Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Explora los datos de salida del perfil visualizados en la interfaz de usuario de Profiler SageMaker
En esta sección, se explica la interfaz de usuario del SageMaker generador de perfiles y se proporcionan consejos sobre cómo utilizarla y obtener información al respecto.
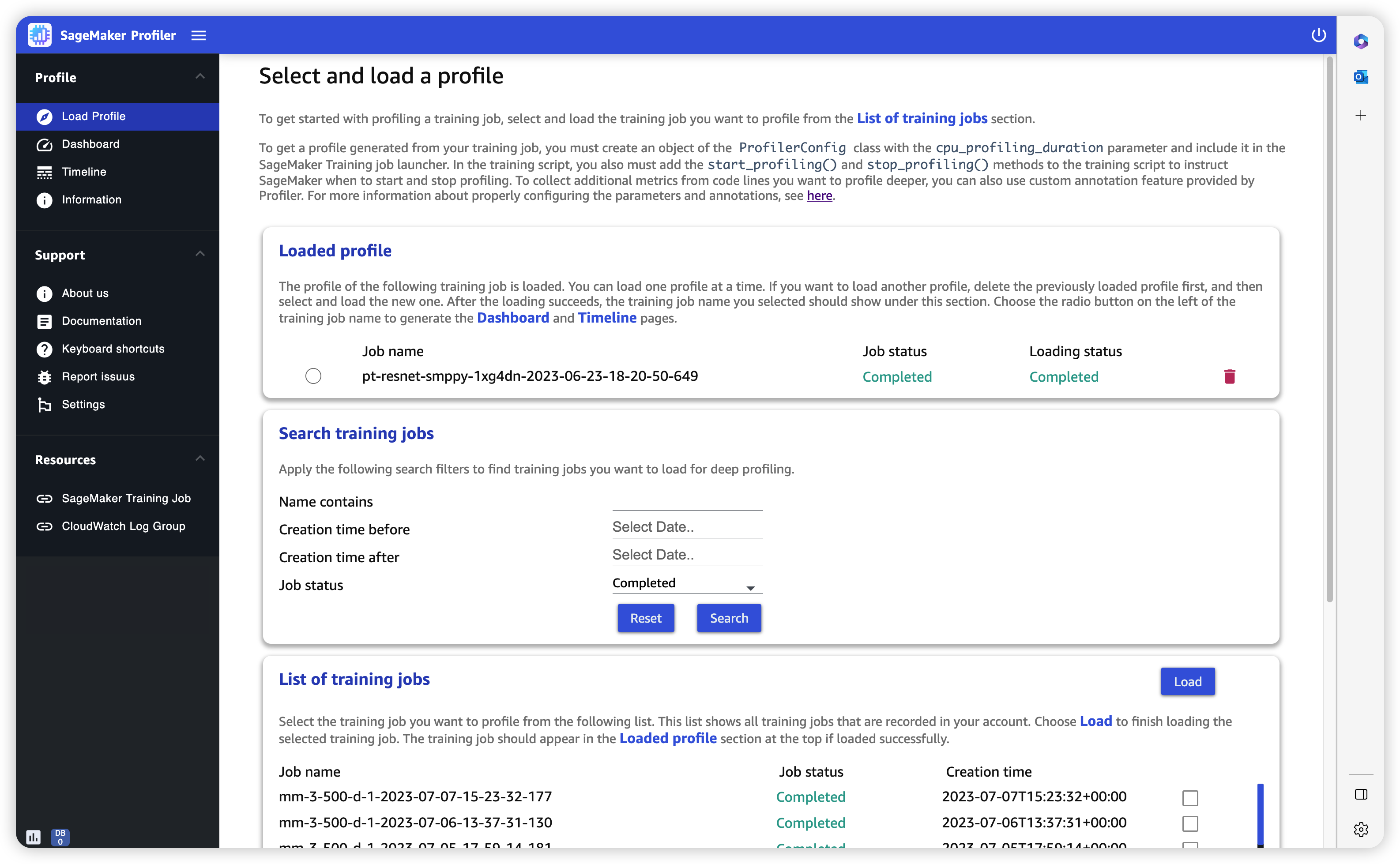
Cargar perfil
Al abrir la interfaz de usuario del SageMaker generador de perfiles, se abre la página Cargar perfil. Para cargar y generar Dashboard (Panel de control) y Timeline (Línea temporal), siga el siguiente procedimiento.
Para cargar el perfil de un trabajo de entrenamiento
-
En la sección List of training jobs (Lista de trabajos de entrenamiento), utilice la casilla de verificación para elegir el trabajo de entrenamiento para el que desea cargar el perfil.
-
Elija Load (Cargar). El nombre del trabajo debe aparecer en la sección Loaded profile (Perfil cargado), en la parte superior.
-
Pulse el botón de radio situado a la izquierda de Job name (Nombre del trabajo) para generar el Dashboard (Panel de control) y Timeline (Línea temporal). Tenga en cuenta que cuando selecciona el botón de opción, la interfaz de usuario abre automáticamente Dashboard (Panel de control). Tenga en cuenta también que si genera las visualizaciones mientras el estado del trabajo y el estado de carga aún parecen estar en curso, la interfaz de usuario del SageMaker generador de perfiles genera gráficos de panel y una cronología con los datos de perfil más recientes recopilados del trabajo de formación en curso o los datos del perfil cargados parcialmente.
sugerencia
Puede cargar y visualizar un perfil a la vez. Para cargar otro perfil, primero debe descargar el perfil cargado anteriormente. Para descargar un perfil, utilice el icono de la papelera situado en el extremo derecho del perfil, en la sección Loaded profile (Perfil cargado).
Panel de control
Cuando termine de cargar y seleccionar el trabajo de entrenamiento, la interfaz de usuario abre la página de Dahsboard (Panel de control), que incluye los siguientes paneles de forma predeterminada.
-
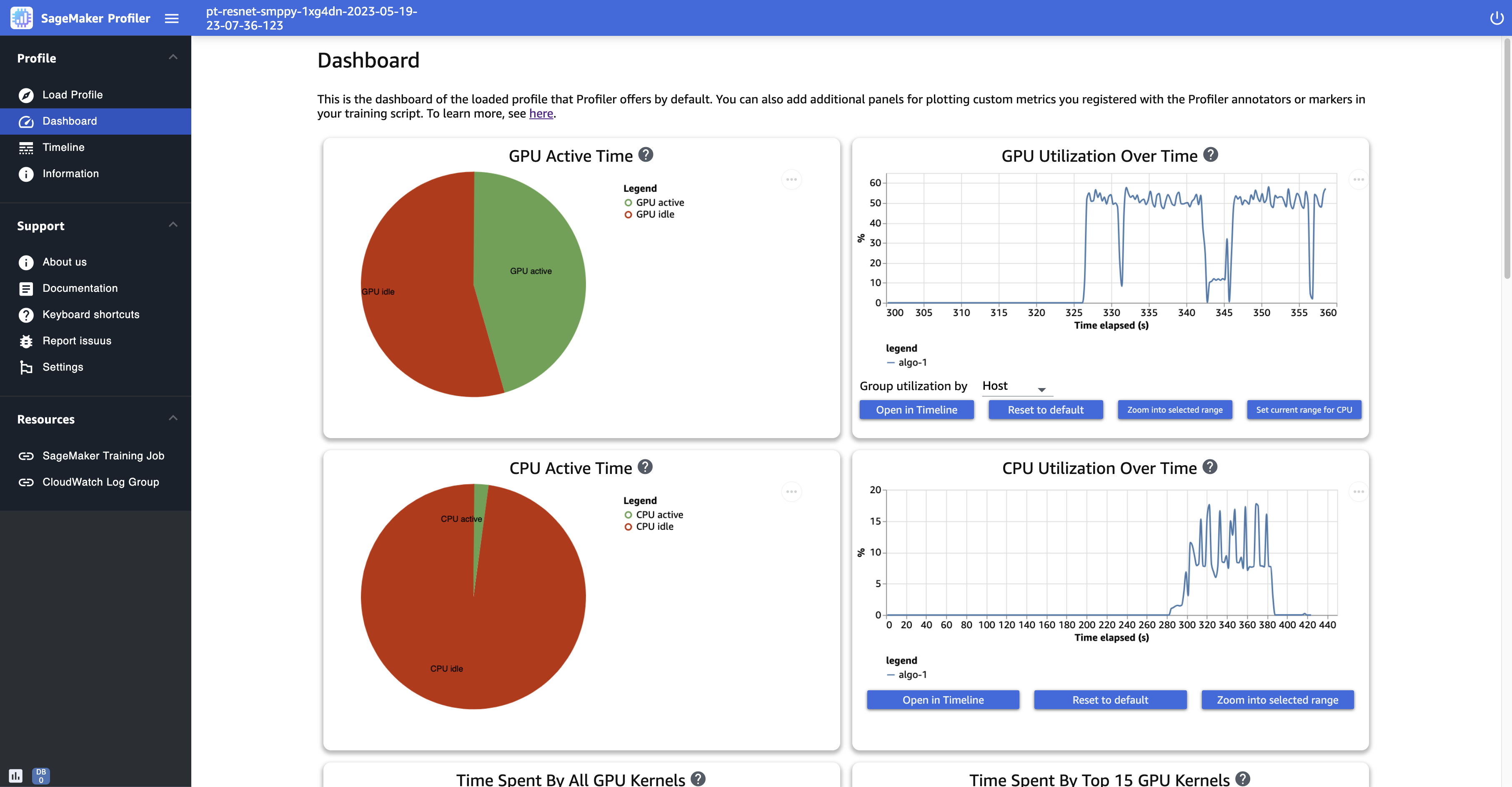
GPU active time (Tiempo de actividad de la GPU): este gráfico circular muestra el porcentaje de tiempo de actividad de la GPU en comparación con el tiempo de inactividad de la GPU. Puedes comprobar si tus GPU están más activas que inactivas durante todo el trabajo de entrenamiento. El tiempo de actividad de la GPU se basa en los puntos de datos del perfil con una tasa de utilización superior al 0 %, mientras que el tiempo de inactividad de la GPU se basa en los puntos de datos perfilados con un 0 % de utilización.
-
GPU utilization over time (Utilización de la GPU a lo largo del tiempo): este gráfico cronológico muestra la tasa media de utilización de la GPU a lo largo del tiempo por nodo, agrupando todos los nodos en un único gráfico. Puede comprobar si las GPU tienen una carga de trabajo desequilibrada, problemas de infrautilización, cuellos de botella o problemas de inactividad durante determinados intervalos de tiempo. Para realizar un seguimiento de la tasa de utilización a nivel de GPU individual y de las ejecuciones del kernel relacionadas, utilice la Interfaz de línea de tiempo. Tenga en cuenta que la recopilación de actividades de la GPU comienza desde donde agregó la función de inicio del generador de perfiles
SMProf.start_profiling()en su script de entrenamiento y termina enSMProf.stop_profiling(). -
GPU active time (Tiempo de actividad de la CPU): este gráfico circular muestra el porcentaje de tiempo de actividad de la CPU en comparación con el tiempo de inactividad de la CPU. Puede comprobar si las CPU están más activas que inactivas durante todo el trabajo de entrenamiento. El tiempo de actividad de la GCU se basa en los puntos de datos del perfil con una tasa de utilización superior al 0 %, mientras que el tiempo de inactividad de la CPU se basa en los puntos de datos perfilados con un 0 % de utilización.
-
CPU utilization over time (Utilización de la CPU a lo largo del tiempo): este gráfico cronológico muestra la tasa media de utilización de la CPU a lo largo del tiempo por nodo, agrupando todos los nodos en un único gráfico. Puede comprobar si las CPU tienen cuellos de botella o están infrautilizadas durante determinados intervalos de tiempo. Para realizar un seguimiento de la tasa de utilización de las CPU en función del uso individual de la GPU y de las ejecuciones del kernel, utilice la Interfaz de línea de tiempo. Tenga en cuenta que las métricas de uso comienzan desde el principio, desde la inicialización del trabajo.
-
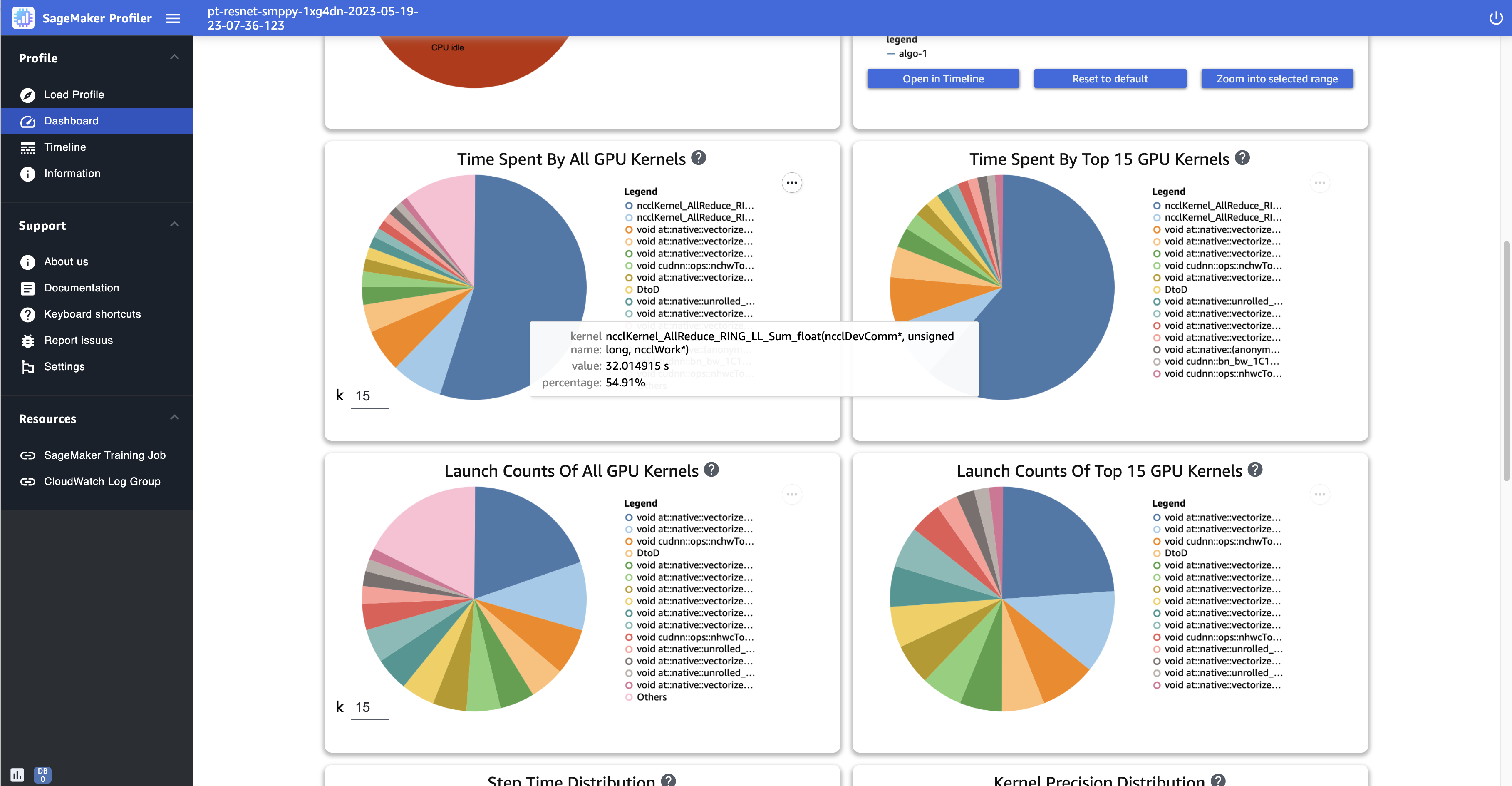
Tiempo empleado por todos los kernels de GPU: en este gráfico circular se muestran todos los kernels de GPU utilizados durante el trabajo de entrenamiento. Muestra los 15 kernels de GPU principales de forma predeterminada como sectores individuales y todos los demás kernels en un sector. Pase el ratón sobre los sectores para ver información más detallada. El valor muestra el tiempo total de funcionamiento de los kernels de la GPU en segundos y el porcentaje se basa en el tiempo total del perfil.
-
Tiempo empleado por los 15 principales kernels de GPU: en este gráfico circular se muestran todos los kernels de GPU que se utilizaron durante el trabajo de entrenamiento. Muestra los 15 kernels de GPU principales como sectores individuales. Pase el ratón sobre los sectores para ver información más detallada. El valor muestra el tiempo total de funcionamiento de los kernels de la GPU en segundos y el porcentaje se basa en el tiempo total del perfil.
-
Launch counts of all GPU kernels (Número de lanzamientos de todos los kernels de GPU): este gráfico circular muestra el número de lanzamientos de cada kernel de GPU lanzados durante el trabajo de entrenamiento. Muestra los 15 kernels de GPU principales como sectores individuales y todos los demás kernels en un sector. Pase el ratón sobre los sectores para ver información más detallada. El valor muestra el recuento total de los kernels de GPU lanzados y el porcentaje se basa en el número total de todos los kernels.
-
Launch counts of all CPU kernels (Número de lanzamientos de los 15 kernels de CPU): este gráfico circular muestra el número de lanzamientos de cada kernel de CPU lanzados durante el trabajo de entrenamiento. Muestra los 15 kernels de GPU principales. Pase el ratón sobre los sectores para ver información más detallada. El valor muestra el recuento total de los kernels de GPU lanzados y el porcentaje se basa en el número total de todos los kernels.
-
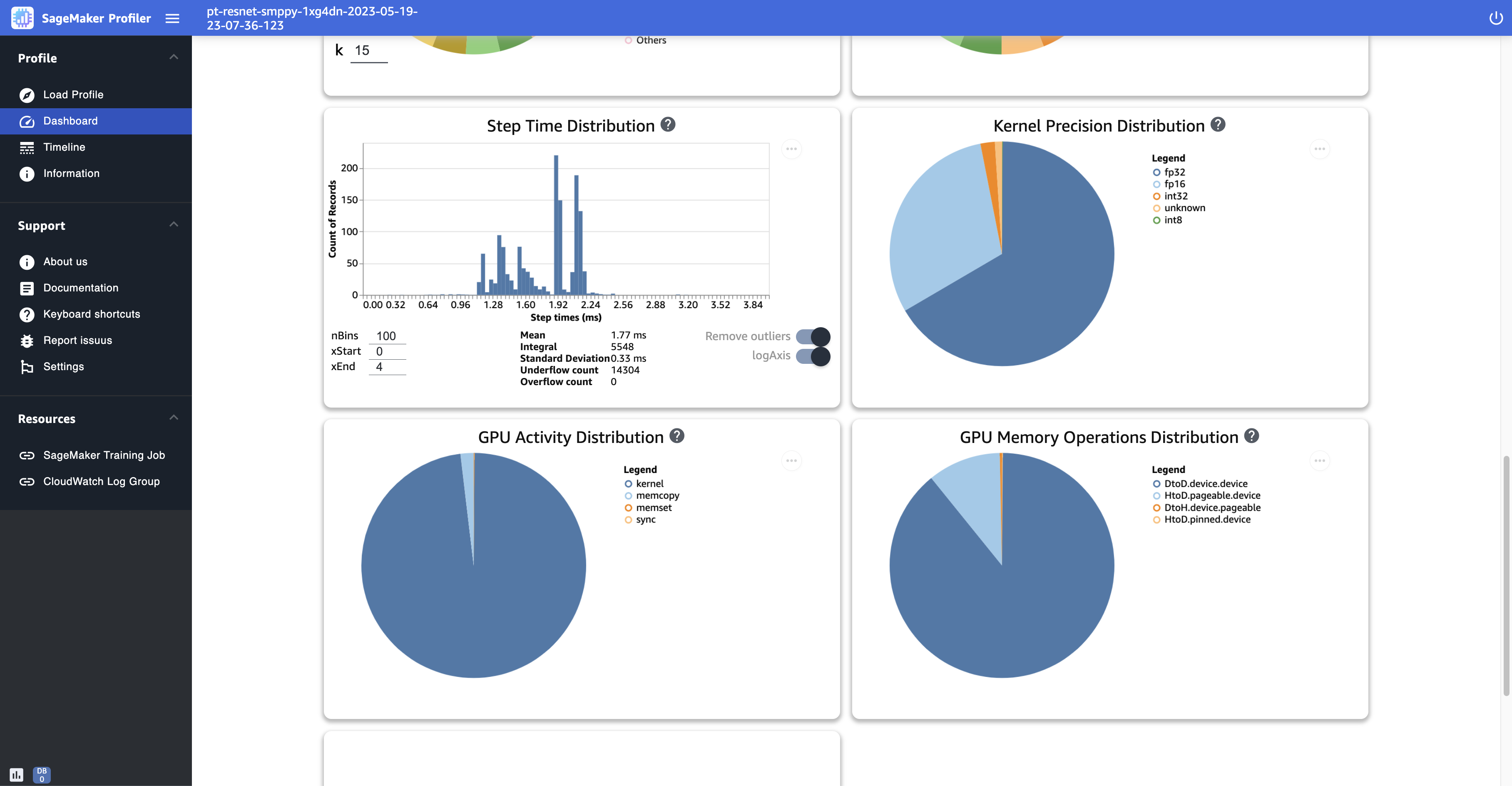
Step time distribution (Distribución del tiempo de paso): este histograma muestra la distribución de la duración de los pasos en las GPU. Este gráfico se genera solo después de añadir el anotador de pasos al script de entrenamiento.
-
Kernel precision distribution (Distribución de precisión del kernel): este gráfico circular muestra el porcentaje de tiempo dedicado a ejecutar los kernels en diferentes tipos de datos, como FP32, FP16, INT32 e INT8.
-
GPU activity distribution (Distribución de la actividad de la GPU): este gráfico circular muestra el porcentaje de tiempo dedicado a las actividades de la GPU, como la ejecución de los kernels, la memoria (
memcpyymemset) y la sincronización (sync). -
GPU memory operations distribution (Distribución de las operaciones de memoria de la GPU): este gráfico circular muestra el porcentaje de tiempo dedicado a las operaciones de memoria de la GPU. Esto visualiza las actividades
memcopyy ayuda a identificar si su trabajo de entrenamiento está dedicando demasiado tiempo a determinadas operaciones de memoria. -
Create a new histogram (Crear un histograma nuevo): cree un diagrama nuevo de una métrica personalizada que haya anotado manualmente durante Paso 1: Adapte su script de entrenamiento con los módulos SageMaker Profiler Python. Al añadir una anotación personalizada a un histograma nuevo, seleccione o escriba el nombre de la anotación que ha añadido en el script de entrenamiento. Por ejemplo, en el script de entrenamiento de demostración del paso 1,
step,Forward,Backward,OptimizeyLossestán las anotaciones personalizadas. Al crear un histograma nuevo, estos nombres de anotación deberían aparecer en el menú desplegable para seleccionar las métricas. Si eligeBackward, la interfaz de usuario añade al panel de control el histograma del tiempo dedicado a las pasadas hacia atrás a lo largo del tiempo perfilado. Este tipo de histograma es útil para comprobar si hay valores atípicos que tardan anormalmente más tiempo y provocan problemas de embotellamiento.
En las siguientes capturas de pantalla se muestra la relación entre el tiempo de actividad de la GPU y la CPU y la tasa media de utilización de la GPU y la CPU con respecto al tiempo por nodo de procesamiento.
En la siguiente captura de pantalla se muestra un ejemplo de gráficos circulares para comparar el número de veces que se lanzan los kernels de la GPU y medir el tiempo empleado en ejecutarlos. En los paneles Tiempo empleado por todos los kernels de la GPU y Recuento de lanzamientos de todos los kernels de la GPU, también puede especificar un número entero en el campo de entrada de k para ajustar el número de leyendas que se muestran en los gráficos. Por ejemplo, si especifica 10, los gráficos muestran los 10 kernels más ejecutados y lanzados, respectivamente.
En la siguiente captura de pantalla se muestra un ejemplo de paso, tiempo, duración, histograma y gráficos circulares para la distribución de precisión del kernel, la distribución de la actividad de la GPU y la distribución del funcionamiento de la memoria de la GPU.
Interfaz de línea de tiempo
Para obtener una visión detallada de los recursos informáticos a nivel de las operaciones y los kernels programados en las CPU y ejecutados en las GPU, utilice la interfaz de Timeline (Línea de tiempo).
Puedes acercar y alejar la imagen y desplazarte hacia la izquierda o hacia la derecha en la interfaz de la línea de tiempo con el ratón, las teclas [w, a, s, d] o las cuatro teclas de flecha del teclado.
sugerencia
Para obtener más consejos sobre los métodos abreviados de teclado para interactuar con la interfaz de Timeline (Línea de tiempo), seleccione Keyboard shortcuts (Métodos abreviados de teclado) en el panel izquierdo.
Las pistas de la línea de tiempo están organizadas en una estructura de árbol, lo que proporciona información desde el nivel del host hasta el nivel del dispositivo. Por ejemplo, si ejecuta instancias de N con ocho GPU en cada una, la estructura temporal de cada instancia sería la siguiente.
-
algo-i node: esto es lo que la SageMaker IA etiqueta para asignar tareas a las instancias aprovisionadas. El dígito inode se asigna de forma aleatoria. Por ejemplo, si usa 4 instancias, esta sección se expande de algo-1 a algo-4.
-
CPU: en esta sección, puede comprobar la tasa media de utilización de la CPU y los contadores de rendimiento.
-
GPU: en esta sección, puede comprobar la tasa de utilización media de la GPU, la tasa de utilización de cada GPU individual y los kernels.
-
SUM Utilization (Utilización de SUM): las tasas de uso medio de la GPU por instancia.
-
HOST-0 PID-123— Un nombre único asignado a cada pista del proceso. El acrónimo PID es el ID del proceso y el número que se le asocia es el número de ID del proceso que se registra durante la captura de datos del proceso. En esta sección se muestra la siguiente información del proceso.
-
GPU-inum_gpuutilización: la tasa de utilización de la num_gpu i-ésima GPU a lo largo del tiempo.
-
GPU-inum_gpudispositivo: el núcleo se ejecuta en el iésimo num_gpu dispositivo GPU.
-
stream icuda_stream: secuencias CUDA que muestran cómo el kernel se ejecuta en el dispositivo GPU. Para obtener más información sobre las transmisiones de CUDA, consulte las diapositivas en PDF en CUDA C/C ++ Streams and Concurrency
proporcionadas por NVIDIA.
-
-
GPU-inum_gpuanfitrión: el núcleo se inicia en el iésimo host de la num_gpu GPU.
-
-
-
En las siguientes capturas de pantalla se muestra la línea de tiempo del perfil de un trabajo de entrenamiento realizado en instancias ml.p4d.24xlarge equipadas con 8 GPU NVIDIA A100 Tensor Core en cada una.
La siguiente es una vista ampliada del perfil, en la que se imprimen una docena de pasos, incluido un cargador de datos intermitente entre step_232 y step_233 para recuperar el siguiente lote de datos.
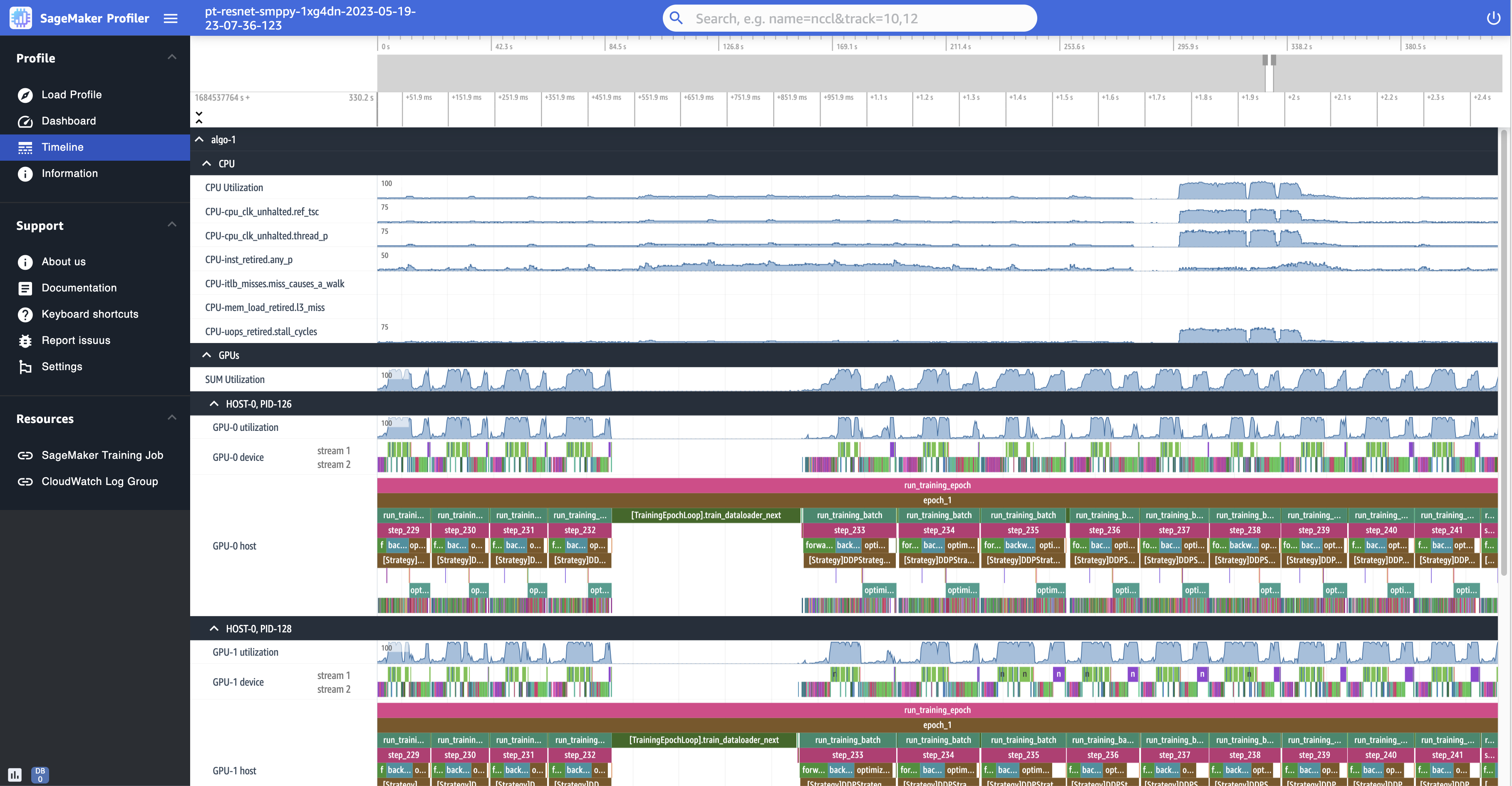
Para cada CPU, puede realizar un seguimiento de los contadores de uso y rendimiento de la CPU, como "clk_unhalted_ref.tsc" y "itlb_misses.miss_causes_a_walk", que son indicativos de las instrucciones que se ejecutan en la CPU.
Para cada GPU, puede ver una línea de tiempo del host y una del dispositivo. Los lanzamientos del kernel se producen en la línea de tiempo del host y las ejecuciones del kernel se realizan en la línea temporal del dispositivo. También puede ver las anotaciones (como avanzar, retroceder y optimizar) si ha añadido un script de entrenamiento en la cronología del host de la GPU.
En la vista de línea de tiempo, también puede hacer un seguimiento de los pares de lanzamiento y ejecución del kernel. Esto le ayuda a entender cómo se ejecuta un lanzamiento del kernel programado en un host (CPU) en el dispositivo GPU correspondiente.
sugerencia
Pulse la tecla f para ampliar el kernel seleccionado.
La siguiente captura de pantalla es una vista ampliada de step_233 y step_234 desde la captura de pantalla anterior. El intervalo temporal seleccionado en la siguiente captura de pantalla corresponde a la AllReduce operación, un paso esencial de comunicación y sincronización en el entrenamiento distribuido, que se ejecuta en el GPU-0 dispositivo. En la captura de pantalla, observe que la ejecución del núcleo en el GPU-0 servidor se conecta con la ejecución del núcleo en la secuencia de GPU-0 dispositivos 1, indicada con una flecha en color cian.
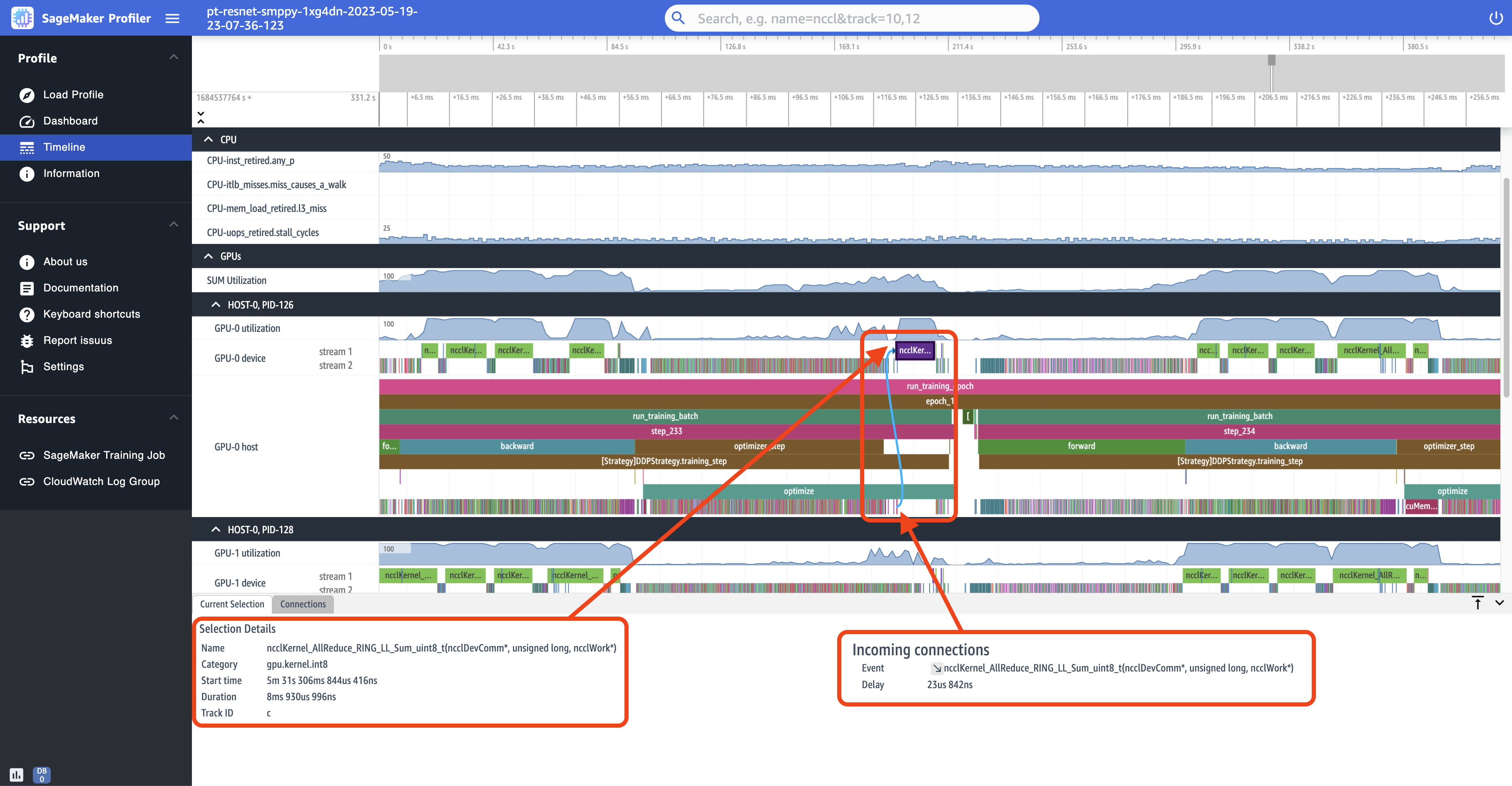
También aparecen dos pestañas de información en el panel inferior de la interfaz de usuario al seleccionar un intervalo de tiempo, como se muestra en la captura de pantalla anterior. La pestaña Current Selection (Selección actual) muestra los detalles del kernel seleccionado y del lanzamiento del kernel conectado desde el servidor. La dirección de conexión es siempre del host (CPU) al dispositivo (GPU), ya que cada kernel de la GPU siempre se llama desde una CPU. La pestaña Connections (Conexiones) muestra el par de inicio y ejecución del kernel elegido. Puede seleccionar cualquiera de ellas para moverla al centro de la vista Timeline (Línea de tiempo).
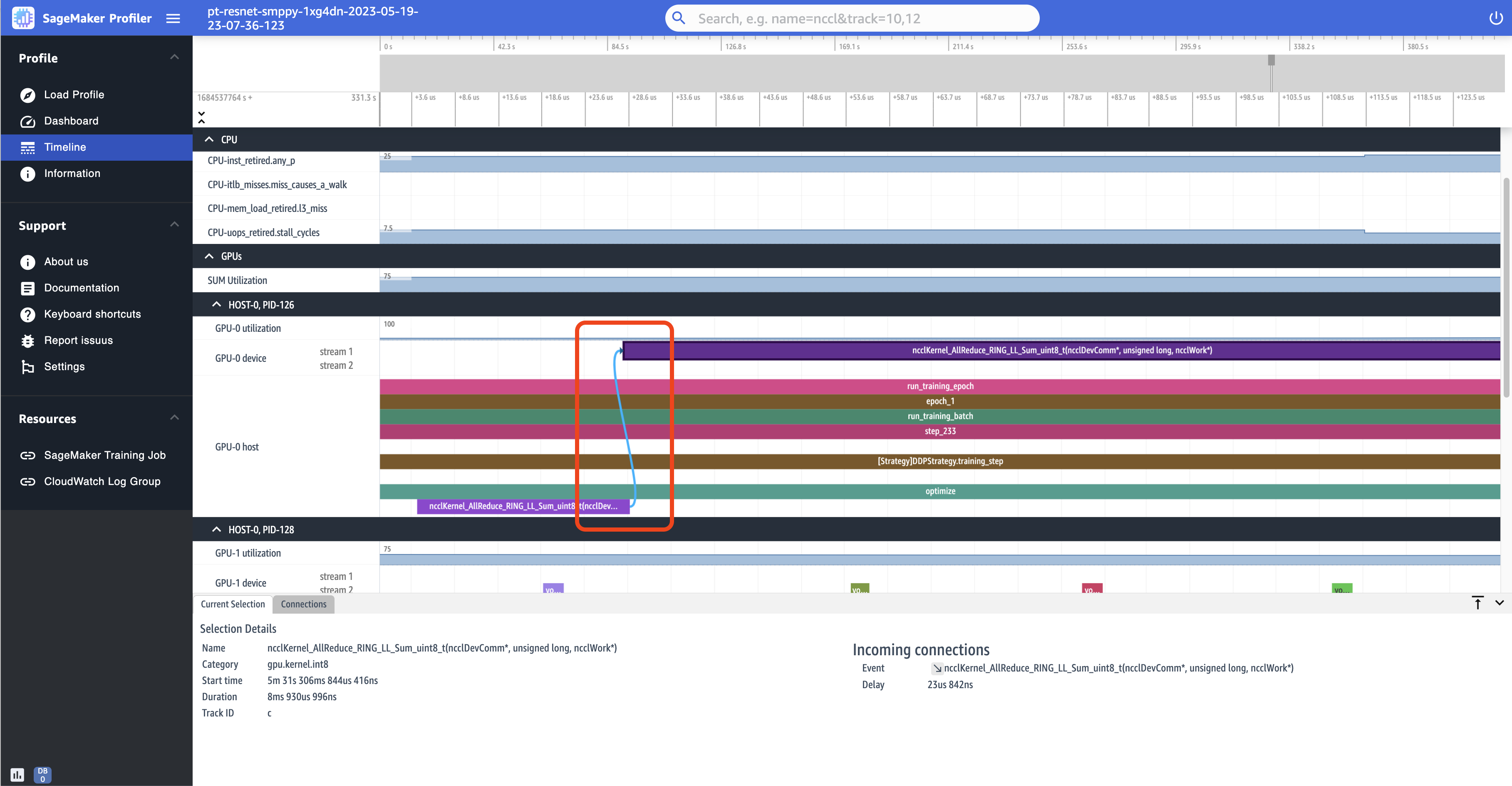
En la siguiente captura de pantalla se amplía aún más la combinación de inicio y ejecución de la operación AllReduce.
Información
En Information (Información), puede acceder a la información sobre el trabajo de entrenamiento cargado, como el tipo de instancia, los Nombres de recurso de Amazon (ARN) (ARN) de los recursos de computación aprovisionados para el trabajo, los nombres de los nodos y los hiperparámetros.
Configuración
De forma predeterminada, la instancia de la aplicación SageMaker AI Profiler UI está configurada para cerrarse tras 2 horas de inactividad. En Settings (Ajustes), use los siguientes parámetros para ajustar el temporizador de cierre automático.
-
Enable app auto shutdown (Habilitar el cierre de la aplicación): seleccione y configúrelo como Enabled (Habilitado) para permitir que la aplicación se cierre automáticamente después del número especificado de horas de inactividad. Para desactivar la función de apagado automático, selecciona DIsabled (Desactivado).
-
Auto shutdown threshold in hours (Umbral de cierre automático en horas): si selecciona Enabled (Habilitado) para Enable app auto shutdown (Habilitar apierre automático de aplicación), puede establecer el tiempo límite en horas para que la aplicación se cierre automáticamente. De forma predeterminada, se establece en 2.
