Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Pasos de preparación de datos
La experiencia de preparación de datos de Amazon Quick Sight ofrece once tipos de pasos eficaces que le permiten transformar sus datos de forma sistemática. Cada paso tiene un propósito específico en el flujo de trabajo de preparación de datos.
Los pasos se pueden configurar a través de una interfaz intuitiva en el panel de configuración, con comentarios inmediatos visibles en el panel de vista previa. Los pasos se pueden combinar de forma secuencial para crear transformaciones de datos sofisticadas sin necesidad de conocimientos de SQL.
Cada paso puede recibir datos de una tabla física o del resultado de un paso anterior. La mayoría de los pasos aceptan una sola entrada, con la excepción de los pasos Añadir y Unir, que requieren exactamente dos entradas.
Input
El paso de entrada inicia el flujo de trabajo de preparación de datos en Quick Sight, ya que le permite seleccionar e importar datos de varias fuentes para transformarlos en los pasos siguientes.
Opciones de entrada
-
Añadir conjunto de datos
Aproveche los conjuntos de datos de Quick Sight existentes como fuentes de entrada y aproveche los datos que su equipo ya ha preparado y optimizado.
-
Agregue una fuente de datos
Conéctese directamente a bases de datos como Amazon Redshift, Athena, RDS u otras fuentes compatibles seleccionando objetos de base de datos específicos y proporcionando parámetros de conexión.
-
Añadir carga de archivos
Importa datos directamente desde archivos locales en formatos como CSV, TSV, Excel o JSON.
Configuración
El paso de entrada no requiere configuración. El panel de vista previa muestra los datos importados junto con la información de origen, incluidos los detalles de la conexión, el nombre de la tabla y los metadatos de las columnas.
Notas de uso
-
Pueden existir varios pasos de entrada en un mismo flujo de trabajo.
-
Puede añadir pasos de entrada en cualquier punto de su flujo de trabajo.
Agregue columnas calculadas
El paso Añadir columnas calculadas le permite crear columnas nuevas mediante expresiones de nivel de fila que realizan cálculos en las columnas existentes. Puede crear columnas nuevas mediante funciones y operadores escalares (a nivel de fila) y aplicar cálculos a nivel de fila que hagan referencia a las columnas existentes.
Configuración
Para configurar el paso Agregar columnas calculadas, en el panel de configuración:
-
Asigne un nombre a la nueva columna calculada.
-
Guarde el cálculo.
-
Obtenga una vista previa de los resultados de la expresión.
-
Añada más columnas calculadas según sea necesario.
Notas de uso
-
En este paso solo se admiten cálculos escalares (a nivel de fila).
-
En SPICE, las columnas calculadas se materializan y funcionan como columnas estándar en los pasos siguientes.
Cambie el tipo de datos
Quick Sight simplifica la administración de los tipos de datos al admitir cuatro tipos de datos abstractos: datedecimal,integer, ystring. Estos tipos abstractos eliminan la complejidad al asignar automáticamente varios tipos de datos de origen a sus equivalentes de Quick Sight. Por ejemplo,, tinyint smallintinteger, y bigint están todos mapeados ainteger, mientras que datedatetime, y timestamp están mapeados a. date
Esta abstracción significa que solo necesita entender los cuatro tipos de datos de Quick Sight, ya que Quick Sight gestiona automáticamente todas las conversiones y cálculos de los tipos de datos subyacentes al interactuar con diferentes fuentes de datos.
Configuración
Para configurar el paso Cambiar el tipo de datos, en el panel de configuración:
-
Seleccione la columna que desee convertir.
-
Elija el tipo de datos de destino (
stringinteger,decimal, odate). -
Para las conversiones de fecha, especifique la configuración del formato y obtenga una vista previa de los resultados en función de los formatos de entrada. Consulte los formatos de fecha compatibles en Quick Sight.
-
Agregue columnas adicionales para convertirlas según sea necesario.
Notas de uso
-
Convierta los tipos de datos de varias columnas en un solo paso para aumentar la eficiencia.
-
Al utilizar SPICE, todos los cambios en los tipos de datos se materializan en los datos importados.
Cambie el nombre de las columnas
El paso Cambiar el nombre de las columnas le permite modificar los nombres de las columnas para que sean más descriptivos, fáciles de usar y coherentes con las convenciones de nomenclatura de su organización.
Configuración
Para configurar el paso Cambiar el nombre de las columnas, en el panel de configuración:
-
Seleccione una columna para asignarle un nombre.
-
Introduzca un nombre nuevo para la columna seleccionada.
-
Añada más columnas para cambiarles el nombre según sea necesario.
Notas de uso
-
Todos los nombres de las columnas deben ser únicos en el conjunto de datos.
Selecciona Columnas
El paso Seleccionar columnas le permite optimizar su conjunto de datos al incluir, excluir y reordenar las columnas. Esto ayuda a optimizar la estructura de datos al eliminar las columnas innecesarias y organizar las restantes en una secuencia lógica para su análisis.
Configuración
Para configurar el paso Seleccionar columnas, en el panel de configuración:
-
Elija columnas específicas para incluirlas en la salida.
-
Seleccione las columnas en el orden que prefiera para establecer la secuencia.
-
Use Seleccionar todo para incluir las columnas restantes en su orden original.
-
Excluya las columnas no deseadas dejándolas sin seleccionar.
Características principales
-
Las columnas de salida aparecen en el orden de selección.
-
La opción Seleccionar todo conserva la secuencia de columnas original.
Notas de uso
-
Las columnas no seleccionadas se eliminan de los pasos siguientes.
-
Optimice el tamaño del conjunto de datos eliminando las columnas innecesarias.
Anexar
El paso Añadir combina verticalmente dos tablas, de forma similar a una operación UNION ALL de SQL. Quick Sight hace coincidir automáticamente las columnas por nombre y no por secuencia, lo que permite una consolidación de datos eficiente incluso cuando las tablas tienen diferentes órdenes de columnas o números de columnas variables.
Configuración
Para configurar el paso Añadir, en el panel de configuración:
-
Seleccione dos tablas de entrada para anexarlas.
-
Revise la secuencia de columnas de salida.
-
Examine qué columnas están presentes en ambas tablas o en las tablas individuales.
Características principales
-
Hace coincidir las columnas por nombre en lugar de por secuencia.
-
Conserva todas las filas de ambas tablas, incluidos los duplicados.
-
Admite tablas con diferentes números de columnas.
-
Sigue la secuencia de columnas de la Tabla 1 para las columnas coincidentes y, a continuación, agrega columnas únicas de la Tabla 2.
-
Muestra indicadores de origen claros para todas las columnas
Notas de uso
-
Utilice primero el paso de cambio de nombre cuando añada columnas con nombres diferentes.
-
Cada paso de adición combina exactamente dos tablas; utilice los pasos de adición adicionales para obtener más tablas.
Join
El paso Unir combina horizontalmente los datos de dos tablas en función de los valores coincidentes de las columnas especificadas. Quick Sight admite los tipos de unión exterior izquierda, exterior derecha, exterior completa e interior, lo que proporciona opciones flexibles para sus necesidades analíticas. Este paso incluye la resolución inteligente de conflictos de columnas que gestiona automáticamente los nombres de columna duplicados. Si bien las uniones automáticas no están disponibles como un tipo de unión específico, se pueden obtener resultados similares si se utiliza la divergencia del flujo de trabajo.
Configuración
Para configurar el paso de unión, en el panel de configuración:
-
Seleccione dos tablas de entrada para unirlas.
-
Elija el tipo de unión (exterior izquierda, exterior derecha, exterior completa o interior).
-
Especifique las claves de unión de cada tabla.
-
Revise los conflictos de nombres de columnas que se resuelven automáticamente.
Características principales
-
Admite varios tipos de uniones para diferentes necesidades analíticas.
-
Resuelve automáticamente los nombres de columnas duplicados.
-
Acepta columnas calculadas como claves de unión.
Notas de uso
-
Las claves de unión deben tener tipos de datos compatibles; utilice el paso Cambiar tipo de datos si es necesario.
-
Cada paso de unión combina exactamente dos tablas; utilice pasos de unión adicionales para obtener más tablas.
-
Cree un paso de cambio de nombre después de la unión para personalizar los encabezados de las columnas que se resuelven automáticamente.
Agregado
El paso Agregar permite resumir los datos agrupando columnas y aplicando operaciones de agregación. Esta poderosa transformación condensa los datos detallados en resúmenes significativos basados en las dimensiones especificadas. Quick Sight simplifica las operaciones SQL complejas a través de una interfaz intuitiva, que ofrece funciones de agregación integrales que incluyen operaciones de cadenas avanzadas como y. ListAgg ListAgg distinct
Configuración
Para configurar el paso de agregación, en el panel de configuración:
-
Seleccione las columnas por las que desee agruparlas.
-
Elija funciones de agregación para las columnas de medidas.
-
Personalice los nombres de las columnas de salida.
-
Para
ListAggyListAgg distinct:-
Seleccione la columna que desee agregar.
-
Elija un separador (coma, guión, punto y coma o línea vertical).
-
-
Obtenga una vista previa de los datos resumidos.
Funciones compatibles por tipo de datos
| Tipo de datos | Funciones compatibles |
|---|---|
|
Numérico |
|
|
Date |
|
|
Cadena |
|
Características principales
-
Aplica diferentes funciones de agregación a las columnas del mismo paso.
-
Agrupar por sin funciones de agregación actúa como SQL SELECT DISTINCT.
-
ListAggconcatena todos los valores;ListAgg distinctincluye solo valores únicos. -
ListAgglas funciones mantienen un orden de clasificación ascendente de forma predeterminada.
Notas de uso
-
La agregación reduce significativamente el número de filas en el conjunto de datos.
-
ListAggyListAgg distinctadmitendatevalores, pero nodatetime. -
Utilice separadores para personalizar el resultado de la concatenación de cadenas.
Filtro
El paso de filtrado le permite restringir el conjunto de datos al incluir solo las filas que cumplen criterios específicos. Puede aplicar varias condiciones de filtrado en un solo paso, y combinarlas mediante la AND lógica para ayudar a centrar el análisis en los datos relevantes.
Configuración
Para configurar el paso de filtrado, en el panel de configuración:
-
Seleccione una columna para filtrar.
-
Elija un operador de comparación.
-
Especifique los valores del filtro en función del tipo de datos de la columna.
-
Agregue condiciones de filtro adicionales en diferentes columnas si es necesario.
nota
-
Filtrar filtros con «está dentro» o «no está dentro»: introduzca varios valores (uno por línea).
-
Filtros numéricos y de fecha: introduzca valores únicos (excepto «entre», que requiere dos valores).
Operadores compatibles por tipo de datos
| Tipo de datos | Operadores admitidos |
|---|---|
|
Número entero y decimal |
Es igual, no es igual Mayor que, menor que Es mayor o igual que, es menor o igual que Está entre |
|
Date |
¿Después, antes Está entre Es posterior o igual a, Es anterior o igual a |
|
Cadena |
Es igual, no es igual Empieza con, termina con Contiene, no contiene Está dentro, no está dentro |
Notas de uso
-
Aplique varias condiciones de filtrado en un solo paso.
-
Mezcle condiciones en distintos tipos de datos.
-
Obtenga una vista previa de los resultados filtrados en tiempo real.
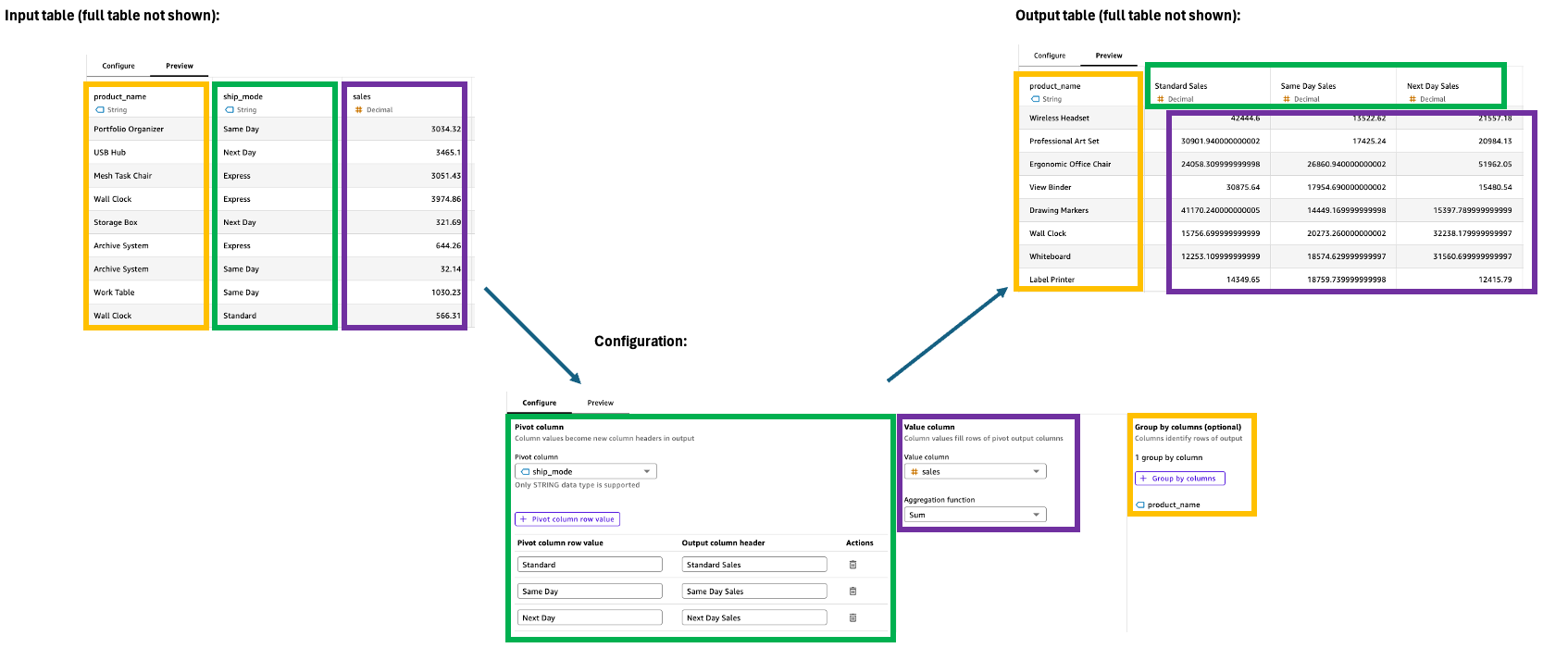
Pivot
El paso dinámico transforma los valores de las filas en columnas únicas y convierte los datos de un formato largo a uno ancho para facilitar la comparación y el análisis. Esta transformación requiere especificaciones de filtrado, agregación y agrupación de valores para gestionar las columnas de salida de forma eficaz.
Configuración
Para configurar el paso dinámico, utilice lo siguiente en el panel de configuración:
-
Columna dinámica: seleccione la columna cuyos valores se convertirán en encabezados de columna (por ejemplo, Categoría).
-
Valor de fila de la columna dinámica: filtre los valores específicos para incluirlos (por ejemplo, tecnología o material de oficina).
-
Encabezado de columna de salida: personalice los nuevos encabezados de columna (de forma predeterminada, los valores de las columnas pivotantes).
-
Columna de valores: seleccione la columna que desee agregar (p. ej., Ventas).
-
Función de agregación: elija el método de agregación (por ejemplo, suma).
-
Agrupar por: especifique las columnas organizativas (por ejemplo, Segmento).
Operadores compatibles por tipo de datos
| Tipo de datos | Operadores admitidos |
|---|---|
|
Número entero y decimal |
|
|
Date |
|
|
Cadena |
|
Notas de uso
-
Cada columna pivotada contiene valores agregados de la columna de valores.
-
Personalice los encabezados de las columnas para mayor claridad.
-
Previsualice los resultados de la transformación en tiempo real.
Despivote
El paso Unpivot transforma las columnas en filas y convierte los datos anchos en un formato más largo y estrecho. Esta transformación ayuda a organizar los datos repartidos en varias columnas en un formato más estructurado para facilitar el análisis y la visualización.
Configuración
Para configurar el paso Unpivot, en el panel de configuración:
-
Seleccione las columnas para separarlas y convertirlas en filas.
-
Defina los valores de las filas de las columnas de salida. El valor predeterminado es el nombre de la columna original. Algunos ejemplos incluyen tecnología, material de oficina y mobiliario.
-
Asigne un nombre a las dos nuevas columnas de resultados.
-
Encabezado de columna no pivotado: el nombre de los nombres de columnas anteriores (por ejemplo, Categoría)
-
Valores de columna no pivotantes: el nombre de los valores no pivotantes (por ejemplo, Ventas)
-

Características principales
-
Conserva todas las columnas no pivotantes de la salida.
-
Crea dos columnas nuevas automáticamente: una para los nombres de columnas anteriores y otra para sus valores correspondientes.
-
Transforma los datos anchos en formato largo.
Notas de uso
-
Todas las columnas no pivotantes deben tener tipos de datos compatibles.
-
El número de filas suele aumentar después de no pivotar.
-
Obtenga una vista previa de los cambios en tiempo real antes de aplicarlos.
