Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
# Paralelización de las tareas
Para optimizar el rendimiento, es importante paralelizar las tareas de carga y transformación de datos. Como explicamos en [Temas clave de Apache Spark](key-topics-apache-spark.md), el número de particiones de conjuntos de datos distribuidos resilientes (RDD) es importante porque determina el grado de paralelismo. Cada tarea que crea Spark corresponde a una partición de RDD de forma 1:1. Para lograr el mejor rendimiento, debe entender cómo se determina el número de particiones de RDD y cómo se optimiza ese número.
Si no tienes suficiente paralelismo, los siguientes síntomas se registrarán en las [CloudWatchmétricas](https://docs.aws.amazon.com/glue/latest/dg/monitoring-awsglue-with-cloudwatch-metrics.html) y en la interfaz de usuario de Spark.
## CloudWatch métricas
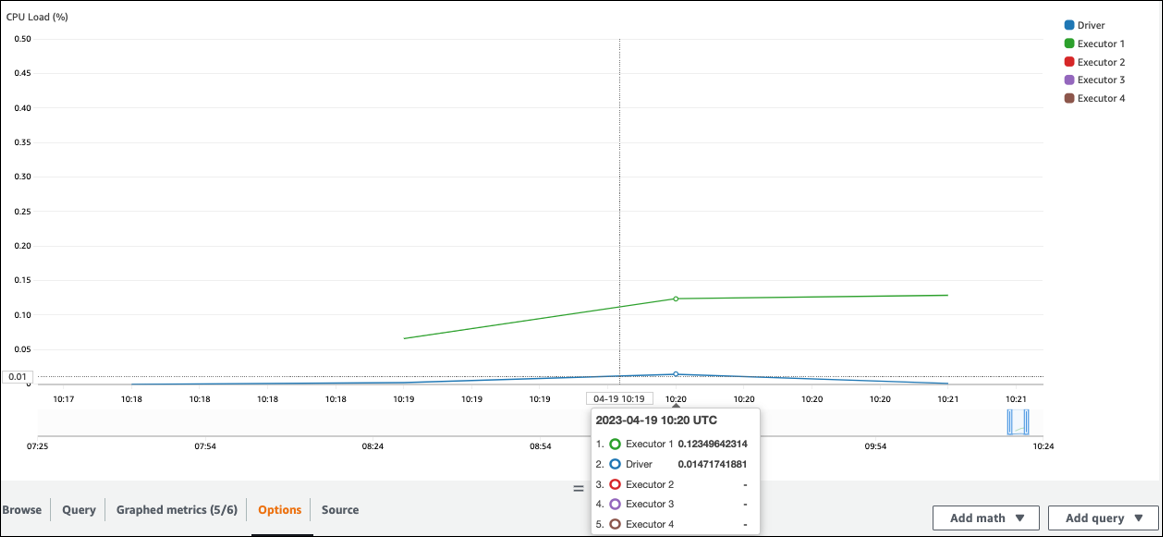
Consulte **Carga de la CPU** y **Utilización de la memoria**. Si algunos ejecutores no se procesan durante una fase de su trabajo, es conveniente mejorar el paralelismo. En este caso, durante el periodo de tiempo visualizado, el **ejecutor 1** estaba llevando a cabo una tarea, pero los ejecutores restantes (2, 3 y 4) no. Se puede deducir que el controlador de Spark no asignó tareas a esos ejecutores.
## UI de Spark
En la pestaña **Etapa** de la IU de Spark, puede ver** **el* número de tareas *de una etapa. En este caso, Spark solo ha llevado a cabo una tarea.

Además, en el cronograma del evento se muestra al **ejecutor 1** procesando una tarea. Esto significa que el trabajo de esta etapa se ejecutó íntegramente con un ejecutor, mientras que los demás estaban inactivos.

Si observa estos síntomas, pruebe las siguientes soluciones para cada origen de datos.
### Paralelización de la carga de datos desde Amazon S3
Para paralelizar las cargas de datos de Amazon S3, compruebe primero el número predeterminado de particiones. A continuación, puede determinar manualmente el número objetivo de particiones, pero asegúrese de evitar tener demasiadas particiones.
*Determinación del número predeterminado de particiones*
En Amazon S3, el número inicial de particiones de RDD de Spark (cada una de las cuales corresponde a una tarea de Spark) se determina según las características del conjunto de datos de Amazon S3 (por ejemplo, el formato, la compresión y el tamaño). Al crear un Spark AWS Glue DynamicFrame o un Spark DataFrame a partir de objetos CSV almacenados en Amazon S3, el número inicial de particiones RDD (`NumPartitions`) se puede calcular aproximadamente de la siguiente manera:
+ Tamaño del objeto <= 64 MB: `NumPartitions = Number of Objects`
+ Tamaño del objeto > 64 MB: `NumPartitions = Total Object Size / 64 MB`
+ No se puede dividir (gzip): `NumPartitions = Number of Objects`
Como se explica en la sección [Reducción de la cantidad de análisis de datos](reduce-data-scan.md), Spark divide los objetos de S3 grandes en divisiones que se pueden procesar en paralelo. Cuando el objeto es más grande que el tamaño de la división, Spark divide el objeto y crea una partición de RDD (y una tarea) para cada división. El tamaño de división de Spark se basa en el formato de datos y el entorno del tiempo de ejecución, pero esta es una aproximación inicial razonable. Algunos objetos se comprimen con formatos de compresión que no se pueden dividir, como gzip, por lo que Spark no puede dividirlos.
El `NumPartitions` valor puede variar en función del formato de datos, la compresión, la AWS Glue versión, el número de AWS Glue trabajadores y la configuración de Spark.
Por ejemplo, cuando cargas un único `csv.gz` objeto de 10 GB con un Spark DataFrame, el controlador de Spark solo creará una partición RDD (`NumPartitions=1`) porque gzip no se puede dividir. Esto supone una gran carga para un ejecutor de Spark en concreto y no se asigna ninguna tarea a los ejecutores restantes, como se describe en la siguiente figura.
Consulte el número real de tareas (`NumPartitions`) de la etapa en la pestaña **Etapa** de la [IU web de Spark](https://docs.aws.amazon.com/glue/latest/dg/monitor-spark-ui.html) o ejecute `df.rdd.getNumPartitions()` en su código para comprobar el paralelismo.
Cuando encuentre un archivo gzip de 10 GB, compruebe si el sistema que lo genera puede generarlo en un formato divisible. Si no es una opción, es posible que tenga que [escalar la capacidad del clúster](scale-cluster-capacity.md) para procesar el archivo. Para ejecutar las transformaciones de forma eficaz en los datos que ha cargado, tendrá que reequilibrar el RDD entre los nodos de trabajo del clúster mediante la repartición.
*Determinación manual del número objetivo de particiones*
En función de las propiedades de sus datos y de la implementación de determinadas funcionalidades por parte de Spark, es posible que acabe con un valor de `NumPartitions` bajo, aunque el trabajo subyacente aún se pueda paralelizar. Si `NumPartitions` es demasiado pequeño, ejecute `df.repartition(N)` para aumentar el número de particiones y poder distribuir el procesamiento entre varios ejecutores de Spark.
En este caso, la ejecución de `df.repartition(100)` aumentará el valor de `NumPartitions` de 1 a 100, lo que generará 100 particiones de sus datos, cada una con una tarea que podrá asignarse a los demás ejecutores.
La operación `repartition(N)` divide todos los datos en partes iguales (10 GB / 100 particiones = 100 MB/partición), lo que evita que los datos se sesguen hacia determinadas particiones.
**nota**
Cuando se ejecuta una operación de mezcla como `join`, el número de particiones aumenta o disminuye de forma dinámica en función del valor de `spark.sql.shuffle.partitions` o `spark.default.parallelism`. Esto facilita un intercambio de datos más eficiente entre los ejecutores de Spark. Para obtener más información, consulte la [documentación de Spark](https://spark.apache.org/docs/latest/configuration.html#runtime-sql-configuration).
Al determinar el número objetivo de particiones, tu objetivo es maximizar el uso de los trabajadores aprovisionados. AWS Glue El número de AWS Glue trabajadores y el número de tareas de Spark se relacionan mediante el número de vCPUs. Spark admite una tarea para cada núcleo de vCPU. En AWS Glue la versión 3.0 o posterior, puedes calcular el número objetivo de particiones mediante la siguiente fórmula.
```
# Calculate NumPartitions by WorkerType
numExecutors = (NumberOfWorkers - 1)
numSlotsPerExecutor =
4 if WorkerType is G.1X
8 if WorkerType is G.2X
16 if WorkerType is G.4X
32 if WorkerType is G.8X
NumPartitions = numSlotsPerExecutor * numExecutors
# Example: Glue 4.0 / G.1X / 10 Workers
numExecutors = ( 10 - 1 ) = 9 # 1 Worker reserved on Spark Driver
numSlotsPerExecutor = 4 # G.1X has 4 vCpu core ( Glue 3.0 or later )
NumPartitions = 9 * 4 = 36
```
En este ejemplo, cada nodo de trabajo G.1X proporciona cuatro núcleos de vCPU a un ejecutor de Spark (`spark.executor.cores = 4`). Spark admite una tarea para cada núcleo de vCPU, por lo que los ejecutores G.1X de Spark pueden ejecutar cuatro tareas simultáneamente (`numSlotPerExecutor`). Este número de particiones aprovecha al máximo el clúster si las tareas tardan el mismo tiempo. Sin embargo, algunas tareas tardarán más que otras y se crearán núcleos inactivos. Si esto ocurre, considere la posibilidad de multiplicar `numPartitions` por 2 o 3 para dividir y programar de manera eficiente las tareas que producen los cuellos de botella.
*Demasiadas particiones*
Un número excesivo de particiones crea un número excesivo de tareas. Esto provoca una gran carga en el controlador de Spark debido a la sobrecarga relacionada con el procesamiento distribuido, como las tareas de administración y el intercambio de datos entre los ejecutores de Spark.
Si el número de particiones de su trabajo es considerablemente mayor que el número objetivo de particiones, considere la posibilidad de reducir el número de particiones. Puede reducir las particiones mediante las siguientes opciones:
+ Si el tamaño de los archivos es muy pequeño, utilice AWS Glue [GroupFiles](https://docs.aws.amazon.com/glue/latest/dg/grouping-input-files.html). Puede reducir el paralelismo excesivo que resulta del lanzamiento de una tarea de Apache Spark para procesar cada archivo.
+ Use `coalesce(N)` para fusionar las particiones. Se trata de un proceso de bajo costo. A la hora de reducir el número de particiones, `coalesce(N)` se prefiere en lugar de `repartition(N)`, ya que `repartition(N)` lleva a cabo una mezcla para distribuir equitativamente la cantidad de registros de cada partición. Esto aumenta los costos y la sobrecarga administrativa.
+ Utilice la ejecución adaptativa de consultas de Spark 3.x. Como se explica en la sección [Temas clave de Apache Spark](key-topics-apache-spark.md), la ejecución adaptativa de consultas proporciona una función para fusionar automáticamente el número de particiones. Puede usar este enfoque cuando no sepa el número de particiones hasta llevar a cabo la ejecución.
### Paralelización de la carga de datos desde JDBC
El número de particiones de RDD de Spark se determina según la configuración. Tenga en cuenta que, de forma predeterminada, solo se ejecuta una tarea para analizar un conjunto de datos de origen completo mediante una consulta `SELECT`.
AWS Glue DynamicFrames Tanto Spark como Spark DataFrames admiten la carga de datos JDBC paralelizada en múltiples tareas. Esto se hace mediante predicados `where` para dividir una consulta `SELECT` en varias consultas. Para paralelizar las lecturas de JDBC, configure las siguientes opciones:
+ Para AWS Glue DynamicFrame, establece (o) y. `hashfield` `hashexpression)` `hashpartition` Para obtener más información, consulte [Lectura desde tablas de JDBC en paralelo](https://docs.aws.amazon.com/glue/latest/dg/run-jdbc-parallel-read-job.html).
```
connection_mysql8_options = {
"url": "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test",
"dbtable": "medicare_tb",
"user": "test",
"password": "XXXXXXXXX",
"hashexpression":"id",
"hashpartitions":"10"
}
datasource0 = glueContext.create_dynamic_frame.from_options(
'mysql',
connection_options=connection_mysql8_options,
transformation_ctx= "datasource0"
)
```
+ Para Spark DataFrame, establece `numPartitions``partitionColumn`,`lowerBound`, y`upperBound`. Para obtener más información, consulte [JDBC To Other Databases](https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html).
```
df = spark.read \
.format("jdbc") \
.option("url", "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test") \
.option("dbtable", "medicare_tb") \
.option("user", "test") \
.option("password", "XXXXXXXXXX") \
.option("partitionColumn", "id") \
.option("numPartitions", "10") \
.option("lowerBound", "0") \
.option("upperBound", "1141455") \
.load()
df.write.format("json").save("s3://bucket_name/Tests/sparkjdbc/with_parallel/")
```
### Paralelización de la carga de datos de DynamoDB al utilizar el conector de ETL
El número de particiones de RDD de Spark se determina según el parámetro `dynamodb.splits`. Para paralelizar las lecturas de Amazon DynamoDB, configure las siguientes opciones:
+ Aumente el valor de `dynamodb.splits`.
+ Optimice el parámetro siguiendo la fórmula explicada en [Tipos y opciones de conexión para ETL en AWS Glue Spark](https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-connect.html#aws-glue-programming-etl-connect-dynamodb).
### Paralelización de la carga de datos de Kinesis Data Streams
El número de particiones de RDD de Spark se determina según el número de particiones del flujo de datos de Amazon Kinesis Data Streams de origen. Si solo tiene unas pocas particiones en su flujo de datos, solo habrá unas pocas tareas de Spark. Esto puede provocar un bajo paralelismo en los procesos posteriores. Para paralelizar las lecturas de Kinesis Data Streams, configure las siguientes opciones:
+ Aumente el número de particiones para obtener más paralelismo al cargar datos de Kinesis Data Streams.
+ Si la lógica del microlote es lo suficientemente compleja, considere la posibilidad de volver a particionar los datos al principio del lote, después de eliminar las columnas innecesarias.
Para obtener más información, consulta [las prácticas recomendadas para optimizar el coste y el rendimiento de la AWS Glue transmisión de trabajos de ETL](https://aws.amazon.com/blogs/big-data/best-practices-to-optimize-cost-and-performance-for-aws-glue-streaming-etl-jobs/).
### Paralelización de las tareas después de la carga de datos
Para paralelizar las tareas después de la carga de datos, aumente el número de particiones de RDD mediante las siguientes opciones:
+ Vuelva a particionar los datos para generar un mayor número de particiones, especialmente justo después de la carga inicial si la carga en sí no se pudo paralelizar.
Llame a `repartition()` DynamicFrame o DataFrame especifique el número de particiones. Una buena regla general es multiplicar por dos o tres el número de núcleos disponibles.
Sin embargo, al escribir una tabla particionada, esto puede provocar una explosión de archivos (cada partición puede generar un archivo en cada partición de la tabla). Para evitarlo, puedes reparticionar tu columna DataFrame por columnas. Esto utiliza las columnas de partición de la tabla para que los datos se organicen antes de escribirlos. Puede especificar un número mayor de particiones sin tener archivos pequeños en las particiones de la tabla. Sin embargo, tenga cuidado para evitar el sesgo de datos, ya que algunos valores de partición acaban con la mayoría de los datos y se retrasa la finalización de la tarea.
+ Cuando haya mezclas, aumente el valor de `spark.sql.shuffle.partitions`. Esto también puede ayudar a solucionar cualquier problema de memoria durante la mezcla.
Cuando tiene más de 2001 particiones de mezcla, Spark utiliza un formato de memoria comprimido. Si tiene un número cercano a ese valor, quizás quiera establecer el valor de `spark.sql.shuffle.partitions` por encima de ese límite para obtener una representación más eficiente.