Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Escalado de la capacidad del clúster
Si el trabajo tarda demasiado tiempo, pero los ejecutores consumen suficientes recursos y Spark crea un gran volumen de tareas en relación con los núcleos disponibles, considere la posibilidad de escalar la capacidad del clúster. Para evaluar si esto es apropiado, use las siguientes métricas.
CloudWatch métricas
-
Consulte Carga de la CPU y Utilización de la memoria para determinar si los ejecutores consumen recursos suficientes.
-
Compruebe cuánto tiempo se ha ejecutado el trabajo para evaluar si el tiempo de procesamiento es demasiado largo para cumplir con sus objetivos de rendimiento.
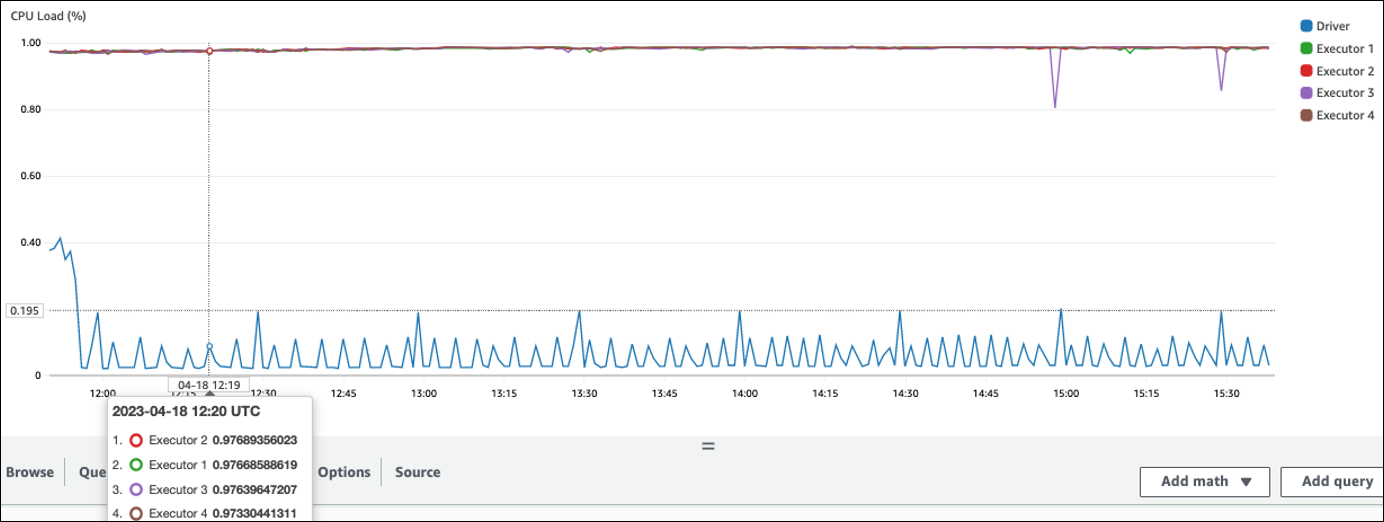
En el siguiente ejemplo, cuatro ejecutores se ejecutan con una carga de CPU superior al 97 %, pero el procesamiento no se ha completado después de unas tres horas.
nota
Si la carga de la CPU es baja, probablemente no se beneficie del escalado de la capacidad del clúster.
UI de Spark
En las pestañas Trabajo o Etapa, puede ver el número de tareas de cada trabajo o etapa. En el siguiente ejemplo, Spark ha creado 58100 tareas.

En la pestaña Ejecutor, puede ver el número total de ejecutores y tareas. En la siguiente captura de pantalla, cada ejecutor de Spark tiene cuatro núcleos y puede llevar a cabo cuatro tareas simultáneamente.
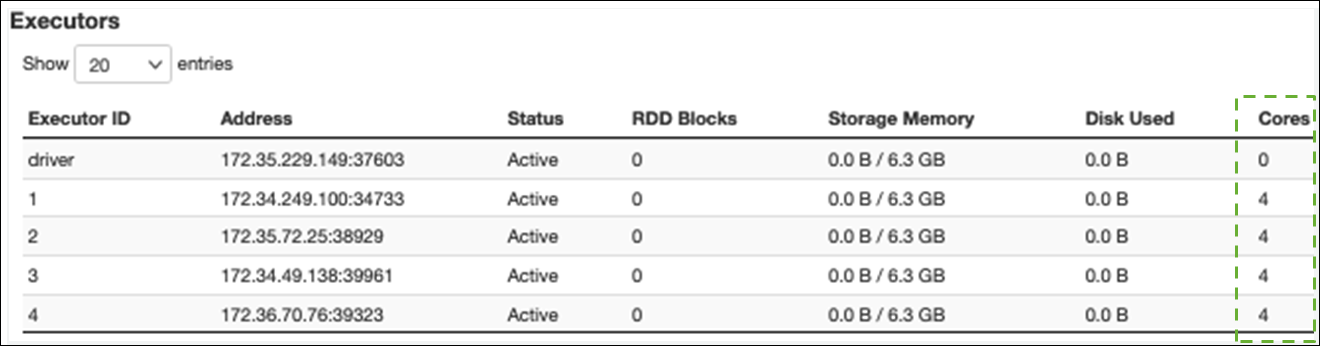
En este ejemplo, el número de tareas de Spark (58100) es mucho mayor que las 16 tareas que los ejecutores pueden procesar simultáneamente (4 ejecutores × 4 núcleos).
Si observa estos síntomas, considere la posibilidad de escalar el clúster. Puede escalar la capacidad del clúster mediante las siguientes opciones:
-
Activar AWS Glue Auto Scaling: Auto Scaling está disponible para sus trabajos de AWS Glue extracción, transformación y carga (ETL) y de streaming en la AWS Glue versión 3.0 o posterior. AWS Glue agrega y elimina automáticamente trabajadores del clúster en función del número de particiones en cada etapa o de la velocidad a la que se generan los microlotes durante la ejecución del trabajo.
Si observa una situación en la que el número de nodos de trabajo no aumenta aunque el escalado automático esté habilitado, considere la posibilidad de agregar nodos de trabajo manualmente. Sin embargo, tenga en cuenta que escalar manualmente para una etapa puede provocar que muchos nodos de trabajo permanezcan inactivos durante las etapas posteriores, lo que podría costar más y no aumentar el rendimiento.
Después de activar Auto Scaling, puede ver el número de ejecutores en las métricas del CloudWatch ejecutor. Utilice las siguientes métricas para supervisar la demanda de ejecutores en las aplicaciones de Spark:
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors -
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
Para obtener más información sobre las métricas, consulta Cómo monitorizar AWS Glue con CloudWatch las métricas de Amazon.
-
-
Escalado horizontal: aumento del número de nodos de trabajo de AWS Glue : puede aumentar el número de nodos de trabajo de AWS Glue de forma manual. Agregue nodos de trabajo solo hasta que observe nodos de trabajo inactivos. En ese momento, agregar más nodos de trabajo aumentará los costos sin mejorar los resultados. Para obtener más información, consulte Paralelización de las tareas.
-
Amplíe: utilice un tipo de trabajador más grande: puede cambiar manualmente el tipo de instancia de sus AWS Glue trabajadores para utilizar trabajadores con más núcleos, memoria y almacenamiento. Los tipos de nodos de trabajo más grandes le permiten escalar verticalmente y ejecutar tareas de integración de datos intensivas, como transformaciones de datos que consumen mucha memoria, agregaciones sesgadas y comprobaciones de detección de entidades con petabytes de datos.
El escalado vertical también ayuda en los casos en que el controlador de Spark necesita una mayor capacidad, por ejemplo, porque el plan de consultas del trabajo es bastante grande. Para obtener más información sobre los tipos de trabajadores y su rendimiento, consulte la entrada del blog sobre AWS macrodatos: amplíe sus trabajos AWS Glue para Apache Spark con nuevos tipos de trabajadores más grandes G.4X y G.8X
. El uso de nodos de trabajo más grandes también puede reducir la cantidad total de nodos de trabajo necesarios, lo que aumenta el rendimiento al reducir la mezcla en operaciones intensivas, como las uniones.
