Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Creación de un filtro de vocabulario
Existen dos opciones para crear un filtro de vocabulario personalizado:
-
Guarda una lista de palabras separadas por líneas como un archivo de texto plano con UTF-8 codificación.
Puedes usar este enfoque con los Consola de administración de AWS AWS CLI, o los AWS SDK.
Si utilizas el Consola de administración de AWS, puedes proporcionar una ruta local o un Amazon S3 URI para tu archivo de vocabulario personalizado.
Si utilizas los AWS CLI AWS SDK, debes cargar tu archivo de vocabulario personalizado en un Amazon S3 depósito e incluir el Amazon S3 URI en tu solicitud.
-
Incluir una lista de palabras separadas por comas directamente en su solicitud de API.
-
Puedes usar este enfoque con los AWS CLI o los AWS SDK mediante el
Wordsparámetro.
-
Para ver ejemplos de cada método, consulte Crear filtros de vocabulario personalizados
Aspectos que debe tener en cuenta al crear su filtro de vocabulario personalizado:
-
Las palabras no distinguen entre mayúsculas y minúsculas. Por ejemplo, “maldición” y “MALDICIÓN” se consideran la misma palabra.
-
Sólo se filtran las coincidencias exactas de palabras. Por ejemplo, si el filtro incluye “decir groserías” pero el contenido multimedia contiene la palabra “decir grosería” o “grosero”, estas palabras no se filtran. Sólo se filtran los casos en los que se dice “decir groserías”. Por lo tanto, debe incluir todas las variantes de las palabras que desee filtrar.
-
Los filtros no se aplican a las palabras que están contenidas en otras palabras. Por ejemplo, si un filtro de vocabulario contiene “marino”, pero no “submarino”, “submarino”.no se modifica en la transcripción.
-
Cada entrada sólo puede contener una palabra (sin espacios).
-
Si guardas tu filtro de vocabulario personalizado como un archivo de texto, debe estar en formato de texto plano con UTF-8 codificación.
-
Puedes tener hasta 100 filtros de vocabulario personalizados por cada uno Cuenta de AWS y cada uno puede tener un tamaño máximo de 50 Kb.
-
Sólo puede usar caracteres compatibles con su idioma. Consulte el conjunto de caracteres de su idioma para obtener más información.
Crear filtros de vocabulario personalizados
Para procesar un filtro de vocabulario personalizado y usarlo con Amazon Transcribeél, consulta los siguientes ejemplos:
Antes de continuar, guarde el filtro de vocabulario personalizado como un archivo de texto (*.txt). Si lo desea, puede cargar el archivo en un Amazon S3 depósito.
-
Inicie sesión en la Consola de administración de AWS
. -
En el panel de navegación, elija Filtrado de vocabulario. Esto abre la página Filtros de vocabulario, donde puede ver los vocabularios existentes o crear uno nuevo.
-
Seleccione Crear filtro de vocabulario.
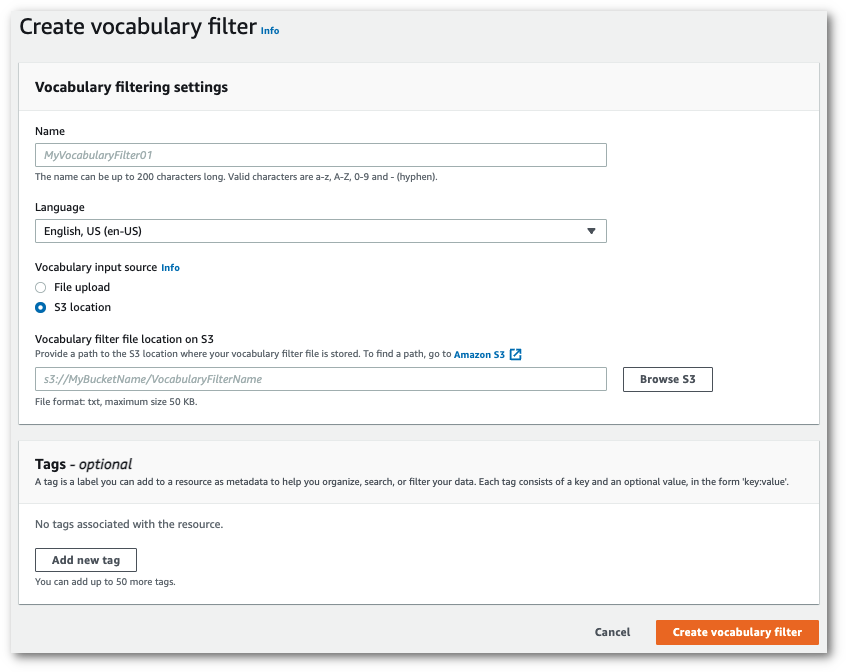
Esto le llevará a la página Crear filtro de vocabulario. Escriba un nombre para su nuevo filtro de vocabulario personalizado.
Seleccione la opción Carga de archivos o Ubicación de S3 en Fuente de entrada del vocabulario. A continuación, especifique la ubicación del archivo de vocabulario personalizado.
-
De manera opcional, agregue etiquetas a su filtro de vocabulario personalizado. Cuando haya completado todos los campos, seleccione Crear filtro de vocabulario en la parte inferior de la página. Si no hay ningún error al procesar el archivo, volverás a la página Filtros de vocabulario.
El filtro de vocabulario personalizado ya está listo para su uso.
En este ejemplo, se utiliza el comando create-vocabulary-filter para procesar una lista de palabras y convertirla en un filtro de vocabulario personalizado utilizable. Para obtener más información, consulte CreateVocabularyFilter.
Opción 1: puede incluir su lista de palabras en su solicitud mediante el parámetro words.
aws transcribe create-vocabulary-filter \ --vocabulary-filter-namemy-first-vocabulary-filter\ --language-codeen-US\ --wordsprofane,offensive,Amazon,Transcribe
Opción 2: puede guardar la lista de palabras como un archivo de texto y subirla a un bucket de Amazon S3 y, a continuación, incluir el URI del archivo en la solicitud mediante el parámetro vocabulary-filter-file-uri.
aws transcribe create-vocabulary-filter \ --vocabulary-filter-namemy-first-vocabulary-filter\ --language-codeen-US\ --vocabulary-filter-file-uri s3://amzn-s3-demo-bucket/my-vocabulary-filters/my-vocabulary-filter.txt
Este es otro ejemplo en el que se usa el comando create-vocabulary-filter y un cuerpo de la solicitud que crea su filtro de vocabulario personalizado.
aws transcribe create-vocabulary-filter \ --cli-input-json file://filepath/my-first-vocab-filter.json
El archivo my-first-vocab-filter.json contiene el siguiente cuerpo de la solicitud.
Opción 1: puede incluir su lista de palabras en su solicitud mediante el parámetro Words.
{ "VocabularyFilterName": "my-first-vocabulary-filter", "LanguageCode": "en-US", "Words": [ "profane","offensive","Amazon","Transcribe" ] }
Opción 2: puede guardar la lista de palabras como un archivo de texto y subirla a un bucket de Amazon S3 y, a continuación, incluir el URI del archivo en la solicitud mediante el parámetro VocabularyFilterFileUri.
{ "VocabularyFilterName": "my-first-vocabulary-filter", "LanguageCode": "en-US", "VocabularyFilterFileUri": "s3://amzn-s3-demo-bucket/my-vocabulary-filters/my-vocabulary-filter.txt" }
nota
Si incluye VocabularyFilterFileUri en su solicitud, no puede usar Words; debe elegir uno u otro.
En este ejemplo, se utiliza AWS SDK para Python (Boto3) para crear un filtro de vocabulario personalizado mediante el método create_vocabulary_filter.CreateVocabularyFilter.
Para ver ejemplos adicionales sobre el uso de los AWS SDK, incluidos ejemplos de funciones específicas, escenarios y servicios cruzados, consulta el capítulo. Ejemplos de código para Amazon Transcribe usando AWS SDK
Opción 1: puede incluir su lista de palabras en su solicitud mediante el parámetro Words.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary-filter" response = transcribe.create_vocabulary_filter( LanguageCode = 'en-US', VocabularyFilterName = vocab_name, Words = [ 'profane','offensive','Amazon','Transcribe' ] )
Opción 2: puede guardar la lista de palabras como un archivo de texto y subirla a un bucket de Amazon S3 y, a continuación, incluir el URI del archivo en la solicitud mediante el parámetro VocabularyFilterFileUri.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary-filter" response = transcribe.create_vocabulary_filter( LanguageCode = 'en-US', VocabularyFilterName = vocab_name, VocabularyFilterFileUri = 's3://amzn-s3-demo-bucket/my-vocabulary-filters/my-vocabulary-filter.txt' )
nota
Si incluye VocabularyFilterFileUri en su solicitud, no puede usar Words; debe elegir uno u otro.
nota
Si creas un nuevo Amazon S3 depósito para tus archivos de filtro de vocabulario personalizados, asegúrate de que el IAM rol que realiza la CreateVocabularyFiltersolicitud tenga permisos para acceder a este depósito. Si el rol no tiene los permisos correctos, la solicitud fallará. Si lo desea, puede especificar un IAM rol en su solicitud incluyendo el DataAccessRoleArn parámetro. Para obtener más información sobre las IAM funciones y políticas de Amazon Transcribe, consulteAmazon Transcribe ejemplos de políticas basadas en identidades.
