Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Métricas de Amazon SageMaker AI en Amazon CloudWatch
Puedes monitorizar la SageMaker IA de Amazon con Amazon CloudWatch, que recopila datos sin procesar y los procesa para convertirlos en métricas legibles prácticamente en tiempo real. Estas estadísticas se conservan durante 15 meses. Con ellas, puede acceder a información histórica y disponer de una mejor perspectiva sobre el rendimiento de su aplicación web o servicio. Sin embargo, la CloudWatch consola de Amazon limita la búsqueda a las métricas que se hayan actualizado en las últimas 2 semanas. Esta limitación garantiza que la mayor parte de los trabajos actuales se muestren en su espacio de nombres.
Para representar métricas gráficamente sin usar una búsqueda, especifique su nombre exacto en la vista del código fuente. También puede establecer alarmas que vigilen determinados umbrales y enviar notificaciones o realizar acciones cuando se cumplan dichos umbrales. Para obtener más información, consulta la Guía del CloudWatch usuario de Amazon.
SageMaker Métricas y dimensiones de la IA
SageMaker Métricas de puntos finales de IA
El espacio de /aws/sagemaker/Endpoints nombres incluye las siguientes métricas para las instancias de punto final.
Las métricas están disponibles con una frecuencia de un minuto. Puede configurar la frecuencia de publicación en 10, 30, 60, 120, 180, 240 o 300 segundos MetricPublishFrequencyInSeconds configurándolo. MetricsConfig No es necesario EnableEnhancedMetrics activar esta configuración. Si lo EnableEnhancedMetrics configurasTrue, estarán disponibles las dimensiones InstanceId y dimensiones adicionales AcceleratorId (solo las métricas de la GPU). Para obtener más información, consulte Métricas mejoradas de Amazon SageMaker AI para puntos finales de inferencia.
nota
Amazon CloudWatch admite métricas personalizadas de alta resolución y su mejor resolución es de 1 segundo. Sin embargo, cuanto más fina sea la resolución, menor será la vida útil de las CloudWatch métricas. Para la resolución de frecuencia de 1 segundo, las CloudWatch métricas están disponibles durante 3 horas. Para obtener más información sobre la resolución y la duración de las CloudWatch métricas, consulta la referencia GetMetricStatisticsde las CloudWatch API de Amazon.
| Métrica | Description (Descripción) |
|---|---|
CPUReservation |
La suma de las CPU reservadas por los contenedores en una instancia. Esta métrica se proporciona solo para los puntos finales que alojan componentes de inferencia activos. El valor oscila entre 0 % y 100 %. En la configuración de un componente de inferencia, se establece la reserva de CPU con el parámetro |
CPUUtilization |
La suma de la utilización de cada núcleo individual de la CPU. La utilización de la CPU de cada núcleo oscila entre 0 y 100. Por ejemplo, si hay cuatro CPU, la Para las variantes de punto de conexión, el valor es la suma de la utilización de la CPU de los contenedores principales y suplementarios en la instancia. Unidad: porcentaje |
CPUUtilizationNormalized |
La suma normalizada de la utilización de cada núcleo individual de la CPU. Esta métrica se proporciona solo para los puntos finales que alojan componentes de inferencia activos. El valor oscila entre 0 % y 100 %. Por ejemplo, si hay 4 CPU y la métrica |
DiskUtilization |
El porcentaje de espacio en disco usado por los contenedores en una instancia. Este valor oscila del 0 % al 100 %. Para las variantes de punto de conexión, el valor es la suma de la utilización del espacio en disco de los contenedores principales y suplementarios en la instancia.Unidad: porcentaje |
GPUMemoryUtilization |
El porcentaje de memoria de GPU que utilizan los contenedores en una instancia. El valor oscila entre 0 y 100, y se multiplica por el número de GPU. Por ejemplo, si hay cuatro GPU, la Para las variantes de punto de conexión, el valor es la suma de la utilización de la memoria de la GPU de los contenedores principales y suplementarios en la instancia. Unidad: porcentaje |
GPUMemoryUtilizationNormalized |
El porcentaje normalizado de memoria de GPU que utilizan los contenedores en una instancia. Esta métrica se proporciona solo para los puntos finales que alojan componentes de inferencia activos. El valor oscila entre 0 % y 100 %. Por ejemplo, si hay 4 GPU y la métrica |
GPUReservation |
La suma de las GPU reservadas por los contenedores en una instancia. Esta métrica se proporciona solo para los puntos finales que alojan componentes de inferencia activos. El valor oscila entre 0 % y 100 %. En la configuración de un componente de inferencia, se establece la reserva de GPU con el parámetro |
GPUUtilization |
El porcentaje de unidades de GPU usadas por los contenedores en una instancia. El valor puede oscilar entre 0 y 100, y se multiplica por el número de GPU. Por ejemplo, si hay cuatro GPU, la Para las variantes de punto de conexión, el valor es la suma de la utilización de la GPU de los contenedores principales y suplementarios en la instancia. Unidad: porcentaje |
GPUUtilizationNormalized |
El porcentaje normalizado de unidades de GPU usadas por los contenedores en una instancia. Esta métrica se proporciona solo para los puntos finales que alojan componentes de inferencia activos. El valor oscila entre 0 % y 100 %. Por ejemplo, si hay 4 GPU y la métrica |
MemoryReservation |
La suma de memoria reservada por los contenedores en una instancia. Esta métrica se proporciona solo para los puntos finales que alojan componentes de inferencia activos. El valor oscila entre 0 % y 100 %. En la configuración de un componente de inferencia, se establece la reserva de memoria con el parámetro |
MemoryUtilization |
El porcentaje de memoria que utilizan los contenedores en una instancia. Este valor oscila del 0 % al 100 %. Para las variantes de punto de conexión, el valor es la suma de la utilización de la memoria de los contenedores principales y suplementarios en la instancia. Unidad: porcentaje |
| Dimensión | Description (Descripción) |
|---|---|
EndpointName, VariantName |
Filtra las métricas de punto final |
EndpointName, VariantName, InstanceType |
Filtra las métricas de punto final por tipo de instancia para una variante de producción que usa grupos de instancias. Usa esta dimensión para monitorear las métricas de cada tipo de instancia de la variante por separado. |
InstanceId |
Filtra las métricas de punto final de una instancia específica. Disponible cuando |
AcceleratorId |
(Solo métricas de GPU) Filtra las métricas de punto final de una GPU específica. Disponible cuando |
SageMaker Métricas de invocación de puntos finales de IA
El espacio de nombres AWS/SageMaker incluye las siguientes métricas de respuesta desde llamadas en InvokeEndpoint.
Las métricas están disponibles con una frecuencia de un minuto. Puede configurar la frecuencia de publicación en 10, 30, 60, 120, 180, 240 o 300 segundos MetricPublishFrequencyInSeconds configurándolo. MetricsConfig Para las métricas de invocación, esta configuración debe EnableEnhancedMetrics estar establecida en. True Si lo configura EnableEnhancedMetricsTrue, también estarán disponibles las dimensiones InstanceId y dimensiones adicionales ContainerId (solo los componentes de inferencia). Para obtener más información, consulte Métricas mejoradas de Amazon SageMaker AI para puntos finales de inferencia.
La siguiente ilustración muestra cómo interactúa un punto final de SageMaker IA con la API Amazon SageMaker Runtime. El tiempo total entre el envío de una solicitud a un punto de conexión y la recepción de una respuesta depende de los tres componentes siguientes.
-
Latencia de red: el tiempo que transcurre entre la presentación de una solicitud y la recepción de una respuesta de la API SageMaker Runtime Runtime.
-
Latencia de sobrecarga: el tiempo que se tarda en transportar una solicitud al contenedor del modelo desde la API SageMaker Runtime Runtime y en transportar la respuesta de vuelta a ella.
-
Latencia del modelo: el tiempo que tarda el contenedor de modelos en procesar la solicitud y devolver una respuesta.
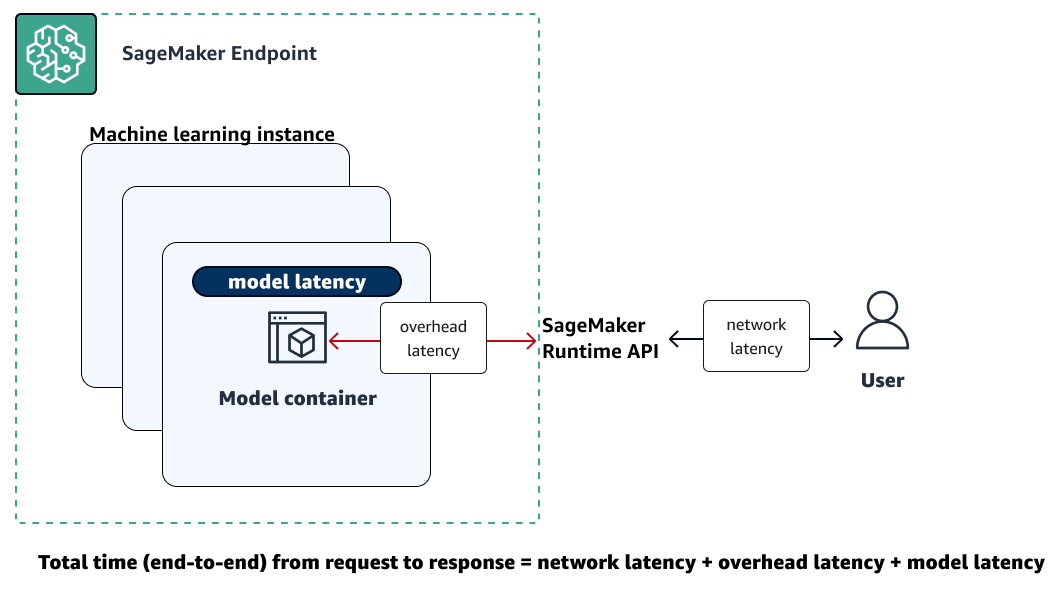
Para obtener más información sobre la latencia total, consulte Prácticas recomendadas para realizar pruebas de carga en los puntos finales de inferencia en tiempo real de Amazon SageMaker AI
| Métrica | Description (Descripción) |
|---|---|
ConcurrentRequestsPerCopy |
El número de solicitudes simultáneas que recibe el componente de inferencia, normalizado por cada copia de un componente de inferencia. Estadísticas válidas: mín, máx |
ConcurrentRequestsPerModel |
El número de solicitudes simultáneas que recibe el modelo. Estadísticas válidas: mín, máx |
Invocation4XXErrors |
El número de solicitudes Unidades: ninguna Estadísticas válidas: Average, Sum |
Invocation5XXErrors |
El número de solicitudes Unidades: ninguna Estadísticas válidas: Average, Sum |
InvocationModelErrors |
El número de solicitudes de invocación del modelo que no dieron lugar a una respuesta HTTP 2XX. Esto incluye los códigos de 4XX/5XX estado, los errores de socket de bajo nivel, las respuestas HTTP mal formateadas y los tiempos de espera de las solicitudes. Para cada respuesta de error, se envía 1; de lo contrario, se envía 0. Unidades: ninguna Estadísticas válidas: Average, Sum |
Invocations |
El número de solicitudes de Para obtener el número total de solicitudes enviadas a un punto de enlace del modelo, utilice la estadística Sum. Unidades: ninguna Estadísticas válidas: Sum |
InvocationsPerCopy |
El número de invocaciones normalizadas por cada copia de un componente de inferencia. Estadísticas válidas: Sum |
InvocationsPerInstance |
El número de invocaciones enviadas a un modelo, normalizado Unidades: ninguna Estadísticas válidas: Sum |
ModelLatency |
El intervalo de tiempo que tarda un modelo en responder a una solicitud de la API SageMaker Runtime. Este intervalo incluye el tiempo de comunicación local empleado en el envío de la solicitud y la recuperación de la respuesta del contenedor de modelos. También incluye el tiempo necesario para completar la inferencia en el contenedor. Unidades: microsegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count, Percentiles. |
ModelSetupTime |
El tiempo que se tarda en lanzar nuevos recursos de computación para un punto de conexión sin servidor. El tiempo puede variar según el tamaño del modelo, el tiempo que se tarde en descargarlo y el tiempo de arranque del contenedor. Unidades: microsegundos Estadísticas válidas: Average, Min, Max, Sample Count, Percentiles. |
OverheadLatency |
El intervalo de tiempo que se suma al tiempo necesario para responder a una solicitud de un cliente debido a los gastos generales de SageMaker IA. Este intervalo se mide desde el momento en que SageMaker AI recibe la solicitud hasta que devuelve una respuesta al cliente, menos el Unidades: microsegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count. |
MidStreamErrors
|
La cantidad de errores que se producen durante la transmisión de la respuesta después de enviar la respuesta inicial al cliente. Unidades: ninguna Estadísticas válidas: Average, Sum |
FirstChunkLatency
|
El tiempo transcurrido desde que la solicitud llega al punto final de la SageMaker IA hasta que se envía la primera parte de la respuesta al cliente. Esta métrica se aplica a las solicitudes de inferencia de transmisión bidireccional. Unidades: microsegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count, Percentiles. |
FirstChunkModelLatency
|
El tiempo que tarda el contenedor modelo en procesar la solicitud y devolver la primera parte de la respuesta. Se mide desde que se envía la solicitud al contenedor del modelo hasta que se recibe el primer byte del modelo. Esta métrica se aplica a las solicitudes de inferencia de transmisión bidireccional. Unidades: microsegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count, Percentiles. |
FirstChunkOverheadLatency
|
La latencia de sobrecarga del primer fragmento, excluido el tiempo de procesamiento del modelo. Se calcula como un Unidades: microsegundos Estadísticas válidas: promedio, suma, mínimo, máximo, recuento de muestras, percentil |
| Dimensión | Description (Descripción) |
|---|---|
EndpointName, VariantName |
Filtra las métricas de invocación de punto de conexión para una |
EndpointName, VariantName, InstanceType |
Filtra las métricas de invocación de puntos finales por tipo de instancia para una variante de producción que usa grupos de instancias. Usa esta dimensión para ver los patrones de invocación de cada tipo de instancia de la variante. |
InferenceComponentName |
Filtra las métricas de invocación de componentes de inferencia. |
InstanceId |
Filtra las métricas de invocación de una instancia específica. Disponible cuando |
ContainerId |
(Solo componentes de inferencia) Filtra las métricas de invocación de un contenedor específico. Disponible cuando |
SageMaker Métricas de componentes de inferencia de IA
El espacio de /aws/sagemaker/InferenceComponents nombres incluye las siguientes métricas de las llamadas a los puntos finales que alojan InvokeEndpointlos componentes de inferencia. Container-level la granularidad requerida en la configuración de los puntos EnableEnhancedMetrics=True finales. MetricsConfig
Las métricas están disponibles con una frecuencia de un minuto. Puede configurar la frecuencia de publicación en 10, 30, 60, 120, 180, 240 o 300 segundos MetricPublishFrequencyInSeconds configurándola. MetricsConfig No es necesario EnableEnhancedMetrics activar esta configuración. Si lo EnableEnhancedMetrics configurasTrue, estarán disponibles las dimensiones InstanceId adicionales y AcceleratorId (solo las métricas de la GPU). ContainerId Para obtener más información, consulte Métricas mejoradas de Amazon SageMaker AI para puntos finales de inferencia.
| Métrica | Description (Descripción) |
|---|---|
CPUUtilizationNormalized |
El valor de la métrica |
GPUMemoryUtilizationNormalized |
El valor de la métrica |
GPUUtilizationNormalized |
El valor de la métrica |
MemoryUtilizationNormalized |
El valor de |
| Dimensión | Description (Descripción) |
|---|---|
InferenceComponentName |
Filtra las métricas de los componentes de inferencia. |
InferenceComponentName, InstanceType |
Filtra las métricas de los componentes de inferencia por tipo de instancia. Usa esta dimensión cuando el componente de inferencia se implemente en una variante de producción con grupos de instancias para ver las métricas de cada tipo de instancia por separado. |
InstanceId |
Filtra las métricas de los componentes de inferencia para una instancia específica. Disponible cuando |
ContainerId |
Filtra las métricas de los componentes de inferencia para un contenedor específico. Disponible cuando |
AcceleratorId |
(Solo métricas de GPU) Filtra las métricas de los componentes de inferencia de una GPU específica. Disponible cuando |
SageMaker Métricas de puntos finales multimodelo de IA
El espacio de AWS/SageMaker nombres incluye el siguiente modelo de carga de métricas de las llamadas a. InvokeEndpoint
Las métricas están disponibles con una frecuencia de un minuto.
Para obtener información sobre cuánto tiempo se conservan CloudWatch las métricas, consulta la referencia GetMetricStatisticsde la CloudWatch API de Amazon.
| Métrica | Description (Descripción) |
|---|---|
ModelLoadingWaitTime |
El intervalo de tiempo que una solicitud de invocación ha esperado a que se descargue o cargue el modelo de destino, o ambos, para ejecutar la inferencia. Unidades: microsegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count. |
ModelUnloadingTime |
El intervalo de tiempo que tardó en descargar el modelo a través de la llamada a la API Unidades: microsegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count. |
ModelDownloadingTime |
El intervalo de tiempo que se tardó en descargar el modelo de Amazon Simple Storage Service (Amazon S3). Unidades: microsegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count. |
ModelLoadingTime |
El intervalo de tiempo que tardó en cargar el modelo a través de la llamada a la API Unidades: microsegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count. |
ModelCacheHit |
El número de solicitudes La estadística Promedio muestra la proporción de solicitudes para las que el modelo ya se ha cargado. Unidades: ninguna Estadísticas válidas: Average, Sum, Sample Count. |
| Dimensión | Description (Descripción) |
|---|---|
EndpointName, VariantName |
Filtra las métricas de invocación de punto de conexión para una |
Los espacios de nombres /aws/sagemaker/Endpoints contienen las siguientes métricas de instancia de las llamadas a InvokeEndpoint.
Las métricas están disponibles con una frecuencia de un minuto.
Para obtener información sobre cuánto tiempo se conservan CloudWatch las métricas, consulta la referencia GetMetricStatisticsde la CloudWatch API de Amazon.
| Métrica | Description (Descripción) |
|---|---|
LoadedModelCount |
El número de modelos cargados en los contenedores del punto de conexión multimodelo. Esta métrica se emite por instancia. La estadística Promedio con un período de 1 minuto indica el número medio de modelos cargados por instancia. La estadística Suma indica el número total de modelos cargados en todas las instancias del punto de conexión. Los modelos de los que realiza el seguimiento de esta métrica no son necesariamente únicos porque un modelo puede cargarse en varios contenedores en el punto de conexión. Unidades: ninguna Estadísticas válidas: Average, Sum, Min, Max, Sample Count. |
| Dimensión | Description (Descripción) |
|---|---|
EndpointName, VariantName |
Filtra las métricas de invocación de punto de conexión para una |
SageMaker Métricas de trabajo de IA
Los /aws/sagemaker/TransformJobs espacios de nombres /aws/sagemaker/ProcessingJobs/aws/sagemaker/TrainingJobs, y incluyen las siguientes métricas para los trabajos de procesamiento, los trabajos de formación y los trabajos de transformación por lotes.
Las métricas están disponibles con una frecuencia de un minuto.
nota
Amazon CloudWatch admite métricas personalizadas de alta resolución y su mejor resolución es de 1 segundo. Sin embargo, cuanto más fina sea la resolución, menor será la vida útil de las CloudWatch métricas. Para la resolución de frecuencia de 1 segundo, las CloudWatch métricas están disponibles durante 3 horas. Para obtener más información sobre la resolución y la duración de las CloudWatch métricas, consulta la referencia GetMetricStatisticsde las CloudWatch API de Amazon.
sugerencia
Para perfilar su trabajo de formación con una resolución más precisa, con una granularidad de hasta 100 milisegundos (0,1 segundos) y almacenar las métricas de formación de forma indefinida en Amazon S3 para su análisis personalizado en cualquier momento, considere la posibilidad de utilizar Amazon Debugger. SageMaker SageMaker Debugger incluye reglas integradas para detectar automáticamente los problemas de entrenamiento más comunes. Detecta problemas de uso de los recursos de hardware (como la CPU, la GPU y los cuellos de I/O botella). También detecta problemas de modelos no convergentes (como el sobreajuste, la desaparición de los gradientes y la explosión de los tensores). SageMaker Debugger también proporciona visualizaciones a través de Studio Classic y su informe de creación de perfiles. Para explorar las visualizaciones del depurador, consulte el tutorial del panel de control de SageMaker Debugger Insights, el tutorial del informe de creación de perfiles del depurador y el análisis de datos mediantela biblioteca de clientes de SMDebug.
| Métrica | Description (Descripción) |
|---|---|
CPUUtilization |
La suma de la utilización de cada núcleo individual de la CPU. La utilización de la CPU de cada núcleo oscila entre 0 y 100. Por ejemplo, si hay cuatro CPU, la CPUUtilization puede oscilar entre 0 % y 400 %. Para trabajos de procesamiento, el valor es la utilización de CPU del contenedor de procesamiento en la instancia.Para los trabajos de capacitación, el valor es la utilización de la CPU del contenedor de algoritmos en la instancia. Para los trabajos de transformación por lotes, el valor es la utilización de la CPU del contenedor de transformación en la instancia. notaEn el caso de trabajos de varias instancias, cada instancia notifica las métricas de utilización de la CPU. Sin embargo, la vista predeterminada CloudWatch muestra el uso promedio de la CPU en todas las instancias. Unidad: porcentaje |
DiskUtilization |
El porcentaje de espacio en disco usado por los contenedores en una instancia. Este valor oscila del 0 % al 100 %. Esta métrica no es compatible con los trabajos de transformación por lotes. Para trabajos de procesamiento, el valor es la utilización del espacio en disco del contenedor de procesamiento en la instancia.Para los trabajos de capacitación, el valor es la utilización del espacio en disco del contenedor de algoritmos en la instancia. Unidad: porcentaje notaEn el caso de trabajos de varias instancias, cada instancia notifica las métricas de utilización del disco. Sin embargo, la vista predeterminada de CloudWatch muestra la utilización media del disco en todas las instancias. |
GPUMemoryUtilization |
El porcentaje de memoria de GPU que utilizan los contenedores en una instancia. El valor oscila entre 0 y 100, y se multiplica por el número de GPU. Por ejemplo, si hay cuatro GPU, la Para los trabajos de capacitación, el valor es la utilización de la memoria de la GPU del contenedor de algoritmos en la instancia. Para los trabajos de transformación por lotes, el valor es la utilización de la memoria de la GPU del contenedor de transformación en la instancia. notaEn el caso de trabajos de varias instancias, cada instancia notifica las métricas de utilización de la memoria GPU. Sin embargo, la vista predeterminada de CloudWatch muestra el uso medio de la memoria de la GPU en todas las instancias. Unidad: porcentaje |
GPUUtilization |
El porcentaje de unidades de GPU usadas por los contenedores en una instancia. El valor puede oscilar entre 0 y 100, y se multiplica por el número de GPU. Por ejemplo, si hay cuatro GPU, la Para los trabajos de capacitación, el valor es la utilización de la GPU del contenedor de algoritmos en la instancia. Para los trabajos de transformación por lotes, el valor es la utilización de la GPU del contenedor de transformación en la instancia. notaEn el caso de trabajos de varias instancias, cada instancia notifica las métricas de utilización de la GPU. Sin embargo, la vista predeterminada de CloudWatch muestra el uso medio de la GPU en todas las instancias. Unidad: porcentaje |
MemoryUtilization |
El porcentaje de memoria que utilizan los contenedores en una instancia. Este valor oscila del 0 % al 100 %. Para trabajos de procesamiento, el valor es la utilización de memoria del contenedor de procesamiento en la instancia.Para los trabajos de capacitación, el valor es la utilización de la memoria del contenedor de algoritmos en la instancia. Para los trabajos de transformación por lotes, el valor es la utilización de la memoria del contenedor de transformación en la instancia. Unidad: porcentaje notaEn el caso de trabajos de varias instancias, cada instancia notifica las métricas de utilización de la memoria. Sin embargo, la vista predeterminada de CloudWatch muestra el uso medio de la memoria en todas las instancias. |
| Dimensión | Description (Descripción) |
|---|---|
Host |
Para trabajos de procesamiento, el valor para esta dimensión tiene el formato Para trabajos de capacitación, el valor para esta dimensión tiene el formato Para trabajos de transformación por lotes, el valor para esta dimensión tiene el formato |
SageMaker Métricas de trabajos de Inference Recommender
El espacio de nombres /aws/sagemaker/InferenceRecommendationsJobs contiene las siguientes métricas para los trabajos de recomendación de inferencias.
| Métrica | Description (Descripción) |
|---|---|
ClientInvocations |
El número de solicitudes Unidades: ninguna Estadísticas válidas: Sum |
ClientInvocationErrors |
El número de solicitudes Unidades: ninguna Estadísticas válidas: Sum |
ClientLatency |
El intervalo de tiempo transcurrido entre el envío de una llamada Unidades: milisegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count, Percentiles. |
NumberOfUsers |
El número de usuarios simultáneos que envían Unidades: ninguna Estadísticas válidas: Max, Min, Average. |
| Dimensión | Description (Descripción) |
|---|---|
JobName |
Filtra las métricas de trabajo del recomendador de inferencias para el trabajo de recomendador de inferencias especificado. |
EndpointName |
Filtra las métricas de trabajo del recomendador de inferencias para el punto de conexión especificado. |
SageMaker Métricas de Ground Truth
| Métrica | Description (Descripción) |
|---|---|
ActiveWorkers |
Un solo trabajador activo de un equipo de trabajo privado presentó, lanzó o rechazó una tarea. Para obtener el número total de trabajadores activos, use la estadística Sum. Ground Truth intenta entregar cada evento individual Unidades: ninguna Estadísticas válidas: Sum, Sample Count. |
DatasetObjectsAutoAnnotated |
El número de objetos de conjunto de datos comentados automáticamente en un trabajo de etiquetado. Esta métrica solo se emite al habilitarse el etiquetado automatizado. Para ver el progreso del trabajo de etiquetado, use la métrica Max. Unidades: ninguna Estadísticas válidas: Máximo |
DatasetObjectsHumanAnnotated |
El número de objetos de conjunto de datos comentados por un humano en un trabajo de etiquetado. Para ver el progreso del trabajo de etiquetado, use la métrica Max. Unidades: ninguna Estadísticas válidas: Máximo |
DatasetObjectsLabelingFailed |
El número de objetos de conjunto de datos que no se pudieron etiquetar en un trabajo de etiquetado. Para ver el progreso del trabajo de etiquetado, use la métrica Max. Unidades: ninguna Estadísticas válidas: Máximo |
JobsFailed |
Error en un solo trabajo de etiquetado. Para obtener el número total de trabajos de etiquetado que generaron error, use la estadística Sum. Unidades: ninguna Estadísticas válidas: Sum, Sample Count. |
JobsSucceeded |
Se ha realizado correctamente un solo trabajo de etiquetado. Para obtener el número total de trabajos de etiquetado que se realizaron correctamente, use la estadística Sum. Unidades: ninguna Estadísticas válidas: Sum, Sample Count. |
JobsStopped |
Se detuvo un solo trabajo de etiquetado. Para obtener el número total de trabajos de etiquetado que se detuvieron, use la estadística Sum. Unidades: ninguna Estadísticas válidas: Sum, Sample Count. |
TasksAccepted |
Un trabajador aceptó una sola tarea. Para obtener el número total de tareas aceptadas por los trabajadores, use la estadística Sum. Ground Truth intenta entregar cada evento individual Unidades: ninguna Estadísticas válidas: Sum, Sample Count. |
TasksDeclined |
Un trabajador rechazó una sola tarea. Para obtener el número total de tareas rechazadas por los trabajadores, use la estadística Sum. Ground Truth intenta entregar cada evento individual Unidades: ninguna Estadísticas válidas: Sum, Sample Count. |
TasksReturned |
Se devolvió una sola tarea. Para obtener el número total de tareas devueltas, use la estadística Sum. Ground Truth intenta entregar cada evento individual Unidades: ninguna Estadísticas válidas: Sum, Sample Count. |
TasksSubmitted |
Una sola tarea la submitted/completed realizó un trabajador privado. Para obtener el número total de tareas enviadas por los trabajadores, use la estadística Sum. Ground Truth intenta entregar cada evento individual Unidades: ninguna Estadísticas válidas: Sum, Sample Count. |
TimeSpent |
Tiempo empleado en una tarea completada por un trabajador privado. Esta métrica no incluye el tiempo en que un trabajador hizo una pausa o se tomó un descanso. Ground Truth intenta entregar cada evento Unidades: segundos Estadísticas válidas: Sum, Sample Count. |
TotalDatasetObjectsLabeled |
El número de objetos de conjunto de datos correctamente etiquetados en un trabajo de etiquetado. Para ver el progreso del trabajo de etiquetado, use la métrica Max. Unidades: ninguna Estadísticas válidas: Máximo |
| Dimensión | Description (Descripción) |
|---|---|
LabelingJobName |
Filtra métricas de recuento de objetos de conjunto de datos para un trabajo de etiquetado. |
Estadísticas de Amazon SageMaker Feature Store
| Métrica | Description (Descripción) |
|---|---|
ConsumedReadRequestsUnits |
El número de unidades de lectura consumidas durante el periodo de tiempo especificado. Puede recuperar las unidades de lectura consumidas para una operación de tiempo de ejecución del almacén de características y su grupo de características correspondiente. Unidades: ninguna Estadísticas válidas: todas. |
ConsumedWriteRequestsUnits |
El número de unidades de escritura consumidas durante el periodo de tiempo especificado. Puede recuperar las unidades de escritura consumidas para una operación de tiempo de ejecución del almacén de características y su grupo de características correspondiente. Unidades: ninguna Estadísticas válidas: todas. |
ConsumedReadCapacityUnits |
El número de unidades de capacidad de lectura aprovisionadas durante el periodo especificado. Puede recuperar las unidades de capacidad de lectura consumidas para una operación de tiempo de ejecución del almacén de características y su grupo de características correspondiente. Unidades: ninguna Estadísticas válidas: todas. |
ConsumedWriteCapacityUnits |
El número de unidades de capacidad de escritura aprovisionadas durante el periodo especificado. Puede recuperar las unidades de capacidad de escritura consumidas para una operación de tiempo de ejecución de un almacén de características y su grupo de características correspondiente. Unidades: ninguna Estadísticas válidas: todas. |
| Dimensión | Description (Descripción) |
|---|---|
FeatureGroupName, OperationName |
Filtra las métricas de consumo de tiempo de ejecución del almacén de características del grupo de características y la operación que ha especificado. |
| Métrica | Description (Descripción) |
|---|---|
Invocations |
El número de solicitudes realizadas a las operaciones de tiempo de ejecución del almacén de características durante el periodo especificado. Unidades: ninguna Estadísticas válidas: Sum |
Operation4XXErrors |
El número de solicitudes realizadas a las operaciones de tiempo de ejecución del almacén de características en las que la operación devolvió un código de respuesta HTTP 4xx. Para cada respuesta 4xx, se envía 1; de lo contrario, se envía 0. Unidades: ninguna Estadísticas válidas: Average, Sum |
Operation5XXErrors |
El número de solicitudes realizadas a las operaciones de tiempo de ejecución del almacén de características en las que la operación devolvió un código de respuesta HTTP 5xx. Para cada respuesta 5xx, se envía 1; de lo contrario, se envía 0. Unidades: ninguna Estadísticas válidas: Average, Sum |
ThrottledRequests |
El número de solicitudes realizadas a las operaciones de tiempo de ejecución del almacén de características en las que se ha limitado la solicitud. Por cada solicitud limitada, se envía 1; de lo contrario, se envía 0. Unidades: ninguna Estadísticas válidas: Average, Sum |
Latency |
El intervalo de tiempo para procesar las solicitudes realizadas a las operaciones de tiempo de ejecución del almacén de características. Este intervalo se mide desde el momento en que SageMaker AI recibe la solicitud hasta que devuelve una respuesta al cliente. Unidades: microsegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count, Percentiles. |
| Dimensión | Description (Descripción) |
|---|---|
|
|
Filtra las métricas operativas de tiempo de ejecución del almacén de características del grupo de características y la operación que ha especificado. Puede utilizar estas dimensiones para operaciones que no sean por lotes GetRecord, como PutRecord, y DeleteRecord. |
OperationName |
Filtra las métricas operativas de tiempo de ejecución del almacén de características para la operación que ha especificado. Puede utilizar esta dimensión para operaciones por lotes como BatchGetRecord. |
SageMaker tuberías, métricas
El espacio de nombres AWS/Sagemaker/ModelBuildingPipeline contiene las siguientes métricas para las ejecuciones de canalizaciones.
Hay dos categorías de métricas de ejecución de canalizaciones disponibles:
-
Métricas de ejecución en todas las canalizaciones: métricas de ejecución de la canalización a nivel de cuenta (para todas las canalizaciones de la cuenta actual).
-
Métricas de ejecución por canalización: métricas de ejecución de la canalización por canalización.
Las métricas están disponibles con una frecuencia de un minuto.
| Métrica | Description (Descripción) |
|---|---|
ExecutionStarted |
El número de ejecuciones de la canalización que se iniciaron. Unidades: recuento Estadísticas válidas: Average, Sum |
ExecutionFailed |
El número de ejecuciones de la canalización que produjeron un error. Unidades: recuento Estadísticas válidas: Average, Sum |
ExecutionSucceeded |
El número de ejecuciones de la canalización que se realizaron correctamente. Unidades: recuento Estadísticas válidas: Average, Sum |
ExecutionStopped |
El número de ejecuciones de la canalización que se detuvieron. Unidades: recuento Estadísticas válidas: Average, Sum |
ExecutionDuration |
La duración en milisegundos de la ejecución de la canalización. Unidades: milisegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count. |
| Dimensión | Description (Descripción) |
|---|---|
PipelineName |
Filtra las métricas de ejecución por canalización específica. |
El espacio de nombres AWS/Sagemaker/ModelBuildingPipeline contiene las siguientes métricas para los pasos de la canalización.
Las métricas están disponibles con una frecuencia de un minuto.
| Métrica | Description (Descripción) |
|---|---|
StepStarted |
Número de pasos que se iniciaron. Unidades: recuento Estadísticas válidas: Average, Sum |
StepFailed |
Número de pasos que produjeron un error. Unidades: recuento Estadísticas válidas: Average, Sum |
StepSucceeded |
Número de pasos que se realizaron correctamente. Unidades: recuento Estadísticas válidas: Average, Sum |
StepStopped |
Número de pasos que se detuvieron. Unidades: recuento Estadísticas válidas: Average, Sum |
StepDuration |
La duración en milisegundos de la ejecución del paso. Unidades: milisegundos Estadísticas válidas: Average, Sum, Min, Max, Sample Count. |
| Dimensión | Description (Descripción) |
|---|---|
PipelineName, StepName |
Filtra las métricas de pasos de una canalización y un paso específicos. |
