Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Solución de problemas
Las siguientes preguntas frecuentes pueden ayudarle a solucionar problemas relacionados con los puntos de conexión de inferencia asíncrona de Amazon SageMaker.
Puede utilizar los siguientes métodos para buscar el número de instancias detrás del punto de conexión:
Puede utilizar la API DescribeEndpoint de SageMaker AI para describir el número de instancias detrás del punto de conexión en un punto determinado.
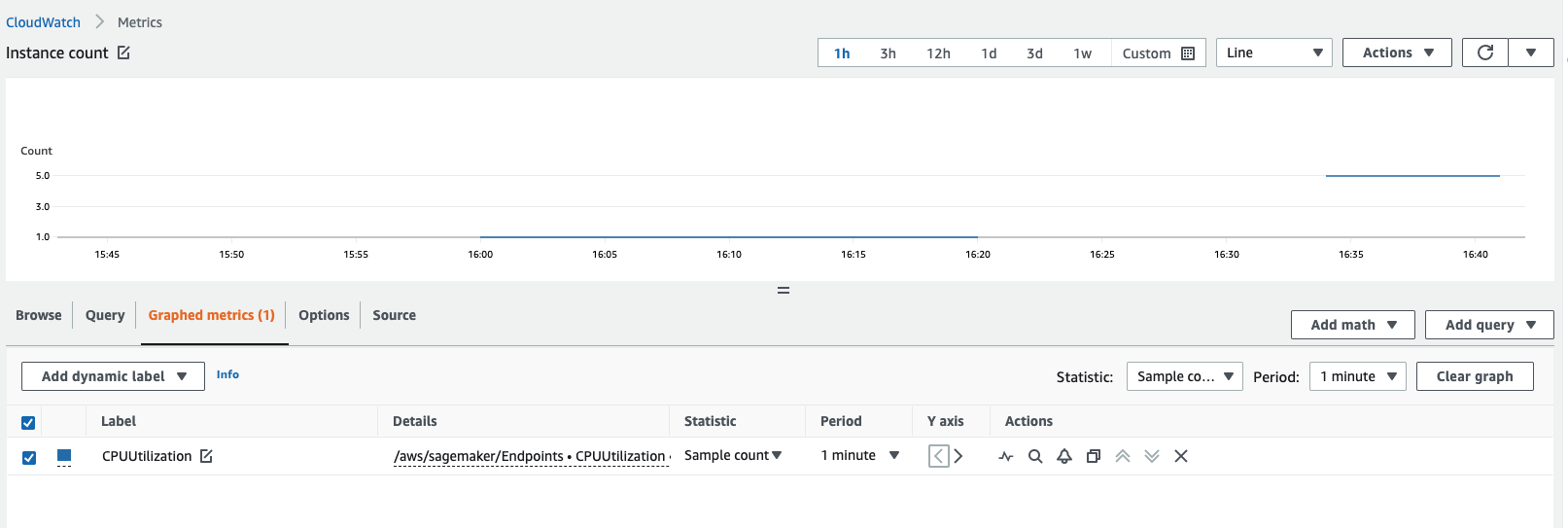
Puede obtener el recuento de instancias consultando las métricas de Amazon CloudWatch. Consulte las métricas de las instancias de punto de conexión, como
CPUUtilizationoMemoryUtilizationy compruebe la estadística del recuento de muestras para un período de 1 minuto. El recuento debe ser igual al número de instancias activas. En la siguiente captura de pantalla, se muestra la métricaCPUUtilizationrepresentada gráficamente en la consola de CloudWatch, donde Estadística se ha configurado enSample count, el Período se ha configurado en1 minutey el recuento resultante es 5.
En las tablas siguientes se describen las variables de entorno ajustables más comunes para los contenedores de SageMaker AI por tipo de marco.
TensorFlow
| Variable de entorno | Descripción |
|---|---|
|
|
Para los modelos basados en TensorFlow, el |
|
|
Este parámetro regula la fracción de memoria de la GPU disponible para inicializar CUDA/cuDNN y otras bibliotecas de GPU. |
|
Esto se relaciona de nuevo con la variable |
|
Esto se relaciona de nuevo con la variable |
|
Esto regula la cantidad de procesos de trabajo que se le pide a Gunicorn que genere para gestionar las solicitudes. Este valor se utiliza en combinación con otros parámetros para obtener un conjunto que maximice el rendimiento de las inferencias. Además de esto, |
|
Esto regula la cantidad de procesos de trabajo que se le pide a Gunicorn que genere para gestionar las solicitudes. Este valor se utiliza en combinación con otros parámetros para obtener un conjunto que maximice el rendimiento de las inferencias. Además de esto, |
|
Python usa internamente OpenMP para implementar subprocesos múltiples en los procesos. Por lo general, se generan subprocesos equivalentes a la cantidad de núcleos de la CPU. Sin embargo, cuando la implementación ocurre sobre el subprocesamiento múltiple simultáneo (SMT), como el HypeThreading de Intel, un proceso determinado puede sobresuscribir un núcleo determinado al generar el doble de subprocesos que el número real de núcleos de la CPU. En ciertos casos, un binario de Python puede terminar generando hasta cuatro veces más subprocesos que los núcleos de procesador disponibles. Por lo tanto, una configuración ideal para este parámetro, si ha sobresuscrito núcleos disponibles mediante subprocesos de trabajo, es |
|
|
En algunos casos, la desactivación de MKL puede acelerar la inferencia si |
PyTorch
| Variable de entorno | Descripción |
|---|---|
|
|
Este es el tiempo máximo de retraso por lote que TorchServe espera para recibir. |
|
|
Si TorchServe no recibe la cantidad de solicitudes especificadas en |
|
|
El número mínimo de procesos al que puede llegar TorchServe en la reducción. |
|
|
El número máximo de procesos al que puede llegar TorchServe en la ampliación. |
|
|
El tiempo de espera; tras este tiempo, se agota el tiempo de espera de la inferencia si no hay respuesta. |
|
|
Tamaño máximo de carga de TorchServe. |
|
|
Tamaño máximo de respuesta de TorchServe. |
Servidor multimodelo (MMS)
| Variable de entorno | Descripción |
|---|---|
|
|
Resulta útil ajustar este parámetro en situaciones en las que el tipo de carga de la solicitud de inferencia es grande; puesto que el tamaño de la carga es mayor, es posible que haya un consumo mayor de memoria de pila de la JVM en la que se mantiene esta cola. Lo ideal sería mantener bajos los requisitos de memoria de pila de la JVM y permitir que los procesos de trabajo de Python asignen más memoria para el suministro del modelo. La JVM solo sirve para recibir las solicitudes HTTP, ponerlas en cola y enviarlas a los procesos de trabajo basados en Python para la inferencia. Si aumenta el |
|
|
Este parámetro se usa para el servidor del modelo de backend. Podría resultar útil ajustarlo, ya que es el componente más importante en el suministro general del modelo; los procesos de Python se basan en esto a fin de generar subprocesos para cada modelo. Si este componente es más lento (o no está ajustado correctamente), es posible que el ajuste del frontend no sea efectivo. |
Puede usar el mismo contenedor para la inferencia asíncrona que para la inferencia en tiempo real o Batch Transform. Compruebe que los tiempos de espera y los límites de tamaño de la carga de su contenedor estén configurados para gestionar cargas más grandes y tiempos de espera más largos.
Consulte los siguientes límites para la inferencia asíncrona:
Límite de tamaño de carga: 1 GB.
Límite de tiempo de espera: una solicitud puede tardar hasta 60 minutos.
TimeToLive (TTL) de mensajes de cola: 6 horas.
Número de mensajes que se pueden incluir en Amazon SQS: ilimitado. Sin embargo, hay una cuota de 120 000 para el número de mensajes en tránsito para una cola estándar y de 20 000 para una cola FIFO.
En términos generales, con la inferencia asíncrona, puede escalar horizontalmente en función de las invocaciones o las instancias. En el caso de las métricas de invocación, es recomendable que consulte su ApproximateBacklogSize, una métrica que define el número de elementos de la cola que aún no se han procesado. Puede utilizar esta métrica o su métrica InvocationsPerInstance para determinar a qué TPS se limita el rendimiento. En el nivel de la instancia, compruebe el tipo de instancia y el uso de la CPU/GPU para definir cuándo escalar horizontalmente. A menudo, una instancia individual con una capacidad superior al 60 o 70 % es un buen indicativo de que se está saturando el hardware.
No recomendamos tener varias políticas de escalado, ya que pueden entrar en conflicto y generar confusión en el hardware, lo que podría provocar retrasos al escalar horizontalmente.
Compruebe si el contenedor puede gestionar a la vez solicitudes de ping e invocación. Las solicitudes de invocación de SageMaker AI tardan aproximadamente tres minutos; durante este tiempo, suele haber fallos en varias solicitudes de ping debido al tiempo de espera, lo que hace que SageMaker AI detecte el contenedor como Unhealthy.
Sí, MaxConcurrentInvocationsPerInstance es una característica de los puntos de conexión asíncronos. Esto no depende de la implementación del contenedor personalizado. MaxConcurrentInvocationsPerInstance controla la velocidad a la que se envían las solicitudes de invocación al contenedor del cliente. Si este valor se establece en 1, solo se envía una solicitud al contenedor a la vez, independientemente del número de trabajadores que haya en el contenedor del cliente.
Este error implica que el contenedor del cliente ha devuelto un error. SageMaker AI no controla el comportamiento de los contenedores de los clientes. SageMaker AI solo devuelve la respuesta de ModelContainer y no hace un nuevo intento. Si lo desea, puede configurar la invocación para que se vuelva a intentar en caso de error. Le sugerimos que active los registros de contenedores y que los revise a fin de encontrar la causa principal del error 500 del modelo. Revise también las métricas CPUUtilization y MemoryUtilization correspondientes en el punto de fallo. También puede configurar S3FailurePath hacia la respuesta del modelo en Amazon SNS como parte de las notificaciones de errores asíncronos a fin de investigar los errores.
Puede comprobar la métrica InvocationsProcesssed, que debería coincidir con el número de invocaciones que espera que se procesen en un minuto en función de la simultaneidad única.
El procedimiento recomendado consiste en habilitar Amazon SNS, que es un servicio de notificación para aplicaciones orientadas a la mensajería; los suscriptores solicitan y reciben notificaciones “push” de mensajes urgentes a través de distintos protocolos de transporte, como HTTP, Amazon SQS y el correo electrónico. La inferencia asíncrona publica notificaciones cuando crea un punto de conexión con CreateEndpointConfig y especifica un tema de Amazon ANS.
Para utilizar Amazon SNS a fin de revisar los resultados de las predicciones de su punto de conexión asíncrono, primero debe crear un tema, suscribirse a este, confirmar la suscripción y anotar el nombre de recurso de Amazon (ARN) de ese tema. Para obtener información detallada sobre cómo crear un tema de Amazon SNS, suscribirse a este y buscar su ARN de Amazon, consulte Configuración de Amazon SNS en la Guía para desarrolladores de Amazon SNS. Para obtener más información cobre cómo utilizar Amazon SNS con la inferencia asíncrona, consulte Check prediction results.
Sí. La inferencia asíncrona proporciona un mecanismo para reducir verticalmente hasta cero instancias cuando no hay solicitudes. Si el punto de conexión se ha reducido verticalmente a cero instancias durante estos períodos, no volverá a escalar hasta que el número de solicitudes en la cola supere el objetivo especificado en la política de escalado. Esto puede provocar largos tiempos de espera para las solicitudes en cola. En estos casos, si quiere escalar verticalmente desde cero instancias para nuevas solicitudes inferiores al objetivo de cola especificado, puedes usar una política de escalado adicional denominada HasBacklogWithoutCapacity. Para obtener más información acerca del modo de definir esta política de escalado, consulte Autoscale an asynchronous endpoint.
Para obtener una lista completa de las instancias compatibles con la inferencia asíncrona por región, consulte Precios de Amazon SageMaker
