Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Opciones y consideraciones de HA/DR
Si bien la posibilidad de que una zona o región de disponibilidad AWS se desconecte por completo es muy poco frecuente, recomendamos adoptar un enfoque múltiple para realizar copias de seguridad y recuperación en caso de desastre, con el fin de garantizar la redundancia y minimizar la pérdida de datos. Los procesos de backup y recuperación deben incluir el nivel de granularidad adecuado para cumplir con el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO) para la carga de trabajo y sus procesos empresariales de apoyo, y a menudo dependen de la aplicación. En el caso de las bases de datos, AWS también es compatible con todas las recomendaciones de Microsoft para la instalación y configuración del servidor de SQL para alta disponibilidad y recuperación de desastres (HA/DR). Las distintas ediciones del servidor de SQL admiten distintas opciones de alta disponibilidad y recuperación de desastres, y debería tener en cuenta los casos especiales, como las bases de datos muy grandes (VLDB), caso por caso. Como ocurre con cualquier configuración de DR, las pruebas son esenciales para garantizar que cada aplicación cumpla con sus acuerdos de nivel de servicio (SLA) en materia de alta disponibilidad y recuperación de desastres. Para su entorno de pruebas/desarrollo, considere la posibilidad de utilizar la edición para desarrolladores del servidor de SQL
Para un caso de uso que requiera un RPO de 15 minutos y un RTO de 4 horas, puede considerar una combinación de las siguientes opciones de HA/DR:
-
Opciones HA/DR nativas del servidor de SQL con un modo de espera temporal (nivel de base de datos): para ver ilustraciones de algunas de estas arquitecturas, consulte la sección Diagramas de arquitectura de SQL Server en Amazon EC2 que aparece más adelante en esta guía.
-
Dos nodos y zonas de disponibilidad múltiples en una sola Región (modo de confirmación sincrónica) o en varias Regiones (modo de confirmación asíncrona, grupo de disponibilidad básico)
-
Tres nodos (o más), multi-AZ en varias Regiones (modos de confirmación síncrona y confirmación asíncrona)
-
Envío de registros con dos nodos, multi-AZ y registros en varias Regiones (con copias de seguridad de los registros cada 5 minutos)
-
-
Copias de seguridad nativas del servidor de SQL en Amazon S3 (a nivel de base de datos, solo DR): copias de seguridad completas (una vez al día)
-
Respaldos diferenciales (entre cada 2 y 4 horas).
-
Registre las copias de seguridad (entre cada 5 y 10 minutos).
-
Las copias de seguridad deben tomarse y copiarse en Amazon Simple Storage Service (Amazon S3) mediante secuencias de comandos personalizadas o una opción como Puerta de enlace de archivo
para una copia de seguridad y transferencia eficientes. -
Si tiene cientos de bases de datos, puede seguir utilizando las herramientas de copia de seguridad existentes (como Commvault o Litespeed) para gestionar las copias de seguridad de forma eficiente y almacenarlas directamente en Amazon S3.
-
Utilice la Replicación entre regiones (CRR) de Amazon S3 con el Control del tiempo de replicación (RTC) de S3 para controlar y supervisar la replicación de objetos dentro de un SLA de 15 minutos.
-
Para cumplir con los requisitos y ahorrar costos, también puede usar la Administración del ciclo de vida de S3 para mover y almacenar copias de seguridad antiguas para su almacenamiento a largo plazo.
-
Si toma copias de seguridad nativas del servidor de SQL y las mueve a Amazon S3 con regularidad, en caso de desastre, las copias de seguridad estarán disponibles en la región de destino. Esto elimina la necesidad de transferir copias de seguridad o restaurar instantáneas.
-
Recomendamos usar la Compresión nativa de copias de seguridad de SQL para reducir el tamaño de los archivos.
-
-
Instantáneas AWS (a nivel de instancia y volumen, solo DR)
-
Amazon Elastic Compute Cloud (Amazon EC2) Copias de seguridad de Imagen de máquina de Amazon (AMI) para reconstruir bases de datos desde cero
-
Instantáneas de volumen de Amazon Elastic Block Store (Amazon EBS) para adjuntar volúmenes de EBS a Amazon EC2
-
Administrar los recursos de alta disponibilidad y recuperación de desastres en AWS Backup
AWS Backup es un servicio totalmente gestionado que ofrece la posibilidad de crear planes y programas de respaldo y asignar los recursos AWS que intervienen en la configuración de alta disponibilidad y recuperación de desastres, como los volúmenes de Amazon EBS para crear instantáneas y las AMI de Amazon EC2, a estos planes de respaldo. También puede utilizar AWS Backup para programar copias multi-regionales de estas instantáneas de EBS. Para un uso óptimo, AWS Backup requiere un mecanismo de etiquetado eficiente para que los recursos estén disponibles. AWS Backup también admite copias de seguridad compatibles con la aplicación a través del Servicio de copia instantánea de volumen (VSS) de Windows, que puede usar para el servidor de SQL. Para una protección a nivel de almacenamiento, recomendamos utilizar instantáneas de EBS. Las instantáneas iniciales de EBS están llenas y las instantáneas posteriores son incrementales. Si bien las instantáneas de EBS ofrecen protección a nivel de almacenamiento, no sustituyen a las copias de seguridad nativas basadas en archivos del servidor de SQL que ofrecen una recuperación puntual.
Utilizar AWS DMS para HA/DR
Si busca una alternativa a las opciones de replicación del servidor de SQL Always On o si tiene bases de datos de origen y destino heterogéneas, ya sea en una configuración híbrida o en AWS, puede usar AWS Database Migration Service (AWS DMS) de las siguientes formas.
Si lo utiliza AWS DMS con SQL Server en un contexto autogestionado (con Amazon EC2 como host o en las instalaciones), admite la replicación única y continua de dos modos: mediante MS-REPLICATION (para capturar los cambios en las tablas que tienen claves principales) y MS-CDC (para capturar los cambios en las tablas que no tienen claves principales). Sin embargo, si usa Amazon Relational Database Service (Amazon RDS) como fuente para AWS DMS, solo se admite MS-CDC. AWS DMS ofrece una gama de puntos de conexión de origen y destino, admite motores de bases de datos heterogéneos y ofrece un control detallado del proceso de replicación. También puede usar AWS Schema Conversion Tool (AWS SCT) con AWS DMS para migraciones de bases de datos heterogéneas. AWS SCTautomatiza los cambios a nivel de esquema y también produce informes para planificar y preparar la migración.
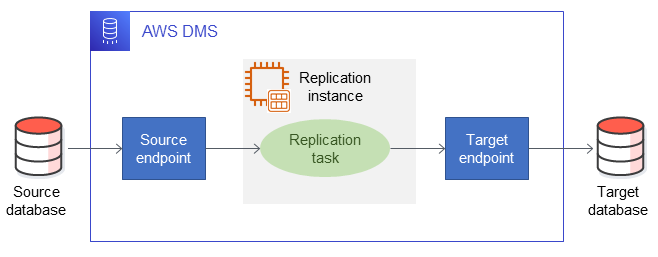
Las bases de datos de origen y destino se agregan como puntos finales en AWS DMS, como se ilustra en el siguiente diagrama. Este servicio implementa un proceso de replicación lógica mediante MS-REPLICATION o MS-CDC. Si tiene una configuración híbrida, puede configurar AWS DMS para una replicación continua entre las instalaciones y AWS. Durante la transición, la tarea de migración AWS DMS se puede detener y la aplicación podrá conectarse a la base de datos que ya está sincronizada con la base de datos en las instalaciones sin más demora. Usando AWS DMS para el servidor de SQL como fuente tiene algunas limitaciones, que se describen en la documentación AWS DMS.
Considere utilizar AWS DMS en lugar de los métodos de alta disponibilidad y recuperación de desastres nativos en las siguientes situaciones:
-
Cuando desee ahorrar en los costos de licencias. Por ejemplo, si utiliza una versión avanzada, como la edición Enterprise del servidor de SQL, solo para las opciones Always On, podría considerar la posibilidad de configurar AWS DMS, ya que puede proporcionar una opción de replicación lógica sin el costo de una licencia de edición Enterprise.
-
Cuando tiene orígenes y destinos heterogéneos. No es necesario que las versiones del servidor de SQL en los nodos principales y de recuperación de desastres coincidan (con ciertas limitaciones AWS DMS), lo que proporciona una flexibilidad significativa.
-
Para evitar la sobrecarga que supone Windows, los clústeres del servidor de SQL y la configuración y administración de grupos de disponibilidad distribuida. AWS DMS ofrece una configuración sencilla y una administración sencilla de las tareas de replicación.
-
Para casos de uso empresarial, como la transferencia prácticamente en tiempo real (según la instancia de replicación, la configuración de la red y el volumen de datos), el enmascaramiento de datos, el filtrado selectivo, el mapeo de esquemas y tablas (homogéneos y heterogéneos), las evaluaciones previas a la migración y la compatibilidad con JSON.
-
Para duplicar, detener e iniciar tareas fácilmente según sea necesario en función de los números de secuencia de registro (LSN), las marcas de tiempo y opciones similares.
El siguiente diagrama muestra un enfoque alternativo sobre cómo AWS DMS puede proporcionar soporte para la replicación. En esta configuración, la fuente es un clúster de grupos de disponibilidad del servidor de SQL Always On y AWS DMS utiliza la opción de captura de datos modificados (CDC) para replicar continuamente los datos a un destino de una región AWS diferente. Para obtener un rendimiento óptimo, es fundamental garantizar que la instancia de replicación tenga el tamaño correcto y permanezca en la región de origen.
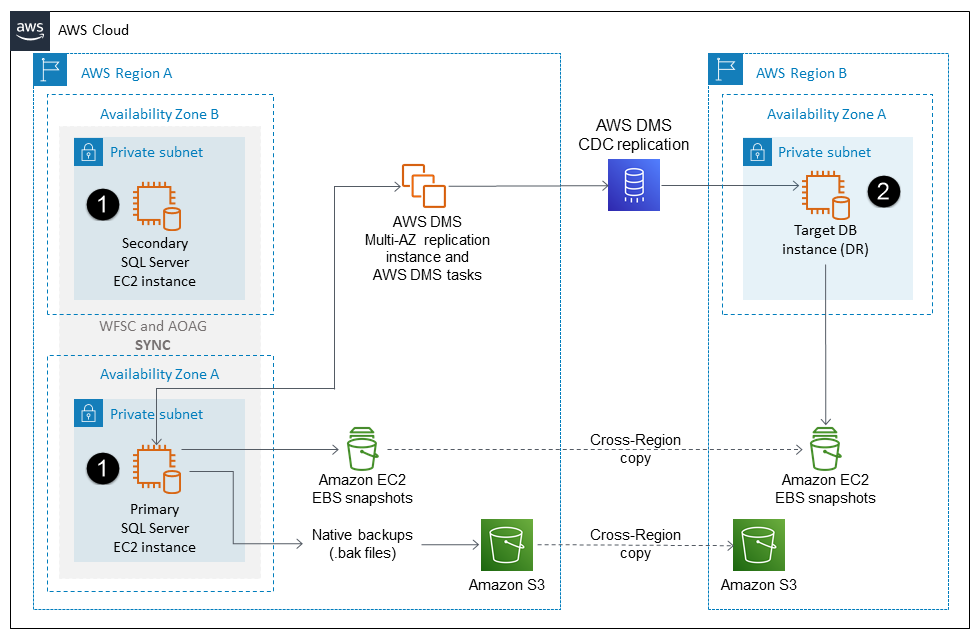
Los motores de origen y destino no tienen por qué coincidir. En el diagrama, los nodos principal y secundario marcados como (1) pueden ser un clúster del servidor de SQL en una configuración single-AZ o multi-AZ. O bien, el origen puede ser un único nodo del servidor de SQL compatible con MS-CDC o MS-REPLICATION.
La instancia de base de datos de destino, marcada como (2) en el diagrama, puede ser cualquier versión del servidor de SQL en Amazon RDS, Amazon EC2 o cualquier otro destino heterogéneo. No tiene que coincidir con las instancias principal y secundaria ni ser compatible con los grupos de disponibilidad de Always On. Por ejemplo, el origen puede ser un clúster de grupo de disponibilidad Always On del servidor de SQL y el destino puede ser una edición compatible con Amazon Aurora PostgreSQL.
Utilizar AWS Application Migration Service para DR
Recomendamos utilizar AWS Application Migration Service para migraciones mediante lift-and-shift a AWS. El servicio de migración de aplicaciones replica de forma continua sus máquinas (incluido el sistema operativo, la configuración del estado del sistema, las bases de datos, las aplicaciones y los archivos) en un área de almacenamiento de bajo costo en su cuenta de destino AWS y región preferida. En caso de que se produzca un desastre, puede utilizar el Servicio de migración de aplicaciones para lanzar automáticamente miles de máquinas en su estado totalmente aprovisionado en cuestión de minutos.
Consideraciones adicionales
La siguiente lista identifica los posibles obstáculos que debe tener en cuenta al diseñar una estrategia de alta disponibilidad y recuperación de desastres.
-
Ancho de banda, latencia, complejidad de la red y conectividad en una configuración de nodos multi-regional.
-
Tamaño de las instantáneas de Amazon EBS o Amazon EC2 y el tiempo que se tarda en copiarlas mediante el uso de AWS Backup.
-
Las instantáneas de Amazon EBS y Amazon EC2 se almacenan en Amazon S3 mediante AWS Backup.
-
Una instantánea de EBS no se replica en la región de destino de Amazon S3 hasta que se complete la instantánea actual. La duración de la replicación también depende del tamaño del volumen.
-
Cuando la instantánea esté completa, el tiempo necesario para copiar las instantáneas puede ser de tan solo 15 minutos para el 99,99 % de los objetos. Sin embargo, se requieren pruebas exhaustivas para casos de uso específicos y grandes volúmenes críticos.
-
-
Tiempo necesario para restaurar los volúmenes de EBS en la zona y región de disponibilidad objetivo.
-
Tiempo necesario para restaurar las imágenes de Amazon EC2 en la zona y región de disponibilidad objetivo.
-
Si se crea desde cero, se necesita tiempo para aprovisionar la infraestructura para la imagen de Amazon EC2 o restaurar las instantáneas de EBS en la zona y región de disponibilidad de destino.
-
Si se restaura desde cero, se necesitará tiempo para restaurar las copias de seguridad nativas completas, diferenciales y de registros del servidor de SQL en la zona y Región de disponibilidad de destino.
-
Dependencias externas y de aplicaciones que deben estar disponibles en todas las Regiones.
-
Limitaciones en el tamaño de los archivos para los volúmenes y para la carga a Amazon S3.
