Para obtener capacidades similares a las de Amazon Timestream, considere Amazon Timestream LiveAnalytics para InfluxDB. Ofrece una ingesta de datos simplificada y tiempos de respuesta a las consultas en milisegundos de un solo dígito para realizar análisis en tiempo real. Obtenga más información aquí.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso de consultas programadas y datos sin procesar para los desgloses
Puede utilizar las estadísticas agregadas de la flota para identificar las áreas que necesitan desglosarse y, luego, utilizar los datos sin procesar para desglosar datos granulares y obtener información más detallada.
En este ejemplo, se muestra cómo puede utilizar el panel agregado para identificar cualquier implementación (una implementación es para un microservicio determinado dentro de una región, celda, silo y zona de disponibilidad determinados) que parezca tener un mayor uso de la CPU en comparación con otras implementaciones. A continuación, puede desglosar para obtener una mejor comprensión mediante el uso de los datos sin procesar. Dado que estos desgloses pueden ser poco frecuentes y solo acceden a los datos pertinentes para la implementación, puede utilizar los datos sin procesar para este análisis y no es necesario utilizar consultas programadas.
Desglose por implementación
En el siguiente panel se ofrece un desglose sobre estadísticas más granulares y a nivel de servidor dentro de una implementación determinada. Para ayudarlo a desglosar las diferentes partes de la flota, este panel utiliza variables como región, celda, silo, microservicio y availability_zone. Luego, muestra algunas estadísticas agregadas para esa implementación.


En la consulta siguiente, puede ver que los valores elegidos en el menú desplegable de las variables se utilizan como predicados en la cláusula WHERE de la consulta, lo que le permite centrarse solo en los datos de la implementación. A continuación, el panel traza las métricas de CPU agregadas para las instancias de esa implementación. Puede utilizar los datos sin procesar para realizar este desglose con la latencia de consultas interactivas para obtener información más detallada.
SELECT bin(time, 5m) as minute, ROUND(AVG(cpu_user), 2) AS avg_value, ROUND(APPROX_PERCENTILE(cpu_user, 0.9), 2) AS p90_value, ROUND(APPROX_PERCENTILE(cpu_user, 0.95), 2) AS p95_value, ROUND(APPROX_PERCENTILE(cpu_user, 0.99), 2) AS p99_value FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099476) AND from_milliseconds(1636613499476) AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND microservice_name = 'demeter' AND availability_zone = 'eu-west-1-3' AND measure_name = 'metrics' GROUP BY bin(time, 5m) ORDER BY 1
Estadísticas de nivel de instancia
Este panel calcula además otra variable que también muestra las que utilizan mucho la CPU, servers/instances ordenadas en orden descendente de utilización. La consulta utilizada para calcular esta variable se encuentra a continuación.
WITH microservice_cell_avg AS ( SELECT AVG(cpu_user) AS microservice_avg_metric FROM "raw_data"."devops" WHERE $__timeFilter AND measure_name = 'metrics' AND region = '${region}' AND cell = '${cell}' AND silo = '${silo}' AND availability_zone = '${availability_zone}' AND microservice_name = '${microservice}' ), instance_avg AS ( SELECT instance_name, AVG(cpu_user) AS instance_avg_metric FROM "raw_data"."devops" WHERE $__timeFilter AND measure_name = 'metrics' AND region = '${region}' AND cell = '${cell}' AND silo = '${silo}' AND microservice_name = '${microservice}' AND availability_zone = '${availability_zone}' GROUP BY availability_zone, instance_name ) SELECT i.instance_name FROM instance_avg i CROSS JOIN microservice_cell_avg m WHERE i.instance_avg_metric > (1 + ${utilization_threshold}) * m.microservice_avg_metric ORDER BY i.instance_avg_metric DESC
En la consulta anterior, la variable se vuelve a calcular de manera dinámica en función de los valores elegidos para las demás variables. Una vez que se haya completado la variable para una implementación, puede seleccionar las instancias individuales de la lista para visualizar mejor las métricas de esa instancia. Puede seleccionar las distintas instancias en el menú desplegable de los nombres de las instancias, como se muestra en la siguiente instantánea.
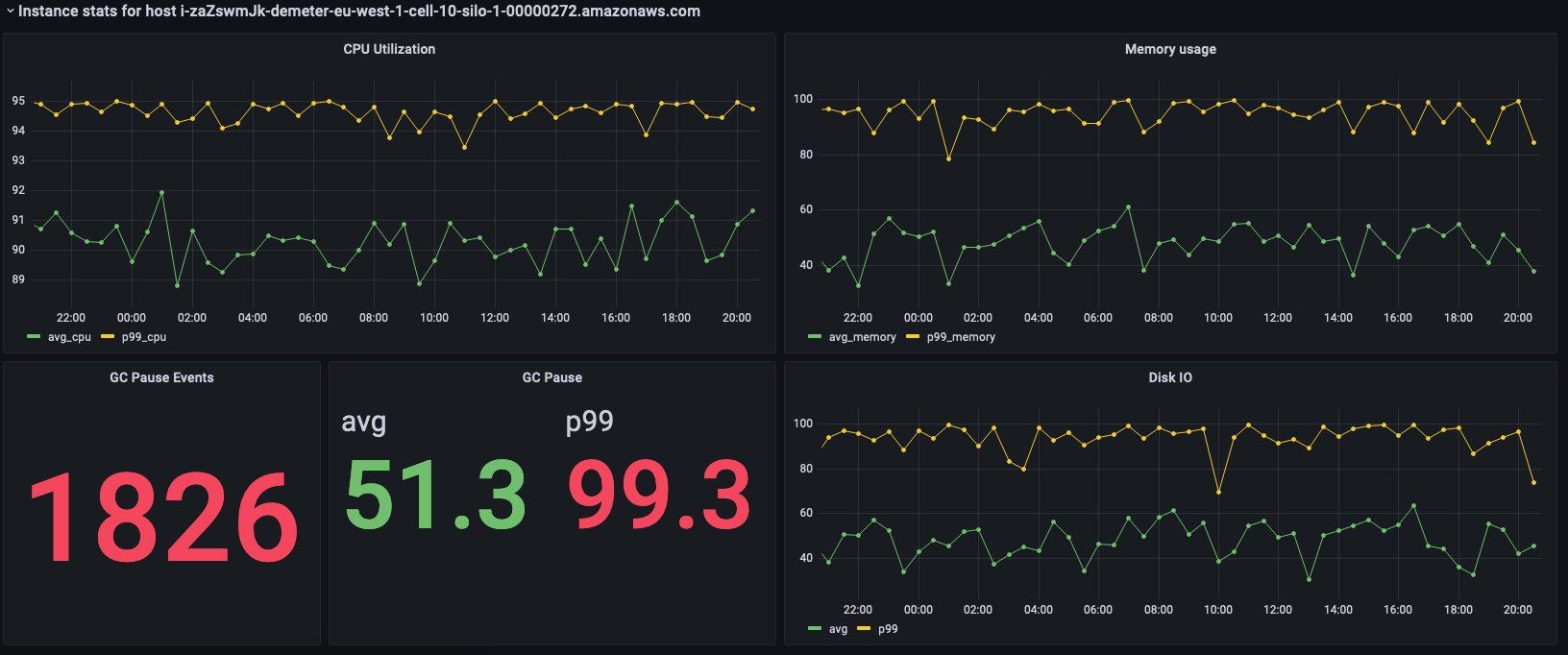
En los paneles anteriores se muestran las estadísticas de la instancia seleccionada y, luego, se muestran las consultas que se utilizan para obtener estas estadísticas.
SELECT BIN(time, 30m) AS time_bin, AVG(cpu_user) AS avg_cpu, ROUND(APPROX_PERCENTILE(cpu_user, 0.99), 2) as p99_cpu FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099477) AND from_milliseconds(1636613499477) AND measure_name = 'metrics' AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND availability_zone = 'eu-west-1-3' AND microservice_name = 'demeter' AND instance_name = 'i-zaZswmJk-demeter-eu-west-1-cell-10-silo-1-00000272.amazonaws.com' GROUP BY BIN(time, 30m) ORDER BY time_bin desc
SELECT BIN(time, 30m) AS time_bin, AVG(memory_used) AS avg_memory, ROUND(APPROX_PERCENTILE(memory_used, 0.99), 2) as p99_memory FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099477) AND from_milliseconds(1636613499477) AND measure_name = 'metrics' AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND availability_zone = 'eu-west-1-3' AND microservice_name = 'demeter' AND instance_name = 'i-zaZswmJk-demeter-eu-west-1-cell-10-silo-1-00000272.amazonaws.com' GROUP BY BIN(time, 30m) ORDER BY time_bin desc
SELECT COUNT(gc_pause) FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099477) AND from_milliseconds(1636613499478) AND measure_name = 'events' AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND availability_zone = 'eu-west-1-3' AND microservice_name = 'demeter' AND instance_name = 'i-zaZswmJk-demeter-eu-west-1-cell-10-silo-1-00000272.amazonaws.com'
SELECT avg(gc_pause) as avg, round(approx_percentile(gc_pause, 0.99), 2) as p99 FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099478) AND from_milliseconds(1636613499478) AND measure_name = 'events' AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND availability_zone = 'eu-west-1-3' AND microservice_name = 'demeter' AND instance_name = 'i-zaZswmJk-demeter-eu-west-1-cell-10-silo-1-00000272.amazonaws.com'
SELECT BIN(time, 30m) AS time_bin, AVG(disk_io_reads) AS avg, ROUND(APPROX_PERCENTILE(disk_io_reads, 0.99), 2) as p99 FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099478) AND from_milliseconds(1636613499478) AND measure_name = 'metrics' AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND availability_zone = 'eu-west-1-3' AND microservice_name = 'demeter' AND instance_name = 'i-zaZswmJk-demeter-eu-west-1-cell-10-silo-1-00000272.amazonaws.com' GROUP BY BIN(time, 30m) ORDER BY time_bin desc
