Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Temas clave de Apache Spark
En esta sección se explican los conceptos básicos de Apache Spark y los temas clave AWS Glue para ajustar el rendimiento de Apache Spark. Es importante entender estos conceptos y temas antes de analizar las estrategias de ajuste del mundo real.
Arquitectura
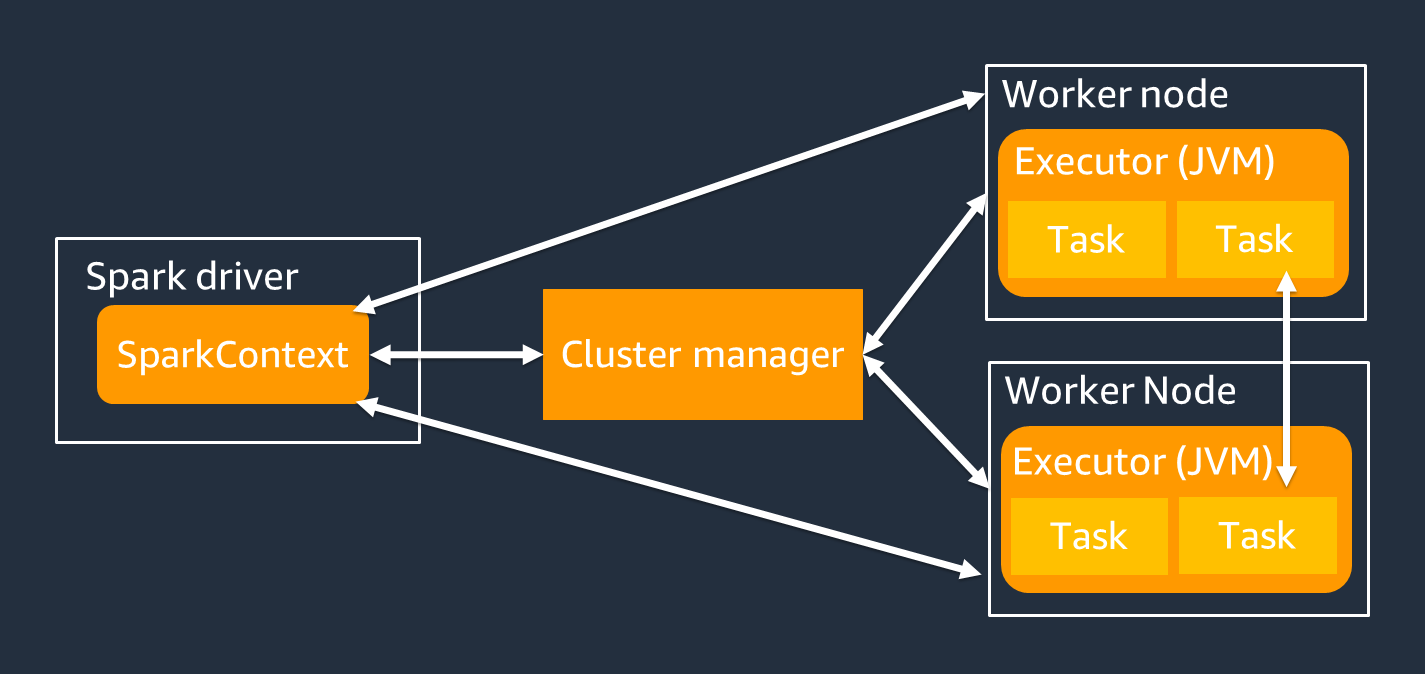
El controlador de Spark es el principal responsable de dividir su aplicación de Spark en tareas que puedan llevar a cabo nodos de trabajo individuales. El controlador de Spark tiene las siguientes responsabilidades:
-
Ejecutar
main()en su código. -
Generar planes de ejecución.
-
Aprovisionar los ejecutores de Spark junto con el administrador de clústeres, que administra los recursos del clúster.
-
Programar tareas y solicitar tareas para los ejecutores de Spark.
-
Administrar el progreso y la recuperación de las tareas.
Utiliza un objeto SparkContext para interactuar con el controlador de Spark durante la ejecución del trabajo.
Un ejecutor de Spark es un nodo de trabajo que se encarga de almacenar datos y ejecutar tareas que se transfieren desde el controlador de Spark. El número de ejecutores de Spark aumentará y disminuirá con el tamaño del clúster.
nota
Un ejecutor de Spark tiene múltiples ranuras para procesar múltiples tareas en paralelo. De forma predeterminada, Spark admite una tarea para cada núcleo de CPU virtual (vCPU). Por ejemplo, si un ejecutor tiene cuatro núcleos de CPU, puede ejecutar cuatro tareas simultáneas.
Conjunto de datos distribuido resiliente
Spark lleva a cabo el complejo trabajo de almacenar y rastrear grandes conjuntos de datos entre los ejecutores de Spark. Cuando escribe código para los trabajos de Spark, no tiene que pensar en los detalles del almacenamiento. Spark proporciona la abstracción de conjuntos de datos distribuidos resilientes (RDD), que es una colección de elementos que se pueden operar en paralelo y que se pueden dividir entre los ejecutores de Spark del clúster.
La siguiente figura muestra la diferencia en la forma de almacenar datos en la memoria cuando se ejecuta un script de Python en su entorno típico y cuando se ejecuta en el marco Spark (PySpark).
![Python val [1,2,3 N], Apache Spark rdd = sc.parallelize[1,2,3 N].](images/store-data-memory.png)
-
Python: al escribir
val = [1,2,3...N]en un script de Python se mantienen los datos en memoria en la única máquina en la que se ejecuta el código. -
PySpark— Spark proporciona la estructura de datos RDD para cargar y procesar los datos distribuidos en la memoria de varios ejecutores de Spark. Puede generar un RDD con código como
rdd = sc.parallelize[1,2,3...N]y Spark puede distribuir y almacenar automáticamente los datos en memoria entre varios ejecutores de Spark.En muchos AWS Glue trabajos, se utilizan los RDD a través AWS Glue DynamicFramesde Spark. DataFrames Se trata de abstracciones que permiten definir el esquema de datos en un RDD y llevar a cabo tareas de nivel superior con esa información adicional. Como utilizan los RDD internamente, los datos se distribuyen y cargan de forma transparente en varios nodos en el siguiente código:
-
DynamicFrame
dyf= glueContext.create_dynamic_frame.from_options( 's3', {"paths": [ "s3://<YourBucket>/<Prefix>/"]}, format="parquet", transformation_ctx="dyf" ) -
DataFrame
df = spark.read.format("parquet") .load("s3://<YourBucket>/<Prefix>")
-
Un RDD tiene las siguientes características:
-
Los RDD constan de datos divididos en varias partes denominadas particiones. Cada ejecutor de Spark almacena una o más particiones en memoria y los datos se distribuyen entre varios ejecutores.
-
Los RDD son inmutables, lo que significa que no se pueden cambiar una vez creados. Para cambiar a DataFrame, puedes usar las transformaciones, que se definen en la siguiente sección.
-
Los RDD replican los datos en los nodos disponibles, por lo que pueden recuperarse automáticamente de los errores de los nodos.
Evaluación lenta
Los RDD admiten dos tipos de operaciones: las transformaciones, que crean un nuevo conjunto de datos a partir de uno existente, y las acciones, que devuelven un valor al programa del controlador tras ejecutar un cálculo en el conjunto de datos.
-
Transformaciones: como los RDD son inmutables, solo puede cambiarlos mediante una transformación.
Por ejemplo,
mapes una transformación que pasa cada elemento del conjunto de datos a través de una función y devuelve un nuevo RDD que representa los resultados. Observe que el métodomapno devuelve ninguna salida. Spark almacena la transformación abstracta para el futuro, en lugar de permitirte interactuar con el resultado. Spark no actuará en las transformaciones hasta que llame a una acción. -
Acciones: al usar las transformaciones, crea su plan de transformaciones lógicas. Para iniciar el cálculo, ejecute una acción como
write,count,showocollect.Todas las transformaciones en Spark son lentas, en el sentido de que no calculan sus resultados de forma inmediata. En su lugar, Spark recuerda una serie de transformaciones aplicadas a algún conjunto de datos base, como objetos de Amazon Simple Storage Service (Amazon S3). Las transformaciones se calculan solo cuando una acción requiere que se devuelva un resultado al controlador. Este diseño permite que Spark se ejecute de forma más eficiente. Por ejemplo, consideremos la situación en la que un conjunto de datos creado mediante la transformación
mapsolo lo consume una transformación que reduce sustancialmente el número de filas, comoreduce. A continuación, puede pasar el conjunto de datos más pequeño que se ha sometido a ambas transformaciones al controlador, en lugar de pasar el conjunto de datos asignado más grande.
Terminología de las aplicaciones de Spark
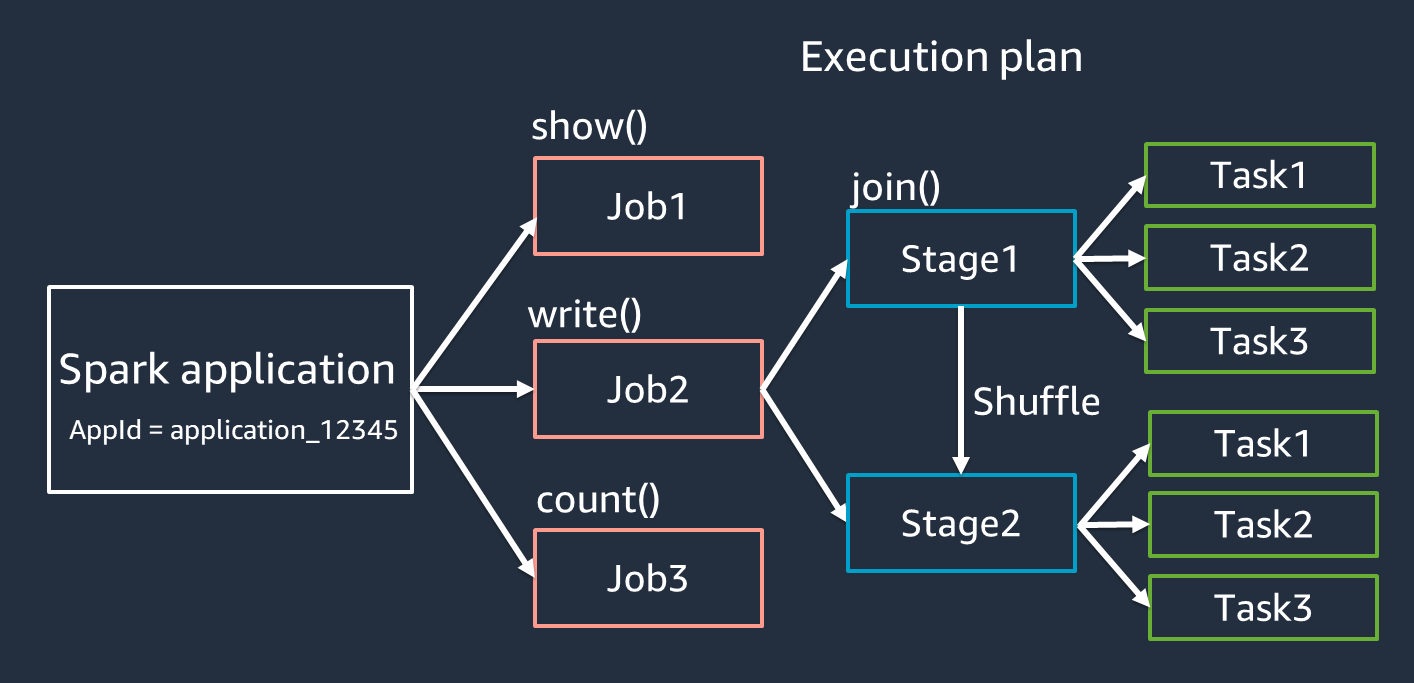
En esta sección se trata la terminología de las aplicaciones de Spark. El controlador de Spark crea un plan de ejecución y controla el comportamiento de las aplicaciones en varias abstracciones. Los siguientes términos son importantes para el desarrollo, la depuración y el ajuste del rendimiento con la IU de Spark.
-
Aplicación: se basa en una sesión de Spark (contexto de Spark). Se identifica mediante un ID único, como
<application_XXX>. -
Trabajos: se basan en las acciones creadas para un RDD. Un trabajo consta de una o más etapas.
-
Etapas: se basan en las mezclas creadas para un RDD. Una etapa consta de una o más tareas. La mezcla es el mecanismo de Spark para redistribuir los datos de forma que se agrupen de forma diferente en las particiones de RDD. Algunas transformaciones, como
join(), requieren una mezcla. Las mezclas se analizan con más detalle en la práctica de ajuste Optimización de las mezclas. -
Tareas: una tarea es la unidad mínima de procesamiento programada por Spark. Las tareas se crean para cada partición de RDD y el número de tareas es el número máximo de ejecuciones simultáneas de la etapa.
nota
Las tareas son lo más importante que se debe tener en cuenta a la hora de optimizar el paralelismo. El número de tareas escala con el número de RDD
Paralelismo
Spark paraleliza las tareas de carga y transformación de datos.
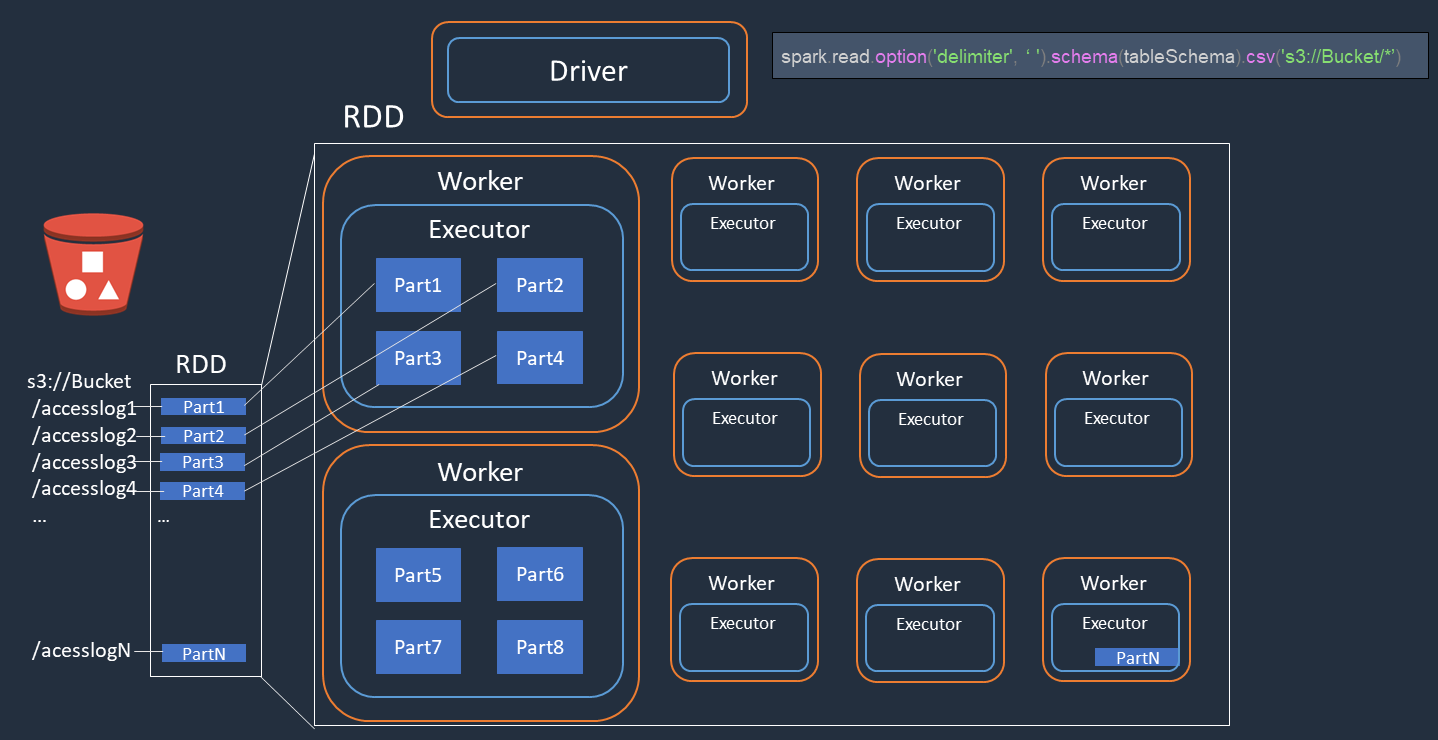
Considere un ejemplo en el que lleva a cabo un procesamiento distribuido de los archivos de registros de acceso (denominados accesslog1 ... accesslogN) en Amazon S3. En el siguiente diagrama se muestra el flujo de procesamiento distribuido.
-
El controlador de Spark crea un plan de ejecución para el procesamiento distribuido entre muchos ejecutores de Spark.
-
El controlador de Spark asigna tareas a cada ejecutor en función del plan de ejecución. De forma predeterminada, el controlador de Spark crea particiones de RDD (cada una de las cuales corresponde a una tarea de Spark) para cada objeto de S3 (
Part1 ... N). A continuación, el controlador de Spark asigna tareas a cada ejecutor. -
Cada tarea de Spark descarga su objeto de S3 asignado y lo almacena en memoria en la partición de RDD. De esta forma, varios ejecutores de Spark descargan y procesan la tarea asignada en paralelo.
Para obtener más información sobre el número inicial de particiones y la optimización, consulte la sección Paralelización de las tareas.
Optimizador Catalyst
Internamente, Spark usa un motor llamado optimizador Catalyst
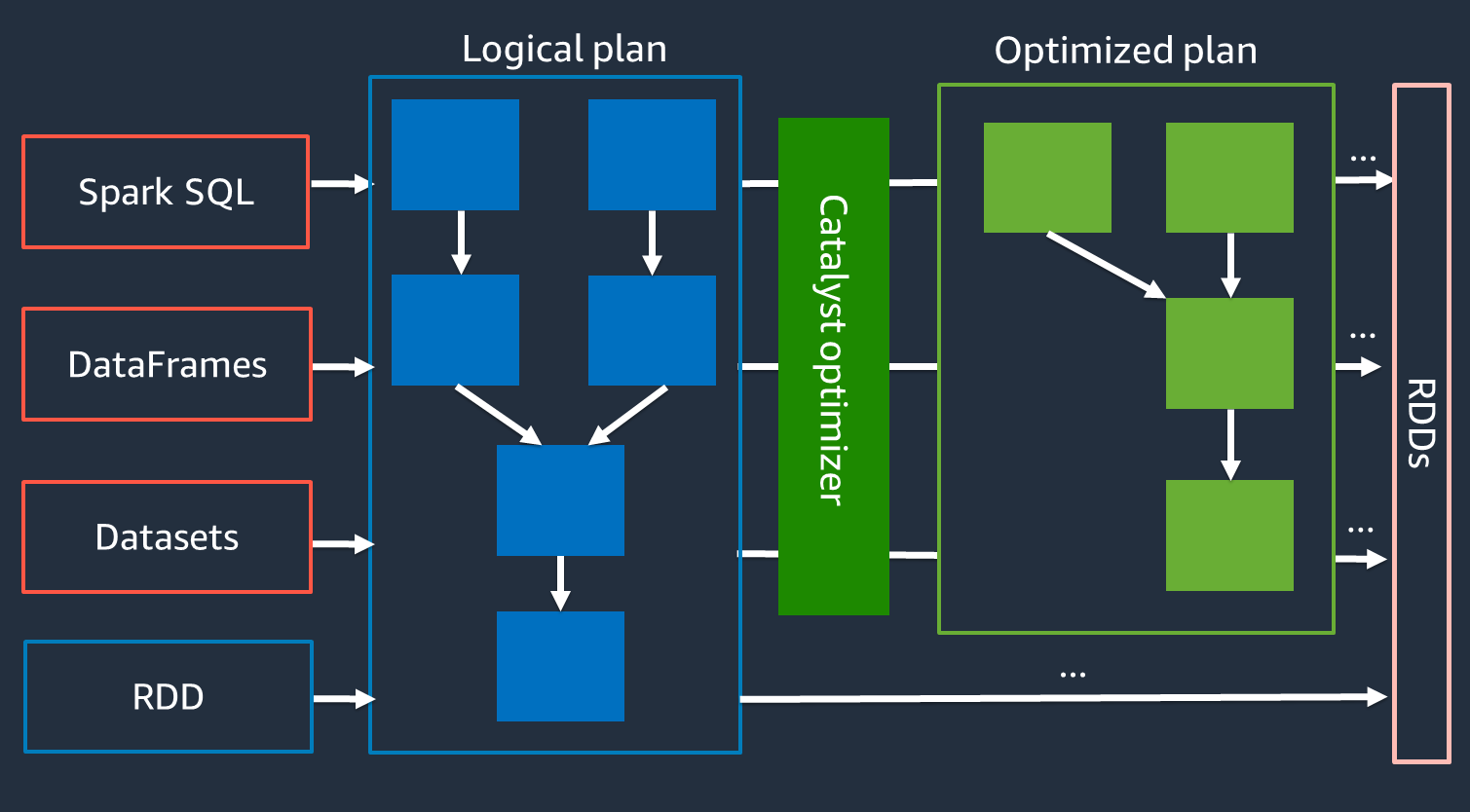
Como el optimizador Catalyst no funciona directamente con la API de RDD, las API de alto nivel suelen ser más rápidas que la API de RDD de bajo nivel. En el caso de uniones complejas, el optimizador Catalyst puede mejorar considerablemente el rendimiento al optimizar el plan de ejecución del trabajo. Puede ver el plan optimizado de su trabajo de Spark en la pestaña SQL de la IU de Spark.
Ejecución adaptativa de consultas
El optimizador Catalyst optimiza el tiempo de ejecución mediante un proceso denominado ejecución adaptativa de consultas. La ejecución adaptativa de consultas utiliza estadísticas de tiempo de ejecución para volver a optimizar el plan de ejecución de las consultas mientras el trabajo está en ejecución. La ejecución adaptativa de consultas ofrece varias soluciones a los desafíos de rendimiento, como la fusión de particiones posteriores a la mezcla, la conversión de uniones de ordenación/combinación en uniones de transmisión y la optimización de uniones sesgadas, tal y como se describe en las siguientes secciones.
La ejecución adaptativa de consultas está disponible en la AWS Glue versión 3.0 y versiones posteriores, y está habilitada de forma predeterminada en la AWS Glue versión 4.0 (Spark 3.3.0) y versiones posteriores. La ejecución adaptativa de consultas se puede activar y desactivar utilizando spark.conf.set("spark.sql.adaptive.enabled",
"true") en el código.
Fusión de particiones posteriores a la mezcla
Esta característica reduce las particiones de RDD (fusión) después de cada mezcla en función de las estadísticas de salida de map. Simplifica el ajuste del número de particiones de mezcla al ejecutar consultas. No tiene que establecer un número de particiones de mezcla para que se ajuste a su conjunto de datos. Spark puede elegir el número de particiones de mezcla adecuado en tiempo de ejecución una vez que el número inicial de particiones de mezcla sea lo suficientemente grande.
La fusión de particiones posteriores a la mezcla se habilita cuando spark.sql.adaptive.enabled y spark.sql.adaptive.coalescePartitions.enabled se establecen en verdadero. Para obtener más información, consulte la documentación de Apache Spark
Conversión de uniones de ordenación/combinación en uniones de transmisión
Esta característica reconoce cuando se unen dos conjuntos de datos de un tamaño sustancialmente diferente y adopta un algoritmo de unión más eficiente según esa información. Para obtener más información, consulte la documentación de Apache Spark
Optimización de uniones sesgadas
El sesgo de datos es uno de los cuellos de botella más habituales para los trabajos de Spark. Describe una situación en la que los datos están sesgados hacia particiones de RDD específicas (y, en consecuencia, hacia tareas específicas), lo que retrasa el tiempo total de procesamiento de la aplicación. A menudo, esto puede reducir el rendimiento de las operaciones de unión. La característica de optimización de uniones sesgadas gestiona de forma dinámica el sesgo en las uniones de ordenación/combinación al dividir (y replicar si es necesario) las tareas sesgadas en tareas con un tamaño aproximadamente uniforme.
Esta característica se habilita cuando spark.sql.adaptive.skewJoin.enabled se establece en verdadero. Para obtener más información, consulte la documentación de Apache Spark
