Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Procesamiento de consultas SQL en Amazon Redshift
Amazon Redshift dirige una consulta SQL enviada a través del analizador y el optimizador para desarrollar un plan de consulta. El motor de ejecución luego traduce el plan de consulta en un código y lo envía a los nodos de computación para su ejecución. Antes de diseñar un plan de consulta, es esencial entender cómo funciona el procesamiento de consultas.
Flujo de trabajo de planificación y ejecución de consultas
En el siguiente diagrama, se proporciona una vista general del flujo de trabajo de planificación y ejecución de consultas.
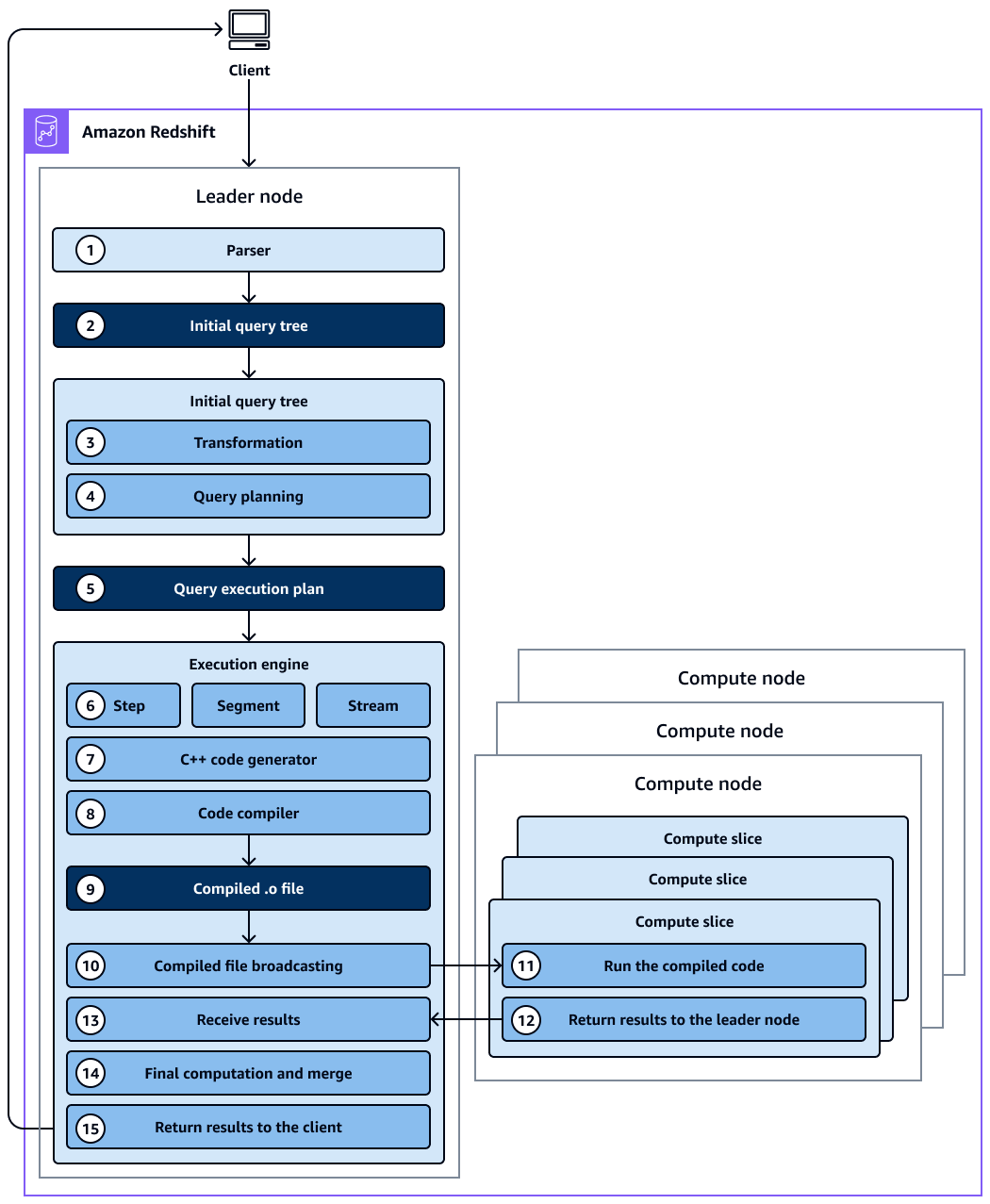
En el diagrama, se muestra el siguiente flujo de trabajo:
-
El nodo principal del clúster de Amazon Redshift recibe la consulta y analiza la instrucción SQL.
-
El analizador genera un árbol de consultas inicial que es una representación lógica de la consulta original.
-
El optimizador de consultas toma el árbol de consultas inicial y lo evalúa, analiza las estadísticas de la tabla para determinar el orden de la combinación y la selectividad de los predicados y, si es necesario, reescribe la consulta para maximizar su eficacia. A veces, una sola consulta se puede escribir como varias instrucciones dependientes en segundo plano.
-
El optimizador genera un plan de consulta (o varios, si el paso anterior generó consultas múltiples) para ejecutarlo con el mejor rendimiento posible. El plan de consulta especifica las opciones de ejecución, como el orden de ejecución, las operaciones de red, los tipos de combinación, e orden de la combinación, las opciones de agrupación y las distribuciones de datos.
-
Los planes de consultas contienen información sobre las operaciones individuales necesarias para ejecutar una consulta. Puede utilizar el comando
EXPLAINpara ver el plan de consulta. El plan de consulta es una herramienta fundamental para analizar y ajustar consultas complejas. -
El optimizador de consultas envía el plan de consulta al motor de ejecución. El motor de ejecución comprueba la caché del plan compilado para ver si coincide con un plan de consulta y utiliza la caché compilada (si la encuentra). De lo contrario, el motor de ejecución traduce el plan de consulta en pasos, segmentos y flujos:
-
Los pasos son operaciones específicas que se llevan a cabo durante la ejecución de la consulta. Los pasos se identifican mediante una etiqueta (por ejemplo,
scan,dist,hjoinomerge). Un paso es la unidad más pequeña. Puede combinar los pasos para permitir que los nodos de computación puedan realizar una consulta, una combinación u otra operación en la base de datos. -
Un segmento hace referencia a un segmento de una consulta y combina varios pasos que se pueden llevar a cabo mediante un único proceso. Un segmento es la unidad de compilación más pequeña que puede ejecutar un sector de nodos de computación. Un sector es la unidad de procesamiento en paralelo de Amazon Redshift.
-
Un flujo es un conjunto de segmentos que se reparten entre los sectores disponibles de un nodo de computación. Los segmentos de un flujo se ejecutan en paralelo entre los sectores de los nodos. Por lo tanto, el mismo paso desde el mismo segmento también se ejecuta en paralelo en varios sectores.
-
-
El generador de código recibe el plan traducido y genera una función en C++ para cada segmento.
-
GNU Compiler Collection compila la función en C++ y la convierte en un archivo O (
.o). -
Se ejecuta el código compilado (archivo O). El código compilado se ejecuta más rápido que el código interpretado y utiliza menor capacidad informática.
-
A continuación, el archivo O compilado se transmite a los nodos de computación.
-
Cada nodo de computación consta de varios sectores de computación. Los sectores de computación ejecutan los segmentos de la consulta en paralelo. Amazon Redshift aprovecha la comunicación optimizada de red, la memoria y la administración de discos para transmitir los resultados intermedios de un paso del plan de consulta al siguiente. Esto también ayuda a agilizar la ejecución de consultas. Considere lo siguiente:
-
Los pasos 6, 7, 8, 9, 10 y 11 se ejecutan una vez para cada flujo.
-
El motor crea segmentos ejecutables para un flujo y los envía a los nodos de computación.
-
Una vez completados los segmentos del flujo anterior, el motor genera los segmentos para el próximo flujo. De esta manera, el motor puede analizar lo que ocurrió la secuencia anterior (por ejemplo, si las operaciones estaban basadas en el disco) para influir sobre la generación de segmentos en la próxima secuencia.
-
-
Cuando los nodos de computación están listos, devuelven los resultados de las consultas al nodo principal para el procesamiento final. El nodo principal fusiona los datos en un conjunto único de resultados y realiza las tareas de ordenación o agregación que sean necesarias.
-
El nodo principal devuelve los resultados al cliente.
En el siguiente diagrama se muestra el flujo de trabajo de ejecución de los flujos, segmentos, pasos y sectores de los nodos de computación. Tenga en cuenta lo siguiente:
-
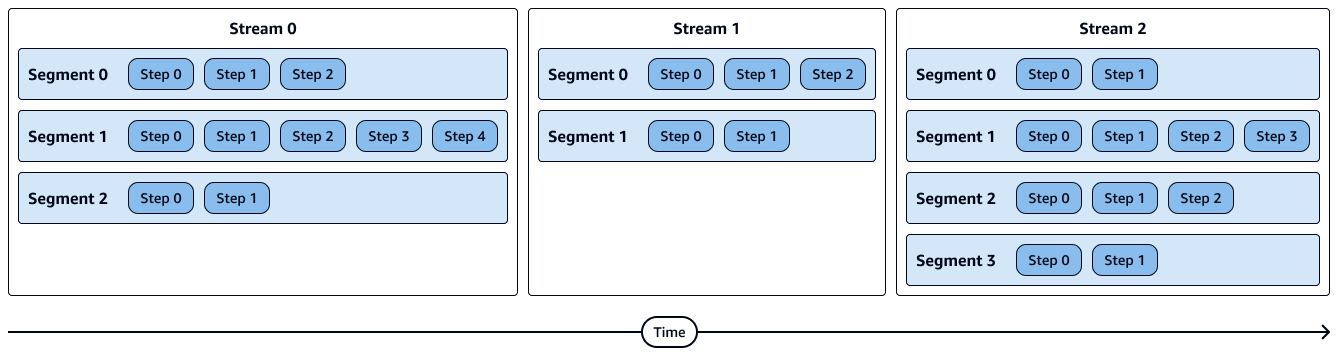
Los pasos de un segmento se ejecutan en secuencia.
-
Los segmentos de un flujo se ejecutan en paralelo.
-
Los flujos se ejecutan en secuencia.
-
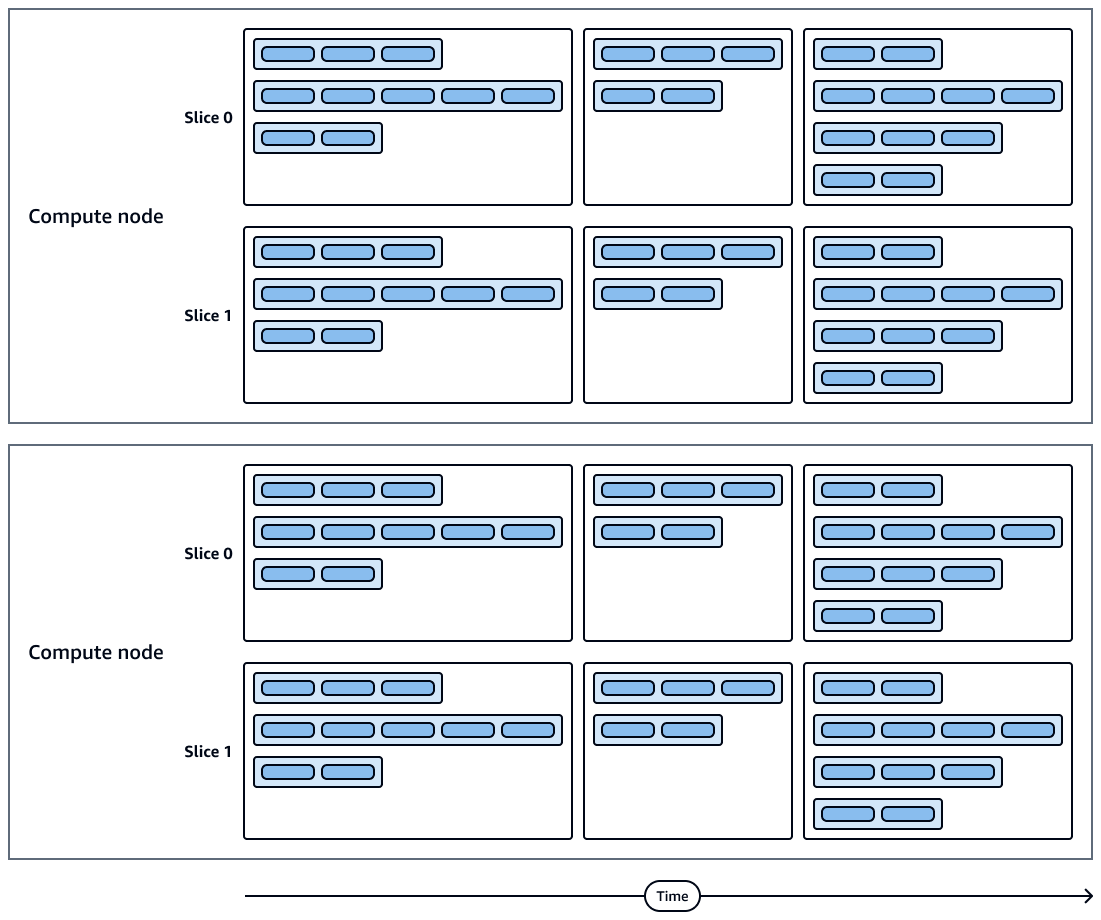
Los sectores de los nodos de computación se ejecutan en paralelo.
En el siguiente diagrama se muestra una representación visual de flujos, segmentos y pasos. Cada segmento contiene varios pasos y cada flujo contiene varios segmentos.
En el siguiente diagrama se muestra una representación visual de las ejecuciones de consultas y los sectores de los nodos de computación. Cada nodo de computación contiene varios sectores, flujos, segmentos y pasos.
Consideraciones adicionales
Le recomendamos que considere lo siguiente en relación con el procesamiento de consultas:
-
El código compilado en caché se comparte entre las sesiones del mismo clúster, por lo que las ejecuciones posteriores de la misma consulta serán más rápidas, incluso con parámetros diferentes.
-
Al realizar análisis comparativos de las consultas, le recomendamos que siempre compare los tiempos de la segunda ejecución de una consulta, porque el tiempo de la primera ejecución incluye el trabajo adicional de compilar el código. Para obtener más información, consulte Factores de rendimiento de las consultas en la guía de prácticas recomendadas para las consultas de Amazon Redshift.
-
Los nodos de computación pueden devolver algunos datos al nodo principal durante la ejecución de consultas si fuera necesario. Por ejemplo, si tiene una subconsulta con una cláusula
LIMIT, el límite se aplica al nodo principal antes de que se distribuyan los datos en todo el clúster para seguir trabajando con ellos.
