Para obtener capacidades similares a las de Amazon Timestream, considere Amazon Timestream LiveAnalytics para InfluxDB. Ofrece una ingesta de datos simplificada y tiempos de respuesta a las consultas en milisegundos de un solo dígito para realizar análisis en tiempo real. Obtenga más información aquí.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
UNLOAD
Timestream for LiveAnalytics admite un UNLOAD comando como extensión de su compatibilidad con SQL. Los tipos de datos compatibles con UNLOAD se describen en Tipos de datos compatibles. Los tipos time y unknown no se aplican a UNLOAD.
UNLOAD (SELECT statement) TO 's3://bucket-name/folder' WITH ( option = expression [, ...] )
donde la opción es
{ partitioned_by = ARRAY[ col_name[,…] ] | format = [ '{ CSV | PARQUET }' ] | compression = [ '{ GZIP | NONE }' ] | encryption = [ '{ SSE_KMS | SSE_S3 }' ] | kms_key = '<string>' | field_delimiter ='<character>' | escaped_by = '<character>' | include_header = ['{true, false}'] | max_file_size = '<value>' }
- Instrucción de selección
-
La sentencia de consulta utilizada para seleccionar y recuperar datos de uno o más Timestream para tablas. LiveAnalytics
(SELECT column 1, column 2, column 3 from database.table where measure_name = "ABC" and timestamp between ago (1d) and now() ) - Cláusula TO
-
TO 's3://bucket-name/folder'o
TO 's3://access-point-alias/folder'La cláusula
TOen la instrucciónUNLOADespecifica el destino de la salida de los resultados de la consulta. Debe proporcionar la ruta completa, incluido el nombre del bucket de Amazon S3 o el alias del punto de acceso de Amazon S3 con la ubicación de la carpeta en Amazon S3 donde Timestream for escribe los objetos del archivo de salida. LiveAnalytics El bucket de S3 debe pertenecer a la misma cuenta y estar en la misma región. Además del conjunto de resultados de la consulta, Timestream for LiveAnalytics escribe los archivos de manifiesto y metadatos en la carpeta de destino especificada. - Cláusula PARTITIONED_BY
-
partitioned_by = ARRAY [col_name[,…] , (default: none)La cláusula
partitioned_byse usa en las consultas para agrupar y analizar los datos a un nivel granular. Al exportar los resultados de la consulta al bucket de S3, puede elegir dividir los datos en función de una o más columnas de la consulta seleccionada. Al particionar los datos, los datos exportados se dividen en subconjuntos según la columna de partición y cada subconjunto se almacena en una carpeta independiente. Dentro de la carpeta de resultados que contiene los datos exportados, se crea automáticamente una subcarpetafolder/results/partition column = partition value/. Sin embargo, tenga en cuenta que las columnas particionadas no se incluyen en el archivo de salida.partitioned_byno es una cláusula obligatoria en la sintaxis. Si opta por exportar los datos sin ninguna partición, puede excluir la cláusula de la sintaxis.ejemplo
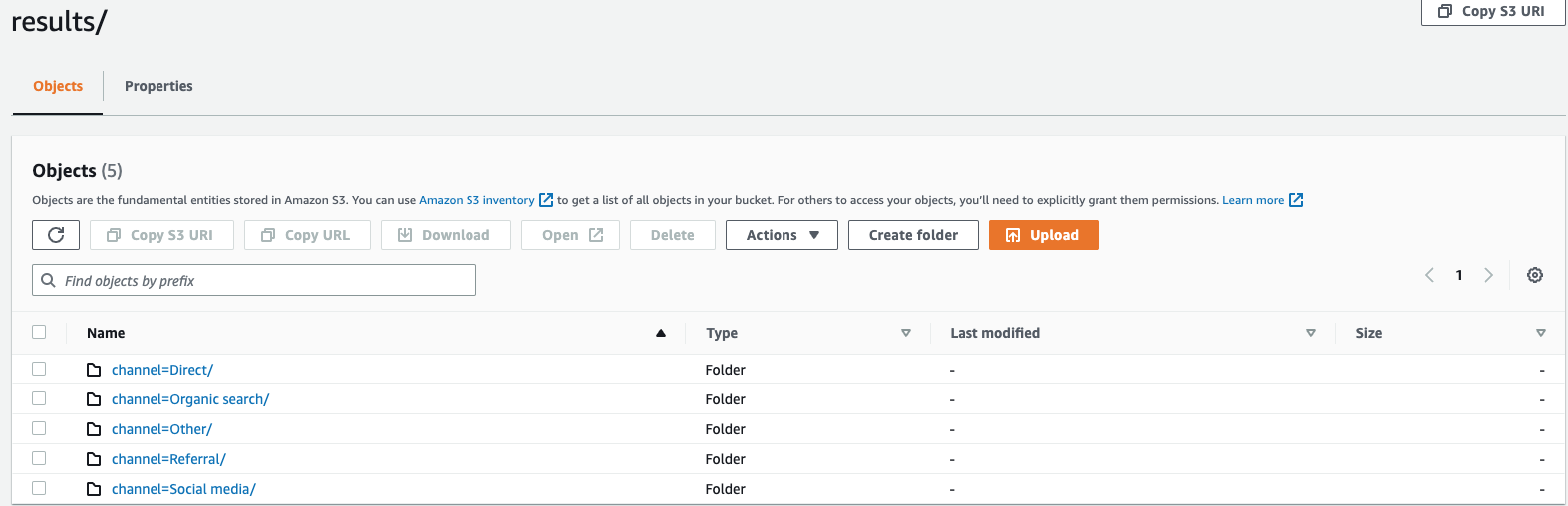
Supongamos que está supervisando los datos del flujo de clics de su sitio web y tiene 5 canales de tráfico, a saber,
direct,Social Media,Organic Search,OtheryReferral. Al exportar los datos, puede optar por particionarlos mediante la columnaChannel. Dentro de la carpeta de datos,s3://bucketname/results, tendrá cinco carpetas, cada una con su nombre de canal respectivo. Por ejemplo,s3://bucketname/results/channel=Social Media/.. Dentro de esta carpeta, encontrará los datos de todos los clientes que llegaron a tu sitio web a través del canalSocial Media. Del mismo modo, dispondrá de otras carpetas para el resto de los canales.Datos exportados particionados por columna de canales
- FORMAT
-
format = [ '{ CSV | PARQUET }' , default: CSVLas palabras clave para especificar el formato de los resultados de la consulta que se escriben en su bucket de S3. Puede exportar los datos como valores separados por comas (CSV) que usan coma (,) como delimitador predeterminado o en el formato Apache Parquet, un eficaz formato de almacenamiento en columnas abiertas para el análisis.
- COMPRESSION
-
compression = [ '{ GZIP | NONE }' ], default: GZIPPuede comprimir los datos exportados mediante el algoritmo de compresión GZIP o descomprimirlos si especifica la opción
NONE. - ENCRYPTION
-
encryption = [ '{ SSE_KMS | SSE_S3 }' ], default: SSE_S3Los archivos de salida en Amazon S3 se cifran mediante la opción de cifrado que haya seleccionado. Además de sus datos, los archivos de manifiesto y metadatos también se cifran en función de la opción de cifrado que haya seleccionado. Actualmente, admitimos el cifrado SSE_S3 y SSE_KMS. SSE_S3 es un cifrado del lado del servidor en el que Amazon S3 cifra los datos mediante el cifrado estándar de cifrado avanzado (AES) de 256 bits. El SSE_KMS es un cifrado del lado del servidor para cifrar los datos mediante claves administradas por el cliente.
- KMS_KEY
-
kms_key = '<string>'La clave KMS es una clave definida por el cliente para cifrar los resultados de las consultas exportadas. Key Management Service (KMS) gestiona de forma segura la AWS clave AWS KMS y se utiliza para cifrar archivos de datos en Amazon S3.
- FIELD_DELIMITER
-
field_delimiter ='<character>' , default: (,)Al exportar los datos en formato CSV, este campo especifica un carácter ASCII único que se utiliza para separar campos en el archivo de salida, como un carácter de barra vertical (|), una coma (,) o una tabulación (\t). El delimitador predeterminado para los archivos CSV es un carácter de coma. Si un valor de los datos contiene el delimitador elegido, el delimitador aparecerá entre comillas. Por ejemplo, si el valor de sus datos contiene
Time,stream, este valor se indicará como"Time,stream"en los datos exportados. El carácter de comilla utilizado por Timestream LiveAnalytics son comillas dobles («).Evite especificar el carácter de retorno (ASCII 13, hexadecimal
0D, texto “\r”) o el carácter de salto de línea (ASCII 10, hexadecimal 0A, texto “\n”) comoFIELD_DELIMITERsi desea incluir encabezados en el CSV, ya que esto impedirá que muchos analizadores puedan analizar los encabezados correctamente en la salida CSV resultante. - ESCAPED_BY
-
escaped_by = '<character>', default: (\)Al exportar los datos en formato CSV, este campo especifica el carácter que debe tratarse como un carácter de escape en el archivo de datos escrito en el bucket de S3. Esto ocurre en las siguientes situaciones:
-
Si el valor en sí contiene el carácter entre comillas ("), se escapará mediante un carácter de escape. Por ejemplo, si el valor es
Time"stream, donde (\) es el carácter de escape configurado, se escapa comoTime\"stream. -
Si el valor contiene el carácter de escape configurado, se escapará. Por ejemplo, si el valor es
Time\stream, se escapará comoTime\\stream.
nota
Si la salida exportada contiene tipos de datos complejos, como matrices, filas o series temporales, se serializará como una cadena JSON. A continuación se muestra un ejemplo.
Tipo de datos: Valor real Cómo se escapa el valor en formato CSV [cadena JSON serializada] Matriz
[ 23,24,25 ]"[23,24,25]"Fila
( x=23.0, y=hello )"{\"x\":23.0,\"y\":\"hello\"}"Serie temporal
[ ( time=1970-01-01 00:00:00.000000010, value=100.0 ),( time=1970-01-01 00:00:00.000000012, value=120.0 ) ]"[{\"time\":\"1970-01-01 00:00:00.000000010Z\",\"value\":100.0},{\"time\":\"1970-01-01 00:00:00.000000012Z\",\"value\":120.0}]" -
- INCLUDE_HEADER
-
include_header = 'true' , default: 'false'Al exportar los datos en formato CSV, este campo le permite incluir los nombres de las columnas como la primera fila de los archivos de datos CSV exportados.
Los valores aceptados son “verdadero” y “falso” y el valor predeterminado es “falso”. Las opciones de transformación de texto, como
escaped_byyfield_delimiter, se aplican también a los encabezados.nota
Al incluir encabezados, es importante no seleccionar un carácter de retorno (ASCII 13, hexadecimal 0D, texto “\r”) o un carácter de salto de línea (ASCII 10, hexadecimal 0A, texto “\n”) como
FIELD_DELIMITER, ya que esto impedirá que muchos analizadores puedan analizar correctamente los encabezados en la salida CSV resultante. - MAX_FILE_SIZE
-
max_file_size = 'X[MB|GB]' , default: '78GB'Este campo especifica el tamaño máximo de los archivos que la instrucción
UNLOADcrea en Amazon S3. La instrucciónUNLOADpuede crear varios archivos, pero el tamaño máximo de cada archivo escrito en Amazon S3 será aproximadamente el que se especifique en este campo.El valor debe estar comprendido entre 16 MB y 78 GB, ambos incluidos. Puede especificarlo en números enteros, como
12GB, o en decimales, como0.5GBo24.7MB. El valor predeterminado es 78 GB.El tamaño real del archivo es aproximado cuando se está escribiendo el archivo, por lo que es posible que el tamaño real máximo no sea exactamente igual al número que especifique.
