Para obtener capacidades similares a las de Amazon Timestream, considere Amazon Timestream LiveAnalytics para InfluxDB. Ofrece una ingesta de datos simplificada y tiempos de respuesta a las consultas en milisegundos de un solo dígito para realizar análisis en tiempo real. Obtenga más información aquí.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Agregados simples a nivel de flota
En este primer ejemplo, se explican algunos de los conceptos básicos al trabajar con consultas programadas. Para ello, se utiliza un ejemplo simple de cálculo de agregados a nivel de flota. Con este ejemplo, aprenderá lo siguiente.
-
Cómo tomar la consulta del panel que se utiliza para obtener estadísticas agregadas y asignarla a una consulta programada.
-
Cómo LiveAnalytics gestiona Timestream for la ejecución de las diferentes instancias de la consulta programada.
-
Cómo hacer que distintas instancias de consultas programadas se superpongan en intervalos de tiempo y cómo mantener la exactitud de los datos en la tabla de destino para garantizar que el panel, que utiliza los resultados de la consulta programada, le brinde los resultados que coincidan con el mismo agregado calculado a partir de los datos sin procesar.
-
Cómo configurar el intervalo de tiempo y la cadencia de actualización de la consulta programada.
-
Cómo puede realizar un seguimiento autónomo de los resultados de las consultas programadas para ajustarlas, de modo que la latencia de ejecución de las instancias de consulta se encuentre dentro de los retrasos aceptables para actualizar los paneles.
Temas
Agregados de las tablas de origen
En este ejemplo, realiza un seguimiento de la cantidad de métricas emitidas por los servidores de una región determinada en cada minuto. En el siguiente gráfico encontrará un ejemplo de la representación de esta serie temporal para la región us-east-1.
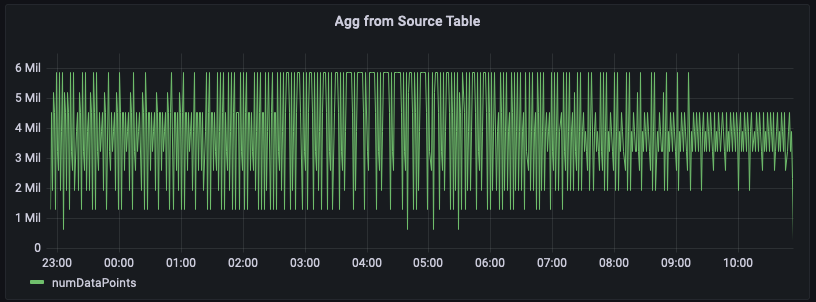
A continuación, se muestra un ejemplo de consulta para calcular este agregado a partir de los datos sin procesar. Filtra las filas de la región us-east-1 y, luego, calcula la suma por minuto teniendo en cuenta las 20 métricas (si measure_name es métrica) o 5 eventos (si measure_name es eventos). En este ejemplo, la ilustración gráfica muestra que la cantidad de métricas emitidas varía entre 1,5 y 6 millones por minuto. Al trazar esta serie temporal durante varias horas (las últimas 12 horas en esta figura), esta consulta sobre los datos sin procesar analiza cientos de millones de filas.
WITH grouped_data AS ( SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY region, measure_name, bin(time, 1m) ) SELECT minute, SUM(numDataPoints) AS numDataPoints FROM grouped_data GROUP BY minute ORDER BY 1 desc, 2 desc
Consulta programada para calcular de manera previa los agregados
Si quiere optimizar los paneles para que se carguen más rápido y reducir los costos escaneando menos datos, puede utilizar una consulta programada para calcular de manera previa estos agregados. Las consultas programadas en Timestream for LiveAnalytics le permiten materializar estos cálculos previos en otra LiveAnalytics tabla de Timestream for, que puede utilizar posteriormente para sus paneles.
El primer paso para crear una consulta programada consiste en identificar la consulta que quiere calcular previamente. Tenga en cuenta que el panel anterior se diseñó para la región us-east-1. Sin embargo, un usuario diferente puede querer el mismo agregado para una región distinta, por ejemplo us-west-2 o eu-west-1. Para evitar crear una consulta programada para cada una de estas consultas, puede calcular previamente el agregado de cada región y materializar los agregados por región en otra tabla de Timestream for. LiveAnalytics
En la siguiente consulta se brinda un ejemplo del cálculo previo correspondiente. Como se puede observar, es similar a la expresión de tabla habitual grouped_data que se utiliza en la consulta de los datos sin procesar, salvo por dos diferencias: 1) no utiliza un predicado de región, por lo que podemos utilizar una consulta para realizar el cálculo previo de todas las regiones; y 2) utiliza un predicado de tiempo parametrizado con un parámetro especial @scheduled_runtime, que se explica en detalle a continuación.
SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region
La consulta anterior puede convertirse en una consulta programada mediante la siguiente especificación. A la consulta programada se le asigna un nombre, que es una nemotecnia fácil de usar. A continuación, incluye la QueryString, a, que es una expresión ScheduleConfiguration cron. Especifica para TargetConfiguration qué se asignan los resultados de la consulta a la tabla de destino en Timestream. LiveAnalytics Por último, especifica otras configuraciones, como la siguiente: en la NotificationConfiguration que se envían notificaciones sobre las ejecuciones individuales de la consulta, ErrorReportConfiguration en la que se redacta un informe en caso de que la consulta detecte algún error y ScheduledQueryExecutionRoleArn, que es la función que se utiliza para realizar las operaciones de la consulta programada.
{ "Name": "MultiPT5mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/5 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt5m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
En el ejemplo, el ScheduleExpression cron (0/5 * * *? *) implica que la consulta se ejecuta una vez cada 5 minutos, los días 5, 10, 15,... minutos de cada hora de cada día. Estas marcas de tiempo en las que se activa una instancia específica de esta consulta son las que se traducen en el parámetro @scheduled_runtime que se utiliza en la consulta. Por ejemplo, considere la instancia de esta consulta programada que se ejecuta el 01-12-2021 00:00:00. Para esta instancia, el parámetro @scheduled_runtime se inicializa en la marca de tiempo 01-12-2021 00:00:00 al invocar la consulta. Por lo tanto, esta instancia específica se ejecutará en la marca de tiempo 01-12-2021 00:00:00 y calculará los agregados por minuto desde el intervalo de tiempo 30-11-2021 23:50:00 hasta 01-12-2021 00:01:00. Del mismo modo, la siguiente instancia de esta consulta se activa en la marca de tiempo 01-12-2021 00:05:00 y, en ese caso, la consulta calculará los agregados por minuto desde el intervalo de tiempo 30-11-2021 23:55:00 hasta 01-12-2021 00:06:00. Por lo tanto, el parámetro @scheduled_runtime ofrece una consulta programada para calcular previamente los agregados de los intervalos de tiempo configurados mediante el tiempo de invocación de las consultas.
Tenga en cuenta que dos instancias posteriores de la consulta se superponen en los intervalos de tiempo. Esto es algo que puede controlar según sus requisitos. En este caso, esta superposición permite que las consultas actualicen los agregados en función de cualquier dato que haya llegado con un ligero retraso (hasta 5 minutos en este ejemplo). Para garantizar la exactitud de las consultas materializadas, Timestream for se LiveAnalytics asegura de que la consulta del 01/12/2021 a las 00:05:00 solo se realice una vez finalizada la consulta del 01/12/2021 a las 00:00:00 horas. Además, los resultados de estas últimas consultas pueden actualizar cualquier agregado previamente materializado si se genera un valor más nuevo. Por ejemplo, si algunos datos de la marca de tiempo 30-11-2021 23:59:00 llegaron después de ejecutarse la consulta de 01-12-2021 00:00:00, pero antes de la consulta de 01-12-2021 00:05:00, la ejecución de 01-12-2021 00:05:00 volverá a calcular los agregados del minuto 30-11-2021 23:59:00 y esto hará que el agregado anterior se actualice con el valor recién calculado. Puede confiar en esta semántica de las consultas programadas para llegar a un equilibrio entre la rapidez con la que actualiza los cálculos previos y la forma en que puede gestionar de manera correcta algunos datos con retraso en la llegada. A continuación, se analizan otras consideraciones sobre cómo se compensa esta cadencia de actualización con la actualización de los datos y cómo se aborda la actualización de los agregados para los datos que llegan con más retraso o si la fuente del cálculo programado tiene valores actualizados que requerirían volver a calcular los agregados.
Cada cálculo programado tiene una configuración de notificaciones en la que Timestream for envía una notificación cada vez que se ejecuta una configuración programada. LiveAnalytics Puede configurar un tema de SNS para recibir las notificaciones de cada invocación. Además del estado correcto o fallido de una instancia específica, también tiene varias estadísticas, como el tiempo que tardó en ejecutarse el cálculo, la cantidad de bytes que escaneó el cálculo y la cantidad de bytes que el cálculo escribió en la tabla de destino. Puede usar estas estadísticas para ajustar mucho más la consulta, programar la configuración o realizar un seguimiento del gasto de las consultas programadas. Un aspecto que vale la pena destacar es el tiempo de ejecución de una instancia. En este ejemplo, se configura el cálculo programado para que se ejecute cada 5 minutos. El tiempo de ejecución determinará el retraso con el que estará disponible el cálculo previo, que también definirá el retraso en el panel cuando utilice los datos que se calcularon previamente en los paneles. Además, si este retraso es constantemente superior al intervalo de actualización, por ejemplo, si el tiempo de ejecución es superior a 5 minutos para un cálculo configurado para que se actualice cada 5 minutos, es importante ajustar el cálculo para que se ejecute más rápido a fin de evitar más retrasos en los paneles.
Agregar desde una tabla derivada
Ahora que ha configurado las consultas programadas y los agregados están precalculados y materializados en otra tabla de flujo temporal especificada en la configuración de destino del cálculo programado, puede utilizar los datos de esa LiveAnalytics tabla para escribir consultas SQL que potencien sus cuadros de mando. A continuación, se muestra un equivalente de la consulta que utiliza los agregados previamente materializados para generar el agregado del recuento de puntos de datos por minuto para us-east-1.
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY bin(time, 1m) ORDER BY 1 desc
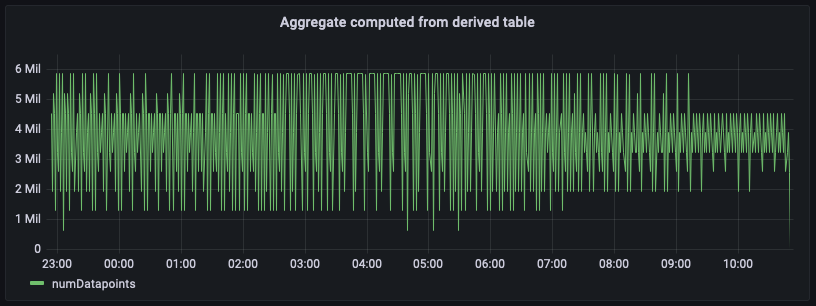
En la figura anterior se representa el agregado calculado a partir de la tabla de agregados. Al comparar este panel con el panel calculado a partir de los datos fuente sin procesar, observará que coinciden de manera exacta, aunque estos agregados se retrasan unos minutos debido al intervalo de actualización que configuró para el cálculo programado más el tiempo de ejecución.
Esta consulta sobre los datos calculados de manera previa escanea datos distintos órdenes de magnitud inferiores a los agregados calculados sobre los datos fuente sin procesar. En función de la granularidad de las agregaciones, esta reducción puede reducir fácilmente hasta 100 veces el costo y la latencia de las consultas. La ejecución de este cálculo programado implica un costo. Sin embargo, según la frecuencia con la que se actualicen estos paneles y de la cantidad de usuarios simultáneos que los carguen, se acabará reduciendo de manera considerable los costos totales si se utilizan estos cálculos previos. Además, los tiempos de carga de los paneles son entre 10 y 100 veces más rápidos.
Agregar la combinación de tablas de origen y derivadas
Los paneles creados con las tablas derivadas pueden tener un retraso. Si el escenario de su aplicación requiere que los paneles tengan los datos más recientes, puede utilizar la potencia y la flexibilidad del soporte SQL LiveAnalytics de Timestream for para combinar los datos más recientes de la tabla de origen con los agregados históricos de la tabla derivada para formar una vista combinada. Esta vista combinada utiliza la semántica de unión de SQL y los intervalos de tiempo que no se superponen entre la tabla de origen y la tabla derivada. En el siguiente ejemplo, utilizamos la tabla derivada "derived"."per_minute_aggs_pt5m". Dado que el cálculo programado para esa tabla derivada se actualiza una vez cada 5 minutos (según la especificación de la expresión de programación), la siguiente consulta utiliza los 15 minutos de datos más recientes de la tabla de origen y cualquier dato de más de 15 minutos de la tabla derivada y, luego, une los resultados para crear la vista combinada que tiene lo mejor de ambos mundos: la economía y la baja latencia mediante la lectura de los agregados calculados previamente más antiguos de la tabla derivada y la frescura de los agregados de la tabla de origen para potenciar los casos de uso de análisis en tiempo real.
Tenga en cuenta que este enfoque de unión tendrá una latencia de consulta un poco mayor en comparación con solo la consulta de la tabla derivada y también escaneará datos ligeramente más altos, ya que agrega los datos sin procesar en tiempo real para completar el intervalo de tiempo más reciente. Sin embargo, esta vista combinada seguirá siendo más rápida y económica de manera considerable en comparación con la agregación inmediata desde la tabla de origen, sobre todo en el caso de los paneles que representan días o semanas de datos. Puede ajustar los intervalos de tiempo de este ejemplo para adaptarlos a las necesidades de actualización y a la tolerancia al retraso de la aplicación.
WITH aggregated_source_data AS ( SELECT bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDatapoints FROM "raw_data"."devops" WHERE time BETWEEN bin(from_milliseconds(1636743196439), 1m) - 15m AND from_milliseconds(1636743196439) AND region = 'us-east-1' GROUP BY bin(time, 1m) ), aggregated_derived_data AS ( SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996439) AND bin(from_milliseconds(1636743196439), 1m) - 15m AND region = 'us-east-1' GROUP BY bin(time, 1m) ) SELECT minute, numDatapoints FROM ( ( SELECT * FROM aggregated_derived_data ) UNION ( SELECT * FROM aggregated_source_data ) ) ORDER BY 1 desc
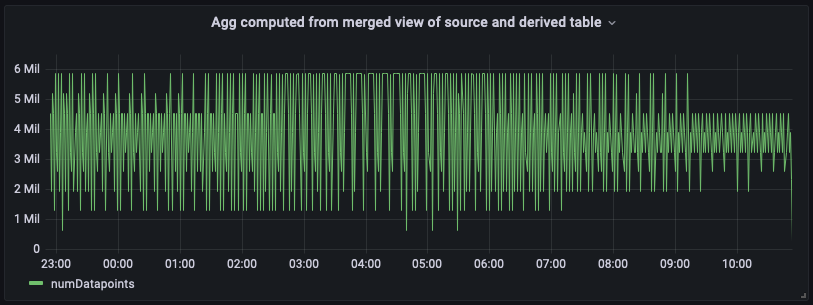
A continuación, se muestra el panel de control del panel con esta vista unificada y combinada. Como puede ver, el panel tiene un aspecto casi idéntico al de la vista calculada a partir de la tabla derivada, con la salvedad de que tendrá la mayor cantidad de up-to-date agregados en el extremo derecho.
Agregar desde los cálculos programados que se actualizan con frecuencia
Según la frecuencia con la que se carguen los paneles y cuánta latencia desee para el panel, existe otro método para obtener resultados más actualizados en el panel: hacer que el cálculo programado actualice los agregados con más frecuencia. Por ejemplo, a continuación se muestra la configuración del mismo cálculo programado, salvo que se actualiza una vez cada minuto (observe el horario rápido cron(0/1 * * * ? *)). Con esta configuración, la tabla derivada per_minute_aggs_pt1m tendrá agregados mucho más recientes en comparación con la situación en la que el cálculo especificaba un programa de actualización de una vez cada 5 minutos.
{ "Name": "MultiPT1mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/1 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt1m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt1m" WHERE time BETWEEN from_milliseconds(1636699996446) AND from_milliseconds(1636743196446) AND region = 'us-east-1' GROUP BY bin(time, 1m), region ORDER BY 1 desc
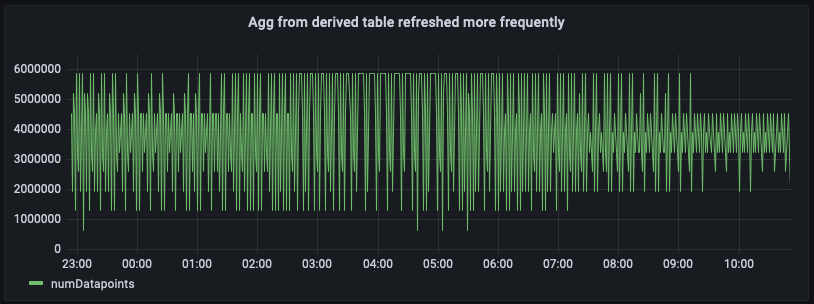
Como la tabla derivada tiene agregados más recientes, ahora puede consultarla directamente per_minute_aggs_pt1m para obtener agregados más actualizados, como puede verse en la consulta anterior y en la siguiente instantánea del panel.
Tenga en cuenta que actualizar el cálculo programado con un horario más rápido (por ejemplo, 1 minuto en vez de 5 minutos) aumentará los costos de mantenimiento del cálculo programado. En el mensaje de notificación de cada ejecución de un cálculo se ofrecen estadísticas sobre la cantidad de datos que se escanearon y la cantidad de datos que se escribieron en la tabla derivada. Del mismo modo, si utiliza la vista combinada para unir la tabla derivada, consulta los costos en la vista combinada y la latencia de carga del panel será mayor en comparación con solo consultar la tabla derivada. Por lo tanto, el enfoque que elija dependerá de la frecuencia con la que se actualicen los paneles y de los costos de mantenimiento de las consultas programadas. Si tiene decenas de usuarios que actualizan los paneles aproximadamente una vez cada minuto, actualizar la tabla derivada con más frecuencia probablemente permita una reducción general de los costos.
