Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso del almacenamiento en caché para reducir la demanda de la base de datos
Descripción general de
Puede utilizar el almacenamiento en caché como una estrategia eficaz para reducir los costos de sus aplicaciones .NET. Muchas aplicaciones utilizan bases de datos en el backend, como SQL Server, cuando las aplicaciones requieren un acceso frecuente a los datos. El costo de mantener estos servicios de backend para hacer frente a la demanda puede ser elevado, pero puede utilizar una estrategia de almacenamiento en caché eficaz para reducir la carga de las bases de datos de backend reduciendo los requisitos de tamaño y escalado. Esto puede ser útil a la hora de reducir los costos y mejorar el rendimiento de sus aplicaciones.
El almacenamiento en caché es una técnica útil para ahorrar costos relacionados con las cargas de trabajo de lectura intensiva que utilizan recursos más caros, como SQL Server. Es importante utilizar la técnica adecuada para la carga de trabajo. Por ejemplo, el almacenamiento en caché local no es escalable y requiere que mantenga una caché local para cada instancia de una aplicación. Debe sopesar el impacto en el rendimiento y compararlo con los posibles costos de modo que el menor costo del origen de datos subyacente compense cualquier costo adicional relacionado con el mecanismo de almacenamiento en caché.
Impacto del costo
SQL Server requiere que tenga en cuenta las solicitudes de lectura al dimensionar la base de datos. Esto podría afectar a los costos, ya que es posible que tenga que introducir réplicas de lectura para adaptarse a la carga. Si utiliza réplicas de lectura, debe tener en cuenta que solo están disponibles en la edición Enterprise de SQL Server. Esta edición requiere una licencia más cara que la edición Standard de SQL Server.
El siguiente diagrama está diseñado para explicar la eficacia del almacenamiento en caché. Muestra Amazon RDS para SQL Server con cuatro nodos db.m4.2xlarge que usan la edición Enterprise de SQL Server. Se implementa en una configuración Multi-AZ con una réplica de lectura. El tráfico de lectura exclusivo (por ejemplo, las consultas SELECT) se envía a las réplicas de lectura. En comparación, Amazon DynamoDB utiliza un clúster de Acelerador de DynamoDB (DAX) r4.2xlarge de dos nodos.
En el siguiente gráfico se muestran los resultados obtenidos al no necesitar réplicas de lectura dedicadas que gestionen un tráfico de lectura elevado.
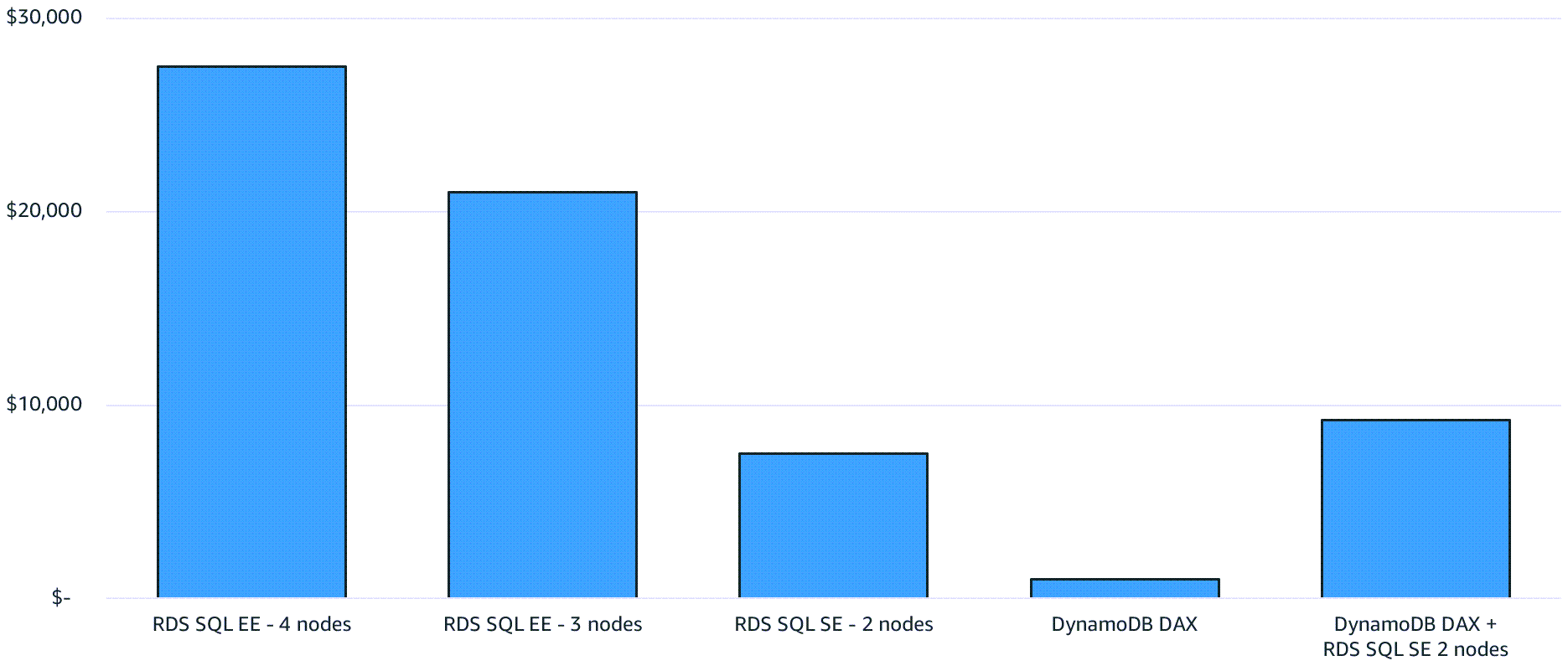
Puede ahorrar bastante si usa el almacenamiento en caché local sin réplicas de lectura o combina el uso de DAX con SQL Server en Amazon RDS como capa de almacenamiento en caché. Esta capa se descarga de SQL Server y reduce el tamaño de los recursos de SQL Server necesarios para poner en marcha la base de datos.
Recomendaciones de optimización de costos
Almacenamiento en la caché local
El almacenamiento en caché local es una de las formas más utilizadas para almacenar en caché el contenido de las aplicaciones alojadas tanto en las instalaciones como en la nube. Esto se debe a que su implementación es relativamente fácil e intuitiva. El almacenamiento en caché local implica tomar contenido de una base de datos u otro origen y almacenarlo en caché local en la memoria o en el disco para un acceso más rápido. Esta estrategia, aunque es fácil de implementar, no es ideal para algunos casos de uso. Por ejemplo, esto incluye casos de uso en los que el contenido almacenado en caché debe persistir en el tiempo, como cuando se requiere preservar el estado de la aplicación o el estado del usuario. Otro caso de uso es presenta cuando es necesario acceder al contenido almacenado en caché desde otras instancias de la aplicación.
El siguiente diagrama muestra un clúster de SQL Server de alta disponibilidad con cuatro nodos y dos réplicas de lectura.
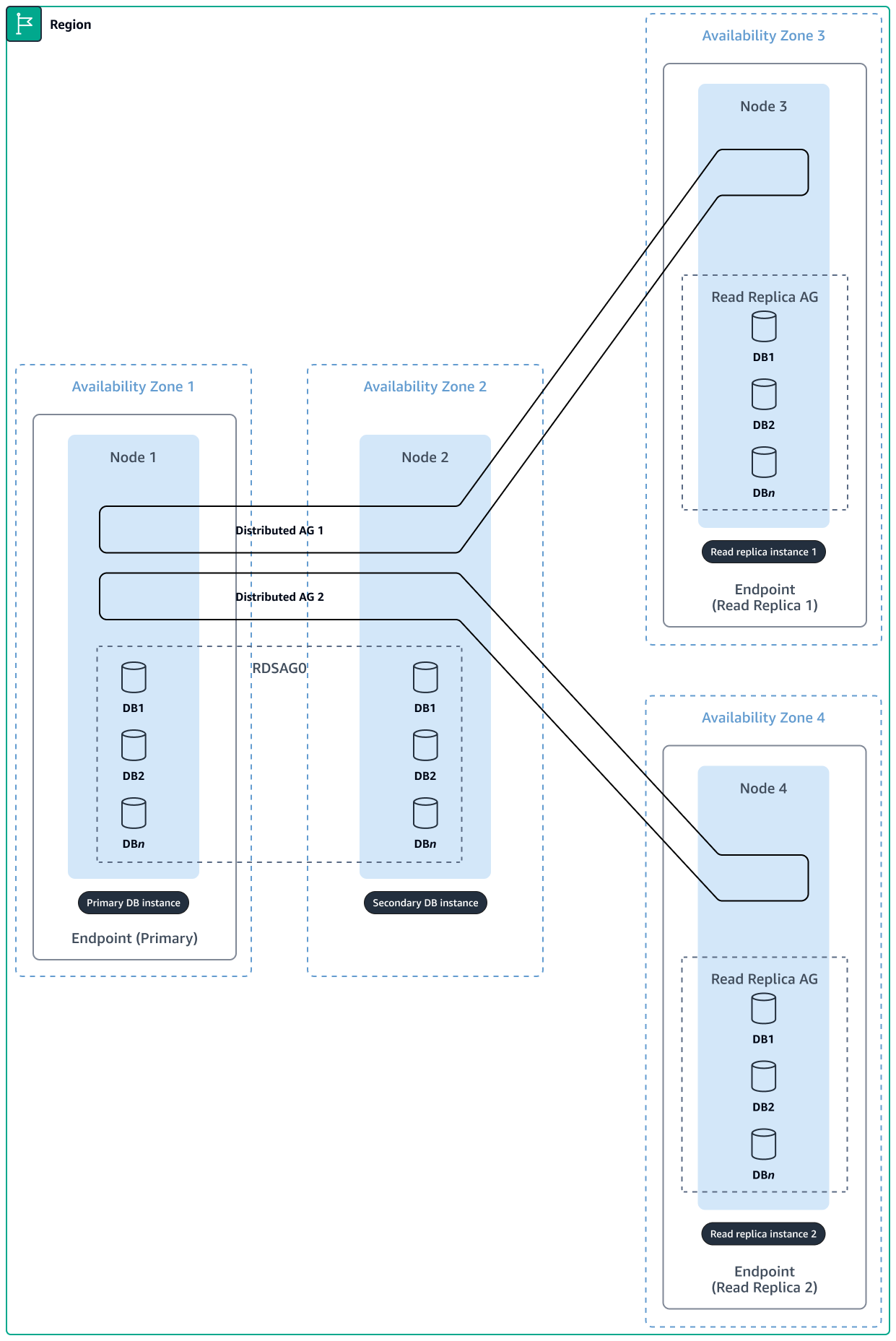
Con el almacenamiento en caché local, es posible que tenga que equilibrar la carga del tráfico entre varias instancias de EC2. Cada instancia debe mantener su propia caché local. Si la caché almacena información con estado, es necesario que se realicen confirmaciones periódicas en la base de datos y es posible que sea necesario redirigir a los usuarios a la misma instancia para cada solicitud posterior (sesión persistente). Esto supone un desafío cuando se intenta escalar las aplicaciones, ya que algunas instancias podrían estar excediendo su capacidad de uso, mientras que otras no se usan lo suficiente debido a la distribución desigual del tráfico.
Puede utilizar el almacenamiento en caché local, ya sea en memoria o mediante almacenamiento local, para las aplicaciones .NET. Para ello, puede agregar la funcionalidad de almacenar objetos en el disco y recuperarlos cuando sea necesario, o bien consultar datos de la base de datos y conservarlos en la memoria. Para realizar un almacenamiento en caché local en memoria y un almacenamiento local de los datos de SQL Server en C#, por ejemplo, puede utilizar una combinación de bibliotecas MemoryCache y LiteDB. MemoryCache proporciona almacenamiento en caché en memoria, mientras que LiteDB es una base de datos NoSQL integrada basada en disco que es rápida y ligera.
Para realizar el almacenamiento en caché en memoria, utilice la biblioteca de .NET System.Runtime.MemoryCache. El siguiente ejemplo de código muestra cómo utilizar la clase System.Runtime.Caching.MemoryCache para almacenar datos en caché en memoria. Esta clase proporciona una forma de almacenar datos temporalmente en la memoria de la aplicación. Esto puede ayudar a mejorar el rendimiento de una aplicación, pues reduce la necesidad de obtener datos de un recurso más caro, como una base de datos o una API.
El código funciona de la siguiente manera:
-
Se crea una instancia estática privada de
MemoryCachedenominada_memoryCache. La memoria caché recibe un nombre (dataCache) para identificarla. A continuación, la memoria caché almacena y recupera los datos. -
El método
GetDataes un método genérico que utiliza dos argumentos: una clavestringy un delegadoFunc<T>llamadogetData. La clave se usa para identificar los datos en caché, mientras que el delegadogetDatarepresenta la lógica de recuperación de datos que se pone en marcha cuando los datos no están presentes en la memoria caché. -
Lo primero que hace el método es comprobar si los datos están presentes en la memoria caché mediante el método
_memoryCache.Contains(key). Si los datos están en la memoria caché, el método los recupera usando_memoryCache.Get(key)y convierte los datos en el tipo T esperado. -
Si los datos no están en la memoria caché, el método llama al delegado
getDatapara que busque los datos. A continuación, agrega los datos a la memoria caché usando_memoryCache.Add(key, data, DateTimeOffset.Now.AddMinutes(10)). Esta llamada especifica que la entrada de la memoria caché debe vencer después de 10 minutos, momento en el que los datos se eliminan automáticamente de la memoria caché. -
El método
ClearCachetoma una clavestringcomo argumento y elimina los datos asociados a esa clave de la memoria caché mediante_memoryCache.Remove(key).
using System; using System.Runtime.Caching; public class InMemoryCache { private static MemoryCache _memoryCache = new MemoryCache("dataCache"); public static T GetData<T>(string key, Func<T> getData) { if (_memoryCache.Contains(key)) { return (T)_memoryCache.Get(key); } T data = getData(); _memoryCache.Add(key, data, DateTimeOffset.Now.AddMinutes(10)); return data; } public static void ClearCache(string key) { _memoryCache.Remove(key); } }
Puede utilizar el siguiente código:
public class Program { public static void Main() { string cacheKey = "sample_data"; Func<string> getSampleData = () => { // Replace this with your data retrieval logic return "Sample data"; }; string data = InMemoryCache.GetData(cacheKey, getSampleData); Console.WriteLine("Data: " + data); } }
El siguiente ejemplo muestra cómo utilizar LiteDBLocalStorageCache contiene las funciones principales para administrar la memoria caché.
using System; using LiteDB; public class LocalStorageCache { private static string _liteDbPath = @"Filename=LocalCache.db"; public static T GetData<T>(string key, Func<T> getData) { using (var db = new LiteDatabase(_liteDbPath)) { var collection = db.GetCollection<T>("cache"); var item = collection.FindOne(Query.EQ("_id", key)); if (item != null) { return item; } } T data = getData(); using (var db = new LiteDatabase(_liteDbPath)) { var collection = db.GetCollection<T>("cache"); collection.Upsert(new BsonValue(key), data); } return data; } public static void ClearCache(string key) { using (var db = new LiteDatabase(_liteDbPath)) { var collection = db.GetCollection("cache"); collection.Delete(key); } } } public class Program { public static void Main() { string cacheKey = "sample_data"; Func<string> getSampleData = () => { // Replace this with your data retrieval logic return "Sample data"; }; string data = LocalStorageCache.GetData(cacheKey, getSampleData); Console.WriteLine("Data: " + data); } }
Si tiene una memoria caché estática o archivos estáticos que no cambian con frecuencia, también puede almacenar estos archivos en un almacén de objetos de Amazon Simple Storage Service (Amazon S3). La aplicación puede recuperar el archivo de la memoria caché estática al iniciarse para usarse localmente. Para obtener más información sobre cómo recuperar archivos de Amazon S3 mediante .NET, consulte Descarga de objetos en la documentación de Amazon S3.
Almacenamiento en caché con DAX
Puede utilizar una capa de almacenamiento en caché que se pueda compartir entre todas las instancias de la aplicación. Acelerador de DynamoDB (DAX) es una caché en memoria altamente disponible y completamente administrada para DynamoDB que multiplica el rendimiento por 10. Puede utilizar DAX para reducir los costos reduciendo la necesidad de asignar más unidades de capacidad de lectura de las necesarias en las tablas de DynamoDB. Esto resulta especialmente útil para cargas de trabajo con muchas solicitudes de lectura y que requieren lecturas repetidas de claves individuales.
DynamoDB cuenta con precios bajo demanda o en función de la capacidad aprovisionada, por lo que el número de lecturas y escrituras al mes se refleja en el costo. Si tiene cargas de trabajo con muchas solicitudes de lectura, los clústeres de DAX pueden ser de ayuda para ahorrar, pues reducen el número de lecturas en las tablas de DynamoDB. Para obtener instrucciones sobre cómo configurar DAX, consulte Aceleración en memoria con Acelerador de DynamoDB (DAX) en la documentación de DynamoDB. Para obtener información sobre la integración de aplicaciones de.NET, consulte Integrating Amazon DynamoDB DAX en su aplicación ASP.NET en
Recursos adicionales
-
Aceleración en memoria con Acelerador de DynamoDB (DAX): Amazon DynamoDB (documentación de DynamoDB)
-
Integración de Amazon DynamoDB DAX en
su aplicación ASP.NET () YouTube -
Descarga de objetos (documentación de Amazon S3)
