Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Prácticas recomendadas para el diseño de tablas de Amazon Redshift
En esta sección se brinda información general sobre las prácticas recomendadas para diseñar tablas de bases de datos. Le recomendamos que siga estas prácticas recomendadas para lograr un rendimiento y una eficacia óptimos en las consultas.
Descripción del funcionamiento de las claves de clasificación
Amazon Redshift almacena los datos en el disco en un determinado orden en función de la clave de ordenación. El optimizador de consultas de Amazon Redshift utiliza la ordenación cuando determina cuáles son los planes óptimos de consulta. Para usar las claves de clasificación de forma eficaz, le recomendamos que haga lo siguiente:
-
Mantenga la tabla lo más ordenada posible.
-
Utilice la clasificación
VACUUMpara restablecer un rendimiento óptimo. -
Evite comprimir la columna de claves de clasificación.
-
Si la clave de clasificación está comprimida y la relación
sortkey1_skewes significativamente alta, vuelva a crear la tabla sin habilitar la compresión de la clave de clasificación. -
Evite aplicar una función a las columnas de la clave de clasificación. Por ejemplo, en la siguiente consulta, la columna de claves de clasificación
trans_dt : TIMESTAMPTZno se usa si convierte su tipo aDATE:select order_id, order_amt from sales where trans_dt::date = '2021-01-08'::date -
Realice las operaciones
INSERTen el orden de las claves de clasificación. -
Utilice las claves de clasificación en la cláusula
GROUP BYsiempre que sea posible.
Consejos de ajuste de consultas
Le recomendamos que siga estos pasos para ajustar las consultas:
-
Ordene siempre las claves de clasificación compuestas desde la cardinalidad más baja hasta la cardinalidad más alta para lograr una eficacia óptima.
-
Si la clave principal de una clave de clasificación compuesta es relativamente única (es decir, tiene una cardinalidad alta), evite agregar más columnas a la clave de clasificación. Agregar más columnas tiene poco impacto en el rendimiento de las consultas, pero incrementa los costos de mantenimiento.
Evaluación de la eficacia de las claves de clasificación
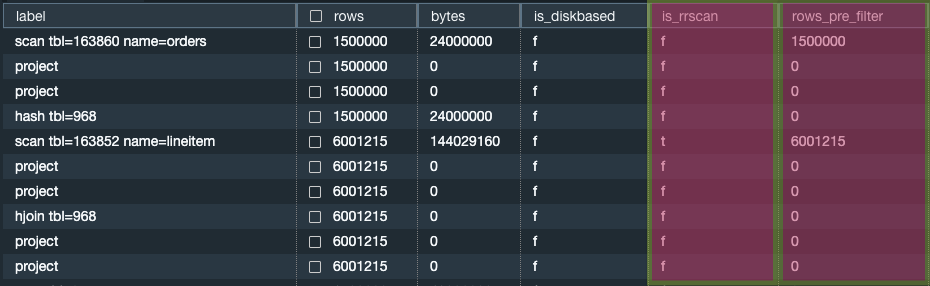
Para optimizar las consultas, debe poder evaluar su eficacia. Le recomendamos que utilice la vista SVL_QUERY_SUMMARY para encontrar información general acerca de la ejecución de una consulta. En esta vista, puede utilizar el atributo IS_RRSCAN para determinar si un paso del plan EXPLAIN usa un análisis de rango restringido. También puede utilizar el atributo rows_pre_filter para determinar la selectividad de una clave de clasificación.
Además, puede usar una vista de administración de GitHub denominada v_my_last_query_summary
La siguiente instrucción muestra cómo obtener información general acerca de la ejecución de una consulta.
select lpad(' ',stm+seg+step) || label as label, rows, bytes, is_diskbased, is_rrscan, rows_pre_filter from svl_query_summary where query = pg_last_query_id() order by stm, seg, step;
La consulta anterior devuelve el siguiente ejemplo de salida.
Información sobre su tabla
Es importante entender las propiedades fundamentales de la tabla. Para obtener más información acerca de la tabla, siga estos pasos:
-
Use PG_TABLE_DEF para ver información acerca de las columnas de la tabla.
-
Use SVV_TABLE_INFO para consultar información más exhaustiva acerca de una tabla, incluidos el sesgo de distribución de datos, el sesgo de distribución de claves, el tamaño de tabla y las estadísticas.
Selección del estilo de distribución de tablas adecuado
Cuando ejecuta una consulta, el optimizador de consultas redistribuye las filas a los nodos de computación según se necesite para realizar combinaciones y agregaciones. El objetivo al seleccionar un estilo de distribución de tablas es reducir el impacto del paso de redistribución al localizar los datos en el lugar que deben estar antes de que ejecute la consulta.
Recomendamos el siguiente enfoque para elegir el estilo de distribución de tablas adecuado:
-
Para evitar la difusión y la redistribución en un plan de ejecución de consultas, coloque las filas dentro del mismo nodo. Por ejemplo, si selecciona
DISTKEY, puede distribuir la tabla de hechos y la tabla unidimensional en sus columnas comunes. Seleccione la mayor dimensión según el tamaño del conjunto de datos filtrado. Solo se deben distribuir las filas que se usan en la combinación; por lo tanto, considere el tamaño del conjunto de datos después del filtrado, no el tamaño de la tabla. -
Asegúrese de que no haya asimetría en la columna en la que se cree la clave de distribución. De ser así, un nodo de computación podría realizar más tareas que otros. Si observa que hay asimetría, considere la posibilidad de cambiar la columna de claves de distribución. Se puede considerar que una columna es candidata a contener claves de distribución si sus valores están distribuidos uniformemente o tienen valores cardinales altos.
-
Si la tabla utilizada en la condición de combinación es pequeña (menos de 1 GB), considere el estilo de distribución
ALL. -
Puede comprimir la clave de distribución, pero debe evitar comprimir la columna de las claves de clasificación (especialmente la primera columna de las claves de clasificación).
nota
Si utiliza la optimización automática de tablas, no necesita elegir el estilo de distribución de la tabla. Para obtener más información, consulte Uso de la optimización de tablas automática en la documentación de Amazon Redshift. Para que Amazon Redshift elija el estilo de distribución adecuado, especifique AUTO en el estilo de distribución.
