Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de groupes de sécurité AD pour le contrôle d’accès Aurora PostgreSQL
À partir des versions 14.10 et 15.5 d'Aurora PostgreSQL, le contrôle d'accès Aurora PostgreSQL peut être géré à l'aide des groupes de sécurité Directory AWS Service for Microsoft Active Directory (AD). Les versions antérieures d’Aurora PostgreSQL prennent en charge l’authentification basée sur Kerberos avec AD seulement pour les utilisateurs individuels. Chaque utilisateur AD devait être explicitement ajouté au cluster de bases de données pour pouvoir y accéder.
Au lieu d’ajouter explicitement chaque utilisateur AD au cluster de bases de données en fonction des besoins de l’entreprise, vous pouvez tirer parti des groupes de sécurité AD comme expliqué ci-dessous :
-
Les utilisateurs AD sont membres de différents groupes de sécurité AD dans un annuaire Active Directory. Ils ne sont pas régis par l’administrateur du cluster de bases de données, mais sont basés sur les exigences de l’entreprise et sont gérés par un administrateur AD.
-
Les administrateurs de clusters de bases de données créent des rôles de base de données dans les instances de base de données en fonction des exigences de l’entreprise. Ces rôles de base de données peuvent avoir des autorisations ou des privilèges distincts.
-
Les administrateurs de clusters de bases de données configurent un mappage entre les groupes de sécurité AD et les rôles de base de données pour chaque cluster de bases de données.
-
Les utilisateurs de bases de données peuvent accéder aux clusters de bases de données à l’aide de leurs informations d’identification AD. L’accès est basé sur l’appartenance au groupe de sécurité AD. Les utilisateurs AD obtiennent ou perdent automatiquement l’accès en fonction de leur appartenance à un groupe AD.
Conditions préalables
Assurez-vous d’effectuer les étapes suivantes avant de configurer l’extension pour les groupes de sécurité AD :
-
Configuration de l’authentification Kerberos pour les clusters de bases de données PostgreSQL. Pour plus d’informations, consultez Configuration de l’authentification Kerberos pour les clusters de bases de données PostgreSQL.
Note
Pour les groupes de sécurité AD, ignorez l’étape 7 : Créer des utilisateurs PostgreSQL pour vos principaux Kerberos dans cette procédure de configuration.
Important
Si vous activez des groupes de sécurité AD sur un cluster Aurora PostgreSQL sur lequel l’authentification Kerberos est déjà activée, vous pouvez rencontrer des problèmes d’authentification. Cela se produit lorsque vous ajoutez
pg_ad_mappingau paramètreshared_preload_librarieset que vous redémarrez la base de données. Lorsque vous utilisez des points de terminaison de cluster, les tentatives de connexion à l’aide d’un compte AD qui n’est pas un utilisateur de base de données doté du rôlerds_adpeuvent échouer. Cela peut également provoquer des pannes du moteur. Pour résoudre ce problème, désactivez puis réactivez l’authentification Kerberos sur le cluster. Cette solution de contournement est requise pour les instances existantes mais n’affecte pas les instances créées après avril 2025. -
Gestion d’un cluster de bases de données dans un domaine. Pour plus d’informations, consultez Gestion d’un cluster de bases de données dans un domaine.
Configuration de l’extension pg_ad_mapping
Aurora PostgreSQL fournit désormais une extension pg_ad_mapping pour gérer le mappage entre les groupes de sécurité AD et les rôles de base de données dans le cluster Aurora PostgreSQL. Pour plus d’informations sur les fonctions fournies par pg_ad_mapping, consultez Utilisation des fonctions de l'extension pg_ad_mapping.
Pour configurer l’extension pg_ad_mapping sur votre cluster de bases de données Aurora PostgreSQL, vous ajoutez d’abord pg_ad_mapping aux bibliothèques partagées au niveau du groupe de paramètres de base de données personnalisé pour votre cluster de bases de données Aurora PostgreSQL. Pour plus d’informations sur la création d’un groupe de paramètres de cluster de bases de données personnalisé, consultez Groupes de paramètres pour Amazon Aurora. Ensuite, vous installez l’extension pg_ad_mapping. Les procédures de cette section vous guident. Vous pouvez utiliser le Console de gestion AWS ou le AWS CLI.
Vous devez disposer d’autorisations en tant que rôle rds_superuser pour effectuer toutes ces tâches.
Les étapes suivantes supposent que votre cluster de bases de données Aurora PostgreSQL est associé à un groupe de paramètres de cluster de bases de données personnalisés.
Pour configurer l'extension pg_ad_mapping
Connectez-vous à la console Amazon RDS Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Dans le panneau de navigation, choisissez l’instance d’enregistreur de votre cluster de bases de données Aurora PostgreSQL.
-
Ouvrez l’onglet Configuration de l’instance d’enregistreur de votre cluster de bases de données Aurora PostgreSQL. Parmi les détails de l’instance, trouvez le lien Groupe de paramètres.
-
Cliquez sur le lien pour ouvrir les paramètres personnalisés associés à votre cluster de bases de données Aurora PostgreSQL.
-
Dans le champ de recherche Parameters (Paramètres), tapez
shared_prepour trouver le paramètreshared_preload_libraries. -
Choisissez Edit parameters (Modifier les paramètres) pour accéder aux valeurs des propriétés.
-
Ajoutez
pg_ad_mappingà la liste dans le champ Values (Valeurs). Utilisez une virgule pour séparer les éléments de la liste de valeurs.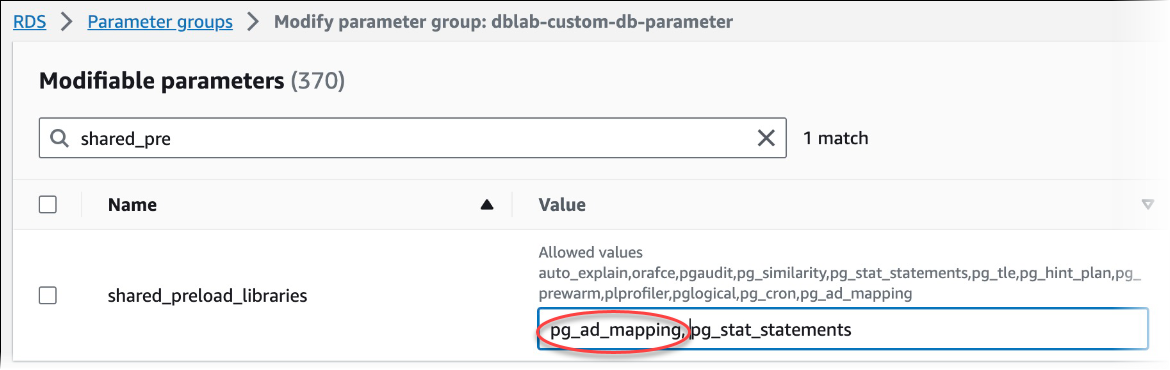
-
Redémarrez l’instance d’enregistreur de votre cluster de bases de données Aurora PostgreSQL afin que vos modifications du paramètre
shared_preload_librariesprennent effet. -
Lorsque l’instance est disponible, vérifiez que
pg_ad_mappinga été initialisé. Utilisezpsqlpour vous connecter à l’instance d’enregistreur de votre cluster de bases de données Aurora PostgreSQL, puis exécutez la commande suivante.SHOW shared_preload_libraries;shared_preload_libraries -------------------------- rdsutils,pg_ad_mapping (1 row) -
Une fois
pg_ad_mappinginitialisé, vous pouvez maintenant créer l’extension. Vous devez créer l’extension après avoir initialisé la bibliothèque pour pouvoir commencer à utiliser les fonctions fournies par cette extension.CREATE EXTENSION pg_ad_mapping; -
Fermez la session
psql.labdb=>\q
Pour configurer pg_ad_mapping
Pour configurer pg_ad_mapping à l'aide de AWS CLI, vous devez appeler l'opération modify-db-parameter-group pour ajouter ce paramètre dans votre groupe de paramètres personnalisé, comme indiqué dans la procédure suivante.
-
Utilisez la AWS CLI commande suivante pour
pg_ad_mappingajouter aushared_preload_librariesparamètre.aws rds modify-db-parameter-group \ --db-parameter-group-namecustom-param-group-name\ --parameters "ParameterName=shared_preload_libraries,ParameterValue=pg_ad_mapping,ApplyMethod=pending-reboot" \ --regionaws-region -
Utilisez la AWS CLI commande suivante pour redémarrer l'instance d'écriture de votre cluster de base de données Aurora PostgreSQL afin que le pg_ad_mapping soit initialisé.
aws rds reboot-db-instance \ --db-instance-identifierwriter-instance\ --regionaws-region -
Lorsque l’instance est disponible, vous pouvez vérifier que
pg_ad_mappinga été initialisé. Utilisezpsqlpour vous connecter à l’instance d’enregistreur de votre cluster de bases de données Aurora PostgreSQL, puis exécutez la commande suivante.SHOW shared_preload_libraries;shared_preload_libraries -------------------------- rdsutils,pg_ad_mapping (1 row)Une fois pg_ad_mapping initialisé, vous pouvez maintenant créer l’extension.
CREATE EXTENSION pg_ad_mapping; -
Fermez la session
psqlafin de pouvoir utiliser l’ AWS CLI.labdb=>\q
Récupération du SID du groupe Active Directory dans PowerShell
Un identifiant de sécurité (SID) permet d’identifier de manière unique un principal ou un groupe de sécurité. Chaque fois qu’un groupe de sécurité ou un compte est créé dans Active Directory, un SID lui est attribué. Pour récupérer le SID du groupe de sécurité AD depuis Active Directory, vous pouvez utiliser l' Get-ADGroup applet de commande de la machine cliente Windows associée à ce domaine Active Directory. Le paramètre Identity spécifie le nom du groupe Active Directory pour obtenir le SID correspondant.
L'exemple suivant renvoie le SID du groupe ADadgroup1.
C:\Users\Admin>Get-ADGroup -Identity adgroup1 | select SIDSID ----------------------------------------------- S-1-5-21-3168537779-1985441202-1799118680-1612
Mappage du rôle de base de données avec le groupe de sécurité AD
Vous devez explicitement configurer les groupes de sécurité AD dans la base de données en tant que rôles de base de données PostgreSQL. Un utilisateur AD faisant partie d’au moins un groupe de sécurité AD provisionné aura accès à la base de données. Vous ne devez pas accorder rds_ad role à un rôle de base de données basé sur le groupe de sécurité AD. L'authentification Kerberos pour le groupe de sécurité sera déclenchée en utilisant le suffixe du nom de domaine tel que. user1@example.com Ce rôle de base de données ne peut pas utiliser l’authentification par mot de passe ni l’authentification IAM pour accéder à la base de données.
Note
Les utilisateurs AD qui ont un rôle de base de données correspondant dans la base de données et auxquels le rôle rds_ad a été accordé ne pourront pas se connecter dans le cadre du groupe de sécurité AD. Ils y auront accès via le rôle de base de données en tant qu’utilisateur individuel.
Prenons l’exemple d’accounts-group, qui est un groupe de sécurité dans AD que vous souhaitez provisionner dans Aurora PostgreSQL en tant que rôle de compte (accounts-role).
| Groupe de sécurité AD | Rôle de base de données PostgreSQL |
|---|---|
| accounts-group | accounts-role |
Lorsque vous mappez le rôle de base de données avec le groupe de sécurité AD, vous devez vous assurer que l’attribut LOGIN du rôle de base de données est défini et que ce rôle dispose du privilège CONNECT pour la base de données de connexion requise.
postgres =>alter roleaccounts-rolelogin;ALTER ROLEpostgres =>grant connect on databaseaccounts-dbtoaccounts-role;
L’administrateur peut maintenant procéder à la création du mappage entre le groupe de sécurité AD et le rôle de base de données PostgreSQL.
admin=>select pgadmap_set_mapping('accounts-group','accounts-role',<SID>,<Weight>);
Pour plus d’informations sur la récupération du SID du groupe de sécurité AD, consultez Récupération du SID du groupe Active Directory dans PowerShell.
Dans certains cas, un utilisateur AD peut appartenir à plusieurs groupes. Dans ce cas, l’utilisateur AD hérite des privilèges du rôle de base de données, qui a été attribué avec le poids le plus élevé. Si les deux rôles ont le même poids, l’utilisateur AD hérite des privilèges du rôle de base de données correspondant au mappage récemment ajouté. Il est recommandé de spécifier des pondérations qui reflètent le rapport entre les différents rôles permissions/privileges de base de données. Plus les autorisations ou privilèges d’un rôle de base de données sont élevés, plus le poids qui doit être associé à l’entrée de mappage est élevé. Cela permet d’éviter l’ambiguïté de deux mappages ayant le même poids.
Le tableau suivant présente un exemple de mappage entre les groupes de sécurité AD et les rôles de base de données Aurora PostgreSQL.
| Groupe de sécurité AD | Rôle de base de données PostgreSQL | Pondération |
|---|---|---|
| accounts-group | accounts-role | 7 |
| sales-group | sales-role | 10 |
| dev-group | dev-role | 7 |
Dans l’exemple suivant, user1 hérite des privilèges de sales-role puisqu’il a le poids le plus élevé, tandis que user2 hérite des privilèges de dev-role, car le mappage pour ce rôle été créé après accounts-role, qui partage le même poids que accounts-role.
| Nom d’utilisateur | Appartenance au groupe de sécurité |
|---|---|
| user1 | accounts-group sales-group |
| user2 | accounts-group dev-group |
Les commandes psql permettant d’établir, de répertorier et d’effacer les mappages sont présentées ci-dessous. Actuellement, il n’est pas possible de modifier une seule entrée de mappage. L’entrée existante doit être supprimée, et le mappage recréé.
admin=>select pgadmap_set_mapping('accounts-group', 'accounts-role', 'S-1-5-67-890', 7);admin=>select pgadmap_set_mapping('sales-group', 'sales-role', 'S-1-2-34-560', 10);admin=>select pgadmap_set_mapping('dev-group', 'dev-role', 'S-1-8-43-612', 7);admin=>select * from pgadmap_read_mapping();ad_sid | pg_role | weight | ad_grp -------------+----------------+--------+--------------- S-1-5-67-890 | accounts-role | 7 | accounts-group S-1-2-34-560 | sales-role | 10 | sales-group S-1-8-43-612 | dev-role | 7 | dev-group (3 rows)
Identité de l'utilisateur AD logging/auditing
Utilisez la commande suivante pour déterminer le rôle de base de données hérité par l’utilisateur actuel ou par l’utilisateur de la session :
postgres=>select session_user, current_user;session_user | current_user -------------+-------------- dev-role | dev-role (1 row)
Pour déterminer l’identité du principal de sécurité AD, utilisez la commande suivante :
postgres=>select principal from pg_stat_gssapi where pid = pg_backend_pid();principal ------------------------- user1@example.com (1 row)
À l’heure actuelle, l’identité de l’utilisateur AD n’est pas visible dans les journaux d’audit. Le paramètre log_connections peut être activé pour enregistrer l’établissement d’une session de base de données. Pour plus d’informations, consultez log_connections. La sortie correspondante inclut l’identité de l’utilisateur AD, comme indiqué ci-dessous. Le PID du système dorsal associé à cette sortie pourra ensuite aider à attribuer les actions à l’utilisateur AD réel.
pgrole1@postgres:[615]:LOG: connection authorized: user=pgrole1 database=postgres application_name=psql GSS (authenticated=yes, encrypted=yes, principal=Admin@EXAMPLE.COM)
Limitations
-
Microsoft Entra ID connu sous le nom d’Azure Active Directory n’est pas pris en charge.
Utilisation des fonctions de l'extension pg_ad_mapping
L’extension pg_ad_mapping a pris en charge les fonctions suivantes :
pgadmap_set_mapping
Cette fonction établit le mappage entre le groupe de sécurité AD et le rôle de base de données avec un poids associé.
Syntaxe
pgadmap_set_mapping(
ad_group,
db_role,
ad_group_sid,
weight)
Arguments
| Paramètre | Description |
|---|---|
| ad_group | Nom du groupe AD. La valeur ne peut pas être une chaîne nulle ou vide. |
| db_role | Rôle de base de données à mapper au groupe AD spécifié. La valeur ne peut pas être une chaîne nulle ou vide. |
| ad_group_sid | Identifiant de sécurité utilisé pour identifier de manière unique le groupe AD. La valeur commence par « S-1 - » et ne peut pas être une chaîne nulle ou vide. Pour de plus amples informations, veuillez consulter Récupération du SID du groupe Active Directory dans PowerShell. |
| weight | Poids associé au rôle de base de données. Le rôle ayant le plus de poids est prioritaire lorsque l’utilisateur est membre de plusieurs groupes. La valeur par défaut de weight est 1. |
Type de retour
None
Notes d’utilisation
Cette fonction ajoute un nouveau mappage entre le groupe de sécurité AD et le rôle de base de données. Elle ne peut être exécutée que sur l’instance de base de données principale du cluster de bases de données par un utilisateur disposant du privilège rds_superuser.
Exemples
postgres=>select pgadmap_set_mapping('accounts-group','accounts-role','S-1-2-33-12345-67890-12345-678',10);pgadmap_set_mapping (1 row)
pgadmap_read_mapping
Cette fonction répertorie les mappages entre le groupe de sécurité AD et le rôle de base de données définis à l’aide de la fonction pgadmap_set_mapping.
Syntaxe
pgadmap_read_mapping()
Arguments
None
Type de retour
| Paramètre | Description |
|---|---|
| ad_group_sid | Identifiant de sécurité utilisé pour identifier de manière unique le groupe AD. La valeur commence par « S-1 - » et ne peut pas être une chaîne nulle ou vide. Pour plus d’informations, consultez Récupération du SID du groupe Active Directory dans PowerShell.accounts-role@example.com |
| db_role | Rôle de base de données à mapper au groupe AD spécifié. La valeur ne peut pas être une chaîne nulle ou vide. |
| weight | Poids associé au rôle de base de données. Le rôle ayant le plus de poids est prioritaire lorsque l’utilisateur est membre de plusieurs groupes. La valeur par défaut de weight est 1. |
| ad_group | Nom du groupe AD. La valeur ne peut pas être une chaîne nulle ou vide. |
Notes d’utilisation
Appelez cette fonction pour répertorier tous les mappages disponibles entre le groupe de sécurité AD et le rôle de base de données.
Exemples
postgres=>select * from pgadmap_read_mapping();ad_sid | pg_role | weight | ad_grp ------------------------------------+---------------+--------+------------------ S-1-2-33-12345-67890-12345-678 | accounts-role | 10 | accounts-group (1 row) (1 row)
pgadmap_reset_mapping
Cette fonction réinitialise un ou tous les mappages définis à l’aide de la fonction pgadmap_set_mapping.
Syntaxe
pgadmap_reset_mapping(
ad_group_sid,
db_role,
weight)
Arguments
| Paramètre | Description |
|---|---|
| ad_group_sid | Identifiant de sécurité utilisé pour identifier de manière unique le groupe AD. |
| db_role | Rôle de base de données à mapper au groupe AD spécifié. |
| weight | Poids associé au rôle de base de données. |
Si aucun argument n’est fourni, tous les mappages entre le groupe AD et le rôle de base de données sont réinitialisés. Tous les arguments doivent être fournis ou aucun.
Type de retour
None
Notes d’utilisation
Appelez cette fonction pour supprimer un mappage spécifique entre un groupe AD et un rôle de base de données ou pour réinitialiser tous les mappages. Cette fonction ne peut être exécutée que sur l’instance de base de données principale du cluster de bases de données par un utilisateur disposant du privilège rds_superuser.
Exemples
postgres=>select * from pgadmap_read_mapping();ad_sid | pg_role | weight | ad_grp --------------------------------+--------------+-------------+------------------- S-1-2-33-12345-67890-12345-678 | accounts-role| 10 | accounts-group S-1-2-33-12345-67890-12345-666 | sales-role | 10 | sales-group (2 rows)postgres=>select pgadmap_reset_mapping('S-1-2-33-12345-67890-12345-678', 'accounts-role', 10);pgadmap_reset_mapping (1 row)postgres=>select * from pgadmap_read_mapping();ad_sid | pg_role | weight | ad_grp --------------------------------+--------------+-------------+--------------- S-1-2-33-12345-67890-12345-666 | sales-role | 10 | sales-group (1 row)postgres=>select pgadmap_reset_mapping();pgadmap_reset_mapping (1 row)postgres=>select * from pgadmap_read_mapping();ad_sid | pg_role | weight | ad_grp --------------------------------+--------------+-------------+-------------- (0 rows)
