Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connexion à Amazon Aurora Global Database
Chaque base de données Aurora Global Database est fournie avec un point de terminaison d’enregistreur qui est automatiquement mis à jour par Aurora pour acheminer les demandes vers l’instance d’enregistreur actuelle du cluster de bases de données principal. Avec le point de terminaison d’enregistreur, vous n’avez pas à modifier la chaîne de connexion après avoir modifié l’emplacement de la région principale à l’aide des fonctionnalités gérées de bascule et de basculement Aurora Global Database. Pour en savoir plus sur l’utilisation du point de terminaison d’enregistreur avec la bascule et le basculement Aurora Global Database, consultez Utilisation de la bascule ou du basculement dans une base de données Amazon Aurora Global Database. Pour plus d’informations sur la connexion à une base de données Aurora Global Database avec un proxy RDS, consultez Utilisation du proxy RDS avec les bases de données globales Aurora.
Rubriques
Sélection du point de terminaison qui répond aux besoins de votre application
La connexion à une base de données Aurora Global Database dépend de ce que vous devez y faire (lecture ou écriture à partir de la base de données) et de la région AWS vers laquelle vous souhaitez acheminer vos demandes. Voici quelques cas d’utilisation typiques :
-
Acheminement des demandes vers l’instance d’enregistreur : connectez-vous au point de terminaison d’enregistreur Aurora Global Database si vous devez exécuter des instructions de langage de manipulation de données (DML) et de langage de définition de données (DDL), ou si vous avez besoin d’une cohérence renforcée entre les lectures et les écritures. Ce point de terminaison achemine les demandes vers l’instance d’enregistreur du cluster principal de votre base de données globale. Ce point de terminaison est automatiquement mis à jour pour acheminer les demandes vers l’instance d’enregistreur, ce qui évite d’avoir à mettre à jour votre application chaque fois que vous modifiez l’emplacement de l’enregistreur dans votre cluster global. Vous pouvez également utiliser le point de terminaison global pour envoyer des read/write demandes interrégionales à votre rédacteur.
Note
Si vous avez configuré votre base de données globale avant que le point de terminaison d’enregistreur Aurora Global Database ne soit disponible, il est possible que votre application se connecte au point de terminaison du cluster principal. Dans ce cas, nous vous recommandons de modifier les paramètres de connexion pour que le point de terminaison d’enregistreur global soit utilisé à la place. Cela évite d’avoir à modifier les paramètres de connexion après chaque bascule ou basculement Aurora Global Database.
La première partie du nom du point de terminaison d’enregistreur est le nom de votre base de données Aurora Global Database. Dès lors, si vous renommez votre base de données Aurora Global Database, le nom du point de terminaison d’enregistreur changera, et tout code qui l’utilise devra être mis à jour avec le nouveau nom.
-
Dimensionnement des lectures au plus près de la région de votre application : pour redimensionner les demandes en lecture seule dans la même AWS région que votre application ou à proximité, connectez-vous au point de terminaison du lecteur des clusters Aurora principaux ou secondaires.
-
Mise à l’échelle des lectures avec des écritures entre régions occasionnelles : pour les instructions DML occasionnelles, telles que pour la maintenance et le nettoyage des données, connectez-vous au point de terminaison du lecteur d’un cluster secondaire sur lequel le transfert d’écriture est activé. Avec le transfert d’écriture, Aurora transmet automatiquement les instructions d’écriture à l’enregistreur de la région principale de votre base de données Aurora Global Database. Le transfert d’écriture offre les avantages suivants :
-
Vous n’avez pas besoin de faire le gros du travail pour établir la connectivité entre les clusters secondaire et principal afin d’envoyer des écritures entre régions.
-
Il n’est pas nécessaire de séparer les demandes de lecture et les demandes d’écriture dans l’application.
-
Il n’est pas nécessaire de développer une logique complexe pour gérer la cohérence des demandes de lecture après écriture.
Toutefois, avec le transfert d’écriture, vous devrez mettre à jour le code ou la configuration de votre application pour pouvoir vous connecter au point de terminaison du lecteur de la région principale qui vient d’être promue après avoir effectué une bascule ou un basculement entre régions. Nous vous recommandons de surveiller la latence des opérations effectuées par le biais du transfert d’écriture, afin de contrôler la surcharge liée au traitement des demandes d’écriture. Enfin, le transfert d’écriture ne prend pas en charge certaines opérations MySQL ou PostgreSQL, telles que les modifications du langage de définition des données (DDL) ou les instructions
SELECT FOR UPDATE.Pour en savoir plus sur l'utilisation du transfert d'écriture entre AWS régions, consultezUtilisation du transfert d'écriture dans une base de données globale Amazon Aurora.
-
Pour plus de détails sur les différents types de points de terminaison Aurora, consultez Connexion à un cluster de bases de données Amazon Aurora.
Affichage des points de terminaison d’une base de données Amazon Aurora Global Database
Lorsque vous examinez une base de données Aurora Global Database dans la console, vous pouvez voir tous les points de terminaison associés à tous ses clusters. La figure suivante montre un exemple des types de points de terminaison que vous voyez lorsque vous consultez les détails de votre cluster de bases de données principal :
-
Rédacteur global : point de read/write terminaison unique qui pointe toujours vers l'instance de base de données d'écriture actuelle pour le cluster de bases de données global.
-
Writer — Point de terminaison de connexion pour les read/write demandes adressées au cluster de base de données principal dans le cluster de bases de données global.
-
Lecteur : point de terminaison de connexion pour les demandes de lecture seule adressées à un cluster de bases de données principal ou secondaire du cluster de bases de données global. Pour minimiser le temps de latence, choisissez le point de terminaison du lecteur qui se trouve dans le vôtre Région AWS ou le Région AWS plus proche de vous.
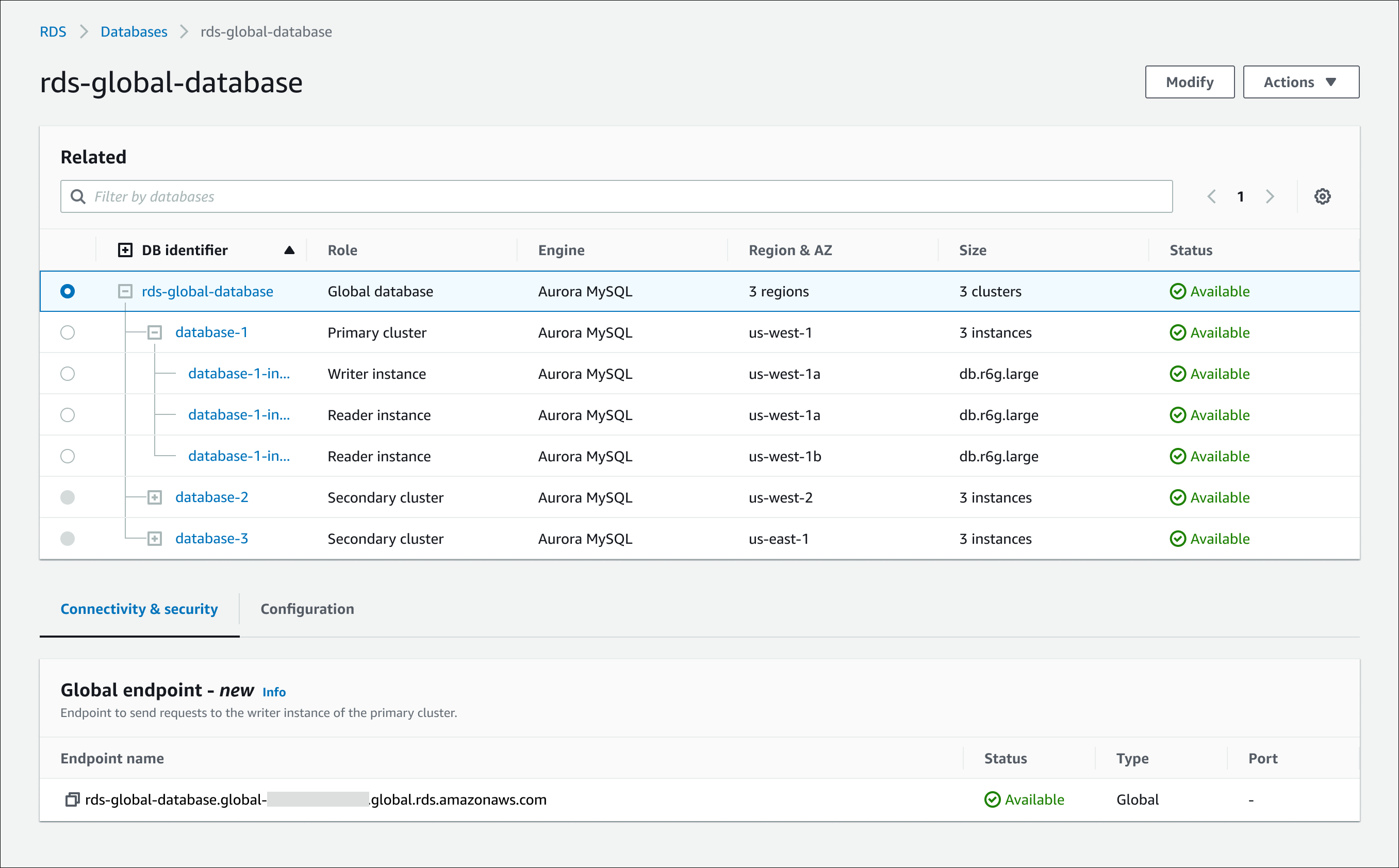
Pour afficher les points de terminaison d’une base de données globale
-
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Dans le panneau de navigation, choisissez Databases (Bases de données).
-
Dans la liste, sélectionnez la base de données globale ou le cluster de bases de données principal ou secondaire dont vous souhaitez afficher les points de terminaison.
-
Choisissez l’onglet Connectivité et sécurité pour voir les détails du point de terminaison. Les points de terminaison affichés dépendent du type de cluster que vous avez sélectionné, comme suit :
-
Base de données globale : point de terminaison d’enregistreur global.
-
Cluster de bases de données principal : point de terminaison d’enregistreur global, point de terminaison du cluster et point de terminaison de lecteur pour le cluster principal.
-
Cluster de bases de données secondaire : point de terminaison de cluster et point de terminaison de lecteur pour le cluster secondaire. Sur un cluster secondaire, le point de terminaison du cluster affiche le statut inactif, car il ne gère pas les demandes d’écriture. Vous pouvez tout de même vous connecter au point de terminaison du cluster, mais uniquement pour les requêtes de lecture.
-
Pour afficher le point de terminaison d’enregistreur du cluster global, utilisez la commande AWS CLI describe-global-clusters, comme dans l’exemple suivant.
aws rds describe-global-clusters --regionaws_region{ "GlobalClusters": [ { "GlobalClusterIdentifier": "global_cluster_id", "GlobalClusterResourceId": "cluster-unique_string", "GlobalClusterArn": "arn:aws:rds::123456789012:global-cluster:global_cluster_id", "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "5.7.mysql_aurora.2.11.2", "GlobalClusterMembers": [ ... ], "Endpoint": "global_cluster_id.global-unique_string.global.rds.amazonaws.com" } ] }
Pour afficher les points de terminaison du cluster et du lecteur pour les clusters de bases de données membres du cluster global, utilisez la commande AWS CLI
describe-db-clusters, comme dans l’exemple suivant. Les valeurs renvoyées pour Endpoint et ReaderEndpoint sont les points de terminaison du cluster et du lecteur, respectivement.
aws rds describe-db-clusters --regionprimary_region--db-cluster-identifierdb_cluster_id{ "DBClusters": [ { "AllocatedStorage": 1, "AvailabilityZones": [ "az_1", "az_2", "az_3" ], "BackupRetentionPeriod": 1, "DBClusterIdentifier": "db_cluster_id", "DBClusterParameterGroup": "default.aurora-mysql5.7", "DBSubnetGroup": "default", "Status": "available", "EarliestRestorableTime": "2023-08-01T18:21:11.301Z", "Endpoint": "db_cluster_id.cluster-unique_string.primary_region.rds.amazonaws.com", "ReaderEndpoint": "db_cluster_id.cluster-ro-unique_string.primary_region.rds.amazonaws.com", "MultiAZ": false, "Engine": "aurora-mysql", "EngineVersion": "5.7.mysql_aurora.2.11.2", "ReadReplicaIdentifiers": [ "arn:aws:rds:secondary_region:123456789012:cluster:db_cluster_id" ], "DBClusterMembers": [ { "DBInstanceIdentifier": "db_instance_id", "IsClusterWriter": true, "DBClusterParameterGroupStatus": "in-sync", "PromotionTier": 1 } ], ... "TagList": [], "GlobalWriteForwardingRequested": false } ] }
Pour afficher le point de terminaison du rédacteur du cluster global, utilisez l'DescribeGlobalClustersopération d'API RDS. Pour afficher les points de terminaison du cluster et du lecteur pour les clusters de bases de données membres du cluster global, utilisez l’opération DescribeDBClusters de l’API RDS.
Considérations relatives à l’utilisation des points de terminaison d’enregistreur global
Pour utiliser efficacement les points de terminaison d’enregistreur Aurora Global Database, reportez-vous aux consignes et aux bonnes pratiques suivantes :
-
Pour minimiser les perturbations après un basculement ou un basculement entre régions, vous pouvez configurer la connectivité VPC entre le calcul de votre application et vos régions principale et secondaire. AWS Supposons, par exemple, que des applications ou des systèmes clients s’exécutent dans le même VPC que le cluster principal. Si le cluster secondaire est promu, le point de terminaison d’enregistreur global change automatiquement pour pointer vers ce cluster. Bien que le point de terminaison global du rédacteur vous permette d'éviter de modifier les paramètres de connexion de votre application, celles-ci ne peuvent pas accéder aux adresses IP du VPC de la AWS région principale nouvellement promue tant que vous n'avez pas configuré le réseau entre les deux VPC. Consultez les options de connectivité Amazon VPC-to-Amazon VPC pour évaluer les différentes options de configuration de cette connectivité.
-
La mise à jour du point de terminaison d’enregistreur global après une bascule ou un basculement global de la base de données peut prendre du temps en fonction de la durée de mise en cache de votre service de noms de domaine (DNS). Consultez le Manuel de l’administrateur de base de données Amazon Aurora MySQL pour en savoir plus. La base de données Aurora Global Database émet un événement RDS lorsqu’elle constate la modification du DNS sur le point de terminaison d’enregistreur global. Vous pouvez utiliser cet événement pour concevoir des stratégies visant à garantir que le cache DNS ne s’étende pas au-delà de la période qui suit la génération de l’événement. Pour plus d’informations, consultez Événements de cluster de bases de données.
-
La base de données Aurora Global Database réplique les données de manière asynchrone. Les méthodes de basculement entre régions peuvent entraîner la réplication de certaines données de transaction d’écriture qui n’ont pas été répliquées dans la région secondaire choisie avant que le basculement se produise. Bien qu'Aurora fasse de son mieux pour bloquer les écritures dans la AWS région principale d'origine, le basculement peut être source de problèmes de division cérébrale. Les considérations visant à minimiser les pertes de données et le risque d’incohérence des données (ou split-brain) s’appliquent également aux points de terminaison d’enregistreur Aurora Global Database. Pour plus d’informations, consultez Réalisation de basculements gérés pour les bases de données globales Aurora.
