Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Extraer contenido de archivos PDF automáticamente con Amazon Textract
Tianxia Jia, Amazon Web Services
Resumen
Muchas organizaciones necesitan extraer información de los archivos PDF que se cargan en sus aplicaciones empresariales. Por ejemplo, una organización podría necesitar extraer con precisión la información de archivos PDF fiscales o médicos para realizar análisis tributarios o procesar reclamaciones médicas.
En la nube de Amazon Web Services (AWS), Amazon Textract extrae automáticamente la información (por ejemplo, texto impreso, formularios y tablas) de los archivos PDF y produce un archivo en formato JSON que contiene información del archivo PDF original. Puede usar Amazon Textract en la consola de administración de AWS o mediante la implementación de llamadas a la API. Le recomendamos que utilice llamadas a la API mediante programación
Cuando Amazon Textract procesa un archivo, crea la siguiente lista de objetos Block: páginas, líneas y palabras de texto, formularios (pares clave-valor), tablas y celdas, y elementos de selección. También se incluye otra información del objeto, por ejemplo, cuadros delimitadores IDs, intervalos de confianza y relaciones. Amazon Textract extrae la información del contenido en forma de cadenas. Es necesario contar con valores de datos correctamente identificados y transformados para que las aplicaciones posteriores puedan utilizarlos más fácilmente.
Este patrón describe un step-by-step flujo de trabajo para usar Amazon Textract para extraer automáticamente el contenido de los archivos PDF y procesarlo para obtener un resultado limpio. El patrón utiliza una técnica de coincidencia de plantillas para identificar correctamente el campo, el nombre clave y las tablas requeridos y, a continuación, aplica correcciones posteriores al procesamiento a cada tipo de datos. Puede utilizar este patrón para procesar distintos tipos de archivos PDF y, a continuación, escalar y automatizar este flujo de trabajo para procesar archivos PDF con un formato idéntico.
Requisitos previos y limitaciones
Requisitos previos
Una cuenta de AWS activa.
Un bucket de Amazon Simple Storage Service (Amazon S3) existente en el que almacenar los archivos PDF una vez convertidos a formato JPEG para su procesamiento por Amazon Textract. Para obtener más información sobre los buckets de S3, consulte la Información general de los buckets en la documentación de Amazon S3.
El cuaderno de Jupyter
Textract_PostProcessing.ipynb(adjunto), instalado y configurado. Para obtener más información sobre las libretas Jupyter, consulta Crear una libreta Jupyter en la documentación de Amazon. SageMakerArchivos PDF existentes que tengan un formato idéntico.
Conocimientos de Python.
Limitaciones
Sus archivos PDF deben ser de buena calidad y claramente legibles. Se recomiendan archivos PDF nativos, pero puede utilizar documentos escaneados y convertidos a formato PDF si todas las palabras individuales se leen con claridad. Para obtener más información al respecto, consulte Preprocesamiento de documentos PDF con Amazon Textract: detección y eliminación de imágenes
en el blog de AWS Machine Learning. Con los archivos de varias páginas, puede utilizar una operación asíncrona o combinar los archivos PDF en una única página y utilizar una operación síncrona. Para obtener más información sobre estas dos opciones, consulte Detección y análisis de texto en documentos de varias páginas y Detección y análisis de texto en documentos de una sola página en la documentación de Amazon Textract.
Arquitectura
El flujo de trabajo de este patrón ejecuta primero Amazon Textract sobre un archivo PDF de muestra (Primera ejecución) y, a continuación, lo ejecuta en archivos PDF que tengan un formato idéntico al del primer PDF (Ejecución repetida). El siguiente diagrama muestra el flujo de trabajo combinado de la Primera ejecución y la Ejecución repetida que extrae de forma automática y repetida el contenido de archivos PDF con idénticos formatos.
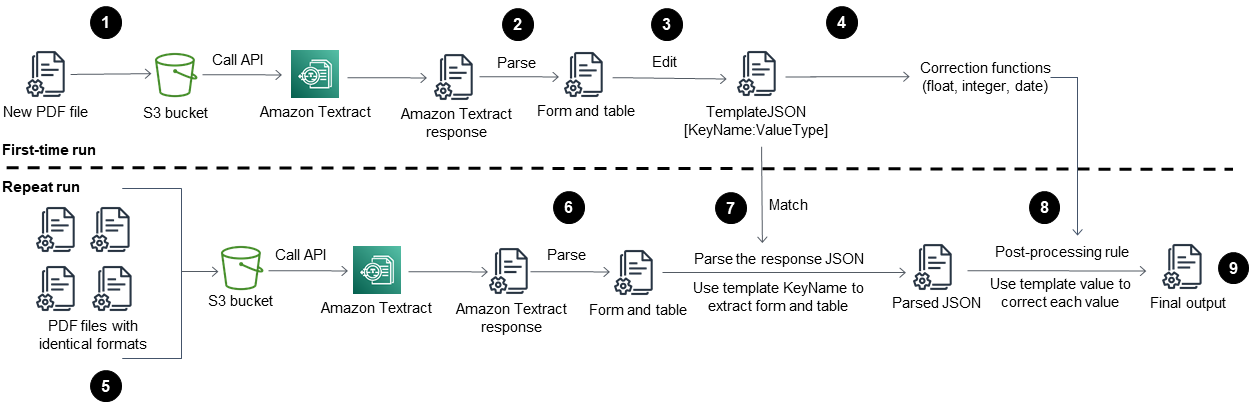
El diagrama muestra el siguiente flujo de trabajo de este patrón:
Convierta un archivo PDF a formato JPEG y almacénelo en un bucket de S3.
Llame a la API de Amazon Textract y analice el archivo JSON de respuesta de Amazon Textract.
Edite el archivo JSON añadiendo el par
KeyName:DataTypecorrecto para cada campo obligatorio. Cree un archivoTemplateJSONpara la etapa de Ejecución repetida.Defina las funciones de corrección posterior al procesamiento para cada tipo de datos (por ejemplo, flotante, entero y fecha).
Prepare los archivos PDF que tengan un formato idéntico al del primer archivo PDF.
Llame a la API de Amazon Textract y analice el JSON de respuesta de Amazon Textract.
Haga coincidir el archivo JSON analizado con el archivo
TemplateJSON.Implemente las correcciones posteriores al procesamiento.
El archivo de salida JSON final tiene el KeyName y el Value correctos para cada campo obligatorio.
Pila de tecnología de destino
Amazon SageMaker
Amazon S3
Amazon Textract
Automatizar y escalar
Puede automatizar el flujo de trabajo de Ejecución repetida mediante una función de AWS Lambda que inicie Amazon Textract cuando se agregue un nuevo archivo PDF a Amazon S3. A continuación, Amazon Textract ejecuta los scripts de procesamiento y el resultado final se puede guardar en una ubicación de almacenamiento. Para obtener más información al respecto, consulte Uso de un desencadenador de Amazon S3 para invocar una función de Lambda en la documentación de Lambda.
Tools (Herramientas)
Amazon SageMaker es un servicio de aprendizaje automático totalmente gestionado que le ayuda a crear y entrenar modelos de aprendizaje automático de forma rápida y sencilla y, a continuación, a implementarlos directamente en un entorno hospedado listo para la producción.
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos basado en la nube que le ayuda a almacenar, proteger y recuperar cualquier cantidad de datos.
Amazon Textract facilita la adición de detección y análisis de texto de documentos a sus aplicaciones.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Convertir el archivo PDF. | Para preparar el archivo PDF para la primera ejecución, combínelo en una única página y conviértalo a formato JPEG para la operación síncrona ( notaTambién puede utilizar la operación asíncrona ( | Científico de datos, desarrollador |
Analizar el JSON de respuesta de Amazon Textract. | Abra el cuaderno de Jupyter
Analice y transforme el JSON de respuesta en un formulario y una tabla mediante el siguiente código:
| Científico de datos, desarrollador |
Editar el archivo de TemplateJSON. | Edite el JSON analizado de cada Esta plantilla se usa para cada tipo de archivo PDF individual, lo que significa que la plantilla se puede reutilizar para archivos PDF que tengan un formato idéntico. | Científico de datos, desarrollador |
Definir las funciones de corrección posterior al procesamiento. | Los valores de la respuesta de Amazon Textract para el archivo Corrija cada tipo de datos según el archivo
| Científico de datos, desarrollador |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Prepare los archivos PDF. | Para preparar los archivos PDF, combínelos en una sola página y conviértalos a formato JPEG para la operación síncrona ( notaTambién puede utilizar la operación asíncrona ( | Científico de datos, desarrollador |
Llamar a la API de Amazon Textract. | Para llamar a la API de Amazon Textract, utilice el siguiente código:
| Científico de datos, desarrollador |
Analizar el JSON de respuesta de Amazon Textract. | Analice y transforme el JSON de respuesta en un formulario y una tabla mediante el siguiente código:
| Científico de datos, desarrollador |
Cargar el archivo TemplateJSON y hacerlo coincidir con el JSON analizado. | Utilice el archivo
| Científico de datos, desarrollador |
Correcciones posteriores al procesamiento. | Use
| Científico de datos, desarrollador |
Recursos relacionados
Conexiones
Para acceder al contenido adicional asociado a este documento, descomprima el archivo: attachment.zip
