Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Opciones de recuperación de desastres en la nube
Las estrategias de recuperación ante desastres que tiene a su disposición en AWS se pueden clasificar a grandes rasgos en cuatro enfoques, que van desde el bajo costo y la baja complejidad de realizar copias de seguridad hasta estrategias más complejas que utilizan varias regiones activas. Active/passive las estrategias utilizan un sitio activo (como una región de AWS) para alojar la carga de trabajo y atender el tráfico. El sitio pasivo (por ejemplo, una región de AWS diferente) se utiliza para la recuperación. El sitio pasivo no atiende tráfico de forma activa hasta que se desencadena un evento de conmutación por error.
Es fundamental evaluar y probar periódicamente su estrategia de recuperación ante desastres para tener confianza a la hora de utilizarla en caso de que sea necesario. Utilice AWS Resilience Hub
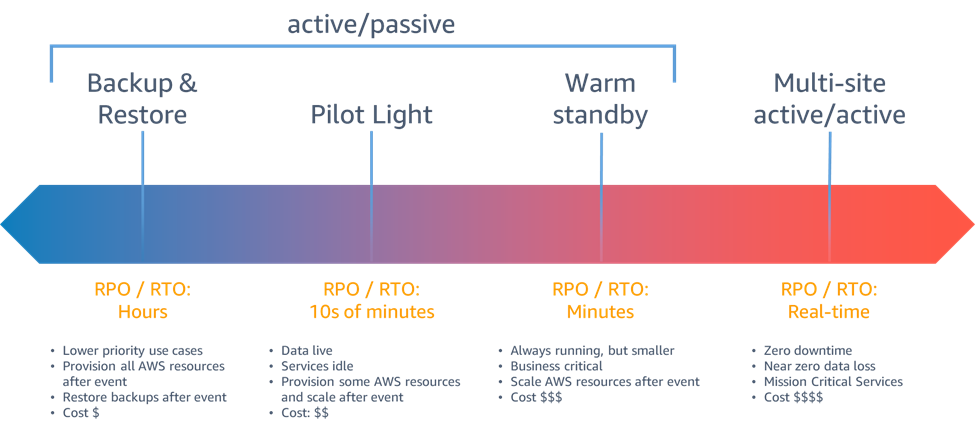
Figura 6: Estrategias de recuperación ante desastres
En el caso de un desastre provocado por la interrupción o la pérdida de un centro de datos físico debido a una carga de trabajo bien diseñada
Al elegir su estrategia y los recursos de AWS para implementarla, tenga en cuenta que, en AWS, solemos dividir los servicios en el plano de datos y el plano de control. El plano de datos se encarga de entregar el servicio en tiempo real mientras que el plano de control se utiliza para configurar el entorno. Para obtener la máxima resiliencia, debe utilizar únicamente las operaciones del plano de datos como parte de la operación de conmutación por error. Esto se debe a que los planos de datos suelen tener objetivos de diseño de disponibilidad más altos que los planos de control.
Copia de seguridad y restauración
El backup y la restauración son un enfoque adecuado para mitigar la pérdida o la corrupción de datos. Este enfoque también se puede utilizar para mitigar un desastre regional mediante la replicación de datos en otras regiones de AWS, o para mitigar la falta de redundancia de las cargas de trabajo implementadas en una única zona de disponibilidad. Además de los datos, debe volver a implementar la infraestructura, la configuración y el código de la aplicación en la región de recuperación. Para permitir que la infraestructura se vuelva a implementar rápidamente y sin errores, siempre debe implementarla utilizando la infraestructura como código (IaC) utilizando servicios como o el. AWS CloudFormationAWS Cloud Development Kit (AWS CDK)
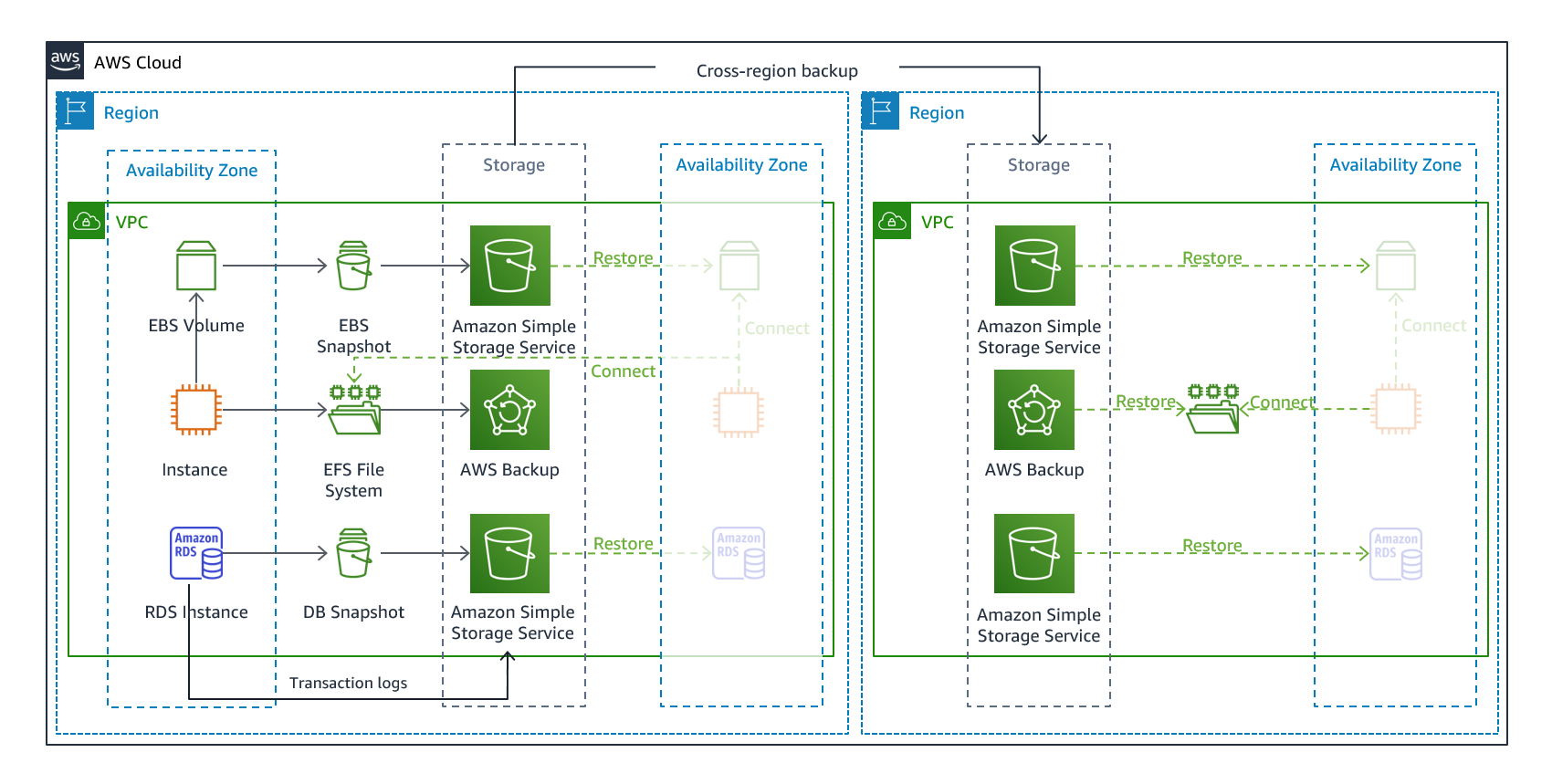
Figura 7: Arquitectura de backup y restauración
Servicios de AWS
Los datos de su carga de trabajo requerirán una estrategia de respaldo que se ejecute periódicamente o sea continua. La frecuencia con la que ejecute el backup determinará el punto de recuperación alcanzable (que debe ajustarse a su RPO). La copia de seguridad también debe ofrecer una forma de restaurarla hasta el momento en que se realizó. El backup con point-in-time recuperación está disponible a través de los siguientes servicios y recursos:
-
Respaldo de Amazon EFS (cuando se usa AWS Backup)
-
Amazon FSx para Windows File Server, Amazon FSx para Lustre, Amazon FSx para NetApp ONTAP y Amazon FSx para OpenZFS
Para Amazon Simple Storage Service (Amazon S3), puede utilizar Amazon S3 Cross-Region Replication (CRR) para copiar objetos de forma asíncrona
AWS Backup
-
EC2Instancias de Amazon
-
Bases de datos de Amazon Relational Database Service (Amazon RDS
) (incluidas las bases de datos de Amazon Aurora ) -
Tablas de Amazon DynamoDB
-
Sistemas de archivos Amazon Elastic File System (Amazon EFS)
-
AWS Storage Gateway
Volúmenes de -
Amazon FSx para Windows File Server, Amazon FSx para Lustre, Amazon FSx para NetApp ONTAP y Amazon FSx para OpenZFS
AWS Backup permite copiar copias de seguridad entre regiones, por ejemplo, en una región de recuperación ante desastres.
Como estrategia adicional de recuperación ante desastres para sus datos de Amazon S3, habilite el control de versiones de objetos de S3. El control de versiones de objetos protege sus datos en S3 de las consecuencias de las acciones de eliminación o modificación, ya que conserva la versión original antes de la acción. El control de versiones de objetos puede ser una forma útil de mitigar los desastres provocados por errores humanos. Si utiliza la replicación de S3 para realizar copias de seguridad de los datos en su región de DR, de forma predeterminada, cuando se elimina un objeto del bucket de origen, Amazon S3 añade un marcador de eliminación únicamente en el bucket de origen. Este enfoque protege los datos de la región de DR de las eliminaciones malintencionadas en la región de origen.
Además de los datos, también debe realizar una copia de seguridad de la configuración y la infraestructura necesarias para volver a implementar su carga de trabajo y cumplir su objetivo de tiempo de recuperación (RTO). AWS CloudFormation
Todos los datos almacenados en la región de recuperación ante desastres como copias de seguridad deben restaurarse en el momento de la conmutación por error. AWS Backup ofrece la capacidad de restauración, pero actualmente no permite la restauración programada o automática. Puede implementar la restauración automática en la región de DR utilizando el SDK de AWS, si así lo APIs solicita AWS Backup. Puede configurarlo como un trabajo periódico o activar la restauración cada vez que se complete una copia de seguridad. En la siguiente figura se muestra un ejemplo de restauración automática mediante Amazon Simple Notification Service (Amazon SNS
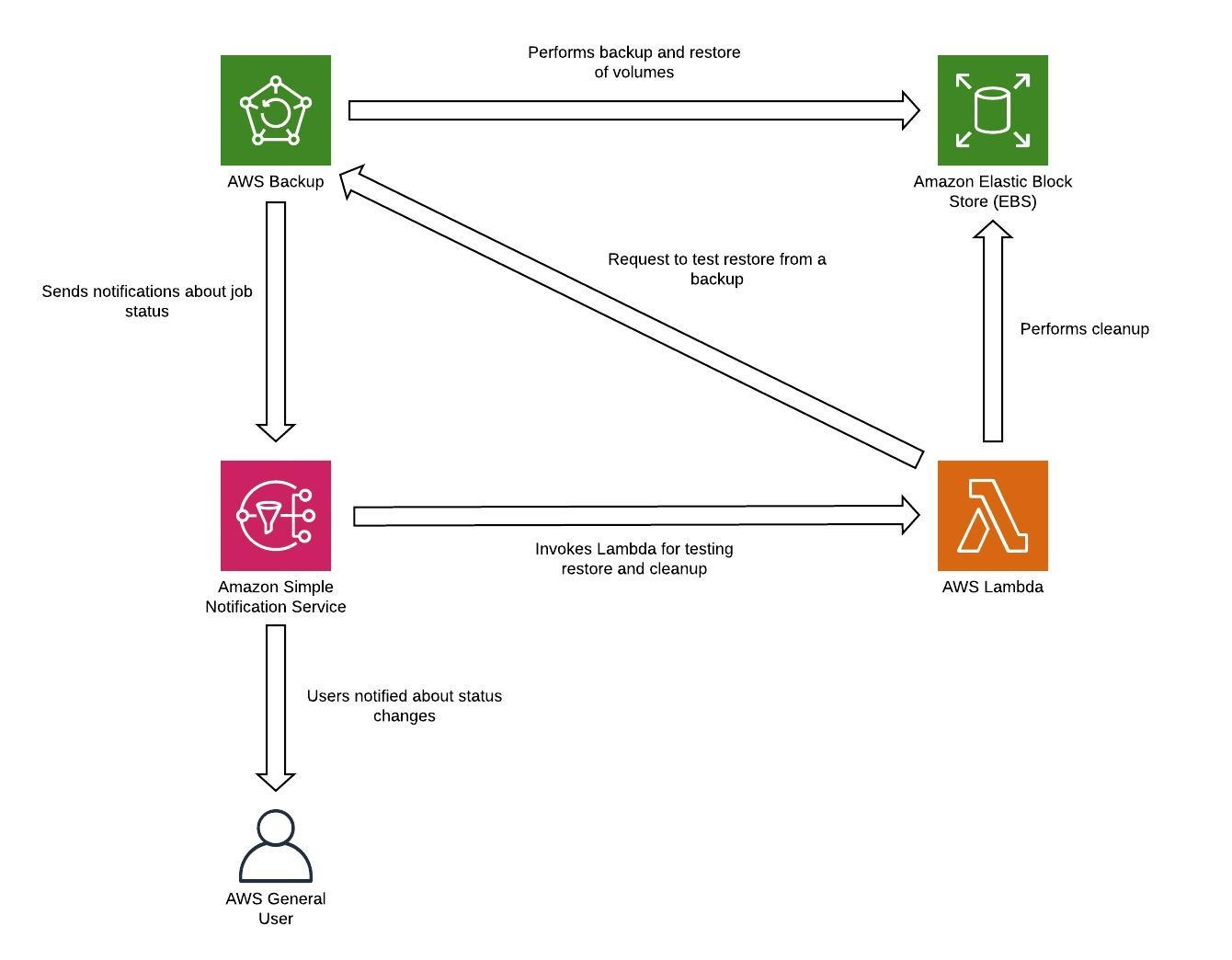
Figura 8: Restauración y prueba de copias de seguridad
nota
La estrategia de copia de seguridad debe incluir la prueba de sus copias de seguridad. Consulte la sección Probar la recuperación ante desastres para obtener más información. Consulte el AWS Well-Architected Lab: Testing Backup and Restore of Data para ver una demostración práctica de la
Luz piloto
Con el enfoque basado en la modalidad piloto, puede replicar sus datos de una región a otra y aprovisionar una copia de su infraestructura de carga de trabajo principal. Los recursos necesarios para permitir la replicación y copia de seguridad de los datos, como el almacenamiento de bases de datos y objetos, están siempre disponibles. Otros elementos, como los servidores de aplicaciones, se cargan con el código y las configuraciones de la aplicación, pero están «apagados» y solo se utilizan durante las pruebas o cuando se invoca la conmutación por error de recuperación ante desastres. En la nube, tiene la flexibilidad de desaprovisionar recursos cuando no los necesite y aprovisionarlos cuando los necesite. Una buena práctica para «desconectar» es no desplegar el recurso y, a continuación, crear la configuración y las capacidades necesarias para desplegarlo («encenderlo») cuando sea necesario. A diferencia del enfoque de backup y restauración, su infraestructura principal está siempre disponible y siempre tiene la opción de aprovisionar rápidamente un entorno de producción a gran escala activando y ampliando sus servidores de aplicaciones.
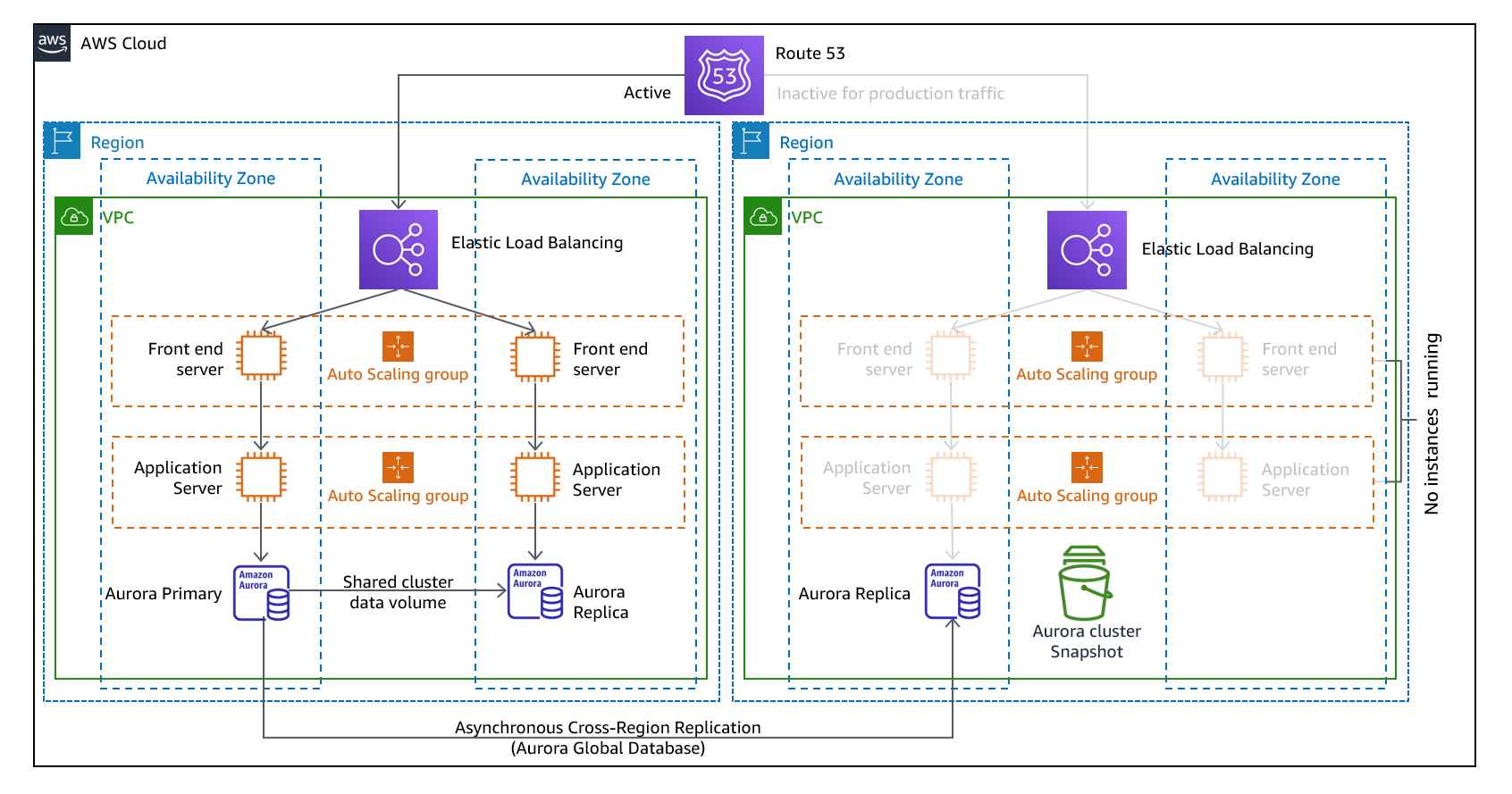
Figura 9: Arquitectura de luz piloto
Un enfoque piloto ligero minimiza el costo continuo de la recuperación ante desastres al minimizar los recursos activos y simplifica la recuperación en el momento de un desastre, ya que todos los requisitos de infraestructura básicos están establecidos. Esta opción de recuperación requiere que cambie su enfoque de implementación. Debe realizar cambios en la infraestructura principal de cada región e implementar los cambios en la carga de trabajo (configuración, código) de forma simultánea en cada región. Este paso se puede simplificar automatizando las implementaciones y utilizando la infraestructura como código (IaC) para implementar la infraestructura en varias cuentas y regiones (implementación completa de la infraestructura en la región principal e implementación de infraestructura reducida o desconectada en las regiones de DR). Se recomienda utilizar una cuenta diferente por región para proporcionar el máximo nivel de aislamiento de recursos y seguridad (en el caso de que las credenciales comprometidas también formen parte de sus planes de recuperación ante desastres).
Con este enfoque, también debe evitar un desastre de datos. La replicación continua de los datos lo protege contra algunos tipos de desastres, pero es posible que no lo proteja contra la corrupción o la destrucción de los datos, a menos que su estrategia también incluya el control de versiones de los datos almacenados o las opciones de point-in-time recuperación. Puede hacer una copia de seguridad de los datos replicados en la región del desastre para crear point-in-time copias de seguridad en esa misma región.
Servicios de AWS
Además de utilizar los servicios de AWS descritos en la sección Backup and Restore para crear point-in-time copias de seguridad, considere también los siguientes servicios para su estrategia piloto.
A modo de prueba, la replicación continua de datos en bases de datos y almacenes de datos activos de la región de DR es el mejor enfoque para un RPO bajo (si se utiliza además de las point-in-time copias de seguridad descritas anteriormente). AWS proporciona una replicación de datos asincrónica, continua y entre regiones mediante los siguientes servicios y recursos:
Con la replicación continua, las versiones de sus datos están disponibles casi de inmediato en su región de DR. Los tiempos de replicación reales se pueden monitorear mediante funciones de servicio como S3 Replication Time Control (S3 RTC) para objetos de S3 y funciones de administración de las bases de datos globales de Amazon Aurora.
Si no puede ejecutar su read/write carga de trabajo desde la región de recuperación ante desastres, debe promover una réplica de lectura de RDS para que se convierta en la instancia principal. En el caso de las instancias de base de datos distintas de Aurora, el proceso tarda unos minutos en completarse y el reinicio forma parte del proceso. Para la replicación entre regiones (CRR) y la conmutación por error con RDS, el uso de la base de datos global Amazon Aurora ofrece varias ventajas. La base de datos global utiliza una infraestructura dedicada que deja sus bases de datos completamente disponibles para servir a su aplicación y puede replicarse en la región secundaria con una latencia típica de menos de un segundo (y dentro de una región de AWS es mucho menor a 100 milisegundos). Con la base de datos global Amazon Aurora, si su región principal sufre una disminución del rendimiento o una interrupción, puede promover una de las regiones secundarias para que asuma responsabilidades de lectura/escritura en menos de un minuto, incluso en el caso de que se produzca una interrupción regional total. También puede configurar Aurora para que supervise el tiempo de retraso del RPO de todos los clústeres secundarios y asegurarse de que al menos un clúster secundario permanezca dentro de la ventana de RPO de destino.
Debe implementar una versión reducida de su infraestructura de carga de trabajo principal con menos o menos recursos en su región de DR. Con él AWS CloudFormation, puede definir su infraestructura e implementarla de manera uniforme en todas las cuentas y regiones de AWS. AWS CloudFormation utiliza pseudoparámetros predefinidos para identificar la cuenta de AWS y la región de AWS en las que se implementa. Por lo tanto, puede implementar la lógica de condiciones en sus CloudFormation plantillas para implementar solo la versión reducida de su infraestructura en la región de DR. Por EC2 ejemplo, en las implementaciones, una Amazon Machine Image (AMI) proporciona información como la configuración del hardware y el software instalado. Puede implementar una canalización de Image Builder que cree las que AMIs necesite y copiarlas tanto en la región principal como en la de respaldo. Esto ayuda a garantizar que estas regiones AMIscuenten con todo lo que necesita para volver a implementar o ampliar su carga de trabajo en una nueva región, en caso de que se produzca un desastre. Las EC2 instancias de Amazon se implementan en una configuración reducida (menos instancias que en su región principal). Para ampliar la infraestructura para soportar el tráfico de producción, consulte Amazon EC2 Auto Scaling
En el caso de una active/passive configuración como la de un semáforo piloto, todo el tráfico se dirige inicialmente a la región principal y pasa a la región de recuperación ante desastres si la región principal ya no está disponible. Esta operación de conmutación por error se puede iniciar automática o manualmente. La conmutación por error que se inicia automáticamente y que se basa en controles de estado o alarmas debe utilizarse con precaución. Incluso si se utilizan las prácticas recomendadas aquí, el tiempo y el punto de recuperación serán superiores a cero, lo que provocará cierta pérdida de disponibilidad y datos. Si realiza una conmutación por error cuando no es necesario (falsa alarma), incurre en esas pérdidas. Por tanto, la conmutación por error iniciada manualmente es la que se suele utilizar. En este caso, debe seguir automatizando los pasos de la conmutación por error, de modo que la iniciación manual sea como pulsar un botón.
Hay varias opciones de administración del tráfico que se deben tener en cuenta al utilizar AWS los servicios.
Una opción es utilizar Amazon Route 53
Otra opción es utilizar AWS Global Accelerator
Amazon CloudFront
AWS Elastic Disaster Recovery
AWS Elastic Disaster Recovery
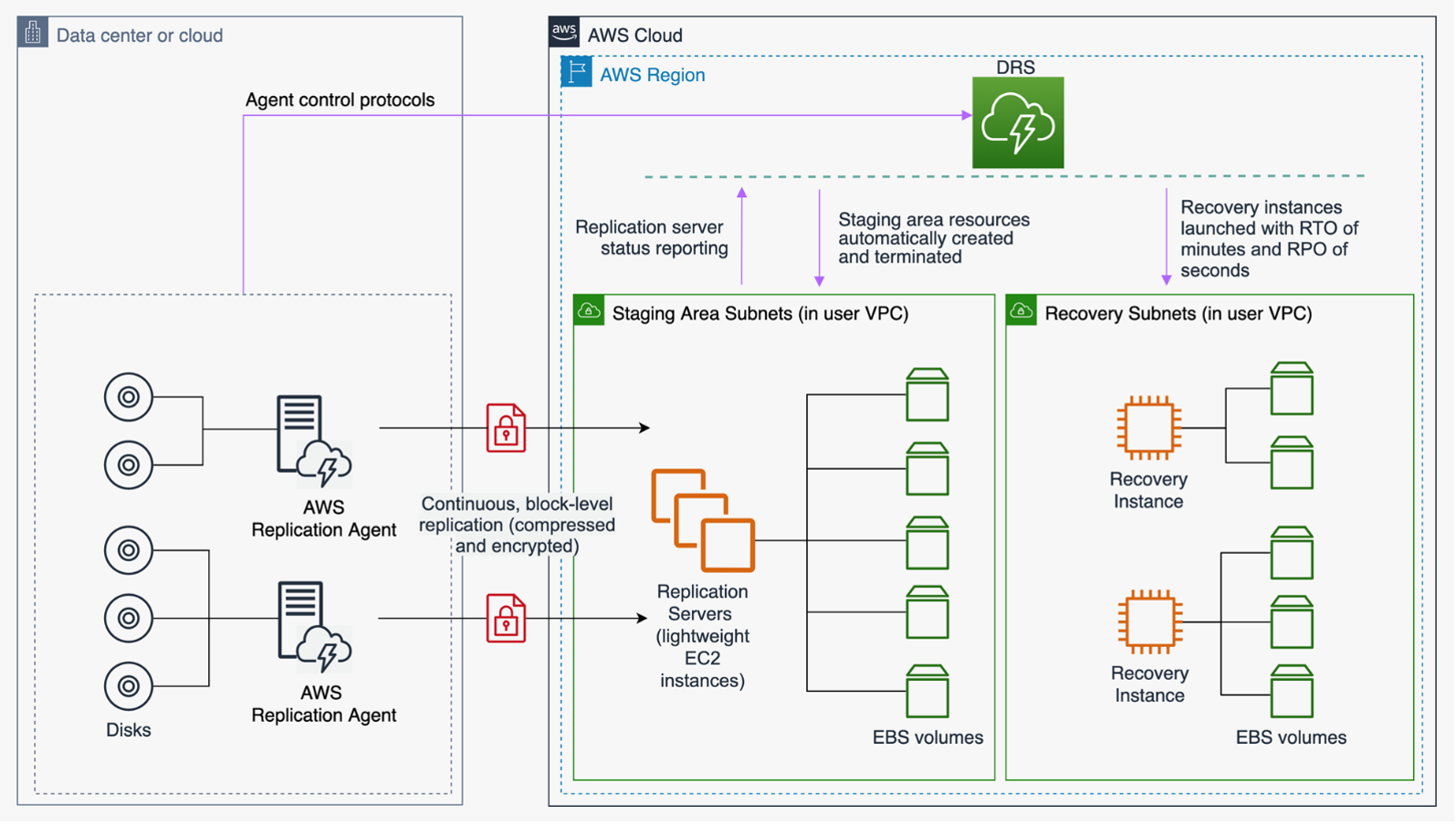
Figura 10: Arquitectura de AWS Elastic Disaster Recovery
Espera semiactiva
El enfoque de espera semiactiva implica garantizar que haya una copia reducida, pero completamente funcional, del entorno de producción en otra región. Este enfoque extiende el concepto de luz piloto y reduce el tiempo de recuperación, ya que su carga de trabajo tiene disponibilidad permanente en otra región. Este enfoque también le permite realizar pruebas con mayor facilidad o implementar pruebas continuas para aumentar la confianza en su capacidad de recuperación tras un desastre.
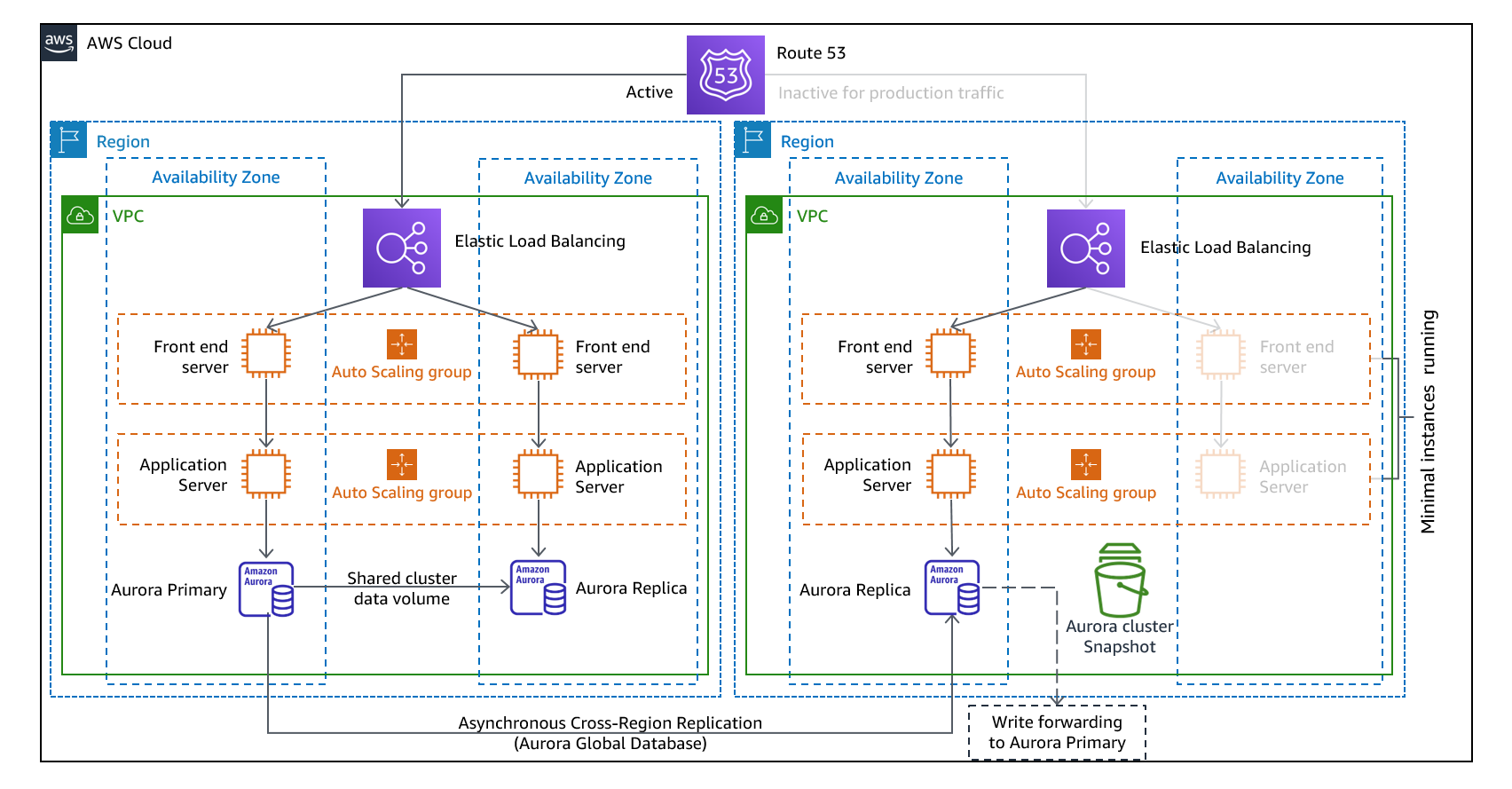
Figura 11: Arquitectura de modo de espera en caliente
Nota: La diferencia entre la luz piloto y la estación de espera cálida a veces puede resultar difícil de entender. Ambos incluyen un entorno en su región de RD con copias de los activos de su región principal. La diferencia es que Pilot Light no puede procesar las solicitudes sin antes tomar medidas adicionales, mientras que en modo de espera en caliente se puede gestionar el tráfico (con niveles de capacidad reducidos) de forma inmediata. El enfoque piloto requiere «encender» los servidores, posiblemente implementar una infraestructura adicional (no esencial) y ampliarlos, mientras que en modo de espera temporal solo es necesario ampliarlos (todo ya está desplegado y funcionando). Utilice sus necesidades de RTO y RPO para ayudarle a elegir entre estos enfoques.
Servicios de AWS
Todos los servicios de AWS incluidos en las secciones de copia de seguridad y restauración y Pilot Light también se utilizan en modo de espera caliente para la copia de seguridad de datos, la replicación de datos, el enrutamiento del active/passive tráfico y el despliegue de la infraestructura, incluidas EC2 las instancias.
Amazon EC2 Auto Scaling se utiliza para escalar
Como Auto Scaling es una actividad del plano de control, depender de él reducirá la resiliencia de su estrategia de recuperación general. Se trata de una compensación. Puede optar por aprovisionar una capacidad suficiente para que la región de recuperación pueda gestionar toda la carga de producción tal como se haya desplegado. Esta configuración estable desde el punto de vista estático se denomina modo de espera activa (consulte la siguiente sección). O puede optar por aprovisionar menos recursos, lo que le costará menos, pero dependerá de Auto Scaling. Algunas implementaciones de DR desplegarán recursos suficientes para gestionar el tráfico inicial, lo que garantizará un RTO bajo, y luego dependerán de Auto Scaling para aumentar el tráfico posterior.
Activa-activa multisitio
Puede gestionar su carga de trabajo simultáneamente en varias regiones como parte de una estrategia activa/activa o pasiva multisitio o en modo de espera activa o pasiva. Los sitios múltiples active/active atienden el tráfico de todas las regiones en las que están desplegados, mientras que el modo de espera activa solo atiende el tráfico de una sola región y las demás regiones solo se utilizan para la recuperación ante desastres. Con un active/active enfoque multisitio, los usuarios pueden acceder a su carga de trabajo en cualquiera de las regiones en las que esté desplegada. Este enfoque es el más complejo y costoso de la recuperación ante desastres, pero puede reducir el tiempo de recuperación prácticamente a cero en la mayoría de los casos si se utilizan la tecnología y la implementación correctas (sin embargo, la corrupción de los datos puede tener que depender de las copias de seguridad, lo que normalmente se traduce en un punto de recuperación distinto de cero). El modo de espera activo utiliza una active/passive configuración en la que los usuarios solo se dirigen a una sola región y las regiones de DR no reciben tráfico. La mayoría de los clientes consideran que, si quieren instalar un entorno completo en la segunda región, tiene sentido utilizarlo activo/activo. Como alternativa, si no desea utilizar ambas regiones para gestionar el tráfico de usuarios, Warm Standby ofrece un enfoque más económico y menos complejo desde el punto de vista operativo.
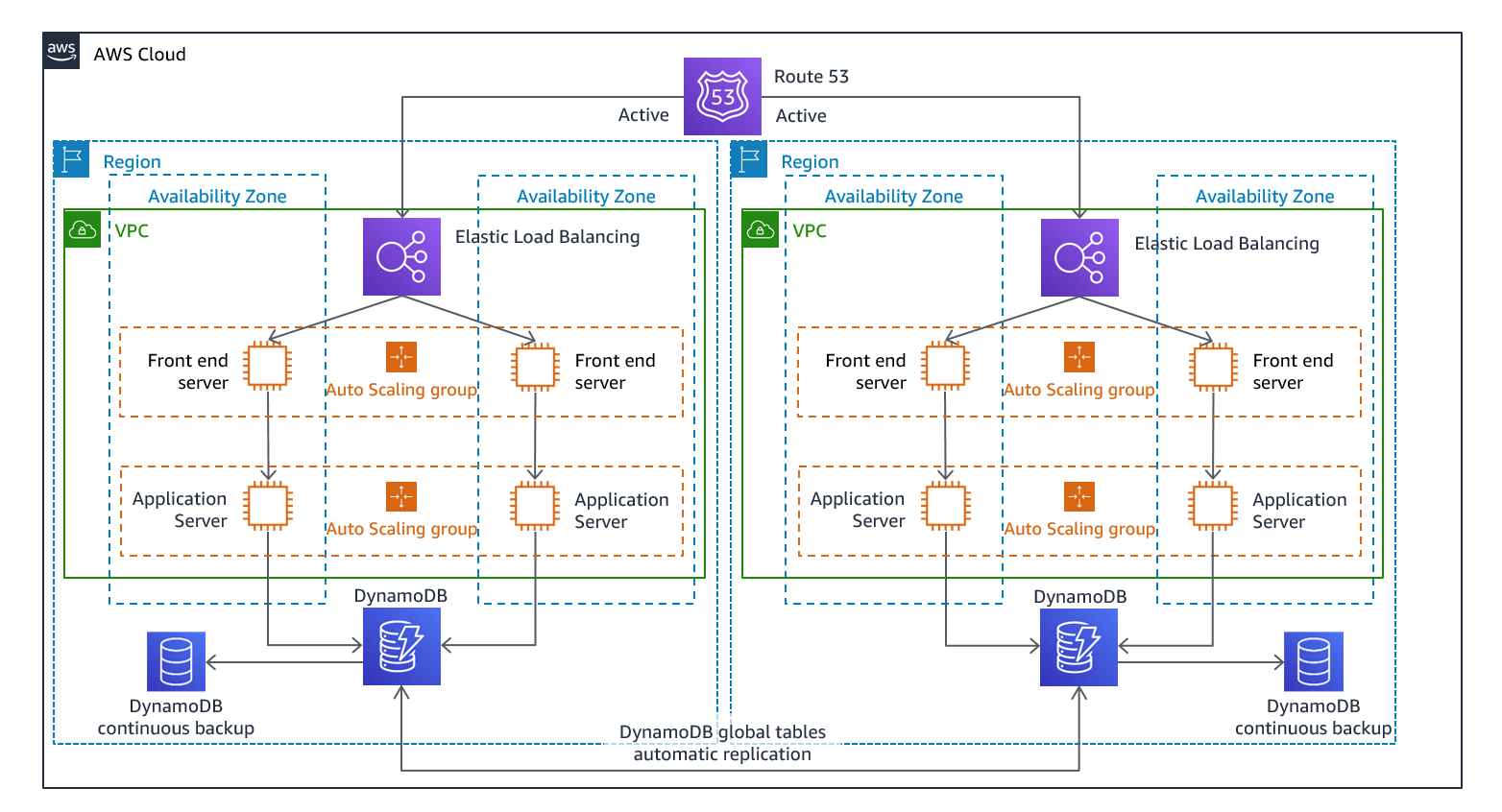
Figura 12: active/active Arquitectura multisitio (cambie una ruta activa a inactiva para el modo de espera activo)
Si se opta por un enfoque multisitio active/active, because the workload is running in more than one Region, there is no such thing as failover in this scenario. Disaster recovery testing in this case would focus on how the workload reacts to loss of a Region: Is traffic routed away from the failed Region? Can the other Region(s) handle all the traffic? Testing for a data disaster is also required. Backup and recovery are still required and should be tested regularly. It should also be noted that recovery times for a data disaster involving data corruption, deletion, or obfuscation will always be greater than zero and the recovery point will always be at some point before the disaster was discovered. If the additional complexity and cost of a multi-site active/active (o en modo de espera activa), es necesario mantener los tiempos de recuperación prácticamente nulos, por lo que se deben realizar esfuerzos adicionales para mantener la seguridad y evitar los errores humanos a fin de mitigar los desastres humanos.
Servicios de AWS
Todos los servicios de AWS incluidos en respaldo y restauración, Pilot Light y Warm standby también se utilizan aquí para el respaldo de point-in-time datos, la replicación de datos, el enrutamiento active/active del tráfico y el despliegue y escalado de la infraestructura, incluidas EC2 las instancias.
Para los active/passive escenarios descritos anteriormente (Pilot Light y Warm Standby), tanto Amazon Route 53 como Amazon AWS Global Accelerator pueden usarse para enrutar el tráfico de la red a la región activa. Para la active/active estrategia en este caso, ambos servicios también permiten definir políticas que determinan qué usuarios van a qué punto final regional activo. Configura un dial de tráfico para controlar el porcentaje de tráfico que se dirige a cada punto final de la aplicación. AWS Global Accelerator Amazon Route 53 admite este enfoque porcentual y también varias otras políticas disponibles, incluidas las basadas en la geoproximidad y la latencia. Global Accelerator aprovecha automáticamente la amplia red de servidores perimetrales de AWS para incorporar el tráfico a la red troncal de AWS lo antes posible, lo que reduce las latencias de las solicitudes.
La replicación asíncrona de datos con esta estrategia permite un RPO prácticamente nulo. Los servicios de AWS, como la base de datos global Amazon Aurora, utilizan una infraestructura dedicada que deja sus bases de datos totalmente disponibles para servir a su aplicación y pueden replicarse en hasta cinco regiones secundarias con una latencia típica de menos de un segundo. active/passive strategies, writes occur only to the primary Region. The difference with active/activeEstá diseñando cómo se gestiona la coherencia de los datos con las escrituras en cada región activa. Es habitual diseñar las lecturas de los usuarios para que las entreguen desde la región más cercana a ellos, lo que se conoce como lectura local. Con las escrituras, tienes varias opciones:
-
Una estrategia global de escritura dirige todas las escrituras a una sola región. En caso de que esa región fracase, se promovería a otra región para que aceptara escrituras. La base de datos global Aurora es una buena opción para la escritura global, ya que admite la sincronización con réplicas de lectura en todas las regiones y puede promover que una de las regiones secundarias read/write asuma responsabilidades en menos de un minuto. Aurora también admite el reenvío de escritura, que permite a los clústeres secundarios de una base de datos global de Aurora reenviar sentencias SQL que realizan operaciones de escritura al clúster principal.
-
Una estrategia local de escritura enruta las escrituras a la región más cercana (igual que las lecturas). Las tablas globales de Amazon DynamoDB permiten esta estrategia, ya que permiten leer y escribir en todas las regiones en las que esté desplegada la tabla global. En las tablas globales de Amazon DynamoDB, el último escritor gana la reconciliación entre las actualizaciones simultáneas.
-
Una estrategia de escritura particionada asigna las escrituras a una región específica en función de una clave de partición (como el ID de usuario) para evitar conflictos de escritura. La replicación de Amazon S3 configurada de forma bidireccional
se puede utilizar en este caso y, actualmente, admite la replicación entre dos regiones. Al implementar este enfoque, asegúrese de habilitar la sincronización de las modificaciones de las réplicas en los depósitos A y B para replicar los cambios en los metadatos de las réplicas, como las listas de control de acceso a los objetos (ACLs), las etiquetas de objetos o los bloqueos de objetos en los objetos replicados. También puede configurar si desea replicar o no los marcadores de eliminación entre los depósitos de sus regiones activas. Además de la replicación, su estrategia también debe incluir point-in-time copias de seguridad para evitar que los datos se corrompan o destruyan.
AWS CloudFormation es una herramienta poderosa para aplicar una infraestructura implementada de manera uniforme entre las cuentas de AWS en varias regiones de AWS. AWS CloudFormation StackSetsamplía esta funcionalidad al permitirle crear, actualizar o eliminar CloudFormation pilas en varias cuentas y regiones con una sola operación. Aunque AWS CloudFormation utiliza YAML o JSON para definir la infraestructura como código, AWS Cloud Development Kit (AWS CDK)
