiter les instructions DDL et DML.
L’utilisation de ces points de terminaison réduit la dépendance sur les noms d’hôte codés en dur et aide votre application à récupérer plus rapidement après des échecs d’instance de base de données.
Note
Aurora possède également des points de terminaison personnalisés que vous créez. Ces points de terminaison ne sont généralement pas nécessaires au cours d’une démonstration de faisabilité.
Les réplicas Aurora sont sujets à un retard de réplication, généralement compris entre 10 et 20 millisecondes. Vous pouvez surveiller ce retard de réplication et décider s’il figure dans la plage de vos exigences de cohérence des données. Dans certains cas, vos requêtes de lecture peuvent exiger une forte cohérence de lecture (cohérence de type lecture après écriture). Dans ces cas, vous pouvez continuer à utiliser le point de terminaison de cluster et non pas le point de terminaison de lecteur.
Pour tirer pleinement parti des capacités d’Aurora pour l’exécution parallèle distribuée, vous pouvez être amené à modifier la logique de connexion. Votre objectif est d’éviter d’envoyer toutes les demandes de lecture à l’instance principale. Les réplicas Aurora en lecture seule sont en attente, tous avec les mêmes données, prêts à traiter les instructions SELECT. Codez votre logique d’application pour utiliser le point de terminaison approprié pour chaque type d’opération. Suivez ces instructions générales :
-
Évitez d’utiliser une seule chaîne de connexion codée en dur pour toutes les sessions de base de données.
-
Si possible, placez les opérations d’écriture, telles que les instructions DDL et DML, dans des fonctions, dans le code de votre application cliente. De cette manière, vous pouvez faire en sorte que différents types d’opérations utilisent des connexions spécifiques.
-
Élaborez des fonctions distinctes pour les opérations de requête. Aurora affecte chaque nouvelle connexion au point de terminaison de lecteur à un réplica Aurora différent, afin d’équilibrer la charge pour les applications nécessitant beaucoup d’opérations de lecture.
-
Pour les opérations impliquant des ensembles de requêtes, fermez et rouvrez la connexion au point de terminaison de lecteur lorsque chaque ensemble de requêtes associées se termine. Utilisez un regroupement de connexions si cette fonction est disponible dans votre pile logicielle. Le fait de diriger les requêtes vers différentes connexions aide Aurora à distribuer la charge de travail de lecture entre les instances de base de données du cluster.
Pour obtenir des informations générales sur la gestion des connexions et les points de terminaison pour Aurora, consultez Connexion à un cluster de bases de données Amazon Aurora. Pour une découverte approfondie de ce sujet, consultez le Manuel d’administrateur de base de données Aurora MySQL : gestion des connexions
10. Exécuter votre charge de travail
Une fois que les paramètres de schéma, de données et de configuration sont en place, vous pouvez commencer à vous exercer à utiliser le cluster en exécutant votre charge de travail. Dans la démonstration de faisabilité, utilisez une charge de travail qui reflète les aspects principaux de votre charge de travail de production. Nous vous recommandons de toujours prendre des décisions concernant les performances en utilisant des tests et des charges de travail réels plutôt que des benchmarks synthétiques tels que sysbench ou. TPC-C Dans la mesure du possible, rassemblez des mesures basées sur vos propres schéma, modèles de requête et volume d'utilisation.
Autant que possible, reproduisez les conditions réelles dans lesquelles l’application s’exécutera. Par exemple, vous exécutez généralement le code de votre application sur des instances Amazon EC2 situées dans la même AWS région et dans le même cloud privé virtuel (VPC) que le cluster Aurora. Si votre application de production s’exécute sur plusieurs instances EC2 réparties dans plusieurs zones de disponibilité, configurez votre environnement de démonstration de faisabilité de la même manière. Pour plus d’informations sur les régions AWS , consultez Régions et zones de disponibilité dans le Guide de l’utilisateur Amazon RDS. Pour en savoir plus sur le service Amazon VPC, consultez Qu’est-ce qu’Amazon VPC ? dans le Guide de l’utilisateur Amazon VPC.
Une fois que vous avez vérifié que les fonctions de base de votre application fonctionnent et que vous pouvez accéder aux données via Aurora, vous pouvez étudier les aspects du cluster Aurora. Certaines fonctions que vous pouvez essayer mettent en jeu des connexions simultanées à l’équilibrage de la charge, à des transactions simultanées et à la réplication automatique.
À ce stade, les mécanismes de transfert de données doivent être familiers et tels que vous puissiez exécuter des tests avec une plus grande proportion d’échantillons de données.
Cette phase permet de voir les effets du changement des paramètres de configuration, tels que les limites de mémoire et les limites de connexion. Réexaminez les procédures que vous avez explorées dans 8. Spécifier les paramètres de configuration.
Vous pouvez également effectuer des essais avec des mécanismes tels que la création et la restauration d’instantanés. Par exemple, vous pouvez créer des clusters avec différentes classes d' AWS instances, différents nombres de AWS répliques, etc. Ensuite, dans chaque cluster, vous pouvez restaurer le même instantané contenant votre schéma et toutes vos données. Pour découvrir les détails de ce cycle, consultez Création d’un instantané de cluster de bases de données et Restauration à partir d’un instantané de cluster de bases de données.
11. Mesurer les performances
Dans ce domaine, les bonnes pratiques sont conçues pour garantir que tous les processus et outils appropriés soient configurés de manière à isoler rapidement les comportements anormaux au cours des opérations mettant en jeu les charges de travail. Elles sont également élaborées pour vous assurer de pouvoir identifier de façon fiable toutes les causes applicables.
Vous pouvez toujours voir l’état actuel de votre cluster ou examiner les tendances au fil du temps en affichant l’onglet Surveillance. Cet onglet est disponible à partir de la page de détails de la console pour chaque cluster ou instance de base de données Aurora. Il affiche les statistiques du service CloudWatch de surveillance Amazon sous forme de graphiques. Vous pouvez filtrer les métriques par leur nom, par l’instance de base de données et par période.
Pour disposer de plus de choix dans l’onglet Surveillance, activez les options de surveillance améliorée et Performance Insights dans les paramètres du cluster. Vous pouvez également activer ultérieurement ces choix si vous ne l’avez pas fait lors de la configuration du cluster.
Pour mesurer les performances, vous pouvez principalement vous appuyer sur les graphiques qui montrent les activités pour le cluster Aurora tout entier. Vous pouvez vérifier si les réplicas Aurora ont une charge et des temps de réponse similaires. Vous pouvez également voir comment le travail est réparti entre l'instance read/write principale et les répliques Aurora en lecture seule. Dans le cas d’un déséquilibre entre les instances de base de données ou d’un problème affectant seulement une instance de base de données, vous pouvez examiner l’onglet Surveillance pour cette instance spécifique.
Une fois que l’environnement et la charge de travail réelle ont été configurés pour émuler votre application de production, vous pouvez mesurer la façon dont Aurora fonctionne. Les questions les plus importantes auxquelles il convient de répondre sont les suivantes :
-
Combien de requêtes par seconde Aurora traite-t-il ? Vous pouvez examiner les métriques de débit (Throughput) pour voir les chiffres pour divers types d’opérations.
-
Combien de temps faut-il en moyenne à Aurora pour traiter une requête donnée ? Vous pouvez examiner les métriques de latence (Latency) pour voir les chiffres pour divers types d’opérations.
Pour consulter les métriques de débit et de latence, consultez l’onglet Surveillance d’un cluster Aurora donné dans la console Amazon RDS
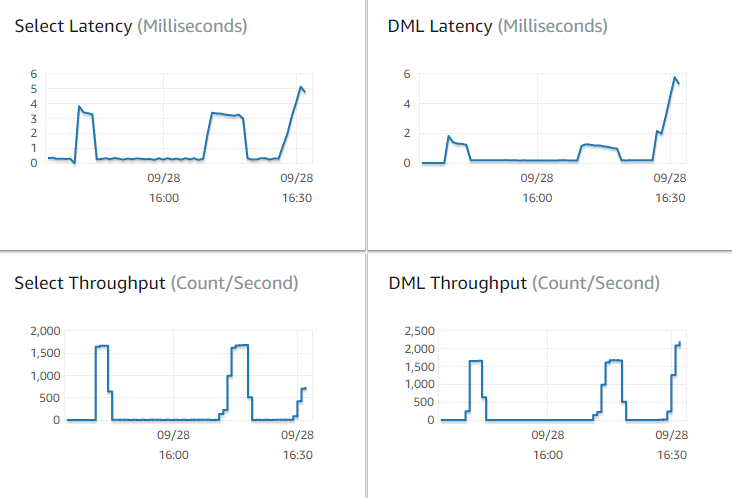
Si vous le pouvez, établissez des valeurs de référence pour ces métriques dans votre environnement actuel. Si ce n’est pas possible, établissez une référence sur le cluster Aurora en exécutant une charge de travail équivalente à votre application de production. Par exemple, exécutez votre charge de travail Aurora avec un nombre similaire d’utilisateurs et de requêtes simultanés. Ensuite, observez la manière dont les valeurs changent lorsque vous essayez différents paramètres de configuration, classes d’instance, tailles de cluster, etc.
Si les chiffres de débit sont inférieurs à ce que vous attendiez, poursuivez vos investigations pour déterminer les facteurs affectant les performances de base de données pour votre charge de travail. De même, si les chiffres de latence sont supérieurs à ce que vous attendiez, poursuivez vos investigations. Pour cela, surveillez les métriques secondaires du serveur de base de données (UC, mémoire, etc.). Vous pouvez voir si les instances de base de données sont proches de leurs limites. Vous pouvez également voir les capacités supplémentaires dont vos instances de base de données disposent pour traiter plus de requêtes simultanées, des requêtes portant sur des tables plus grandes, etc.
Astuce
Pour détecter les valeurs métriques situées en dehors des plages attendues, configurez des CloudWatch alarmes.
Lorsque vous évaluez la capacité et la taille idéales d’un cluster Aurora, vous pouvez trouver la configuration qui permet d’atteindre des performances d’application de pointe sans sur-approvisionnement de ressources. Un facteur important est de trouver la taille appropriée pour les instances de base de données du cluster Aurora. Commencez par sélectionner une taille d’instance qui possède une capacité d’UC et de mémoire similaire à celle de votre environnement de production actuel. Collectez les chiffres de débit et de latence pour la charge de travail à cette taille d’instance. Ensuite, mettez à l’échelle l’instance jusqu’à la taille supérieure suivante. Observez si les chiffres de débit et de latence s’améliorent. Réduisez également la taille de l’instance et observez si les chiffres de latence et de débit restent les mêmes. Votre objectif est d’obtenir le plus haut débit avec la plus basse latence sur la plus petite instance possible.
Astuce
Dimensionnez vos clusters Aurora et les instances de base de données associées avec une capacité existante suffisante pour traiter les pics de trafic imprévisibles et soudains. Pour les bases de données d’importance capitale, laissez au moins 20 % de capacité d’UC et de mémoire non utilisée.
Exécuter des tests de performances suffisamment longs pour mesurer les performances de base de données dans un état stable et à chaud. Vous pouvez avoir besoin d’exécuter la charge de travail pendant de nombreuses minutes ou même quelques heures avant d’atteindre cet état stable. Il est normal d’avoir une certaine variation en début d’exécution. Cette variation se produit, car chaque réplica Aurora fait chauffer ses caches sur la base des requêtes SELECT qu’il traite.
Aurora fonctionne le mieux avec des charges de travail transactionnelles impliquant plusieurs requêtes et utilisateurs simultanés. Pour vérifier que vous utilisez une charge suffisante pour obtenir des performances optimales, effectuez des évaluations qui utilisent le multithreading ou exécutez simultanément plusieurs instances des tests de performances. Mesurez les performances avec des centaines ou même des milliers de threads client simultanés. Simulez le nombre de threads simultanés que vous prévoyez dans votre environnement de production. Vous pouvez également effectuer des tests de contrainte supplémentaires avec plus de threads pour mesurer l’évolutivité d’Aurora.
12. Étudier la haute disponibilité d’Aurora
Un grand nombre des fonctions Aurora principales impliquent la haute disponibilité. Ces fonctions incluent la réplication automatique, le basculement automatique, les sauvegardes automatiques avec restauration à un instant dans le passé, ainsi que la capacité à ajouter des instances de base de données au cluster. La sécurité et la fiabilité qui émanent de fonctions telles que celles-ci sont importantes pour les applications d’importance capitale.
L’évaluation de ces fonctions requiert un certain état d’esprit. Dans les activités précédentes, telles que le mesurage des performances, vous observez les performances du système quand tout fonctionne correctement. Les tests de haute disponibilité exigent que vous pensiez dans le détail le comportement pour le pire scénario. Vous devez prendre en compte différents types d’échecs, même si de telles conditions sont rares. Vous pouvez introduire intentionnellement des problèmes pour vérifier la capacité du système à récupérer rapidement et correctement.
Astuce
Pour une preuve de concept, configurez toutes les instances de base de données d'un cluster Aurora avec la même classe d' AWS instance. Cela permet de tester les fonctions de disponibilité d’Aurora sans changements majeurs des performances et de l’évolutivité lorsque vous mettez hors connexion les instances de base de données pour simuler des défaillances.
Nous vous recommandons d’utiliser au moins deux instances dans chaque cluster Aurora. Les instances de base de données d’un cluster Aurora peuvent couvrir jusqu’à trois zones de disponibilité. Localisez chacune des deux ou trois premières instances de base de données dans une zone de disponibilité différente. Lorsque vous commencez à utiliser des clusters plus importants, répartissez vos instances de base de données sur toutes les AZ de votre AWS région. Cela augmente la capacité de tolérance aux pannes. Même si un problème affecte une zone de disponibilité complète, Aurora peut basculer vers une instance de base de données située dans une autre zone de disponibilité. Si vous utilisez un cluster doté de plus de trois instances, distribuez les instances de base de données aussi uniformément que possible sur les trois zones de disponibilité.
Astuce
Le stockage pour un cluster Aurora est indépendant des instances de base de données. Le stockage pour chaque cluster Aurora couvre toujours trois zones de disponibilité.
Lorsque vous testez des fonctions à haute disponibilité, utilisez toujours des instances de base de données d’une capacité identique dans votre cluster test. Cela permet d’éviter les modifications imprévisibles de performances, de latence, etc., chaque fois qu’une instance de base de données prend la relève d’une autre.
Pour découvrir comment simuler des conditions de défaillance pour tester des fonctions à haute disponibilité, consultez Test d’Amazon Aurora MySQL à l’aide de requêtes d’injection d’erreurs.
Dans le cadre de votre exercice de démonstration de faisabilité, l’un des objectifs est de trouver le nombre idéal d’instances de base de données et la classe d’instance optimale pour ces instances de base de données. Cela requiert d’équilibrer les exigences de performances et de haute disponibilité.
Pour Aurora, plus vous avez d’instances de base de données dans un cluster, plus cela profite à la haute disponibilité. L’augmentation du nombre d’instances de base de données améliore également la capacité de mise à l’échelle des applications nécessitant beaucoup d’opérations de lecture. Aurora peut distribuer plusieurs connexions pour les requêtes SELECT entre les réplicas Aurora en lecture seule.
D’un autre côté, la limitation du nombre d’instances de base de données réduit le trafic de réplication à partir du nœud principal. Le trafic de réplication consomme de la bande passante réseau, ce qui constitue un autre aspect des performances et de l’évolutivité globales. Ainsi, pour les applications OLTP qui demandent beaucoup d’opérations d’écriture, privilégiez un plus petit nombre de grandes instances de base de données à un grand nombre de petites instances de base de données.
Dans un cluster Aurora standard, une seule instance de base de données (l’instance principale) traite toutes les instructions DDL et DML. Les autres instances de base de données (les réplicas Aurora) traitent uniquement les instructions SELECT. Bien que les instances de base de données n’exécutent pas exactement la même quantité de travail, nous vous recommandons d’utiliser la même classe d’instance pour toutes les instances de base de données du cluster. De cette manière, si une défaillance survient et qu’Aurora promeut l’une des instances de base de données en lecture seule comme nouvelle instance principale, cette instance principale a la même capacité qu’avant.
Si vous avez besoin d’utiliser des instances de base de données de différentes capacités dans un même cluster, configurez des niveaux de basculement pour les instances de base de données. Ces niveaux déterminent l’ordre dans lequel les réplicas Aurora sont promus par le mécanisme de basculement. Placez les instances de base de données beaucoup plus grandes ou plus petites que les autres à un niveau de basculement inférieur. Cela garantit qu’ils seront choisis en dernier pour une promotion.
Exercez-vous à utiliser les fonctions de récupération de données d’Aurora, telles que la restauration automatique à un instant dans le passé, la restauration et les instantanés manuels, ainsi que le retour en arrière du cluster. Le cas échéant, copiez les instantanés dans d'autres AWS régions et restaurez-les dans d'autres AWS régions pour imiter les scénarios de reprise après sinistre.
Vérifiez les exigences de votre organisation en ce qui concerne l’objectif de délai de reprise (RTO), l’objectif de point de reprise (RPO) et la redondance géographique. La plupart des organisations groupent ces éléments dans la catégorie élargie de reprise après sinistre. Évaluez les fonctions de haute disponibilité d’Aurora décrites dans cette section dans le contexte de votre processus de reprise après sinistre pour vous assurer que vos exigences RTO et RPO sont satisfaites.
13. Suite des opérations
À la fin d’un processus de démonstration de faisabilité réussi, vous confirmez qu’Aurora est une solution qui vous convient sur la base de la charge de travail anticipée. Tout au long du processus précédent, vous avez vérifié comment Aurora fonctionne dans un environnement opérationnel réaliste et avez mesuré cela sur la base de vos critères de réussite.
Une fois que votre environnement de base de données est opérationnel avec Aurora, vous pouvez passer à des étapes d’évaluation plus détaillées, qui mènent à votre migration finale et au déploiement en production. Selon votre situation, ces autres étapes peuvent être incluses ou non dans le processus de démonstration de faisabilité. Pour plus de détails sur les activités de migration et de portage, consultez le AWS livre blanc sur le manuel de migration Aurora
Dans une autre étape ultérieure, prenez en considération les configurations de sécurité pertinentes pour votre charge de travail et conçues pour satisfaire vos exigences de sécurité dans un environnement de production. Planifiez les contrôles à mettre en place pour protéger l’accès aux informations d’identification des utilisateurs principaux du cluster Aurora. Définissez les rôles et responsabilités des utilisateurs de base de données pour contrôler l’accès aux données stockées dans le cluster Aurora. Prenez en compte les exigences d’accès aux bases de données pour les applications, les scripts et les outils ou services tiers. Explorez les AWS services et fonctionnalités tels que l'authentification AWS Secrets Manager et Gestion des identités et des accès AWS (IAM).
À ce stade, vous devez comprendre les procédures et les bonnes pratiques à utiliser pour effectuer des tests d’évaluation avec Aurora. Vous pouvez constater qu’il vous faut effectuer un réglage supplémentaire des performances. Pour en savoir plus, consultez Gestion des performances et dimensionnement des clusters de bases de données Aurora, Améliorations des performances Amazon Aurora MySQL, Performance et mise à l’échelle d’Amazon Aurora PostgreSQL et Surveillance de la charge de la base de données avec Performance Insights sur . Si vous effectuez un réglage supplémentaire, veillez à bien connaître les métriques que vous avez rassemblées au cours de la démonstration de faisabilité. Dans une étape ultérieure, vous pouvez créer des clusters en faisant des choix différents de paramètres de configuration, de moteur de base de données et de version de base de données. Vous pouvez également créer des types spécialisés de clusters Aurora pour répondre aux besoins de cas d’utilisation spécifiques.
Par exemple, vous pouvez explorer les clusters de requêtes parallèles Aurora pour les applications de transaction/analytical traitement hybride (HTAP). Si une large distribution géographique est essentielle pour la reprise après sinistre ou pour réduire au maximum la latence, vous pouvez explorer les bases de données globales Aurora. Si votre charge de travail est intermittente ou si vous utilisez Aurora dans un development/test scénario, vous pouvez explorer les Aurora Serverless clusters.
Vos clusters de production peuvent également avoir besoin de traiter des volumes élevés de connexions entrantes. Pour découvrir ces techniques, consultez le AWS livre blanc Manuel de l'administrateur de base de données Aurora MySQL — Gestion des connexions
Si, après la preuve de concept, vous décidez que votre cas d’utilisation n’est pas adapté pour Aurora, envisagez d’utiliser les autres services AWS suivants :
-
Pour les cas d'utilisation purement analytiques, les charges de travail bénéficient d'un format de stockage en colonnes et d'autres fonctionnalités plus adaptées aux charges de travail OLAP. AWS les services qui répondent à de tels cas d'utilisation sont les suivants :
-
De nombreuses charges de travail profitent d’une combinaison d’Aurora et d’un ou de plusieurs de ces services. Vous pouvez déplacer les données entre ces services en utilisant les solutions suivantes :
-
Importation à partir d’Amazon S3, comme décrit dans le Guide de l’utilisateur Amazon Aurora
-
Exportation vers Amazon S3, comme décrit dans le Guide de l’utilisateur Amazon Aurora
-
De nombreux autres outils ETL courants
