Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Ejecución de consultas SQL en Amazon Redshift mediante Terraform
Sylvia Qi y Aditya Ambati, Amazon Web Services
Resumen
El uso de la infraestructura como código (IaC) para la implementación y la administración de Amazon Redshift es una práctica habitual en el país. DevOps La IaC facilita la implementación y la configuración de varios recursos de Amazon Redshift, como clústeres, instantáneas y grupos de parámetros. Sin embargo, la IaC no se extiende a la administración de los recursos de las bases de datos, como tablas, esquemas, vistas y procedimientos almacenados. Estos elementos de la base de datos se administran mediante consultas SQL y las herramientas de IaC no los admiten directamente. Si bien existen soluciones y herramientas para administrar estos recursos, es posible que prefiera no introducir herramientas adicionales en su conjunto de tecnologías.
Este patrón describe una metodología que utiliza Terraform para implementar los recursos de bases de datos de Amazon Redshift, incluidas tablas, esquemas, vistas y procedimientos almacenados. El patrón distingue entre dos tipos de consultas SQL:
Consultas no repetibles: estas consultas se ejecutan una vez durante la implementación inicial de Amazon Redshift para establecer los componentes esenciales de la base de datos.
Consultas repetibles: estas consultas son inmutables y se pueden volver a ejecutar sin que ello afecte a la base de datos. La solución usa Terraform para supervisar los cambios en las consultas repetibles y aplicarlos en consecuencia.
Para obtener más información, consulte el tutorial de la solución en Información adicional.
Requisitos previos y limitaciones
Requisitos previos
Debe tener una máquina de implementación activa Cuenta de AWS e instalar lo siguiente:
AWS Command Line Interface (AWS CLI)
Un AWS CLI perfil configurado con permisos de Amazon Redshift read/write
La versión 1.6.2 o posterior de Terraform
Limitaciones
Esta solución admite una única base de datos de Amazon Redshift porque Terraform solo permite la creación de una base de datos durante la creación del clúster.
Este patrón no incluye pruebas para validar los cambios en las consultas repetibles antes de aplicarlos. Le recomendamos que incorpore dichas pruebas para mejorar la fiabilidad.
Para ilustrar la solución, este patrón proporciona un archivo
redshift.tfde muestra que utiliza un archivo de estado local de Terraform. Sin embargo, para los entornos de producción, le recomendamos encarecidamente que utilice un archivo de estado remoto con un mecanismo de bloqueo para mejorar la estabilidad y la colaboración.Algunos Servicios de AWS no están disponibles en todos. Regiones de AWS Para obtener información sobre la disponibilidad en regiones, consulte Servicios de AWS by Region
. Para ver los puntos de conexión específicos, consulte Service endpoints and quotas y elija el enlace del servicio.
Versiones de producto
Esta solución se ha desarrollado y probado en el parche 179 de Amazon Redshift.
Repositorio de código
El código de este patrón está disponible en el repositorio GitHub amazon-redshift-sql-deploy-terraform
Arquitectura
El siguiente diagrama ilustra cómo Terraform administra los recursos de la base de datos de Amazon Redshift gestionando consultas SQL repetibles y no repetibles.
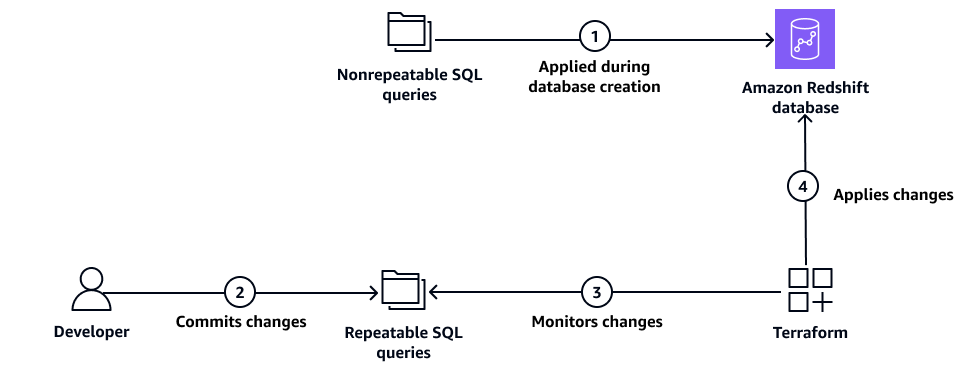
En el diagrama se muestran los siguientes pasos:
Terraform aplica consultas SQL no repetibles durante la implementación inicial del clúster de Amazon Redshift.
El desarrollador confirma los cambios en las consultas SQL repetibles.
Terraform supervisa los cambios en las consultas SQL repetibles.
Terraform aplica consultas SQL repetibles a la base de datos de Amazon Redshift.
La solución que proporciona este patrón se basa en el módulo de Terraform para Amazon Redshiftterraform_data resources, que invoca un script de Python personalizado para ejecutar consultas SQL mediante la operación de la API Amazon ExecuteStatementRedshift. En consecuencia, el módulo puede hacer lo siguiente:
Implemente cualquier cantidad de recursos de base de datos mediante consultas SQL después de aprovisionar la base de datos.
Supervise continuamente los cambios en las consultas SQL repetibles y aplique esos cambios con Terraform.
Para obtener más información, consulte el tutorial de la solución en Información adicional.
Tools (Herramientas)
Servicios de AWS
Amazon Redshift es un servicio de almacén de datos completamente administrado que opera a escala de petabytes en la Nube de AWS.
Otras herramientas
Prácticas recomendadas
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Clone el repositorio. | Para clonar el repositorio de Git que contiene el código de Terraform para aprovisionar un clúster de Amazon Redshift, utilice el siguiente comando.
| DevOps ingeniero |
Actualice las variables de Terraform. | Para personalizar la implementación del clúster de Amazon Redshift de acuerdo con sus requisitos específicos, actualice los siguientes parámetros del archivo
| DevOps ingeniero |
Implemente los recursos con Terraform. |
| DevOps ingeniero |
(Opcional) Ejecute consultas SQL adicionales. | El repositorio de ejemplos proporciona varias consultas SQL con fines de demostración. Para ejecutar sus propias consultas SQL, agréguelas a las siguientes carpetas:
|
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Supervise la implementación de las instrucciones SQL. | Puede supervisar los resultados de las ejecuciones de SQL en un clúster de Amazon Redshift. Para ver ejemplos de resultados que muestran una ejecución de SQL fallida y correcta, consulte Ejemplos de instrucciones SQL en Información adicional. | DBA, ingeniero DevOps |
Eliminación de recursos. | Para eliminar todos los recursos implementados por Terraform, ejecute el siguiente comando.
| DevOps ingeniero |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Valide los datos en el clúster de Amazon Redshift. |
| ADMINISTRADOR DE BASES DE DATOS, AWS DevOps |
Recursos relacionados
AWS documentación
Otros recursos
Comando: apply
(documentación de Terraform)
Información adicional
Tutorial de la solución
Para usar la solución, debe organizar las consultas SQL de Amazon Redshift de una manera específica. Todas las consultas SQL deben almacenarse en archivos con una extensión .sql.
En el ejemplo de código que se proporciona con este patrón, las consultas SQL se organizan en la siguiente estructura de carpetas. Puede modificar el código (sql-queries.tf y sql-queries.py) para que funcione con cualquier estructura que se adapte a su caso de uso exclusivo.
/bootstrap |- Any # of files |- Any # of sub-folders /nonrepeatable |- Any # of files |- Any # of sub-folders /repeatable /udf |- Any # of files |- Any # of sub-folders /table |- Any # of files |- Any # of sub-folders /view |- Any # of files |- Any # of sub-folders /stored-procedure |- Any # of files |- Any # of sub-folders /finalize |- Any # of files |- Any # of sub-folders
Dada la estructura de carpetas anterior, durante la implementación del clúster de Amazon Redshift, Terraform ejecuta las consultas en el siguiente orden:
/bootstrap/nonrepeatable/repeatable/finalize
La carpeta /repeatable contiene las subcarpetas /udf, /table, /view y /stored-procedure. Estas subcarpetas indican el orden en el que Terraform ejecuta las consultas SQL.
El script de Python que ejecuta las consultas SQL es sql-queries.py. En primer lugar, el script lee todos los archivos y subcarpetas de un directorio fuente específico, por ejemplo, el parámetro sql_path_bootstrap. A continuación, el script ejecuta las consultas mediante una llamada a la operación de la API Amazon ExecuteStatementRedshift. Es posible que tenga una o más consultas SQL en un archivo. El siguiente fragmento de código muestra la función de Python que ejecuta instrucciones SQL almacenadas en un archivo en un clúster de Amazon Redshift.
def execute_sql_statement(filename, cluster_id, db_name, secret_arn, aws_region): """Execute SQL statements in a file""" redshift_client = boto3.client( 'redshift-data', region_name=aws_region) contents = get_contents_from_file(filename), response = redshift_client.execute_statement( Sql=contents[0], ClusterIdentifier=cluster_id, Database=db_name, WithEvent=True, StatementName=filename, SecretArn=secret_arn ) ...
El script sql-queries.tf de Terraform crea los recursos terraform_datasql-queries.py. Hay un recurso terraform_data para cada una de las cuatro carpetas: /bootstrap, /nonrepeatable, /repeatable y /finalize. El siguiente fragmento de código muestra el recurso terraform_data que ejecuta las consultas SQL de la carpeta /bootstrap.
locals { program = "${path.module}/sql-queries.py" redshift_cluster_name = try(aws_redshift_cluster.this[0].id, null) } resource "terraform_data" "run_bootstrap_queries" { count = var.create && var.run_nonrepeatable_queries && (var.sql_path_bootstrap != "") && (var.snapshot_identifier == null) ? 1 : 0 depends_on = [aws_redshift_cluster.this[0]] provisioner "local-exec" { command = "python3 ${local.program} ${var.sql_path_bootstrap} ${local.redshift_cluster_name} ${var.database_name} ${var.redshift_secret_arn} ${local.aws_region}" } }
Puede controlar si desea ejecutar estas consultas mediante las siguientes variables. Si no desea ejecutar consultas ensql_path_bootstrap, sql_path_nonrepeatable, sql_path_repeatable o sql_path_finalize, establezca sus valores en "".
run_nonrepeatable_queries = true run_repeatable_queries = true sql_path_bootstrap = "src/redshift/bootstrap" sql_path_nonrepeatable = "src/redshift/nonrepeatable" sql_path_repeatable = "src/redshift/repeatable" sql_path_finalize = "src/redshift/finalize"
Cuando se ejecuta terraform apply, Terraform tiene en cuenta el recurso terraform_data agregado una vez que se ha completado el script, independientemente de los resultados del script. Si algunas consultas de SQL fallaron y desea volver a ejecutarlas, puede eliminar manualmente el recurso del estado de Terraform y volver a ejecuta terraform apply. Por ejemplo, el siguiente comando elimina el recurso run_bootstrap_queries del estado de Terraform.
terraform state rm module.redshift.terraform_data.run_bootstrap_queries[0]
El siguiente ejemplo de código muestra cómo el recurso run_repeatable_queries supervisa los cambios en la carpeta repeatable mediante el hash sha256terraform apply.
resource "terraform_data" "run_repeatable_queries" { count = var.create_redshift && var.run_repeatable_queries && (var.sql_path_repeatable != "") ? 1 : 0 depends_on = [terraform_data.run_nonrepeatable_queries] # Continuously monitor and apply changes in the repeatable folder triggers_replace = { dir_sha256 = sha256(join("", [for f in fileset("${var.sql_path_repeatable}", "**") : filesha256("${var.sql_path_repeatable}/${f}")])) } provisioner "local-exec" { command = "python3 ${local.sql_queries} ${var.sql_path_repeatable} ${local.redshift_cluster_name} ${var.database_name} ${var.redshift_secret_arn}" } }
Para refinar el código, puede implementar un mecanismo que detecte y aplique los cambios solo a los archivos que se hayan actualizado dentro de la carpeta repeatable, en lugar de aplicarlos a todos los archivos de forma indiscriminada.
Ejemplos de instrucciones SQL
El siguiente resultado muestra una ejecución fallida de SQL, junto con un mensaje de error.
module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): Executing: ["/bin/sh" "-c" "python3 modules/redshift/sql-queries.py src/redshift/nonrepeatable testcluster-1 db1 arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:/redshift/master_user/password-8RapGH us-east-1"] module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): ------------------------------------------------------------------- module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): src/redshift/nonrepeatable/table/admin/admin.application_family.sql module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): ------------------------------------------------------------------- module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): Status: FAILED module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): SQL execution failed. module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): Error message: ERROR: syntax error at or near ")" module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): Position: 244 module.redshift.terraform_data.run_nonrepeatable_queries[0]: Creation complete after 3s [id=ee50ba6c-11ae-5b64-7e2f-86fd8caa8b76]
El siguiente resultado muestra una ejecución correcta de SQL.
module.redshift.terraform_data.run_bootstrap_queries[0]: Provisioning with 'local-exec'... module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): Executing: ["/bin/sh" "-c" "python3 modules/redshift/sql-queries.py src/redshift/bootstrap testcluster-1 db1 arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:/redshift/master_user/password-8RapGH us-east-1"] module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): ------------------------------------------------------------------- module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): src/redshift/bootstrap/db.sql module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): ------------------------------------------------------------------- module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): Status: FINISHED module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): SQL execution successful. module.redshift.terraform_data.run_bootstrap_queries[0]: Creation complete after 2s [id=d565ef6d-be86-8afd-8e90-111e5ea4a1be]
