Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Componentes de arquitectura de un almacén de datos de Amazon Redshift
Le recomendamos que tenga un conocimiento básico de los principales componentes de la arquitectura de un almacén de datos de Amazon Redshift. Este conocimiento puede ayudarlo a comprender mejor cómo diseñar las consultas y las tablas para obtener un rendimiento óptimo.
Un almacén de datos en Amazon Redshift consta de los siguientes componentes de arquitectura principales:
-
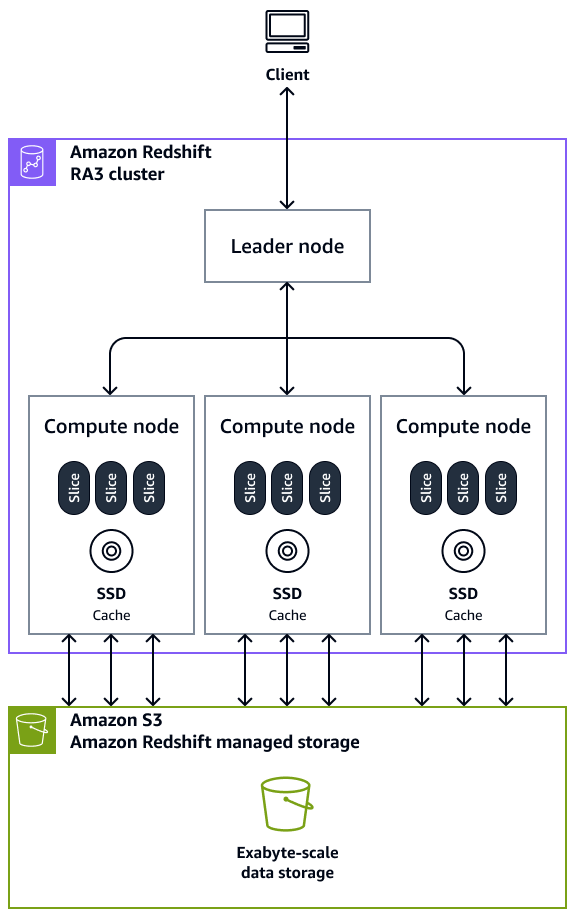
Clústeres: un clúster, compuesto por uno o más nodos de computación, es el componente de infraestructura principal de un almacén de datos de Amazon Redshift. Los nodos de computación son transparentes para las aplicaciones externas, pero la aplicación cliente solo interactúa directamente con el nodo principal. Los clústeres habituales tienen dos o más nodos de computación. Los nodos de computación se coordinan a través del nodo principal.
-
Nodo principal: los nodos principales administran las comunicaciones de los programas cliente y todos los nodos de computación. Los nodos principales también preparan los planes para ejecutar una consulta cada vez que se envía una consulta a un clúster. Una vez listos los planes, el nodo principal compila el código, lo distribuye a los nodos de computación y les asigna sectores de los datos a cada uno para procesar los resultados de la consulta.
-
Nodo de computación: los nodos de computación ejecutan las consultas. El nodo principal compila un código para los elementos individuales del plan a fin de ejecutar la consulta y lo asigna a los nodos de computación individuales. Los nodos de computación ejecutan el código compilado y envían resultados intermedios de vuelta al nodo principal para su agregación final. Cada nodo de computación tiene su propia CPU dedicada, memoria y almacenamiento en disco integrado. A medida que la carga de trabajo crece, puede aumentar la capacidad de computación y almacenamiento de un clúster aumentando el número de nodos, actualizando el tipo de nodo o ambas.
-
Sector de nodo: los nodos de computación están divididos en sectores. A cada sector de los nodos de computación se le asigna una parte de la memoria y del espacio en disco del nodo, donde se procesa una parte de la carga de trabajo asignada al nodo. A continuación, los sectores funcionan en paralelo para completar la operación. Los datos se distribuyen entre los sectores en función del estilo de distribución y la clave de distribución de una tabla en particular. Una distribución uniforme de los datos hace posible que Amazon Redshift asigne las cargas de trabajo de manera uniforme a los sectores y maximiza las ventajas del procesamiento en paralelo. El número de sectores por nodo de computación se decide en función del tipo de nodo. Para obtener más información, consulte Clústeres y nodos de Amazon Redshift en la documentación de Amazon Redshift.
-
Procesamiento en paralelo masivo (MPP): Amazon Redshift utiliza la arquitectura MPP para procesar datos de forma rápida, incluso las consultas complejas y con grandes cantidades de datos. Varios nodos de computación ejecutan el mismo código de consulta en partes de los datos para maximizar el procesamiento en paralelo.
-
Aplicación cliente: Amazon Redshift se integra a distintas herramientas de extracción, transformación y carga (ETL), inteligencia empresarial (BI), generación de informes, minería de datos y análisis. Todas las aplicaciones cliente se comunican con el clúster solamente mediante el nodo principal.
En el siguiente diagrama se muestra cómo los componentes de la arquitectura de un almacén de datos de Amazon Redshift trabajan juntos para acelerar las consultas.