Para obtener capacidades similares a las de Amazon Timestream, considere Amazon Timestream LiveAnalytics para InfluxDB. Ofrece una ingesta de datos simplificada y tiempos de respuesta a las consultas en milisegundos de un solo dígito para realizar análisis en tiempo real. Obtenga más información aquí.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Arquitectura
Amazon Timestream para Live Analytics se ha diseñado desde cero para recopilar, almacenar y procesar datos de serie temporal a escala. Su arquitectura sin servidor admite sistemas de procesamiento de consultas, almacenamiento e ingesta de datos totalmente disociados que pueden escalarse de forma independiente. Este diseño simplifica cada subsistema, lo que facilita el logro de una fiabilidad inquebrantable, elimina los cuellos de botella de escalado y reduce las probabilidades de que se produzcan fallos correlacionados con el sistema. Cada uno de estos factores adquiere más importancia a medida que el sistema se amplía.
Temas
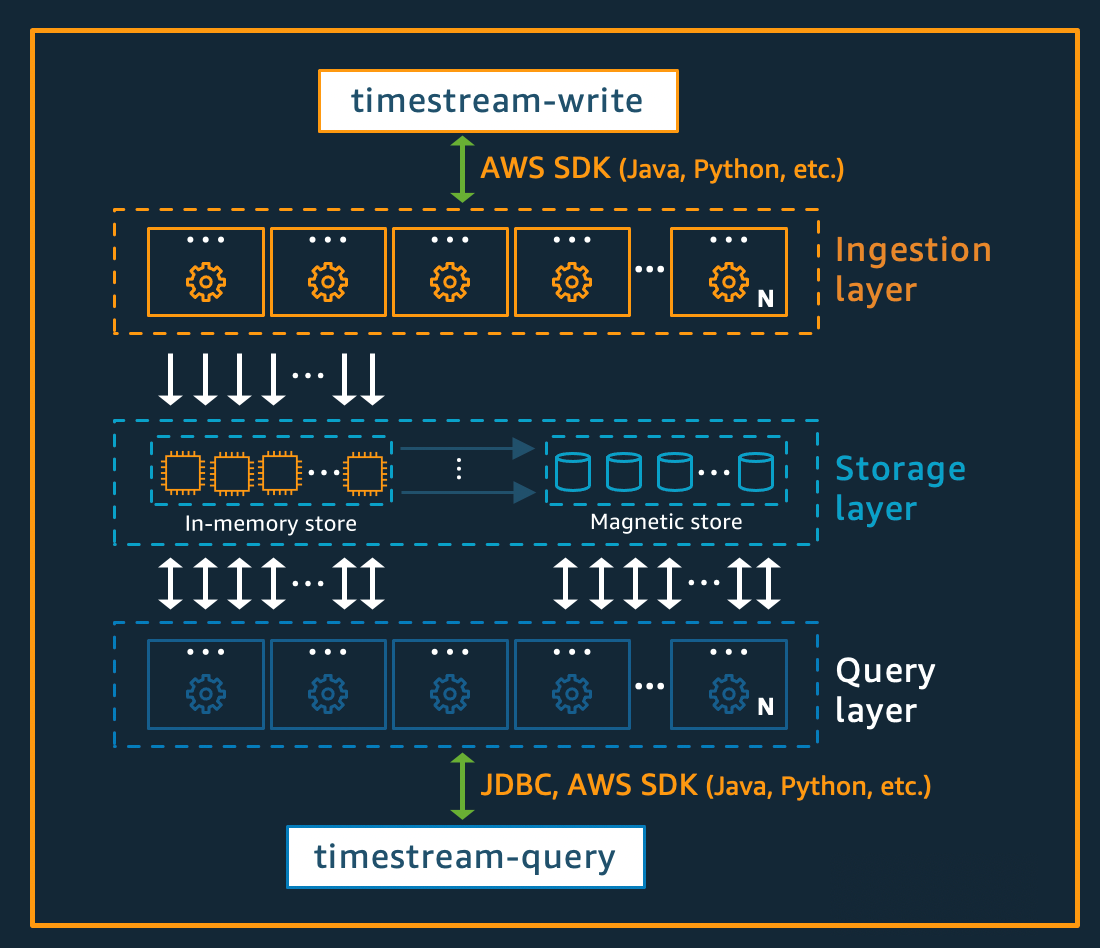
Arquitectura de escritura
Al escribir datos de serie temporal, Amazon Timestream para Live Analytics enruta las escrituras de una tabla o partición a una instancia de almacenamiento de memoria tolerante a errores que procesa escrituras de datos de alto rendimiento. El almacén de memoria, a su vez, logra una mayor durabilidad en un sistema de almacenamiento independiente que replica los datos en tres zonas de disponibilidad (). AZs La replicación se basa en el quórum, de modo que la pérdida de nodos, o de una zona de disponibilidad completa, no interrumpirá la disponibilidad de escritura. Casi en tiempo real, otros nodos de almacenamiento en memoria se sincronizan con los datos para atender las consultas. Los nodos de la réplica del lector AZs también se extienden para garantizar una alta disponibilidad de lectura.
Timestream para Live Analytics permite escribir datos directamente en el almacén magnético, para aplicaciones que generan datos de menor rendimiento y llegan tarde. Los datos de llegada tardía son datos con una marca de tiempo anterior a la hora actual. Al igual que ocurre con las escrituras de alto rendimiento en el almacén de memoria, los datos escritos en el almacén magnético se replican en tres AZs y la replicación se basa en el quórum.
Tanto si los datos se escriben en la memoria como en un almacén magnético, Timestream para Live Analytics indexa y divide de forma automática los datos antes de guardarlos en el almacenamiento. Una sola tabla de Timestream para Live Analytics puede tener cientos, miles o incluso millones de particiones. Las particiones individuales no se comunican directamente entre sí y no comparten ningún dato (arquitectura que no comparte nada). En su lugar, el seguimiento de la partición de una tabla se realiza mediante un servicio de indexación y seguimiento de particiones de alta disponibilidad. Esto proporciona otra separación de problemas diseñada específicamente para minimizar el efecto de las fallas en el sistema y reducir la probabilidad de que se produzcan fallas correlacionadas.
Arquitectura del almacenamiento
Cuando los datos se almacenan en Timestream para Live Analytics, los datos se organizan en orden temporal y temporal en función de los atributos de contexto escritos con los datos. Disponer de un esquema de particiones que divida el “espacio” del tiempo es importante para escalar masivamente un sistema de series temporales. Esto se debe a que la mayoría de los datos de serie temporal se escriben en la hora actual o en torno a ella. En consecuencia, la partición basada únicamente en el tiempo no distribuye bien el tráfico de escritura ni permite reducir de forma eficaz los datos en el momento de la consulta. Esto es importante para el procesamiento de series temporales a escala extrema, y ha permitido a Timestream para Live Analytics escalar órdenes de magnitud más que los demás sistemas líderes que existen hoy en día sin servidores. Las particiones resultantes se denominan “teselas” porque representan divisiones de un espacio bidimensional (que están diseñadas para tener un tamaño similar). Las tablas Timestream para Live Analytics comienzan como una partición única (mosaico) y, después, se dividen en la dimensión espacial según lo requiera el rendimiento. Cuando los mosaicos alcanzan un tamaño determinado, se dividen en la dimensión temporal para lograr un mejor paralelismo de lectura a medida que aumenta el tamaño de los datos.
Timestream para Live Analytics está diseñado para gestionar automáticamente el ciclo de vida de los datos de serie temporal. Timestream para Live Analytics ofrece dos almacenes de datos: un almacén en memoria y un almacén magnético rentable. También permite configurar políticas a nivel de tabla para transferir de forma automática los datos entre las tiendas. Las escrituras de datos entrantes de alto rendimiento aterrizan en el almacén de memoria, donde los datos se optimizan para la escritura, así como las lecturas que se realizan en torno a la hora actual, lo que facilita las consultas de tipo panel y alerta. Una vez transcurrido el plazo principal para escribir, enviar alertas y crear cuadros de mando, se permite que los datos fluyan de forma automática del almacén de memoria al almacén magnético para optimizar los costos. Timestream para Live Analytics permite establecer una política de retención de datos en el almacén de memoria con este fin. Las escrituras de datos para los datos que llegan tarde se escriben directamente en el almacén magnético.
Una vez que los datos están disponibles en el almacén magnético (debido a la expiración del período de retención del almacenamiento de memoria o debido a la escritura directa en el almacenamiento magnético), se reorganizan en un formato altamente optimizado para lecturas de grandes volúmenes de datos. El almacén magnético también tiene una política de retención de datos que se puede configurar si hay un límite de tiempo en el que los datos dejan de ser útiles. Cuando los datos superan el intervalo de tiempo definido para la política de retención del almacén magnético, se eliminan de forma automática. Por lo tanto, con Timestream para Live Analytics, salvo alguna configuración, la administración del ciclo de vida de los datos se lleva a cabo sin problemas entre bastidores.
Arquitectura de la consulta
Las consultas de Timestream para Live Analytics se expresan en una gramática SQL que incluye extensiones para admitir series temporales específicas (funciones y tipos de datos específicos de series temporales), por lo que la curva de aprendizaje resulta sencilla para los desarrolladores que ya estén familiarizados con SQL. A continuación, las consultas se procesan mediante un motor de consultas distribuido y adaptativo que utiliza los metadatos del servicio de seguimiento e indexación de teselas para acceder sin problemas a los datos de los distintos almacenes de datos y combinarlos sin problemas en el momento de emitir la consulta. Esto hace que la experiencia resulte atractiva para los clientes, ya que reduce muchas de las complejidades de Rube Goldberg en una simple y familiar abstracción de bases de datos.
Las consultas son ejecutadas por una flota de procesos de trabajo especializada, en la que el número de procesos de trabajo utilizados para ejecutar una consulta determinada está determinado por la complejidad de la consulta y el tamaño de los datos. El rendimiento de las consultas complejas en conjuntos de datos de gran tamaño se logra mediante un paralelismo masivo, tanto en la flota de tiempo de ejecución de las consultas como en las flotas de almacenamiento del sistema. La capacidad de analizar grandes cantidades de datos de forma rápida y eficiente es uno de los puntos fuertes de Timestream para Live Analytics. Una sola consulta que abarque terabytes o incluso petabytes de datos puede tener miles de máquinas trabajando en ella al mismo tiempo.
Arquitectura móvil
Para garantizar que Timestream para Live Analytics pueda ofrecer una escala prácticamente infinita para sus aplicaciones y, al mismo tiempo, garantizar una disponibilidad del 99,99 %, el sistema también está diseñado con una arquitectura celular. En lugar de escalar el sistema como un todo, Timestream para Live Analytics se segmenta en varias copias más pequeñas de sí mismo, denominadas celdas. Esto permite analizar las células a gran escala y evita que un problema del sistema en una célula afecte a la actividad de cualquier otra célula de una región determinada. Si bien Timestream para Live Analytics está diseñado para admitir varias celdas por región, considere el siguiente escenario ficticio, en el que hay dos celdas en una región.
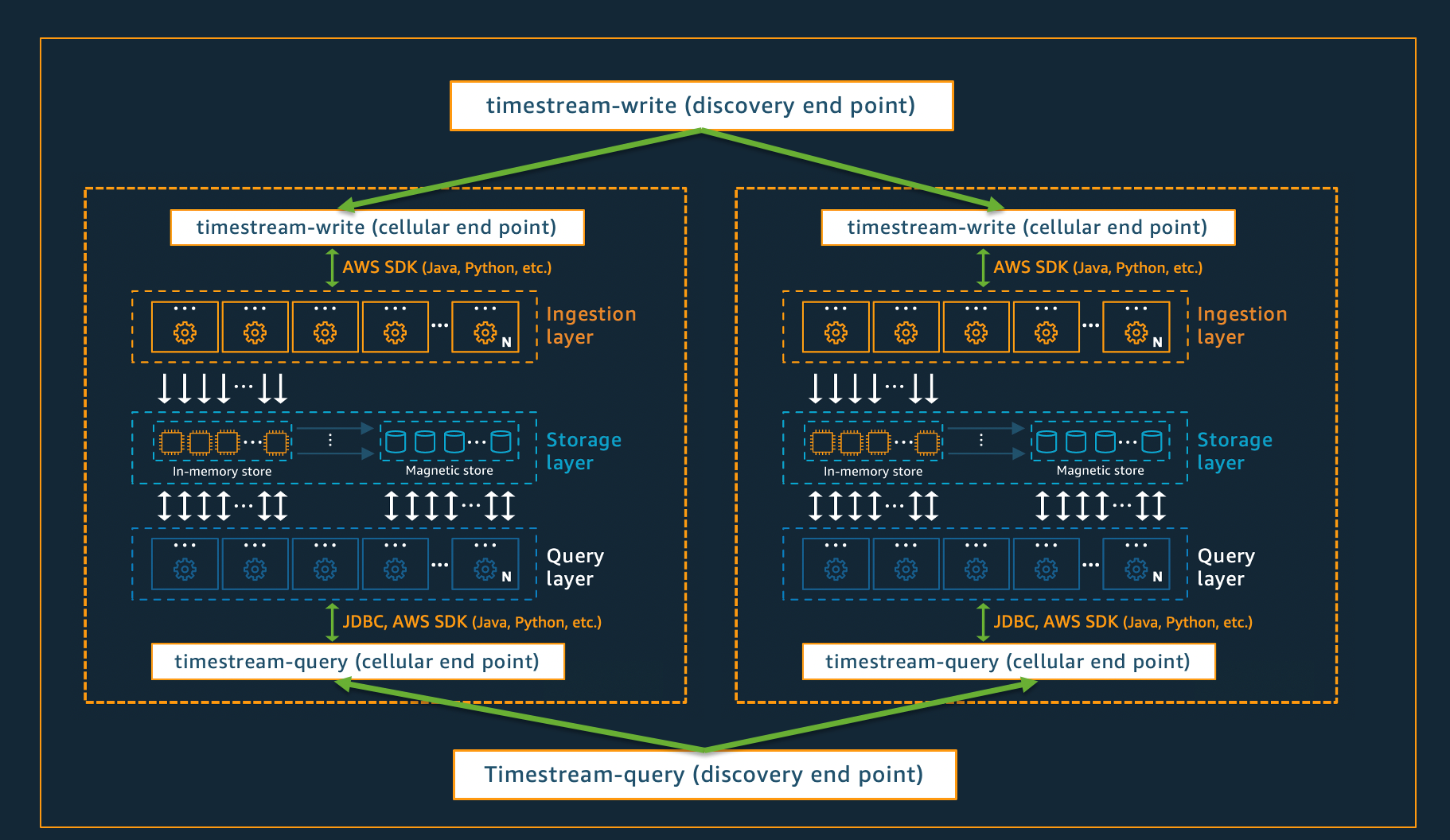
En la situación descrita anteriormente, las solicitudes de ingesta y consulta de datos son procesadas primero por el punto de conexión de detección para la ingesta y consulta de datos, respectivamente. A continuación, el punto de conexión de detección identifica la celda que contiene los datos del cliente y dirige la solicitud al punto final de recepción o consulta correspondiente a esa celda. Cuando se utiliza SDKs, estas tareas de administración de terminales se gestionan de forma transparente para usted.
nota
Cuando utilice puntos de conexión de VPC con Timestream para Live Analytics o acceda directamente a las operaciones de la API de REST para Timestream para Live Analytics, tendrá que interactuar directamente con los puntos de conexión móviles. Para obtener instrucciones sobre cómo hacerlo, consulte los puntos de conexión de la VPC para obtener instrucciones sobre cómo configurar los puntos de conexión de la VPC y el patrón de detección de puntos de conexión para obtener instrucciones sobre la invocación directa de las operaciones de la API de REST.
