Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Ejecute lecturas paralelas de objetos S3 mediante Python en una AWS Lambda función
Eduardo Bortoluzzi, Amazon Web Services
Resumen
Puede utilizar este patrón para recuperar y resumir una lista de documentos de buckets de Amazon Simple Storage Service (Amazon S3) en tiempo real. El patrón proporciona código de ejemplo para leer en paralelo objetos de buckets de S3 en Amazon Web Services (AWS). El patrón muestra cómo ejecutar eficientemente tareas I/O enlazadas con AWS Lambda funciones usando Python.
Una empresa financiera utilizó este patrón en una solución interactiva para aprobar o rechazar manualmente las transacciones financieras correlacionadas en tiempo real. Los documentos de las transacciones financieras se almacenaron en un bucket de S3 relacionado con el mercado. Un operador seleccionó una lista de documentos del bucket de S3, analizó el valor total de las transacciones calculadas por la solución y decidió aprobar o rechazar el lote seleccionado.
Las tareas vinculadas a operacioness de E/S admiten varios subprocesos. En este código de ejemplo, el concurrent.futures. ThreadPoolExecutorbotocore para que todos los subprocesos puedan descargar el objeto de S3 de forma simultánea.
El código de ejemplo usa un objeto de 8,3 KB, con datos JSON en un bucket de S3. El objeto se lee varias veces. Cuando la función de Lambda lee el objeto, los datos JSON se decodifican en un objeto de Python. En diciembre de 2024, el resultado tras ejecutar este ejemplo fue de 1000 lecturas procesadas en 2,3 segundos y 10 000 lecturas procesadas en 27 segundos mediante una función Lambda configurada con 2304 MB de memoria. AWS Lambda admite configuraciones de memoria de 128 MB a 10 240 MB (10 GB), aunque aumentar la memoria Lambda a más de 2304 MB no ayudó a reducir el tiempo de ejecución de esta tarea específica vinculada a la E/S.
La herramienta AWS Lambda Power Tuning
Requisitos previos y limitaciones
Requisitos previos
Un activo Cuenta de AWS
Competencia en desarrollo con Python.
Limitaciones
Una función de Lambda puede tener como máximo 1024 procesos o subprocesos de puesta en marcha.
Cuentas de AWS Los nuevos tienen un límite de memoria Lambda de 3.008 MB. Ajuste la herramienta de ajuste AWS Lambda de potencia en consecuencia. Para obtener más información, consulte la sección Solución de problemas.
Amazon S3 tiene un límite de 5500 GET/HEAD solicitudes por segundo por prefijo particionado.
Versiones de producto
Python 3.9 o posterior
AWS Cloud Development Kit (AWS CDK) v2
AWS Command Line Interface (AWS CLI) versión 2
AWS Lambda Power Tuning 4.3.6 (opcional)
Arquitectura
Pila de tecnología de destino
AWS Lambda
Amazon S3
AWS Step Functions (si se ha implementado AWS Lambda Power Tuning)
Arquitectura de destino
En el siguiente diagrama, se muestra una función de Lambda que lee objetos de un bucket de S3 en paralelo. El diagrama también incluye un flujo de trabajo de Step Functions para que la herramienta AWS Lambda Power Tuning ajuste con precisión la memoria de funciones Lambda. Este refinamiento permite lograr un buen equilibrio entre el costo y el rendimiento.
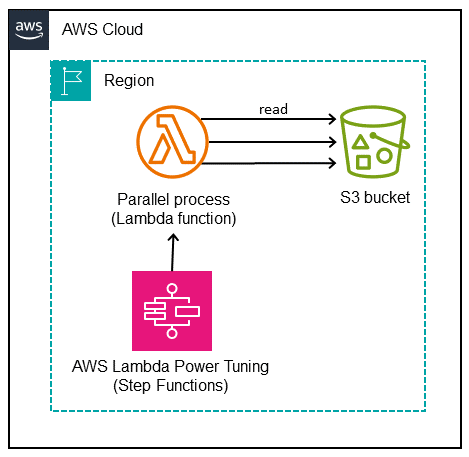
Automatización y escala
Las funciones de Lambda se escalan rápidamente cuando es necesario. Para evitar los errores 503 de ralentización de Amazon S3 cuando hay mucha demanda, le recomendamos que ponga algunos límites al escalado.
Tools (Herramientas)
Servicios de AWS
AWS Cloud Development Kit (AWS CDK) v2 es un marco de desarrollo de software que le ayuda a definir y aprovisionar la Nube de AWS infraestructura en código. La infraestructura de ejemplo se creó para implementarla con AWS CDK.
AWS Command Line InterfaceAWS CLIes una herramienta de código abierto que le ayuda a interactuar Servicios de AWS mediante comandos en su shell de línea de comandos. En este patrón, la AWS CLI versión 2 se utiliza para cargar un archivo JSON de ejemplo.
AWS Lambda es un servicio de computación que ayuda a ejecutar código sin necesidad de aprovisionar ni administrar servidores. Ejecuta el código solo cuando es necesario y amplía la capacidad de manera automática, por lo que solo pagará por el tiempo de procesamiento que utilice.
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos basado en la nube que le permite almacenar, proteger y recuperar cualquier cantidad de datos.
AWS Step Functionses un servicio de organización sin servidor que le ayuda a combinar AWS Lambda funciones y otros servicios de AWS para crear aplicaciones críticas para la empresa.
Otras herramientas
Python
es un lenguaje de programación informático de uso general. La reutilización de subprocesos de trabajo inactivos se introdujo en la versión 3.8 de Python, y el código de la función de Lambda de este patrón se creó para la versión 3.9 y posteriores de Python.
Repositorio de código
El código de este patrón está disponible en el repositorio. aws-lambda-parallel-download
Prácticas recomendadas
Esta AWS CDK construcción se basa en sus permisos Cuenta de AWS de usuario para implementar la infraestructura. Si tienes pensado usar AWS CDK Pipelines o despliegues multicuenta, consulta los sintetizadores Stack.
Esta aplicación de ejemplo no tiene habilitados los registros de acceso en el bucket de S3. Se recomienda habilitar los registros de acceso en el código de producción.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Compruebe la versión instalada de Python. | Este código se probó específicamente en Python 3.9 y Python 3.13, y debería funcionar en todas las versiones entre estas versiones. Para comprobar su versión de Python, use el comando Para verificar que los módulos necesarios estén instalados, use | Arquitecto de la nube |
Instala. AWS CDK | Para instalarlo AWS CDK si aún no está instalado, siga las instrucciones que aparecen en Introducción al AWS CDK. Para confirmar que la AWS CDK versión instalada es 2.0 o posterior, ejecute | Arquitecto de la nube |
Arranque su entorno de . | Para arrancar su entorno, si aún no lo ha hecho, siga las instrucciones de Bootstrap your environment for use with the AWS CDK. | Arquitecto de la nube |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Clonar el repositorio. | Para instalar la versión más reciente del repositorio, use el siguiente comando:
| Arquitecto de la nube |
Cambie el directorio de trabajo al repositorio clonado. | Use el siguiente comando:
| Arquitecto de la nube |
Cree un entorno virtual de Python. | Para crear un entorno virtual de Python, use el siguiente comando:
| Arquitecto de la nube |
Active el entorno virtual. | Para activar el entorno virtual, puede usar el siguiente comando:
| Arquitecto de la nube |
Instalar las dependencias. | Para instalar las dependencias de Python, use el comando
| Arquitecto de la nube |
Examine el código. | (Opcional) El código de ejemplo que descarga un objeto del bucket de S3 está en El código de la infraestructura está en la carpeta | Arquitecto de la nube |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Implemente la aplicación. | Ejecute Anote los AWS CDK resultados:
| Arquitecto de la nube |
Cargue un archivo JSON de ejemplo. | El repositorio contiene un archivo JSON de ejemplo de unos 9 KB. Para cargar el archivo en el bucket de S3 de la pila creada, use el siguiente comando:
Reemplace | Arquitecto de la nube |
Ejecute la aplicación. | Para poner en marcha la aplicación, haga lo siguiente:
| Arquitecto de la nube |
Agregue el número de descargas. | (Opcional) Para poner en marcha 1500 llamadas a get object, use el siguiente JSON en Evento JSON del parámetro
| Arquitecto de la nube |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Ejecute la herramienta AWS Lambda de ajuste de potencia. |
Al final de la ejecución, el resultado aparecerá en la pestaña Entrada y salida de ejecución. | Arquitecto de la nube |
Vea los resultados del ajuste de AWS Lambda potencia en un gráfico. | En la pestaña Entrada y salida de ejecución, copie el enlace de la propiedad | Arquitecto de la nube |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Elimine los objetos del bucket de S3. | Antes de destruir los recursos implementados, debe eliminar todos los objetos del bucket de S3:
Recuerde | Arquitecto de la nube |
Destruya los recursos. | Para destruir todos los recursos que se hayan creado para este piloto, use el siguiente comando:
| Arquitecto de la nube |
Resolución de problemas
| Problema | Solución |
|---|---|
| En el caso de las cuentas nuevas, es posible que no pueda configurar más de 3008 MB en las funciones de Lambda. Para probar con AWS Lambda Power Tuning, añada la siguiente propiedad en el JSON de entrada al iniciar la ejecución de Step Functions:
|
Recursos relacionados
Información adicional
Código
El siguiente fragmento de código realiza el procesamiento paralelo I/O :
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: for result in executor.map(a_function, (the_arguments)): ...
ThreadPoolExecutor reutiliza los subprocesos cuando están disponibles.
Pruebas y resultados
Estas pruebas se realizaron en diciembre de 2024.
La primera prueba procesó 2500 lecturas de objetos, con el siguiente resultado:
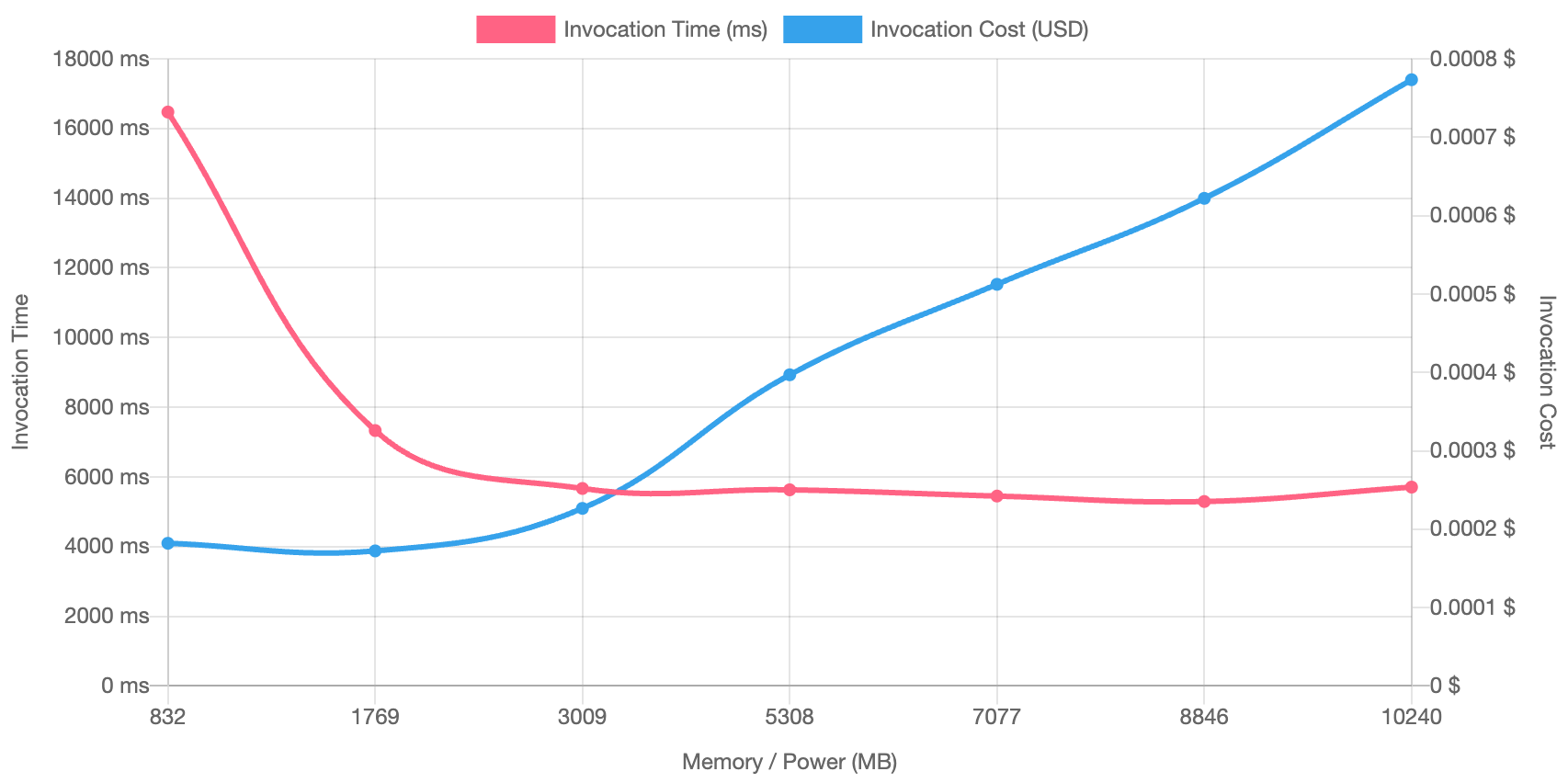
A partir de 3009 MB, el nivel de tiempo de procesamiento se mantuvo prácticamente igual para cualquier incremento de memoria, pero el costo se hacía mayor a medida que aumentaba el tamaño de la memoria.
En otra prueba, se investigó el intervalo entre 1536 MB y 3072 MB de memoria. Se utilizaron valores que eran múltiplos de 256 MB y se procesaron 10 000 lecturas de objetos; los resultados son los siguientes:
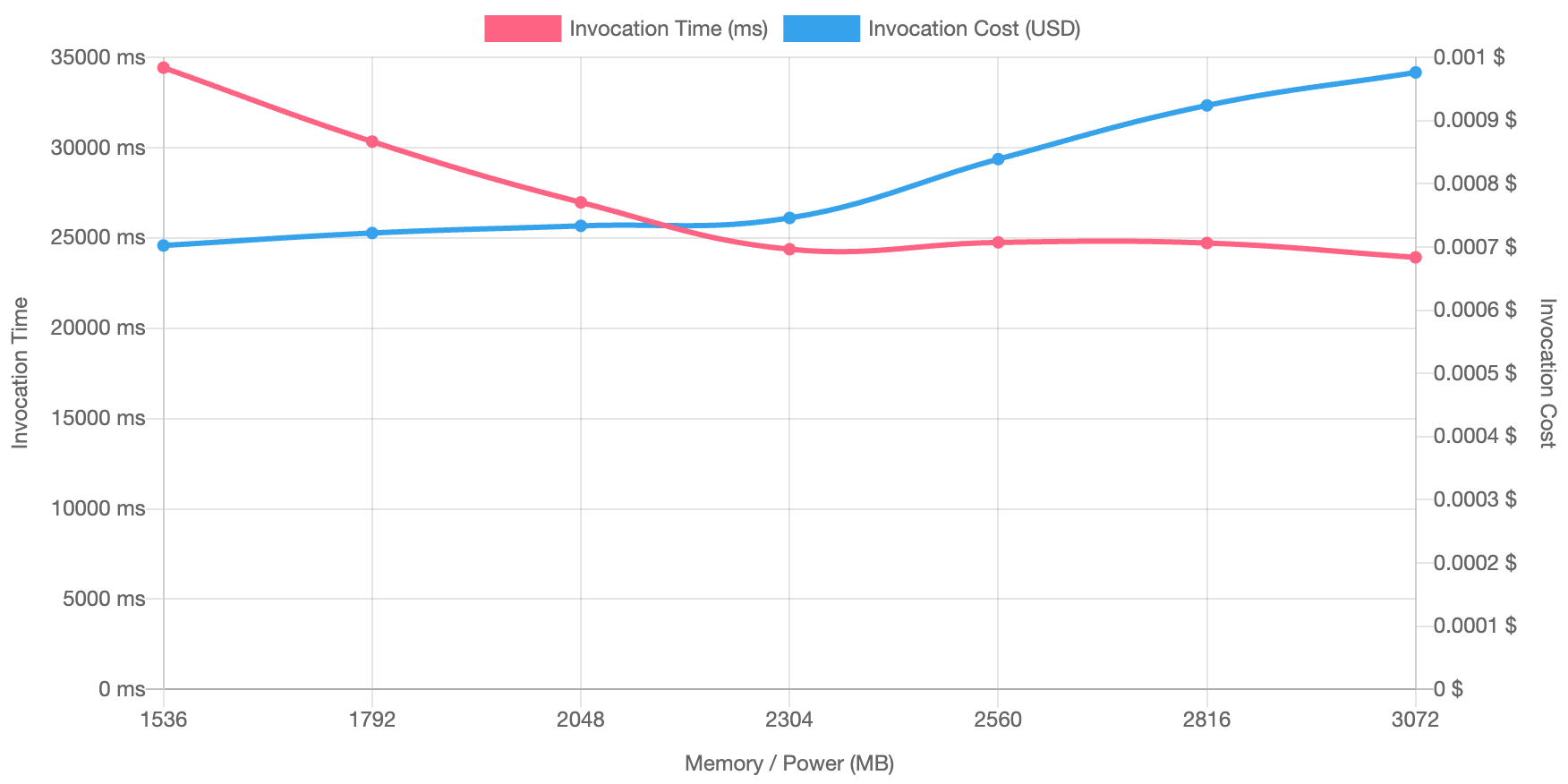
La mejor performance-to-cost relación fue con la configuración Lambda de 2.304 MB de memoria.
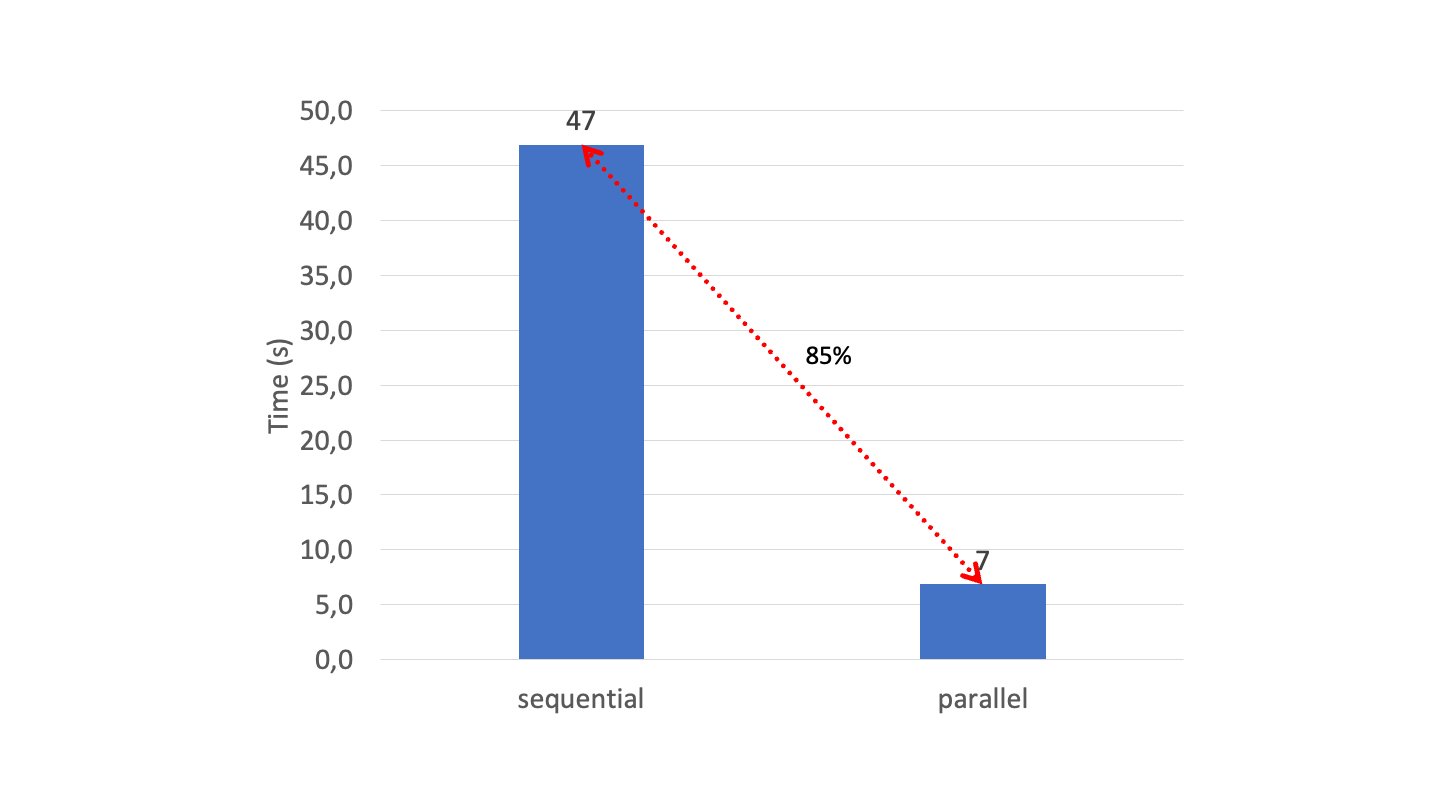
A modo de comparación, un proceso secuencial de 2500 lecturas de objetos tardó 47 segundos. El proceso paralelo con la configuración de Lambda de 2304 MB tardó 7 segundos, lo que supone un 85 por ciento menos.