Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Optimice el rendimiento de su aplicación modernizada AWS Blu Age
Vishal Jaswani, Manish Roy y Himanshu Sah, Amazon Web Services
Resumen
Las aplicaciones de mainframe que se modernizan con AWS Blu Age requieren pruebas de equivalencia funcional y de rendimiento antes de implementarlas en producción. En las pruebas de rendimiento, las aplicaciones modernizadas pueden funcionar más lentamente que los sistemas heredados, especialmente en trabajos por lotes complejos. Esta disparidad se debe a que las aplicaciones de mainframe son monolíticas, mientras que las aplicaciones modernas utilizan arquitecturas de varios niveles. Este patrón presenta técnicas de optimización para abordar estas brechas de rendimiento en las aplicaciones que se modernizan mediante la refactorización automatizada con Blu Age. AWS
El patrón utiliza el marco de modernización de AWS Blu Age con capacidades nativas de Java y ajuste de bases de datos para identificar y resolver los cuellos de botella en el rendimiento. El patrón describe cómo puede utilizar la creación de perfiles y la supervisión para identificar los problemas de rendimiento con métricas como los tiempos de ejecución de SQL, el uso de la memoria y los patrones. I/O A continuación, se explica cómo aplicar optimizaciones específicas, como la reestructuración de las consultas de la base de datos, el almacenamiento en caché y el perfeccionamiento de la lógica empresarial.
Las mejoras en los tiempos de procesamiento por lotes y en el uso de los recursos del sistema lo ayudan a igualar los niveles de rendimiento del mainframe en los sistemas modernizados. Este enfoque mantiene la equivalencia funcional durante la transición a arquitecturas modernas basadas en la nube.
Para utilizar este patrón, configure el sistema e identifique hotspots de rendimiento siguiendo las instrucciones de la sección Epics y aplique las técnicas de optimización que se describen en detalle en la sección Arquitectura.
Requisitos previos y limitaciones
Requisitos previos
Una aplicación modernizada de AWS Blu Age
Privilegios administrativos para instalar herramientas de creación de perfiles y clientes de bases de datos
Comprensión de nivel intermedio del marco AWS Blu Age, la estructura del código generado y la programación en Java
Limitaciones
Las siguientes funciones y características de optimización quedan fuera del alcance de este patrón:
Optimización de la latencia de la red entre los niveles de aplicación
Optimizaciones a nivel de infraestructura mediante tipos de instancias de Amazon Elastic Compute Cloud (Amazon EC2) y optimización del almacenamiento
Pruebas simultáneas de carga de usuarios y pruebas de estrés
Versiones de producto
JProfiler versión 13.0 o posterior (recomendamos la versión más reciente)
Versión 8.14 o posterior de pgAdmin
Arquitectura
Este patrón configura un entorno de creación de perfiles para una aplicación de AWS Blu Age mediante herramientas como JProfiler pgAdmin. Es compatible con la optimización mediante el SQLExecution generador DAOManager y el generador APIs proporcionado por AWS Blu Age.
El resto de esta sección proporciona información detallada y ejemplos para identificar los hotspots de rendimiento y las estrategias de optimización para sus aplicaciones modernizadas. Los pasos de la sección Epics se refieren a esta información para brindar más pautas.
Identificación de los hotspots de rendimiento en las aplicaciones de mainframe modernizadas
En las aplicaciones de mainframe modernizadas, los hotspots de rendimiento son áreas específicas del código que provocan ralentizaciones o ineficiencias significativas. Estos hotspots suelen deberse a las diferencias de arquitectura entre el mainframe y las aplicaciones modernizadas. Para identificar estos obstáculos en el rendimiento y optimizar el rendimiento de su aplicación modernizada, puede utilizar tres técnicas: el registro de SQL, un EXPLAIN plan de consultas y el análisis. JProfiler
Técnica de identificación de hotspots: registro de SQL
Las aplicaciones Java modernas, incluidas las que se han modernizado con AWS Blu Age, tienen funciones integradas para registrar consultas SQL. Puede habilitar registradores específicos en los proyectos de AWS Blu Age para rastrear y analizar las sentencias SQL ejecutadas por su aplicación. Esta técnica es particularmente útil para identificar patrones ineficientes de acceso a las bases de datos, como el exceso de consultas individuales o las llamadas a las bases de datos mal estructuradas, que podrían optimizarse mediante el procesamiento por lotes o el refinamiento de las consultas.
Para implementar el registro SQL en su aplicación modernizada de AWS Blu Age, establezca el nivel de registro en las sentencias SQL del application.properties archivo a fin DEBUG de capturar los detalles de la ejecución de las consultas:
level.org.springframework.beans.factory.support.DefaultListableBeanFactory : WARN level.com.netfective.bluage.gapwalk.runtime.sort.internal: WARN level.org.springframework.jdbc.core.StatementCreatorUtils: DEBUG level.com.netfective.bluage.gapwalk.rt.blu4iv.dao: DEBUG level.com.fiserv.signature: DEBUG level.com.netfective.bluage.gapwalk.database.support.central: DEBUG level.com.netfective.bluage.gapwalk.rt.db.configuration.DatabaseConfiguration: DEBUG level.com.netfective.bluage.gapwalk.rt.db.DatabaseInteractionLoggerUtils: DEBUG level.com.netfective.bluage.gapwalk.database.support.AbstractDatabaseSupport: DEBUG level.com.netfective.bluage.gapwalk.rt: DEBUG
Supervise las consultas de alta frecuencia y de bajo rendimiento utilizando los datos registrados para identificar los objetivos de optimización. Céntrese en las consultas dentro de los procesos por lotes, ya que suelen tener el mayor impacto en el rendimiento.
Técnica de identificación de hotspots: plan EXPLAIN de las consultas
Este método utiliza las capacidades de planificación de consultas de los sistemas de administración de bases de datos relacionales. Puede utilizar comandos como EXPLAIN en PostgreSQL o MySQL o EXPLAIN PLAN en Oracle para examinar cómo la base de datos pretender ejecutar una consulta determinada. El resultado de estos comandos proporciona información valiosa sobre la estrategia de ejecución de la consulta; por ejemplo, si se utilizarán índices o si se realizarán exámenes de tablas completas. Esta información es fundamental para optimizar el rendimiento de las consultas, especialmente en los casos en que una indexación adecuada puede reducir considerablemente el tiempo de ejecución.
Extraiga las consultas SQL más repetitivas de los registros de la aplicación y analice la ruta de ejecución de las consultas con un rendimiento lento mediante el comando EXPLAIN específico de la base de datos. A continuación, se muestra un ejemplo de base de datos de PostgreSQL.
Consulta:
SELECT * FROM tenk1 WHERE unique1 < 100;
Comando de EXPLAIN:
EXPLAIN SELECT * FROM tenk1 where unique1 < 100;
Salida:
Bitmap Heap Scan on tenk1 (cost=5.06..224.98 rows=100 width=244) Recheck Cond: (unique1 < 100) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0) Index Cond: (unique1 < 100)
Puede interpretar la salida de EXPLAIN de la siguiente forma:
Lea el plan
EXPLAINdesde las operaciones más internas hasta las más externas (de abajo hacia arriba).Busque los términos clave. Por ejemplo,
Seq Scanindica un examen completo de la tabla yIndex Scanmuestra el uso del índice.Compruebe los valores de costo: el primer número es el costo inicial y el segundo es el costo total.
Consulte el valor
rowsdel número estimado de filas de salida.
En este ejemplo, el motor de consultas utiliza un examen del índice para buscar las filas coincidentes y, a continuación, prepara solo esas filas (Bitmap Heap Scan). Este método es más eficiente que examinar toda la tabla, a pesar del mayor costo del acceso a las filas individuales.
Las operaciones de examen de las tablas incluidas en la salida de un plan EXPLAIN indican que falta un índice. La optimización requiere la creación de un índice adecuado.
Técnica de identificación de puntos calientes: análisis JProfiler
JProfiler es una completa herramienta de creación de perfiles de Java que le ayuda a resolver los cuellos de botella en el rendimiento al identificar las llamadas lentas a las bases de datos y las llamadas que requieren un uso intensivo de la CPU. Esta herramienta es particularmente eficaz para identificar las consultas SQL lentas y el uso ineficiente de la memoria.
Ejemplo de análisis para la consulta:
select evt. com.netfective.bluage.gapwalk.rt.blu4iv.dao.Blu4ivTableManager.queryNonTrasactional
La vista JProfiler Hot Spots proporciona la siguiente información:
Columna Tiempo
Muestra la duración total de la ejecución (por ejemplo, 329 segundos)
Muestra el porcentaje del tiempo total de la aplicación (por ejemplo, 58,7 %)
Ayuda a identificar las operaciones que más tiempo consumen
Columna Tiempo medio
Muestra la duración de cada ejecución (por ejemplo, 2692 microsegundos)
Indica el rendimiento de cada operación
Ayuda a detectar operaciones lentas
Columna Eventos
Muestra el recuento de ejecuciones (por ejemplo, 122 387 veces)
Indica la frecuencia de la operación
Ayuda a identificar los métodos a los que se llama con frecuencia
Para ver los resultados del ejemplo:
Frecuencia alta: 122 387 ejecuciones indican un potencial de optimización
Problema de rendimiento: 2692 microsegundos durante un tiempo medio sugieren poca eficiencia
Impacto crítico: el 58,7 % del tiempo total indica un cuello de botella importante
JProfiler puede analizar el comportamiento de la aplicación en tiempo de ejecución para revelar puntos críticos que podrían no ser evidentes mediante el análisis de código estático o el registro de SQL. Estas métricas lo ayudan a identificar las operaciones que necesitan optimizarse y a determinar la estrategia de optimización que sería más eficaz. Para obtener más información sobre JProfiler las funciones, consulte la JProfiler documentación
Si utiliza estas tres técnicas (registro de SQL, EXPLAIN plan de consultas y JProfiler) en combinación, puede obtener una visión holística de las características de rendimiento de la aplicación. Al identificar y abordar los hotspots de rendimiento más críticos, puede cerrar la brecha de rendimiento entre la aplicación de mainframe original y el sistema modernizado basado en la nube.
Tras identificar los hotspots de rendimiento de la aplicación, puede aplicar estrategias de optimización, que se explican en la siguiente sección.
Estrategias de optimización para la modernización del mainframe
En esta sección se describen las estrategias clave para optimizar las aplicaciones que se han modernizado a partir de sistemas de mainframe. Se centra en tres estrategias: utilizar las existentes APIs, implementar un almacenamiento en caché eficaz y optimizar la lógica empresarial.
Estrategia de optimización: utilizar la existente APIs
AWS Blu Age proporciona varias interfaces DAO potentes APIs que puede utilizar para optimizar el rendimiento. Dos interfaces principales, DAOManager y SQLExecution Builder, ofrecen capacidades para mejorar el rendimiento de las aplicaciones.
DAOManager
DAOManager sirve como interfaz principal para las operaciones de bases de datos en aplicaciones modernizadas. Ofrece varios métodos para mejorar las operaciones de las bases de datos y mejorar el rendimiento de las aplicaciones, especialmente para las operaciones sencillas de creación, lectura, actualización y eliminación (CRUD, por sus siglas en inglés) y procesamiento por lotes.
Uso SetMaxResults. En la DAOManager API, puede usar el SetMaxResultsmétodo para especificar el número máximo de registros que se van a recuperar en una sola operación de base de datos. De forma predeterminada, DAOManager recupera solo 10 registros a la vez, lo que puede provocar varias llamadas a la base de datos al procesar conjuntos de datos de gran tamaño. Utilice esta optimización cuando la aplicación tenga que procesar una gran cantidad de registros y actualmente esté realizando varias llamadas a bases de datos para recuperarlos. Esto resulta particularmente útil en situaciones de procesamiento por lotes en las que se realiza una iteración a través de un conjunto de datos de gran tamaño. En el siguiente ejemplo, el código de la izquierda (antes de la optimización) usa el valor de recuperación de datos predeterminado de 10 registros. El código de la derecha (después de la optimización) se configura setMaxResultspara recuperar 100 000 registros a la vez.

nota
Elija lotes de mayor tamaño con cuidado y compruebe el tamaño del objeto, ya que esta optimización aumenta el consumo de memoria.
Sustituir SetOnGreatorOrEqual por SetOnEqual. Esta optimización implica cambiar el método que se utiliza para establecer la condición de recuperación de registros. El SetOnGreatorOrEqualmétodo recupera los registros que son mayores o iguales a un valor especificado, mientras que solo SetOnEqualrecupera los registros que coinciden exactamente con el valor especificado.
SetOnEqualUtilícelo como se ilustra en el siguiente ejemplo de código, cuando sepa que necesita coincidencias exactas y esté utilizando actualmente el SetOnGreatorOrEqualmétodo seguido de readNextEqual(). Esta optimización reduce la recuperación innecesaria de datos.

Utilice operaciones de escritura y actualización por lotes. Puede utilizar las operaciones por lotes para agrupar varias operaciones de escritura o actualización en una sola transacción de la base de datos. Esto reduce el número de llamadas a la base de datos y puede mejorar considerablemente el rendimiento de las operaciones que implican varios registros.
En el siguiente ejemplo, el código de la izquierda realiza operaciones de escritura en bucle, lo que ralentiza el rendimiento de la aplicación. Puede optimizar este código mediante una operación de escritura por lotes: durante cada iteración del bucle
WHILE, se agregan registros a un lote hasta que el tamaño del lote alcance un tamaño predeterminado de 100. A continuación, puede vaciar el lote cuando alcance el tamaño de lote predeterminado y, a continuación, vaciar los registros restantes en la base de datos. Esto resulta especialmente útil en las situaciones en las que se procesan conjuntos de datos de gran tamaño que requieren actualizaciones.
Agregue índices. Agregar índices es una optimización a nivel de base de datos que puede mejorar considerablemente el rendimiento de las consultas. Los índices permiten que la base de datos localice rápidamente las filas con un valor de columna específico sin tener que examinar toda la tabla. Utilice la indexación en las columnas que se utilizan con frecuencia en las cláusulas
WHERE, las condicionesJOINo las instruccionesORDER BY. Esto es particularmente importante para las tablas de gran tamaño o cuando la recuperación rápida de datos es fundamental.
SQLExecutionConstructor
SQLExecutionBuilder es una API flexible que puede utilizar para controlar las consultas SQL que se ejecutarán, recuperar solo determinadas columnas mediante SELECT el uso de nombres de tablas dinámicas y utilizar nombres de tablas dinámicas. INSERT En el siguiente ejemplo, SQLExecutor Builder usa una consulta personalizada que usted defina.

Elegir entre DAOManager y SQLExecution Builder
La elección entre estas opciones APIs depende de su caso de uso específico:
Úselo DAOManager cuando desee que AWS Blu Age Runtime genere las consultas SQL en lugar de escribirlas usted mismo.
Elija SQLExecution Builder cuando necesite escribir consultas SQL para aprovechar las funciones específicas de la base de datos o escribir consultas SQL óptimas.
Estrategia de optimización: almacenamiento en caché
En las aplicaciones modernizadas, la implementación de estrategias de almacenamiento en caché eficaces puede reducir significativamente las llamadas a las bases de datos y mejorar los tiempos de respuesta. Esto ayuda a cerrar la brecha de rendimiento entre los entornos de mainframe y en la nube.
En las aplicaciones de AWS Blu Age, las implementaciones de almacenamiento en caché sencillas utilizan estructuras de datos internas, como mapas hash o listas de matrices, por lo que no es necesario configurar una solución de almacenamiento en caché externa que requiera una reestructuración de costes y código. Este enfoque es particularmente eficaz para los datos a los que se accede con frecuencia, pero que no cambian a menudo. Al implementar el almacenamiento en caché, tenga en cuenta las limitaciones de memoria y los patrones de actualización para mantener el rendimiento y las ventajas de rendimiento reales de los datos almacenados en caché.
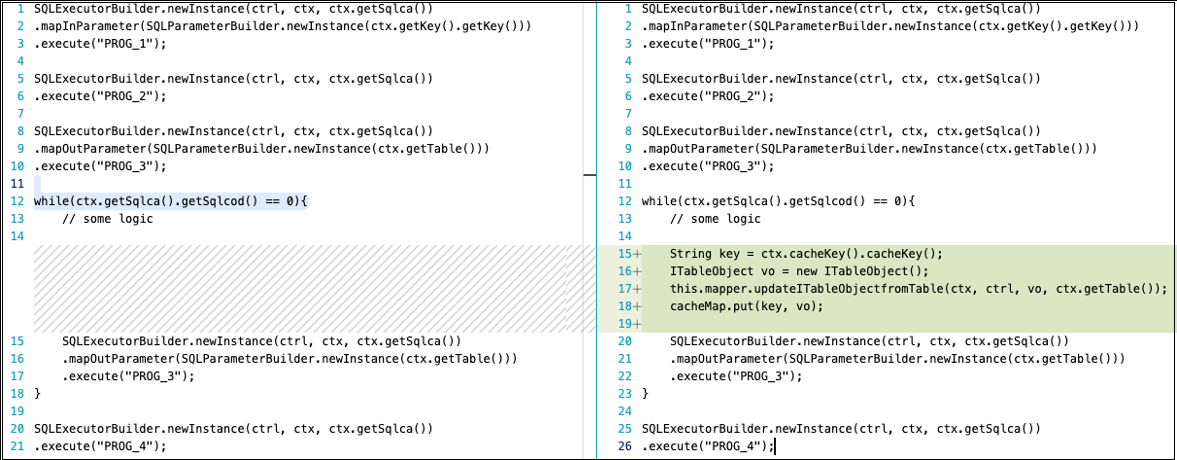
La clave para un almacenamiento en caché exitoso es identificar los datos correctos que se van a almacenar en caché. En el siguiente ejemplo, el código de la izquierda siempre lee los datos de la tabla, mientras que el código de la derecha lee los datos de la tabla cuando el mapa hash local no tiene un valor para una clave determinada. cacheMap es un objeto de mapa hash que se crea en el contexto del programa y se borra con el método de limpieza del contexto del programa.
Almacenamiento en caché con: DAOManager

Almacenamiento en caché con Builder: SQLExecution
Estrategia de optimización: optimización de la lógica empresarial
La optimización de la lógica empresarial se centra en reestructurar el código generado automáticamente por AWS Blu Age para alinearlo mejor con las capacidades de la arquitectura moderna. Esto se hace necesario cuando el código generado mantiene la misma estructura lógica que el código de mainframe heredado, lo que puede no ser óptimo para los sistemas modernos. El objetivo es mejorar el rendimiento y, al mismo tiempo, mantener la equivalencia funcional de la aplicación original.
Este enfoque de optimización no se centra solo en los simples ajustes de la API y las estrategias de almacenamiento en caché. Implica cambios en la forma en que la aplicación procesa los datos e interactúa con la base de datos. Algunas de las optimizaciones más comunes son evitar operaciones de lectura innecesarias para las actualizaciones sencillas, eliminar las llamadas redundantes a las bases de datos y reestructurar los patrones de acceso a los datos para adaptarlos mejor a la arquitectura moderna de la aplicación. A continuación se muestran algunos ejemplos:
Actualizar los datos directamente en la base de datos.Reestructure su lógica empresarial mediante actualizaciones directas de SQL en lugar de DAOManager realizar múltiples operaciones con bucles. Por ejemplo, el siguiente código (lado izquierdo) realiza varias llamadas a la base de datos y utiliza memoria excesiva. En concreto, utiliza varias operaciones de lectura y escritura en bases de datos dentro de bucles, actualizaciones específicas en lugar de hacer procesamientos por lotes y crear objetos innecesarios para cada iteración.
El siguiente código optimizado (en la derecha) utiliza una sola operación de actualización de Direct SQL. En concreto, utiliza una sola llamada a la base de datos en lugar de realizar varias llamadas y no requiere bucles, ya que todas las actualizaciones se gestionan en una sola instrucción. Esta optimización proporciona un mejor rendimiento y una mejor utilización de los recursos y reduce la complejidad. Evita la inyección de código SQL, proporciona un mejor almacenamiento en caché del plan de consultas y ayuda a mejorar la seguridad.

nota
Utilice siempre consultas parametrizadas para evitar la inyección de código SQL y garantizar una administración adecuada de las transacciones.
Reducción de las llamadas redundantes a las bases de datos. Las llamadas redundantes a las bases de datos pueden afectar significativamente al rendimiento de las aplicaciones, especialmente cuando se producen dentro de bucles. Una técnica de optimización sencilla pero eficaz consiste en evitar repetir la misma consulta a la base de datos varias veces. En la siguiente comparación de código se demuestra cómo al mover la llamada a la base de datos
retrieve()fuera del bucle se evita la ejecución redundante de consultas idénticas, lo que mejora la eficiencia.
Reducción de las llamadas a la base de datos mediante la cláusula SQL
JOIN. Implemente SQLExecution Builder para minimizar las llamadas a la base de datos. SQLExecutionBuilder proporciona un mayor control sobre la generación de SQL y es particularmente útil para consultas complejas que DAOManager no se pueden gestionar de manera eficiente. Por ejemplo, el código siguiente utiliza varias DAOManager llamadas:List<Employee> employees = daoManager.readAll(); for(Employee emp : employees) { Department dept = deptManager.readById(emp.getDeptId()); // Additional call for each employee Project proj = projManager.readById(emp.getProjId()); // Another call for each employee processEmployeeData(emp, dept, proj); }El código optimizado usa una sola llamada a la base de datos en SQLExecution Builder:
SQLExecutionBuilder builder = new SQLExecutionBuilder(); builder.append("SELECT e.*, d.name as dept_name, p.name as proj_name"); builder.append("FROM employee e"); builder.append("JOIN department d ON e.dept_id = d.id"); builder.append("JOIN project p ON e.proj_id = p.id"); builder.append("WHERE e.status = ?", "ACTIVE"); List<Map<String, Object>> results = builder.execute(); // Single database call for(Map<String, Object> result : results) { processComplexData(result); }
Uso conjunto de estrategias de optimización
Estas tres estrategias funcionan de forma sinérgica: APIs proporcionan las herramientas para un acceso eficiente a los datos, el almacenamiento en caché reduce la necesidad de recuperar datos de forma repetida y la optimización de la lógica empresarial garantiza que APIs se utilicen de la manera más eficaz posible. La supervisión y el ajuste periódicos de estas optimizaciones garantizan una mejora continua del rendimiento y, al mismo tiempo, mantienen la fiabilidad y la funcionalidad de la aplicación modernizada. La clave del éxito reside en comprender cuándo y cómo aplicar cada estrategia en función de las características y los objetivos de rendimiento de la aplicación.
Tools (Herramientas)
JProfiler
es una herramienta de creación de perfiles de Java diseñada para desarrolladores e ingenieros de rendimiento. Analiza las aplicaciones Java y ayuda a identificar los cuellos de botella en el rendimiento, las pérdidas de memoria y los problemas de subprocesos. JProfiler ofrece perfiles de CPU, memoria y subprocesos, así como supervisión de bases de datos y máquinas virtuales Java (JVM) para proporcionar información sobre el comportamiento de las aplicaciones. nota
Como alternativa JProfiler, puede utilizar Java
VisualVM. Se trata de una herramienta gratuita de código abierto de creación de perfiles de rendimiento y supervisión para aplicaciones de Java que permite supervisar en tiempo real el uso de la CPU, el consumo de memoria, la administración de subprocesos y las estadísticas de recopilación de elementos no utilizados. Dado que Java VisualVM es una herramienta JDK integrada, resulta más JProfiler rentable que para las necesidades básicas de creación de perfiles. pgAdmin
es una plataforma de administración y desarrollo de código abierto para PostgreSQL. Proporciona una interfaz gráfica que permite crear, mantener y utilizar objetos de bases de datos. Puede usar pgAdmin para realizar una amplia gama de tareas, desde escribir consultas SQL sencillas hasta desarrollar bases de datos complejas. Algunas de sus características son un editor de código SQL que resalta la sintaxis, un editor de código en el servidor, un agente de programación para SQL, un intérprete de comandos y tareas por lotes, y compatibilidad con todas las características de PostgreSQL tanto para usuarios sin experiencia como con experiencia de PostgreSQL.
Prácticas recomendadas
Identificación de hotspots de rendimiento:
Documente las métricas de rendimiento de referencia antes de iniciar las optimizaciones.
Establezca objetivos claros de mejora del rendimiento en función de los requisitos empresariales.
Al realizar evaluaciones comparativas, desactive la creación de registros detallados, ya que esto puede afectar al rendimiento.
Configure un conjunto de pruebas de rendimiento y ejecútelo periódicamente.
Utilice la versión más reciente de pgAdmin. (Las versiones más antiguas no admiten el plan
EXPLAINde consultas).Para realizar una evaluación comparativa, desconéctese una vez que se hayan JProfiler completado las optimizaciones, ya que esto aumenta la latencia.
Para realizar evaluaciones comparativas, asegúrese de ejecutar el servidor en modo de inicio en lugar de en modo de depuración, ya que el modo de depuración aumenta la latencia.
Estrategias de optimización:
Configure SetMaxResultslos valores en el
application.yamlarchivo para especificar lotes del tamaño correcto de acuerdo con las especificaciones de su sistema.Configure SetMaxResultslos valores en función del volumen de datos y las restricciones de memoria.
Cambie SetOnGreatorOrEquala SetOnEqualsolo cuando se realicen llamadas posteriores
.readNextEqual().En las operaciones de escritura o actualización por lotes, gestione el último lote por separado, ya que podría ser más pequeño que el tamaño del lote configurado y la operación de escritura o actualización podría pasarlo por alto.
Almacenamiento en caché:
Los campos que se introducen para el almacenamiento en caché en
processImpl, que cambian con cada ejecución, siempre deben definirse en el contexto de eseprocessImpl. Los campos también deben borrarse mediante el métododoReset()ocleanUp().Cuando implemente el almacenamiento en caché en memoria, ajuste el tamaño de la caché. Las cachés muy grandes que se almacenan en la memoria pueden ocupar todos los recursos, lo que podría afectar al rendimiento general de la aplicación.
SQLExecutionConstructor:
Para las consultas que planea usar en SQLExecution Builder, utilice nombres clave como
PROGRAMNAME_STATEMENTNUMBER.Cuando utilice SQLExecution Builder, compruebe siempre el
Sqlcodcampo. Este campo contiene un valor que especifica si la consulta se ejecutó correctamente o si encontró algún error.Utilice consultas parametrizadas para evitar la inyección de código SQL.
Optimización de la lógica empresarial:
Mantenga la equivalencia funcional al reestructurar el código y ejecute pruebas de regresión y comparaciones de bases de datos para el subconjunto de programas correspondiente.
Mantenga instantáneas de la creación de perfiles para poder compararlas.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Instalar y configurar. JProfiler |
| Desarrollador de aplicaciones |
Instale y configure pgAdmin. | En este paso, debe instalar y configurar un cliente de base de datos para que realice consultas en la base de datos. Este patrón utiliza una base de datos PostgreSQL y pgAdmin como cliente de base de datos. Si utiliza otro motor de base de datos, siga la documentación del cliente de base de datos correspondiente.
| Desarrollador de aplicaciones |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Habilite el registro de consultas SQL en su aplicación AWS Blu Age. | Habilite los registradores para el registro de consultas SQL en el | Desarrollador de aplicaciones |
Genere y analice los planes | Para obtener información detallada, consulte la sección Arquitectura. | Desarrollador de aplicaciones |
Cree una JProfiler instantánea para analizar un caso de prueba de rendimiento lento. |
| Desarrollador de aplicaciones |
Analice la JProfiler instantánea para identificar los cuellos de botella en el rendimiento. | Siga estos pasos para analizar la instantánea. JProfiler
Para obtener más información sobre su uso JProfiler, consulte la sección Arquitectura y la JProfiler documentación | Desarrollador de aplicaciones |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Establezca una línea de base de rendimiento antes de implementar las optimizaciones. |
| Desarrollador de aplicaciones |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Optimice las llamadas de lectura. | Optimice la recuperación de datos mediante el DAOManager SetMaxResultsmétodo. Para obtener más información sobre este enfoque, consulte la sección Arquitectura. | Desarrollador de aplicaciones, DAOManager |
Refactorice la lógica empresarial para evitar varias llamadas a la base de datos. | Reduzca las llamadas a la base de datos mediante una cláusula | Desarrollador de aplicaciones, SQLExecution constructor |
Refactorice el código para usar el almacenamiento en caché para reducir la latencia de las llamadas de lectura. | Para obtener información sobre esta técnica, consulte Almacenamiento en caché en la sección Arquitectura. | Desarrollador de aplicaciones |
Reescriba el código ineficiente que utiliza varias DAOManager operaciones para realizar operaciones de actualización sencillas. | Para obtener más información sobre cómo actualizar los datos directamente en la base de datos, consulte Optimización de la lógica empresarial en la sección Arquitectura. | Desarrollador de aplicaciones |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Valide cada cambio de optimización de forma iterativa y, al mismo tiempo, mantenga la equivalencia funcional. |
notaEl uso de métricas de línea de base como referencia garantiza una medición precisa del impacto de cada optimización y, al mismo tiempo, mantiene la fiabilidad del sistema. | Desarrollador de aplicaciones |
Resolución de problemas
| Problema | Solución |
|---|---|
Al ejecutar la aplicación moderna, verá una excepción con el error | Para resolver este problema, siga estos pasos:
|
Ha agregado índices, pero no ve ninguna mejora de rendimiento. | Siga estos pasos para asegurarse de que el motor de consultas utilice el índice:
|
Te encuentras con una excepción out-of-memory. | Compruebe que el código libere la memoria almacenada en la estructura de datos. |
Las operaciones de escritura por lotes hacen que falten registros en la tabla | Revise el código para asegurarse de que se realice una operación de escritura adicional cuando el recuento de lotes no es cero. |
El registro de SQL no aparece en los registros de la aplicación. |
|
Recursos relacionados
