Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Creación de un modelo de idioma personalizado
Antes de poder crear un modelo de idioma personalizado, debe:
-
Preparar los datos. Los datos deben guardarse en formato de texto plano y no pueden contener caracteres especiales.
-
Cargue sus datos en un Amazon S3 depósito. Se recomienda crear carpetas independientes para los datos de entrenamiento y ajuste.
-
Asegúrate de que Amazon Transcribe tiene acceso a tu Amazon S3 depósito. Debes especificar un IAM rol que tenga permisos de acceso para usar tus datos.
Preparación de los datos de entrada
Puede compilar todos los datos en un archivo o guardarlos como varios archivos. Tenga en cuenta que si decide incluir datos de ajuste, debe guardarlos en un archivo diferente al de sus datos de entrenamiento.
No importa cuántos archivos de texto utilice para sus datos de entrenamiento o de ajuste. Al subir un archivo de 100 000 palabras se obtiene el mismo resultado que al subir 10 archivos de 10 000 palabras. Prepare los datos de texto de la forma que le resulte más cómoda.
Asegúrese de que todos los archivos de datos cumplen los siguientes criterios:
-
Todos están en el mismo idioma que el modelo que desea crear. Por ejemplo, si desea crear un modelo de idioma personalizado que transcriba el audio en inglés estadounidense (
en-US), todos los datos de texto deben estar en inglés estadounidense. -
Están en formato de texto plano con UTF-8 codificación.
-
No contienen caracteres ni formatos especiales, como etiquetas HTML.
-
Tienen un tamaño total combinado máximo de 2 GB para los datos de entrenamiento y 200 MB para los datos de ajuste.
Si no se cumple cualquiera de estos criterios, el modelo fallará.
Cargar los datos
Antes de subir sus datos, cree una nueva carpeta para sus datos de entrenamiento. Si utiliza datos de ajuste, cree otra carpeta independiente.
Los URI de sus buckets podrían tener el siguiente aspecto:
-
s3://amzn-s3-demo-bucket/my-model-training-data/ -
s3://amzn-s3-demo-bucket/my-model-tuning-data/
Cargue sus datos de entrenamiento y ajuste en los buckets correspondientes.
Puede agregar más datos a estos buckets más adelante. Sin embargo, si lo hace, tendrá que volver a crear el modelo con los nuevos datos. Los modelos existentes no se pueden actualizar con datos nuevos.
Permitir el acceso a sus datos
Para crear un modelo de lenguaje personalizado, debes especificar un IAM rol que tenga permisos para acceder a tu Amazon S3 bucket. Si aún no tienes un rol con acceso al Amazon S3 depósito en el que colocaste tus datos de entrenamiento, debes crear uno. Una vez que crea un rol, puede adjuntar una política para conceder permisos a ese rol. Asociar una política a un usuario.
Para ver ejemplos de políticas, consulte Amazon Transcribe ejemplos de políticas basadas en identidades.
Para obtener información sobre cómo crear una nueva IAM identidad, consulte IAM Identidades (usuarios, grupos de usuarios y roles).
Para obtener más información acerca de las políticas de IAM, consulte:
Crear un modelo de idioma personalizado
Al crear su modelo de idioma personalizado, debe elegir un modelo base. Hay dos opciones de modelo base:
-
NarrowBand: utilice esta opción para audio con una frecuencia de muestreo inferior a 16 000 Hz. Este tipo de modelo se utiliza normalmente para conversaciones telefónicas grabadas a 8000 Hz. -
WideBand: utilice esta opción para audio con una frecuencia de muestreo mayor que o igual a 16 000 Hz.
Puede crear modelos de lenguaje personalizados mediante los Consola de administración de AWS AWS CLI, o AWS los SDK. Consulte los siguientes ejemplos:
-
Inicie sesión en la Consola de administración de AWS
. -
En el panel de navegación, elija Modelo de idioma personalizado. Esto abre la página Modelos de idioma personalizados, donde puede ver los modelos de idioma personalizados existentes o entrenar un nuevo modelo de idioma personalizado.
-
Para entrenar un modelo nuevo, seleccione Modelo de entrenamiento.
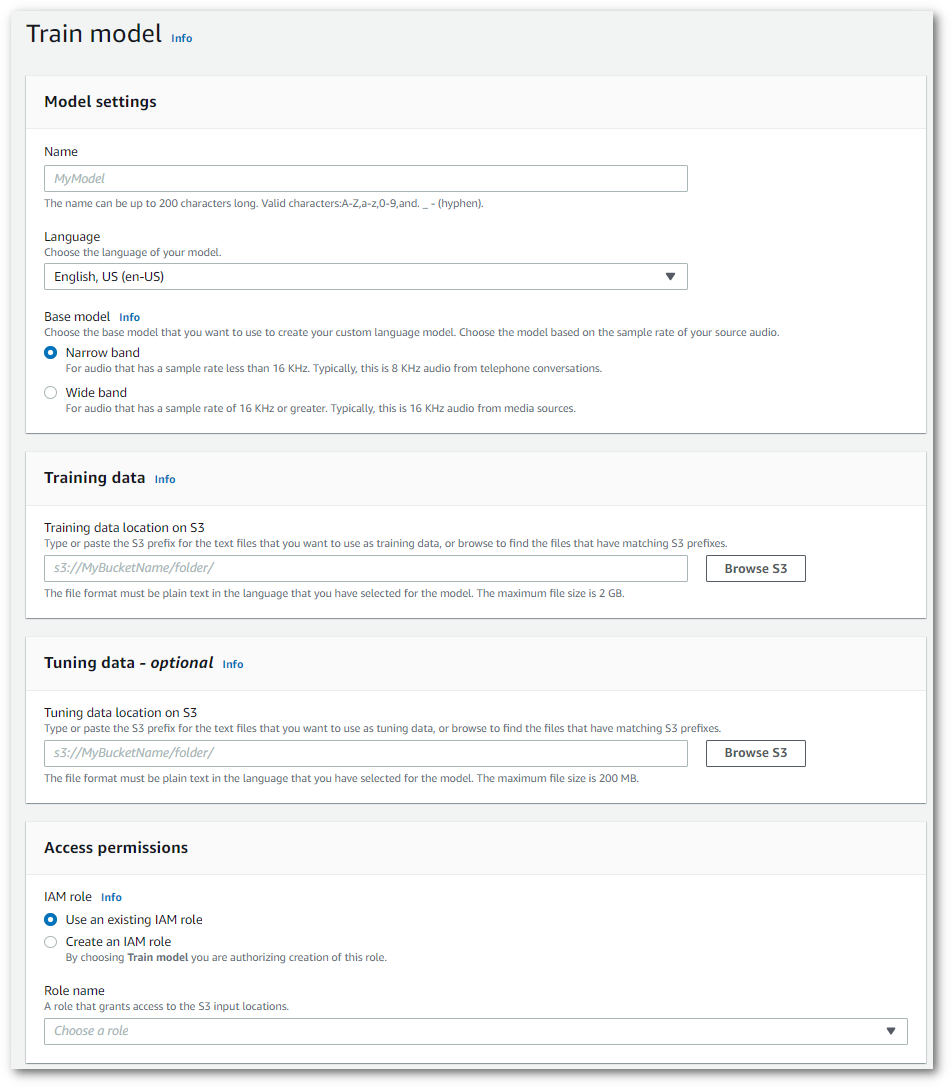
Esto le lleva a la página Modelo de entrenamiento. Agregue un nombre, especifique el idioma y elija el modelo base que desee para su modelo. A continuación, agregue la ruta de su entrenamiento y, de forma opcional, a sus datos de ajuste. Debes incluir un IAM rol que tenga permisos para acceder a tus datos.
-
Cuando haya completado todos los campos, seleccione Modelo de entrenamiento en la parte inferior de la página.
En este ejemplo se utiliza el comando create-language-modelCreateLanguageModel y LanguageModel.
aws transcribe create-language-model \ --base-model-nameNarrowBand\ --model-namemy-first-language-model\ --input-data-config S3Uri=s3://amzn-s3-demo-bucket/my-clm-training-data/,TuningDataS3Uri=s3://amzn-s3-demo-bucket/my-clm-tuning-data/,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole\ --language-codeen-US
A continuación, se muestra otro ejemplo en el que se utiliza el comando create-language-model
aws transcribe create-language-model \ --cli-input-json file://filepath/my-first-language-model.json
El archivo my-first-language-model.json contiene el siguiente cuerpo de la solicitud.
{ "BaseModelName": "NarrowBand", "ModelName": "my-first-language-model", "InputDataConfig": { "S3Uri": "s3://amzn-s3-demo-bucket/my-clm-training-data/", "TuningDataS3Uri"="s3://amzn-s3-demo-bucket/my-clm-tuning-data/", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" }, "LanguageCode": "en-US" }
En este ejemplo, se utiliza AWS SDK para Python (Boto3) para crear un CLM mediante el método create_language_model.CreateLanguageModel y LanguageModel.
Para ver ejemplos adicionales sobre el uso de los AWS SDK, incluidos ejemplos de funciones específicas, escenarios y servicios cruzados, consulte el capítulo. Ejemplos de código para Amazon Transcribe usando AWS SDK
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') model_name = 'my-first-language-model', transcribe.create_language_model( LanguageCode = 'en-US', BaseModelName = 'NarrowBand', ModelName = model_name, InputDataConfig = { 'S3Uri':'s3://amzn-s3-demo-bucket/my-clm-training-data/', 'TuningDataS3Uri':'s3://amzn-s3-demo-bucket/my-clm-tuning-data/', 'DataAccessRoleArn':'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_language_model(ModelName = model_name) if status['LanguageModel']['ModelStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Actualización de un modelo de idioma personalizado
Amazon Transcribe actualiza continuamente los modelos base disponibles para los modelos de lenguaje personalizados. Para aprovechar estas actualizaciones, recomendamos entrenar nuevos modelos de idioma personalizados cada 6 a 12 meses.
Para comprobar si tu modelo de lenguaje personalizado utiliza el modelo base más reciente, ejecuta una DescribeLanguageModelsolicitud con el AWS CLI o un AWS SDK y, a continuación, busca el UpgradeAvailability campo en tu respuesta.
Si UpgradeAvailability es true, su modelo no ejecuta la última versión del modelo base. Para utilizar el modelo base más reciente en un modelo de idioma personalizado, debe crear un nuevo modelo de idioma personalizado. Los modelos de idioma personalizados no se pueden actualizar.
