Introducción
La seguridad es la máxima prioridad en AWS. Los clientes de AWS se beneficiarán de una arquitectura de red y de centros de datos diseñados para satisfacer las necesidades de seguridad de las organizaciones más exigentes en materia de seguridad. AWS tiene un modelo de responsabilidad compartida: AWS gestiona la seguridad de la nube y los clientes son responsables de la seguridad en la nube. Esto significa que usted tiene el control total de su implementación de seguridad, incluido el acceso a varias herramientas y servicios que lo ayudarán a cumplir sus objetivos de seguridad. Estas capacidades lo ayudan a establecer una línea de base de seguridad para las aplicaciones que se ejecutan en la Nube de AWS.
Si se produce una desviación de la línea de base (por ejemplo, debido a un error de configuración o a un cambio de factores externos), tendrá que responder a ella e investigarla. Para hacerlo correctamente, debe comprender los conceptos básicos de la respuesta ante incidentes de seguridad en su entorno de AWS y los requisitos para preparar, formar y capacitar a los equipos de trabajo en la nube antes de que se produzcan problemas de seguridad. Es importante saber qué controles y capacidades puede utilizar, revisar ejemplos temáticos para resolver posibles problemas e identificar métodos de remediación que utilicen la automatización a fin de mejorar la velocidad y la coherencia de la respuesta. Además, debe comprender sus requisitos normativos y de cumplimiento en lo que respecta a la creación de un programa de respuesta ante incidentes de seguridad que cumpla con esos requisitos.
La respuesta ante incidentes de seguridad puede ser compleja, por lo que le recomendamos que adopte un enfoque iterativo: comience con los servicios de seguridad básicos, desarrolle las capacidades fundamentales de detección y respuesta y, a continuación, desarrolle manuales de estrategias para crear una biblioteca inicial de mecanismos de respuesta ante incidentes sobre los que pueda iterar y mejorar.
Antes de empezar
Antes de empezar a aprender sobre la respuesta ante incidentes de seguridad en AWS, familiarícese con los estándares y marcos pertinentes de seguridad y respuesta ante incidentes de AWS. Estos aspectos fundamentales lo ayudarán a comprender los conceptos y las prácticas recomendadas que se presentan en esta guía.
Estándares y marcos de seguridad de AWS
Para empezar, le recomendamos que consulte Prácticas recomendadas para la seguridad, la identidad y el cumplimiento, pilar de seguridad: AWS Well-Architected Framework
AWS CAF proporciona una guía que apoya la coordinación entre las diferentes partes de las organizaciones que migran a la nube. La guía de AWS CAF se divide en varias áreas de enfoque (denominadas perspectivas) que son importantes para la creación de sistemas de TI basados en la nube. La perspectiva de seguridad describe cómo implementar un programa de seguridad en todos los flujos de trabajo, uno de los cuales es la respuesta ante incidentes. Este documento es el resultado de nuestra experiencia trabajando con clientes para ayudarlos a crear programas y capacidades de respuesta ante incidentes de seguridad eficaces y eficientes.
Estándares y marcos de respuesta ante incidentes del sector
Este documento técnico sigue los estándares de respuesta ante incidentes y las prácticas recomendadas de la guía Computer Security Incident Handling Guide SP 800-61 r3
Información general sobre la respuesta ante incidentes de AWS
Para empezar, es importante entender en qué se diferencian las operaciones de seguridad y la respuesta ante incidentes en la nube. Para desarrollar capacidades de respuesta que sean eficaces en AWS, deberá comprender las diferencias con respecto a la respuesta tradicional ante incidentes en las instalaciones y su impacto en su programa de respuesta ante incidentes. En esta sección se detallan cada una de estas diferencias y los principios básicos del diseño de la respuesta ante incidentes de AWS.
Aspectos de la respuesta ante incidentes de AWS
Todos los usuarios de AWS de una organización deben tener un conocimiento básico de los procesos de respuesta ante incidentes de seguridad; de igual manera, el personal de seguridad debe entender cómo responder a los problemas de seguridad. La educación, la capacitación y la experiencia son fundamentales para el éxito de un programa de respuesta ante incidentes en la nube y, en un escenario ideal, deben implementarse mucho antes de tener que gestionar un posible incidente de seguridad. La base de un programa de respuesta antes incidentes exitoso en la nube es la preparación, las operaciones y la actividad posterior al incidente.
A continuación se describe cada uno de estos aspectos para que los entienda mejor:
-
Preparación: prepare a su equipo de respuesta ante incidentes para que detecte y responda a los incidentes internos de AWS mediante la habilitación de controles de detección y la comprobación de que tengan el acceso adecuado a las herramientas y los servicios en la nube necesarios. Asimismo, prepare las guías de estrategias necesarias, tanto manuales como automatizadas, para comprobar respuestas fiables y coherentes.
-
Operaciones: opere en caso de eventos de seguridad y posibles incidentes según las fases de respuesta ante incidentes del NIST (detección, análisis, contención, erradicación y recuperación).
-
Actividad posterior al incidente: repita el resultado de sus eventos y simulaciones de seguridad para mejorar la eficacia de su respuesta, aumentar el valor derivado de la respuesta y la investigación y reducir aún más el riesgo. Hay que aprender de los incidentes y ser plenamente responsable de las actividades de mejora.
En esta guía se explora y se detalla cada uno de estos aspectos. En el siguiente diagrama se muestra el flujo de estos aspectos y se alinea con el ciclo de vida de respuesta ante incidentes del NIST mencionado anteriormente, pero con operaciones que abarcan detección y análisis con contención, erradicación y recuperación.
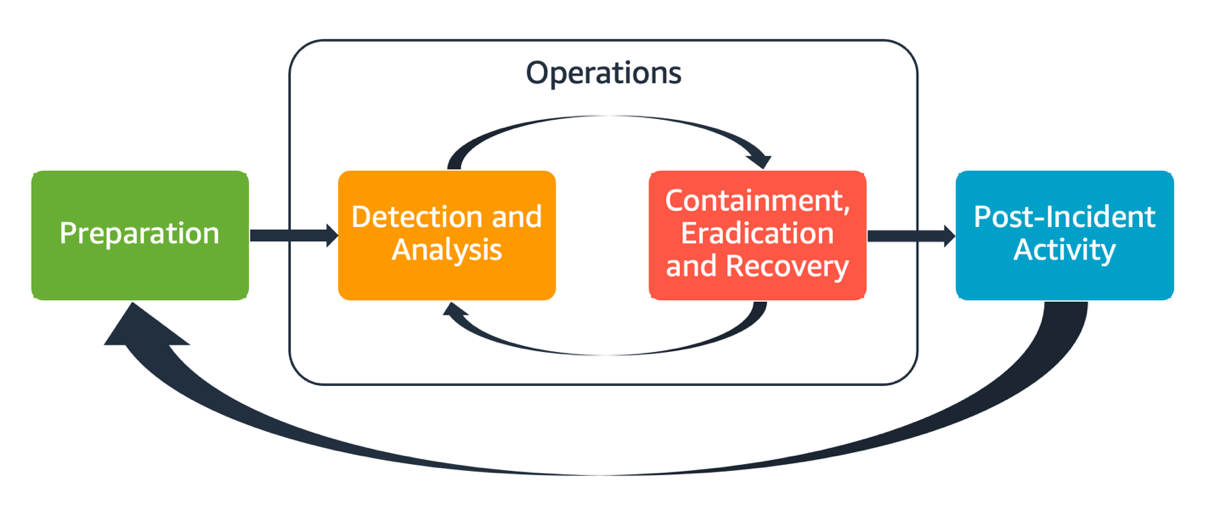
Aspectos de la respuesta ante incidentes de AWS
Principios de respuesta ante incidentes y objetivos de diseño de AWS
Si bien los procesos y mecanismos generales de respuesta ante incidentes, como los definidos en la guía SP 800-61 Computer Security Incident Handling Guide
-
Establecimiento de objetivos de repuesta: trabaje con las partes interesadas, el consejo legal y el equipo directivo de la organización para determinar el objetivo de respuesta ante un incidente. Algunos objetivos habituales incluyen la contención y mitigación del problema, la recuperación de los recursos afectados, la conservación de los datos para el análisis forense, el retorno a las operaciones seguras conocidas y, en última instancia, el aprendizaje de los incidentes.
-
Respuesta a través de la nube: implemente los patrones de respuesta en la nube, donde tiene lugar el evento y se generan los datos.
-
Conocimientos sobre lo que tiene y lo que necesita: preserve los registros, los recursos, las instantáneas y otras pruebas. Cópielos y almacénelos en una cuenta en la nube centralizada dedicada a la respuesta. Utilice etiquetas, metadatos y mecanismos que cumplan las políticas de retención. Deberá comprender qué servicios utiliza y, a continuación, identificar los requisitos para la investigación de dichos servicios. Para ayudarlo a comprender mejor su entorno, también puede utilizar el etiquetado, que se trata más adelante en este documento en la sección Desarrollo e implementación de una estrategia de etiquetado.
-
Uso de mecanismos de repetición de la implementación: si se puede atribuir una anomalía de seguridad a una configuración errónea, la solución podría ser tan sencilla como eliminar la varianza mediante la repetición de la implementación de los recursos con la configuración adecuada. En caso de que se identificara un posible compromiso, compruebe que la repetición de la implementación incluya una mitigación correcta y verificada de las causas raíz.
-
Automatización siempre que sea posible: a medida que surjan problemas o se repitan los incidentes, cree mecanismos para clasificar y responder a eventos habituales mediante programación. Utilice respuestas humanas para incidentes únicos, complejos o delicados en los que las automatizaciones sean insuficientes.
-
Uso de soluciones escalables: esfuércese por igualar la escalabilidad del enfoque de su organización con respecto a la computación en la nube. Implemente mecanismos de detección y respuesta que se escalen en todos sus entornos para reducir eficazmente el tiempo entre la detección y la respuesta.
-
Mejora y aprendizaje del proceso: sea proactivo a la hora de identificar las carencias en sus procesos, herramientas o personas e implemente un plan para solucionarlas. Las simulaciones son métodos seguros para detectar carencias y mejorar los procesos. Consulte la sección Actividad posterior al incidente de este documento para obtener información detallada sobre cómo iterar en sus procesos.
Estos objetivos de diseño son un recordatorio para revisar la implementación de su arquitectura y determinar la capacidad de llevar a cabo tanto la respuesta a los incidentes como la detección de amenazas. Cuando planifique sus implementaciones en la nube, piense en responder a un incidente y lo ideal es que sea con una metodología de respuesta sólida desde el punto de vista forense. En algunos casos, esto significa que podría tener varias organizaciones, cuentas y herramientas configuradas específicamente para estas tareas de respuesta. Estas herramientas y funciones deben ponerse a disposición del personal de respuesta ante incidentes mediante una canalización de implementación. No deben ser estáticas porque pueden causar un riesgo mayor.
Dominios de incidentes de seguridad en la nube
Para prepararse y responder eficazmente a los eventos de seguridad en su entorno de AWS, debe comprender los tipos más comunes de incidentes de seguridad en la nube. Hay tres ámbitos de responsabilidad del cliente en los que pueden producirse incidentes de seguridad: el servicio, la infraestructura y la aplicación. Los diferentes dominios requieren diferentes conocimientos, herramientas y procesos de respuesta. Considere estos dominios:
-
Dominio de servicio: los incidentes en el dominio de servicio pueden afectar a su Cuenta de AWS, a los permisos de AWS Identity and Access Management
(IAM), a los metadatos de los recursos, a la facturación o a otras áreas. Un evento del dominio de servicio es aquel al que responde exclusivamente con mecanismos de API de AWS o en el que las causas principales están asociadas a la configuración o a los permisos de los recursos y que pueden tener un registro relacionado orientado al servicio. -
Dominio de infraestructura: los incidentes en el dominio de infraestructura son actividades relacionadas con la red o los datos, como los procesos y los datos de sus instancias de Amazon Elastic Compute Cloud
(Amazon EC2), el tráfico a sus instancias de Amazon EC2 dentro de la nube privada virtual (VPC) y otras áreas, como contenedores u otros servicios futuros. Su respuesta a los eventos del dominio de infraestructura suele implicar la adquisición de datos relacionados con los incidentes para su análisis forense. Es probable que implique la interacción con el sistema operativo de una instancia y, en varios casos, también pueda implicar mecanismos de API de AWS. En el dominio de infraestructura, puede utilizar una combinación de API y herramientas de análisis forense digital o respuesta a incidentes (DFIR) de AWS en un sistema operativo huésped, como una instancia de Amazon EC2 dedicada a realizar análisis e investigaciones forenses. Los incidentes en el dominio de infraestructura pueden implicar el análisis de capturas de paquetes de red, bloques de discos en un volumen de Amazon Elastic Block Store (Amazon EBS) o memoria volátil adquirida de una instancia. -
Dominio de aplicación: los incidentes en el dominio de aplicación se producen en el código de la aplicación o en el software implementado en los servicios o la infraestructura. Este dominio debería incluirse en sus manuales de estrategias de detección y respuesta a las amenazas en la nube y podría incorporar respuestas similares a las del dominio de infraestructura. Con una arquitectura de aplicaciones adecuada y bien pensada, puede administrar este dominio con herramientas en la nube mediante la adquisición, la recuperación y la implementación automatizadas.
En estos dominios, considere los actores que podrían actuar en contra de las cuentas, los recursos o los datos de AWS. Utilice un marco de riesgos, ya sea interno o externo, para determinar los riesgos específicos para la organización y prepárese en consecuencia. Además, debe desarrollar modelos de amenazas que lo ayuden a planificar la respuesta ante incidentes y a desarrollar una arquitectura cuidadosa.
Principales diferencias de la respuesta ante incidentes en AWS
La respuesta ante incidentes es una parte integral de una estrategia de ciberseguridad, ya sea en las instalaciones o en la nube. Los principios de seguridad, como el privilegio mínimo y la defensa en profundidad, tienen por objeto proteger la confidencialidad, la integridad y la disponibilidad de los datos tanto en las instalaciones como en la nube. Varios patrones de respuesta ante incidentes que respaldan estos principios de seguridad siguen la misma línea, como la retención de registros, la selección de alertas derivadas del modelado de amenazas, el desarrollo de manuales de estrategias y la integración de la administración de información y eventos de seguridad (SIEM). Las diferencias comienzan cuando los clientes empiezan a diseñar e implementar estos patrones en la nube. Las siguientes son las principales diferencias de la respuesta ante incidentes en AWS.
Diferencia n.º 1: la seguridad como responsabilidad compartida
Los asuntos relacionados con la seguridad y el cumplimiento son una responsabilidad compartida entre AWS y sus clientes. Este modelo de responsabilidad compartida alivia la carga operativa del cliente, ya que AWS opera, administra y controla los componentes del sistema operativo host y la capa de virtualización con el fin de ofrecer seguridad física en las instalaciones en las que operan los servicios. Para obtener más información sobre el modelo de responsabilidad compartida, consulte la documentación del Modelo de responsabilidad compartida
A medida que cambia su responsabilidad compartida en la nube, también cambian sus opciones de respuesta ante incidentes. Planificar y comprender estas diferencias y adaptarlas a sus necesidades de gobernanza es un paso crucial en la respuesta ante incidentes.
Además de la relación directa que tiene con AWS, es posible que haya otras entidades que tengan responsabilidades en su modelo de responsabilidad particular. Por ejemplo, es posible que tenga unidades organizativas internas que asuman la responsabilidad de algunos aspectos de sus operaciones. Es posible que también tenga relaciones con otras partes que desarrollen, administren u operen parte de su tecnología en la nube.
Es de suma importancia crear y probar un plan de respuesta ante incidentes y los manuales adecuados que se adapten a su modelo operativo.
Diferencia n.º 2: dominio de servicio en la nube
Debido a las diferencias en la responsabilidad de seguridad que existen en los servicios en la nube, se introdujo un nuevo dominio para los incidentes de seguridad: el dominio de servicio, que se explicó anteriormente en la sección Dominio de incidentes. El dominio de servicio abarca la cuenta de AWS del cliente, los permisos de IAM, los metadatos de los recursos, la facturación y otras áreas. Este dominio es diferente para la respuesta ante incidentes debido a la forma en que se responde. La respuesta dentro del dominio de servicio suele realizarse mediante la revisión y emisión de llamadas a la API, en lugar de la respuesta tradicional basada en el host y la red. En el dominio de servicio, no interactuará con el sistema operativo de un recurso afectado.
En el siguiente diagrama se muestra un ejemplo de un evento de seguridad en el dominio de servicio basado en un antipatrón de arquitectura. En este evento, un usuario no autorizado obtiene las credenciales de seguridad de larga duración de un usuario de IAM. El usuario de IAM tiene una política de IAM que le permite recuperar objetos de un bucket de Amazon Simple Storage Service
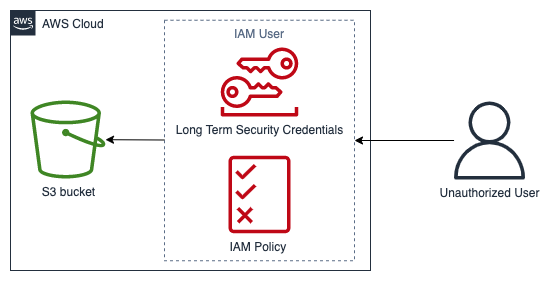
Ejemplo de dominio de servicio
Diferencia n.º 3: API para el aprovisionamiento de la infraestructura
Otra diferencia proviene de la característica de la nube del autoservicio bajo demanda
Debido a la naturaleza basada en API de AWS, AWS CloudTrail es un origen de registro importante para responder a los eventos de seguridad. Permite hacer un seguimiento de las llamadas a la API de administración que se realizan en sus cuentas de AWS y puede encontrar información sobre la ubicación de origen de las llamadas a la API.
Diferencia n.º 4: la naturaleza dinámica de la nube
La nube es dinámica; le permite crear y eliminar recursos rápidamente. Con el escalado automático, los recursos se pueden aumentar y reducir en función del aumento del tráfico. Con una infraestructura de corta duración y cambios rápidos, es posible que un recurso que esté investigando ya no exista o se haya modificado. Para analizar los incidentes, será importante comprender la naturaleza efímera de los recursos de AWS y saber cómo realizar un seguimiento de la creación y eliminación de los recursos de AWS. Puede utilizar AWS Config
Diferencia n.º 5: acceso a los datos
El acceso a los datos también es diferente en la nube. No puede conectarse a un servidor para recopilar los datos que necesita para una investigación de seguridad. Los datos se recopilan a través de la red y mediante llamadas a la API. Deberá practicar y comprender cómo realizar la recopilación de datos a través de las API a fin de prepararse para este cambio y verificar el almacenamiento adecuado para una recopilación y un acceso eficaces.
Diferencia n.º 6: importancia de la automatización
Para que los clientes se beneficien plenamente de la adopción de la nube, su estrategia operativa debe tener en cuenta la automatización. La infraestructura como código (IaC) es un patrón de entornos automatizados altamente eficientes en el que los servicios de AWS se implementan, configuran, reconfiguran y destruyen mediante código facilitado por servicios de IaC nativos, como AWS CloudFormation
Gestión de estas diferencias
Para gestionar estas diferencias, siga los pasos que se describen en la siguiente sección y compruebe que su programa de respuesta ante incidentes, tanto en lo que respecta a las personas como a los procesos y la tecnología, esté bien preparado.
