Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Transcripción de audio multicanal
Si el audio tiene dos canales, puede usar la identificación de canales para transcribir la voz de cada canal por separado. Amazon Transcribe actualmente no admite audio con más de dos canales.
En su transcripción, a los canales se les asignan las etiquetas ch_0 ych_1.
Además de las secciones de transcripciones estándar (transcripts y items), las solicitudes con la partición de las voces habilitada incluyen una sección channel_labels. Esta sección contiene cada enunciado o signo de puntuación, agrupado por canal, y su etiqueta de canal asociada, las marcas de tiempo y la puntuación de confianza.
"channel_labels": { "channels": [ { "channel_label": "ch_0", "items": [ { "channel_label": "ch_0", "start_time": "4.86", "end_time": "5.01", "alternatives": [ { "confidence": "1.0", "content": "I've" } ], "type": "pronunciation" },..."channel_label": "ch_1", "items": [ { "channel_label": "ch_1", "start_time": "8.5", "end_time": "8.89", "alternatives": [ { "confidence": "1.0", "content": "Sorry" } ], "type": "pronunciation" },..."number_of_channels": 2 },
Si una persona de un canal habla por encima de otra persona de otro canal, las marcas de cada canal se superponen mientras unas personas hablan por encima de las otras.
Para ver un ejemplo completo de la transcripción con la identificación del canal, consulte. Ejemplo de resultados de identificación de canal (lote)
Uso de la identificación de canales en una transcripción por lotes
Para identificar canales en una transcripción por lotes, puede utilizar Consola de administración de AWS, AWS CLI o los SDK de AWS ; consulte los ejemplos siguientes:
-
Inicie sesión en la Consola de administración de AWS
. -
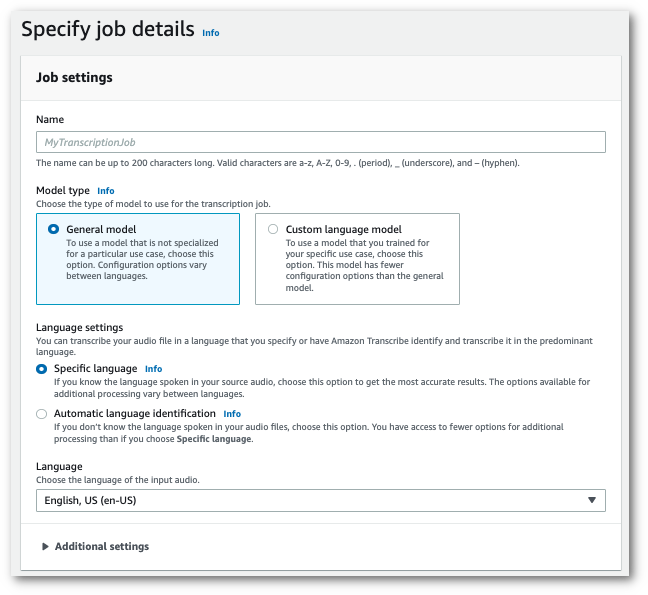
En el panel de navegación, elija Trabajos de transcripción y, a continuación, seleccione Crear trabajo (arriba a la derecha). Se abrirá la página Especificar los detalles del trabajo.
-
Rellene los campos que desee incluir en la página Especificar los detalles del trabajo y, a continuación, seleccione Siguiente. Esto lo llevará a la página Configurar trabajo: opcional.
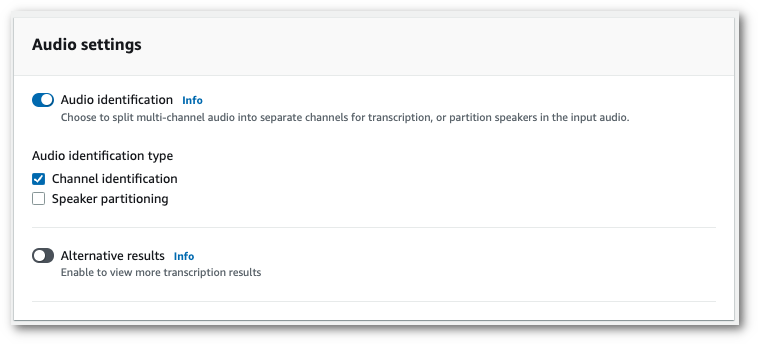
En el panel Ajustes de audio, seleccione Identificación del canal (en el encabezado “Tipo de identificación de audio”).
-
Seleccione Crear trabajo para ejecutar su trabajo de transcripción.
En este ejemplo, se usa el comando start-transcription-jobStartTranscriptionJob.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings ChannelIdentification=true
Este es otro ejemplo en el que se utiliza el comando start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-transcription-job.json
El archivo my-first-transcription-job.json contiene el siguiente cuerpo de la solicitud.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "Settings": { "ChannelIdentification": true } }
En este ejemplo, se utiliza AWS SDK para Python (Boto3) para identificar los canales mediante el método start_transcription_job
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'ChannelIdentification':True } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Uso de la identificación de canales en una transcripción por lotes
Para identificar los canales de una transcripción en streaming, puedes usar HTTP/2o WebSockets; consulta los siguientes ejemplos:
En este ejemplo, se crea una HTTP/2 solicitud que separa los canales de la salida de la transcripción. Para obtener más información sobre el uso HTTP/2 de la transmisión con Amazon Transcribe, consulteConfigurar una HTTP/2 transmisión. Para obtener más información sobre los parámetros y encabezados específicos de Amazon Transcribe, consulte. StartStreamTranscription
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-channel-identification: TRUE transfer-encoding: chunked
Las definiciones de los parámetros se encuentran en la referencia de la API; los parámetros comunes a todas las operaciones de la AWS API se enumeran en la sección Parámetros comunes.
En este ejemplo, se crea una URL prefirmada que separa los canales del resultado de la transcripción. Se han añadido saltos de línea para facilitar la lectura. Para obtener más información sobre el uso de WebSocket transmisiones con Amazon Transcribe, consulteConfiguración de una WebSocket transmisión. Para obtener más información sobre parámetros, consulte StartStreamTranscription.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US &specialty=PRIMARYCARE&type=DICTATION&media-encoding=flac&sample-rate=16000&channel-identification=TRUE
Las definiciones de los parámetros se encuentran en la referencia de la API; los parámetros comunes a todas las operaciones de la AWS API se enumeran en la sección Parámetros comunes.
