Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cree un MLOps flujo de trabajo con Amazon SageMaker AI y Azure DevOps
Deepika Kumar, Sara van de Moosdijk y Philips Kokoh Prasetyo, Amazon Web Services
Resumen
Las operaciones de aprendizaje automático (MLOps) son un conjunto de prácticas que automatizan y simplifican los flujos de trabajo y las implementaciones del aprendizaje automático (ML). MLOps se centra en automatizar el ciclo de vida del aprendizaje automático. Ayuda a garantizar que los modelos no solo se desarrollen, sino que también se implementen, supervisen y reentrenen de manera sistemática y repetida. Aporta DevOps principios al ML. MLOps da como resultado un despliegue más rápido de los modelos de aprendizaje automático, una mayor precisión a lo largo del tiempo y una mayor seguridad de que proporcionan un valor empresarial real.
Las organizaciones suelen tener DevOps herramientas y soluciones de almacenamiento de datos existentes antes de iniciar su MLOps viaje. Este patrón muestra cómo aprovechar los puntos fuertes de Microsoft Azure y AWS. Le ayuda a integrar Azure DevOps con Amazon SageMaker AI para crear un MLOps flujo de trabajo.
La solución simplifica el trabajo entre Azure y AWS. Puede usar Azure para el desarrollo y AWS el aprendizaje automático. Favorece un proceso eficaz para crear modelos de machine learning de principio a fin, que incluye la gestión de datos, el entrenamiento y la implementación en AWS. Para aumentar la eficiencia, administra estos procesos a través de las DevOps canalizaciones de Azure. La solución es aplicable a las operaciones de modelos básicos (FMOps) y a las operaciones de modelos de lenguaje de gran tamaño (LLMOps) en la IA generativa, lo que incluye ajustes precisos, bases de datos vectoriales y administración rápida.
Requisitos previos y limitaciones
Requisitos previos
Suscripción a Azure: acceso a los servicios de Azure, como Azure DevOps, para configurar las canalizaciones de integración e implementación continuas (CI/CD).
Cuenta de AWS activa: permisos para usar lo que Servicios de AWS se usa en este patrón.
Datos: acceso a datos históricos para entrenar el modelo de machine learning.
Familiaridad con los conceptos de ML: comprensión de Python, Jupyter Notebooks y desarrollo de modelos de machine learning.
Configuración de seguridad: configuración adecuada de los roles, políticas y permisos en Azure y AWS para garantizar la transferencia y el acceso seguros a los datos.
Base de datos vectorial (opcional): si utiliza un enfoque de generación aumentada por recuperación (RAG) y un servicio de terceros para la base de datos vectorial, necesitará acceder a la base de datos vectorial externa.
Limitaciones
Esta guía no trata las transferencias de datos seguras entre nubes. Para obtener más información sobre de las transferencias de datos entre nubes, consulte Soluciones de AWS para sistemas híbridos y multinube
. Las soluciones multinube pueden aumentar la latencia del procesamiento de datos en tiempo real y la inferencia del modelo.
Esta guía proporciona un ejemplo de una MLOps arquitectura de cuentas múltiples. Los ajustes son necesarios en función del aprendizaje automático y la AWS estrategia.
Esta guía no describe el uso de AI/ML servicios distintos de Amazon SageMaker AI.
Algunos Servicios de AWS no están disponibles en todos Regiones de AWS. Para obtener información sobre la disponibilidad en regiones, consulte Servicios de AWS by Region
. Para ver los puntos de conexión específicos, consulte la página Service endpoints and quotas y elija el enlace del servicio.
Arquitectura
Arquitectura de destino
La arquitectura de destino integra Azure DevOps con Amazon SageMaker AI, lo que crea un flujo de trabajo de aprendizaje automático entre nubes. Utiliza Azure para CI/CD los procesos y la SageMaker IA para el entrenamiento y la implementación de modelos de aprendizaje automático. Describe el proceso de obtención de datos (de fuentes como Amazon S3, Snowflake y Azure Data Lake) mediante el desarrollo e implementación de modelos. Los componentes clave incluyen CI/CD las canalizaciones para la creación e implementación de modelos, la preparación de datos, la administración de la infraestructura y Amazon SageMaker AI para el entrenamiento y el ajuste, la evaluación y la implementación de modelos de aprendizaje automático. Esta arquitectura está diseñada para proporcionar flujos de trabajo de ML eficientes, automatizados y escalables en todas las plataformas en la nube.
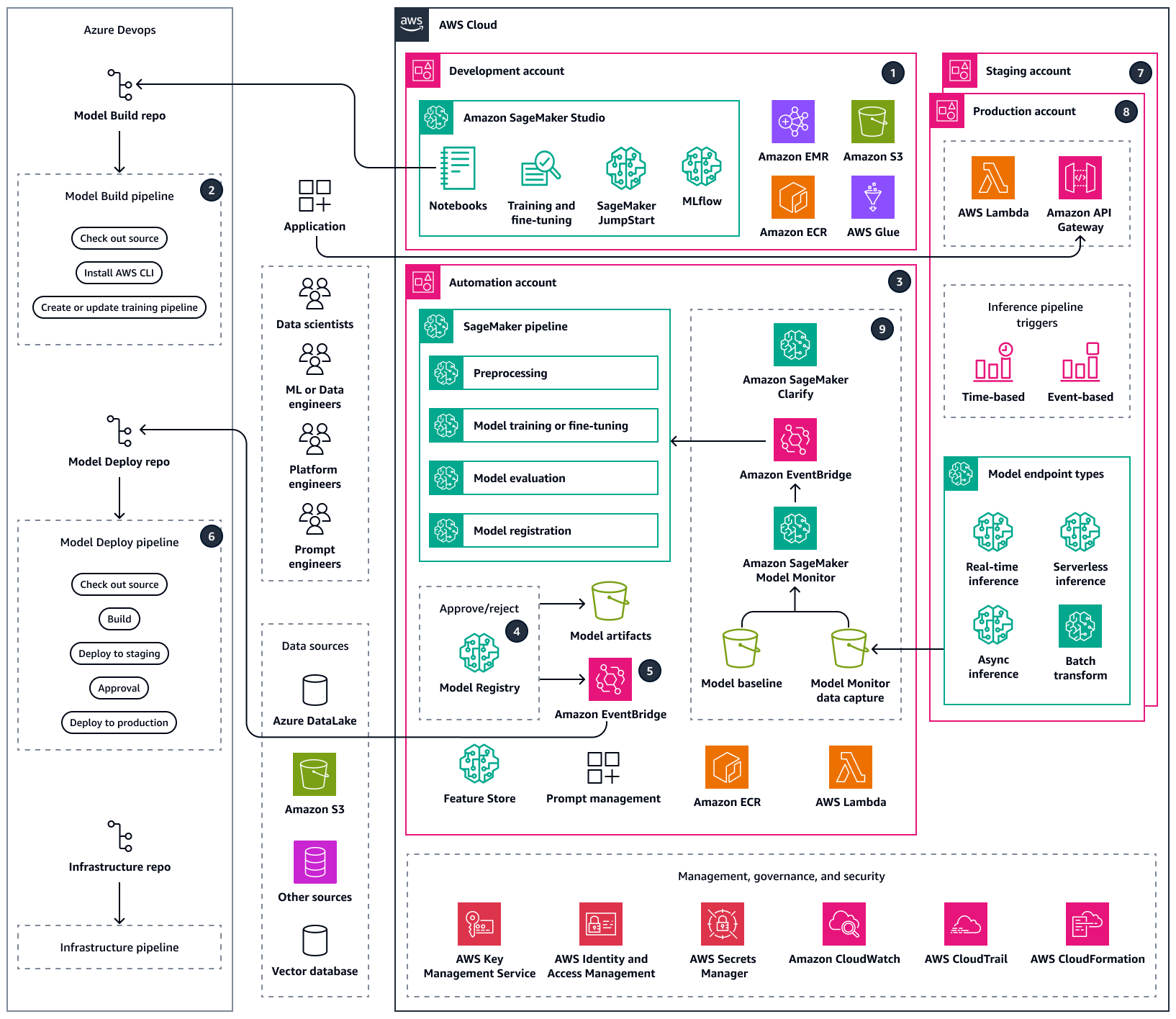
La arquitectura consta de los siguientes componentes:
Los científicos de datos realizan experimentos de ML en la cuenta de desarrollo para explorar diferentes enfoques para los casos de uso de ML mediante diversos orígenes de datos. Los científicos de datos realizan pruebas y ensayos unitarios y, para realizar un seguimiento de sus experimentos, pueden utilizar Amazon SageMaker AI con MLflow. En el desarrollo de modelos de IA generativa, los científicos de datos ajustan los modelos básicos del centro de modelos Amazon SageMaker AI JumpStart . Tras la evaluación del modelo, los científicos de datos insertan el código y lo combinan en el repositorio Model Build, que está alojado en Azure. DevOps Este repositorio contiene código para poder hacer una canalización de creación de modelos de varios pasos.
En Azure DevOps, la canalización de creación de modelos, que proporciona una integración continua (CI), se puede activar automática o manualmente al fusionar el código con la rama principal. En la cuenta de automatización, esto activa la canalización de SageMaker IA para el preprocesamiento de los datos, el entrenamiento y el ajuste de los modelos, la evaluación de los modelos y el registro condicional de los modelos en función de la precisión.
La cuenta de automatización es una cuenta central en todas las plataformas de aprendizaje automático que aloja entornos de aprendizaje automático (Amazon ECR), modelos (Amazon S3), metadatos de modelos (SageMaker AI Model Registry), funciones (SageMaker AI Feature Store), canalizaciones automatizadas (SageMaker AI Pipelines) e información de registros de aprendizaje automático (). CloudWatch Si se trata de una carga de trabajo de IA generativa, es posible que necesite hacer evaluaciones adicionales para las peticiones de las aplicaciones posteriores. Una aplicación de administración rápida de peticiones le permitirá agilizar y automatizar el proceso. Esta cuenta permite la volver a usar los recursos de ML y aplica las prácticas recomendadas para acelerar la entrega de casos de uso de ML.
La última versión del modelo se añade al Registro de modelos de SageMaker IA para su revisión. Realiza un seguimiento de las versiones de los modelos y de los artefactos respectivos (linaje y metadatos). También administra el estado del modelo (aprobado, rechazado o pendiente) y la versión para su implementación posterior.
Una vez que se apruebe un modelo entrenado en Model Registry mediante la interfaz del estudio o una llamada a la API, se puede enviar un evento a Amazon EventBridge. EventBridge inicia la canalización de Model Deploy en Azure DevOps.
La canalización de la implementación de modelos, que proporciona una implementación continua (CD), extrae la fuente del repositorio de implementación de modelos. El origen contiene el código, la configuración para la implementación del modelo y los scripts de prueba para establecer puntos de referencia de calidad. La canalización de implementación de modelos se puede adaptar a su tipo de inferencia.
Tras realizar las comprobaciones de control de calidad, la canalización de implementación de modelos implementa el modelo en la cuenta transitoria. La cuenta transitoria es una copia de la cuenta de producción y se utiliza para las pruebas y la evaluación de la integración. En el caso de querer realizar una transformación por lotes, la canalización de implementación de modelos puede actualizar automáticamente el proceso de inferencia en lotes para utilizar la última versión aprobada del modelo. Para realizar una inferencia asíncrona, sin servidor o en tiempo real, puede configurar o actualizar el punto de conexión del modelo correspondiente.
Tras realizar correctamente las pruebas en la cuenta transitoria, se puede implementar un modelo en la cuenta de producción mediante una aprobación manual a través de la canalización de implementación de modelos. Esta canalización proporciona un punto de conexión de producción en la etapa Implementación y producción, que incluye la supervisión del modelo y un mecanismo de valoración de los datos.
Una vez que el modelo esté en producción, utilice herramientas como SageMaker AI Model Monitor y SageMaker AI Clarify para identificar los sesgos, detectar desviaciones y supervisar continuamente el rendimiento del modelo.
Automatización y escala
Utilice infraestructura como código (IaC) para implementar automáticamente en varias cuentas y entornos. Al automatizar el proceso de configuración de un MLOps flujo de trabajo, es posible separar los entornos que utilizan los equipos de aprendizaje automático que trabajan en diferentes proyectos. AWS CloudFormationle ayuda a modelar, aprovisionar y gestionar AWS los recursos al tratar la infraestructura como código.
Tools (Herramientas)
Servicios de AWS
Amazon SageMaker AI es un servicio de aprendizaje automático gestionado que le ayuda a crear y entrenar modelos de aprendizaje automático para luego implementarlos en un entorno hospedado listo para la producción.
AWS Glue es un servicio de extracción, transformación y carga (ETL) completamente administrado. Ayuda a clasificar, limpiar, enriquecer y mover datos de forma fiable entre almacenes de datos y flujos de datos.
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos basado en la nube que lo ayuda a almacenar, proteger y recuperar cualquier cantidad de datos. En este patrón, Amazon S3 se utiliza para el almacenamiento de datos y se integra con la SageMaker IA para el entrenamiento de modelos y los objetos de modelo.
AWS Lambda es un servicio de computación que ayuda a ejecutar código sin necesidad de aprovisionar ni administrar servidores. Ejecuta el código solo cuando es necesario y amplía la capacidad de manera automática, por lo que solo pagará por el tiempo de procesamiento que utilice. En este patrón, Lambda se utiliza para las tareas procesamiento previas y posteriores de los datos.
Amazon Elastic Container Registry (Amazon ECR) es un servicio de registro de imágenes de contenedor administrado que es seguro, escalable y fiable. En este patrón, almacena los contenedores Docker que la SageMaker IA utiliza como entornos de entrenamiento e implementación.
Amazon EventBridge es un servicio de bus de eventos sin servidor que le ayuda a conectar sus aplicaciones con datos en tiempo real de diversas fuentes. Siguiendo este patrón, EventBridge organiza flujos de trabajo basados en eventos o basados en el tiempo que inician el reentrenamiento o la implementación automáticos del modelo.
Amazon API Gateway le ayuda a crear, publicar, mantener, supervisar y proteger REST, HTTP y WebSocket APIs a cualquier escala. En este patrón, se utiliza para crear un punto de entrada único orientado al exterior para los puntos finales de SageMaker IA.
En el caso de las aplicaciones RAG, puede Servicios de AWS utilizarlas, como Amazon OpenSearch Service y Amazon RDS for PostgreSQL, para almacenar las incrustaciones vectoriales que proporcionan al LLM sus datos internos.
Otras herramientas
Azure
le DevOps ayuda a administrar las CI/CD canalizaciones y a facilitar la creación, las pruebas y la implementación del código. Azure Data Lake Storage
o Snowflake son posibles orígenes de datos de entrenamiento de terceros para los modelos de ML. Pinecone
, Milvus o ChromaDB son posibles bases de datos vectoriales de terceros para almacenar incrustaciones vectoriales.
Prácticas recomendadas
Antes de implementar cualquier componente de este MLOps flujo de trabajo multinube, lleve a cabo las siguientes actividades:
Defina y comprenda el flujo de trabajo de machine learning y las herramientas necesarias para que funcione adecuadamente. Los diferentes casos de uso requieren diferentes flujos de trabajo y componentes. Por ejemplo, es posible que necesite un almacén de características para la reutilización de características y la inferencia de baja latencia en un caso de uso de personalización, pero puede que no sea necesario para otros casos de uso. Para personalizar correctamente la arquitectura, es necesario comprender el flujo de trabajo objetivo, los requisitos de los casos de uso y los métodos de colaboración preferidos del equipo de ciencia de datos.
Establezca una separación clara de responsabilidades para cada componente de la arquitectura. La distribución del almacenamiento de datos entre Azure Data Lake Storage, Snowflake y Amazon S3 puede aumentar la complejidad y los costos. Si es posible, elija un mecanismo de almacenamiento coherente. Del mismo modo, evite usar una combinación de DevOps servicios de Azure y AWS, o una combinación de servicios de Azure y AWS ML.
Elija uno o más modelos y conjuntos de datos existentes para realizar las end-to-end pruebas del MLOps flujo de trabajo. Los artefactos de prueba deben reflejar los casos de uso reales que los equipos de ciencia de datos desarrollen cuando la plataforma entre en la fase de producción.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Identifique los orígenes de datos | En función de los casos de uso actuales y futuros, las fuentes de datos disponibles y los tipos de datos (como los datos confidenciales), documente las fuentes de datos que deben integrarse con la MLOps plataforma. Los datos se pueden almacenar en Amazon S3, Azure Data Lake Storage, Snowflake u otros orígenes. En el caso de las cargas de trabajo de IA generativa, los datos también pueden incluir una base de conocimiento en la que se base la respuesta generada. Estos datos se almacenan como incrustaciones vectoriales en bases de datos vectoriales. Cree un plan para integrar estos orígenes con su plataforma y garantizar el acceso a los recursos correctos. | Ingeniero de datos, científico de datos, arquitecto de la nube |
Elija los servicios aplicables. | Personalice la arquitectura añadiendo o quitando servicios en función del flujo de trabajo que quiera usar el equipo de ciencia de datos, los orígenes de datos aplicables y la arquitectura de nube existente. Por ejemplo, los ingenieros de datos y los científicos de datos pueden realizar el preprocesamiento de datos y la ingeniería de características en SageMaker AI o Amazon EMR. AWS Glue Es poco probable que necesiten usar los tres servicios. | Administrador de AWS, ingeniero de datos, científico de datos, ingeniero de machine learning |
Analice los requisitos de seguridad. | Reúna y documente los requisitos de seguridad. Esto incluye determinar lo siguiente:
Para obtener más información sobre cómo proteger las cargas de trabajo de IA generativa, consulte Cómo proteger la IA generativa: una introducción a la matriz de alcance de la seguridad de la IA generativa | Administrador de AWS, arquitecto de la nube |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Configurar AWS Organizations. | AWS Organizations Configúrelo desde la raíz Cuenta de AWS. Esto le ayuda a administrar las cuentas subsiguientes que cree como parte de una MLOps estrategia de cuentas múltiples. Para obtener más información, consulte la Documentación de AWS Organizations. | Administrador de AWS |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Crea una cuenta AWS de desarrollo. | Cree un espacio Cuenta de AWS en el que los ingenieros y científicos de datos tengan permisos para experimentar y crear modelos de aprendizaje automático. Para obtener instrucciones, consulte Crear una cuenta de miembro en su organización en la AWS Organizations documentación. | Administrador de AWS |
Creación de un repositorio de creación de modelos. | Cree un repositorio de Git en Azure donde los científicos de datos puedan enviar el código de creación e implementación de sus modelos una vez finalizada la fase de experimentación. Para obtener instrucciones, consulte Configurar un repositorio de Git | DevOps ingeniero, ingeniero de aprendizaje automático |
Cree un repositorio de implementación de modelos. | Cree un repositorio de Git en Azure que almacene el código y las plantillas de implementación estándar. Debe incluir código para cada opción de implementación que utilice la organización, tal como se indicó en la fase de diseño. Por ejemplo, debe incluir puntos de conexión en tiempo real, puntos de conexión asíncronos, inferencias sin servidor o transformaciones por lotes. Para obtener instrucciones, consulte Configurar un repositorio de Git | DevOps ingeniero, ingeniero de aprendizaje automático |
Cree un repositorio de Amazon ECR. | Configure un repositorio de Amazon ECR que almacene los entornos de ML aprobados como imágenes de Docker. Permita que los científicos de datos y los ingenieros de ML definan nuevos entornos. Para obtener instrucciones, consulte Creación de un repositorio privado en la documentación de Amazon ECR. | Ingeniero de ML |
Configura SageMaker AI Studio. | Configura SageMaker AI Studio en la cuenta de desarrollo de acuerdo con los requisitos de seguridad previamente definidos, las herramientas de ciencia de datos preferidas (como MLflow) y el entorno de desarrollo integrado (IDE) preferido. Utilice las configuraciones del ciclo de vida para automatizar la instalación de las funciones clave y crear un entorno de desarrollo uniforme para los científicos de datos. Para obtener más información, consulte Amazon SageMaker AI Studio y el servidor MLflow de seguimiento en la documentación de SageMaker IA. | Científico de datos, ingeniero de ML, ingeniero de peticiones |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cree una cuenta de Automation. | Cree un Cuenta de AWS lugar en el que se ejecuten las canalizaciones y los trabajos automatizados. Puede dar a los equipos de ciencia de datos acceso de lectura a esta cuenta. Para obtener instrucciones, consulte Crear una cuenta de miembro en su organización en la AWS Organizations documentación. | Administrador de AWS |
Configure un registro de modelos. | Configura el registro de modelos de SageMaker IA en la cuenta de automatización. Este registro almacena los metadatos de los modelos de ML y permite que determinados científicos de datos o líderes de equipo aprueben o rechacen modelos. Para obtener más información, consulte Registrar e implementar modelos con Model Registry en la documentación de SageMaker IA. | Ingeniero de ML |
Cree una canalización de creación de modelos. | Cree una CI/CD canalización en Azure que se inicie de forma manual o automática cuando el código se envíe al repositorio de Model Build. La canalización debería revisar el código fuente y crear o actualizar una canalización de SageMaker IA en la cuenta de Automation. La canalización debe añadir un modelo nuevo al registro de modelos. Para obtener más información acerca de la creación de una canalización, consulte la documentación de Azure Pipelines | DevOps ingeniero, ingeniero de ML |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cree cuentas AWS de puesta en escena y despliegue. | Cree modelos Cuentas de AWS de aprendizaje automático para la puesta en escena y el despliegue de ellos. Estas cuentas deben ser idénticas para poder realizar pruebas precisas de los modelos durante la fase de transición antes de pasar a la fase de producción. Puede dar a los equipos de ciencia de datos acceso de lectura a esta cuenta transitoria. Para obtener instrucciones, consulte Crear una cuenta de miembro en su organización en la AWS Organizations documentación. | Administrador de AWS |
Configure los buckets de S3 para la supervisión de modelos. | Complete este paso si desea habilitar la supervisión de modelos para los modelos implementados que crea la canalización de implementación de modelos. Cree buckets de Amazon S3 para almacenar los datos de entrada y salida. Para más información sobre cómo crear buckets de S3, consulte Creación de un bucket en la documentación de Amazon S3. Configure los permisos entre cuentas para que los trabajos de supervisión de modelos automatizados se ejecuten en la cuenta de Automation. Para obtener más información, consulte Supervisar la calidad de los datos y los modelos en la documentación sobre SageMaker IA. | Ingeniero de ML |
Cree una canalización de implementación de modelos. | Cree una CI/CD canalización en Azure que comience cuando se apruebe un modelo en el registro de modelos. La canalización debe comprobar el código fuente y el artefacto del modelo, crear las plantillas de infraestructura para implementar el modelo en las cuentas transitorias y de producción, implementar el modelo en la cuenta transitoria, ejecutar pruebas automatizadas, esperar a la aprobación manual e implementar el modelo aprobado en la cuenta de producción. Para obtener más información acerca de la creación de una canalización, consulte la documentación de Azure Pipelines | DevOps ingeniero, ingeniero de aprendizaje automático |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cree AWS CDK nuestras CloudFormation plantillas. | Defina AWS Cloud Development Kit (AWS CDK) AWS CloudFormation nuestras plantillas para todos los entornos que deban implementarse automáticamente. Esto puede incluir el entorno de desarrollo, el entorno de automatización y los entornos transitorios y de implementación. Para obtener más información, consulte la documentación de AWS CDK y CloudFormation. | AWS DevOps |
Cree una canalización de infraestructura. | Cree una CI/CD canalización en Azure para el despliegue de la infraestructura. Un administrador puede iniciar esta canalización para crear nuevos entornos Cuentas de AWS y configurar los que necesite el equipo de aprendizaje automático. | DevOps ingeniero |
Resolución de problemas
| Problema | Solución |
|---|---|
Supervisión y detección de desviaciones insuficientes: una supervisión inadecuada puede provocar que no se detecten los problemas de rendimiento del modelo o la deriva de datos. | Refuerce los marcos de monitoreo con herramientas como Amazon CloudWatch, SageMaker AI Model Monitor y SageMaker AI Clarify. Configure alertas para tomar medidas inmediatas en caso de tener alguno de los problemas identificados. |
Errores de activación de la canalización de CI: es DevOps posible que la canalización de CI de Azure no se active al fusionar el código debido a una mala configuración. | Comprueba la configuración del DevOps proyecto de Azure para asegurarte de que los webhooks estén correctamente configurados y apunten a los puntos finales de SageMaker IA correctos. |
Gobernanza: es posible que la cuenta central de Automation no aplique las prácticas recomendadas en todas las plataformas de ML, lo que provocará flujos de trabajo incoherentes. | Audite la configuración de la cuenta de Automation y asegúrese de que todos los entornos y modelos de ML se ajusten a las prácticas recomendadas y políticas predefinidas. |
Retrasos en la aprobación del registro de modelos: esto ocurre cuando hay un retraso en la comprobación y aprobación del modelo, ya sea porque los usuarios tardan en revisarlo o por problemas técnicos. | Implemente un sistema de notificación para alertar a las partes interesadas sobre los modelos que están pendientes de aprobación y agilice el proceso de revisión. |
Errores en los eventos de implementación de modelos: los eventos enviados para iniciar los procesos de implementación del modelo pueden devolver errores y provocar retrasos en el proceso de implementación. | Confirma que Amazon EventBridge tiene los permisos y los patrones de eventos correctos para invocar las DevOps canalizaciones de Azure correctamente. |
Cuellos de botella en la implementación de producción: los procesos de aprobación manual pueden crear cuellos de botella y retrasar la implementación de los modelos en producción. | Para optimizar el flujo de trabajo de aprobación del proceso de implementación del modelo, favorezca las revisiones oportunas y los canales de comunicación claros. |
Recursos relacionados
AWS documentación
Machine Learning Lens (marco AWS bien diseñado)
Planificar con éxito MLOps (orientación AWS prescriptiva)
Otros recursos AWS
MLOps hoja de ruta básica para empresas con Amazon SageMaker AI
(AWS entrada del blog) AWS Summit ANZ 2022: End-to-end MLOps para arquitectos
(YouTube vídeo) FMOps/LLMOps: Operacionalice la IA generativa y sus diferencias con ella MLOps
(AWS entrada del blog) Operacionalice la evaluación de LLM a gran escala con Amazon SageMaker AI Clarify y sus MLOps servicios
(AWS entrada de blog) El papel de las bases de datos vectoriales en las aplicaciones de IA generativa
(AWS entrada del blog)
Documentación de Azure
