Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Dominios técnicos
En esta sección, se brinda una descripción general de los principales dominios tecnológicos de la organización en contenedores. En el siguiente diagrama, se muestra la arquitectura de una aplicación Java EE tradicional.
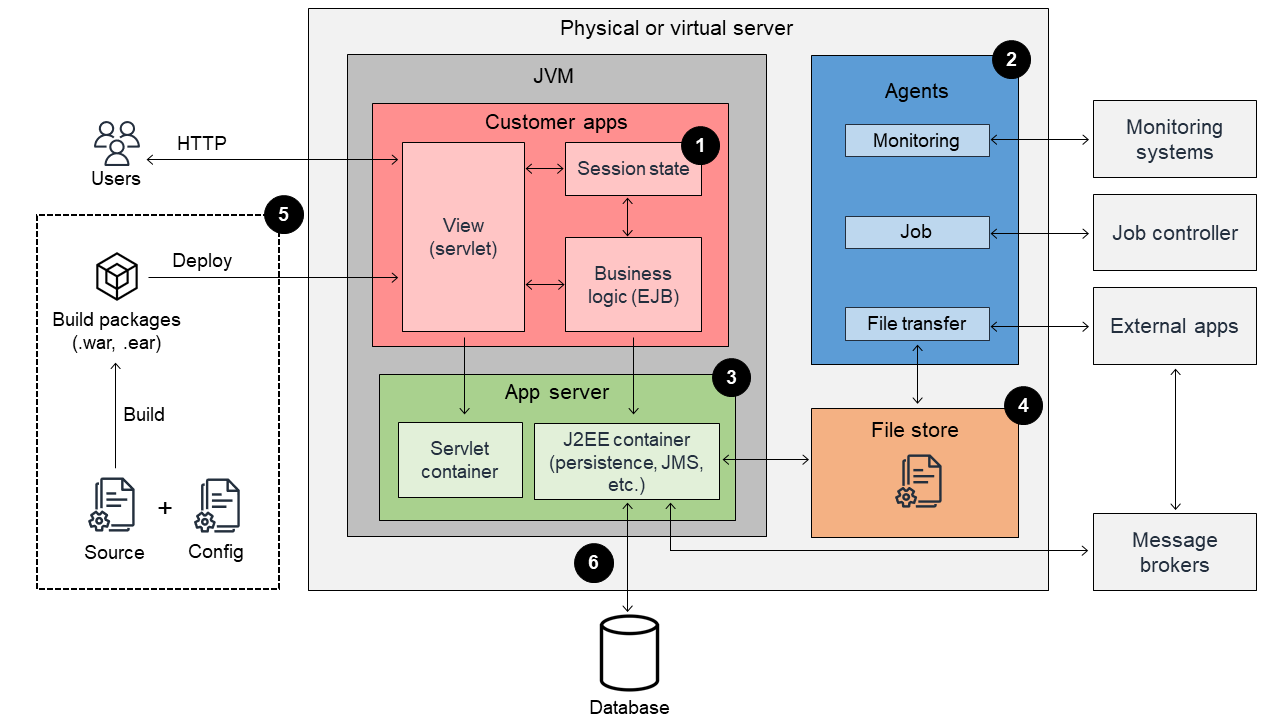
En el siguiente diagrama, se muestra la arquitectura de una aplicación Java EE en contenedores tradicional.
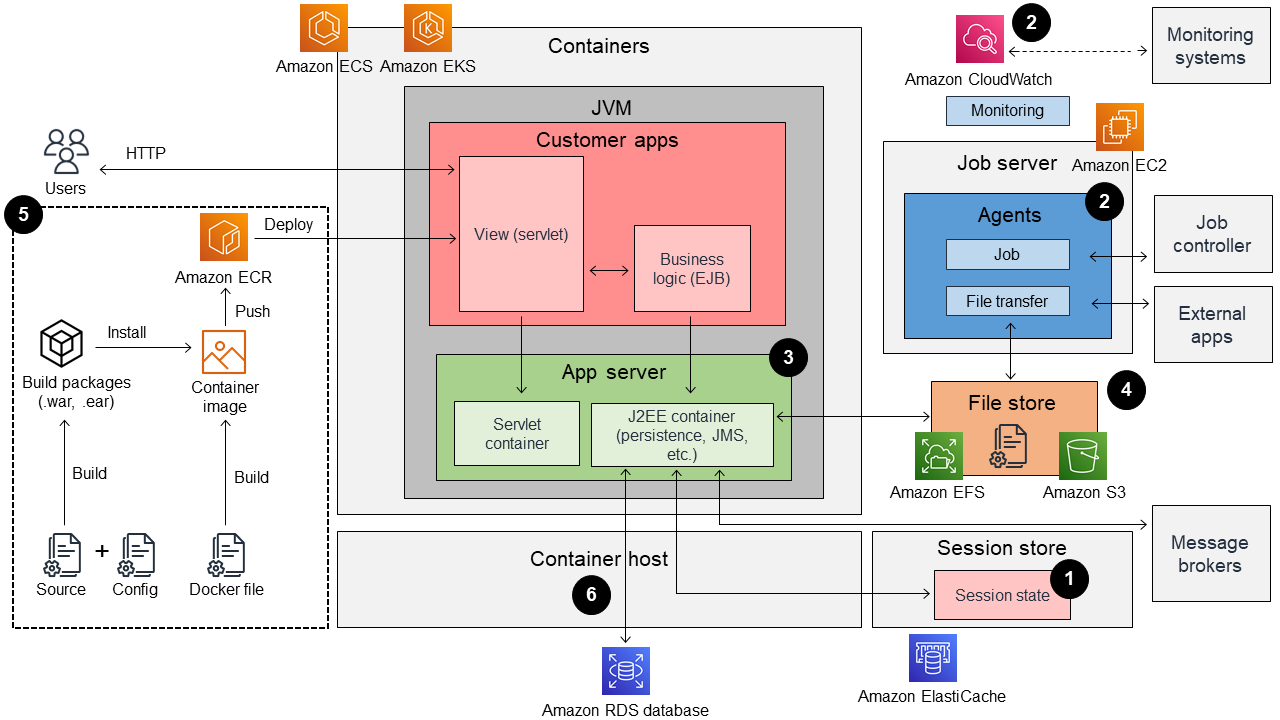
1. Estado de la sesión
En la mayoría de los casos, las aplicaciones Java EE almacenan los datos de sesión asociados a las solicitudes de los usuarios, como las cookies de los servlets y las sesiones con estado de Enterprise Java Beans (EJB). Recomendamos evitar almacenar la información de estado en la memoria de la máquina virtual Java (JVM), ya que el contenedor debe mantenerse sin estado. Para obtener más información sobre el principio de disponibilidad, consulte Principios del diseño de aplicaciones basadas en contenedores
El mecanismo de replicación de memoria presupone que siempre existe un conjunto concreto de servidores en el clúster o que un número reducido de servidores se unen o abandonan el clúster. Esto no es compatible con un entorno de contenedores, por lo que recomendamos eliminar el mecanismo de replicación de memoria. En un entorno de contenedores, los servidores de aplicaciones se vuelven a implementar cuando se crea una nueva versión de la imagen del contenedor. Es decir, también se borran todos los datos de la memoria replicada.
2. Agentes
Hay varios procesos de agente que se ejecutan en un único servidor físico o virtual que, por lo general, realizan tareas de automatización y utilidades, como las siguientes:
-
Monitoreo: los entornos de aplicaciones Java EE tradicionales suelen utilizar agentes exclusivos para el monitoreo. Estos agentes se encargan de monitorear la CPU del servidor, la memoria, el uso del disco, el uso de la memoria dentro de la JVM, registrar mensajes, etc. Sin embargo, no es posible ejecutar directamente los agentes de monitoreo en un entorno de contenedores. Debe sustituir los agentes de supervisión por el mecanismo de supervisión que proporciona la plataforma de contenedores, como Amazon CloudWatch y Amazon CloudWatch Logs.
-
Trabajos (tareas programadas): en los entornos de aplicaciones Java EE tradicionales, el entorno de ejecución de tareas suele residir en el mismo servidor que el servidor de aplicaciones y es responsable de los procesos por lotes de ejecución prolongada, aparte de las solicitudes de los usuarios. Por ejemplo, el proceso por lotes controlado por el controlador del trabajo accede a la base de datos para recuperar datos y crear un informe. Dado que estas múltiples cargas de trabajo no pueden coexistir en un entorno de contenedores, debe crear el entorno de ejecución de tareas y lotes separado del entorno de contenedores.
-
Transferencia de archivos: los agentes de transferencia de archivos no suelen ser tan comunes en los entornos de aplicaciones Java EE. Sin embargo, a veces se ejecutan en el mismo sistema operativo que la aplicación Java como un proceso independiente para intercambiar archivos hacia o desde aplicaciones externas. Por ejemplo, los datos utilizados por otras aplicaciones se transfieren a un archivo todos los días y se reflejan en la base de datos. Los agentes de transferencia de archivos no pueden ejecutarse fuera de los contenedores, sino que deben ejecutarse en otro servidor que tenga acceso a la base de datos y a los archivos.
3. Servidores de aplicaciones
El desafío más importante de la organización en contenedores es cambiar los servidores de aplicaciones. Los servidores de aplicaciones tradicionales compatibles con Java EE asumen un entorno informático estático, por lo que es posible que no sean adecuados para ejecutarse en un entorno de contenedores. Es decir, se supone que los servidores físicos o virtuales son la entidad del entorno informático de las aplicaciones Java EE. Por ejemplo, los servidores de aplicaciones Java EE patentados, como el IBM WebSphere Application Server (TWAs) tradicional y el Oracle WebLogic Server, tienen su propio mecanismo de despliegue de aplicaciones.
La situación es diferente en un entorno de contenedores. En este entorno, los contenedores incluyen un servidor de aplicaciones y un tiempo de ejecución con paquetes de compilación de aplicaciones (por ejemplo, archivos .war y .jar) y se implementan en plataformas de contenedores como Amazon ECS o Amazon EKS. Recomendamos utilizar un mecanismo de plataforma de contenedores para implementar las aplicaciones en los entornos. Los servidores de aplicaciones generalmente se implementan con contenedores, por lo que deben ser de tamaño pequeño (menos de 500 MB) y de inicio rápido. Para cumplir con este requisito, es posible que deba cambiar el servidor de aplicaciones tradicional y migrar a un servidor de aplicaciones más compatible con los contenedores. Esto podría requerir una migración de IBM WebSphere Application Server a IBM WebSphere Liberty o JBoss Enterprise Application Platform (EAP) a. WildFly
Recomendamos tener en cuenta los siguientes efectos que pueden producirse al cambiar un servidor de aplicaciones:
-
Inyección de la configuración a través de variables de entorno (a diferencia de las aplicaciones Java EE tradicionales que almacenan las configuraciones en un archivo, como web.xml)
-
Compatibilidad con las capacidades de Java EE
-
Versiones de JVM
4. Almacén de archivos
El almacén de archivos más utilizado para las aplicaciones Java EE tradicionales es el sistema de archivos local. Los casos de uso más comunes incluyen los archivos de registro de aplicaciones, los archivos generados por la aplicación, como los informes empresariales, y los contenidos subidos por los usuarios. Recomendamos evitar almacenar los archivos dentro del contenedor, ya que los contenedores no tienen estado, lo cual significa que los almacenes de archivos deben externalizarse para su organización en contenedores.
Tenga en cuenta las siguientes opciones de organización en contenedores:
-
Amazon Elastic File System (Amazon EFS): Amazon EFS es un servicio NFS administrado al que se puede acceder desde contenedores. Amazon EFS está integrado con Amazon ECS y Amazon EKS. Si utiliza Amazon EFS, no necesita escribir scripts personalizados para montar los volúmenes de EFS en los contenedores. El primer paso de esta opción consiste en enumerar todas las rutas del sistema de archivos de la aplicación que se utilizan para leer o escribir. Tras identificar la ruta del sistema de archivos que se debe conservar, puede asignar la ruta del sistema de archivos a una ruta del sistema de archivos de EFS. Para obtener más información, consulte Tutorial: Utilización de sistemas de archivos de Amazon EFS en Amazon ECS en la documentación de Amazon ECS. No es necesario conservar todas las rutas, especialmente los archivos de registro de las aplicaciones. La mayoría de las aplicaciones empresariales escriben archivos de registro en un sistema de archivos local. Como parte del proceso de organización en contenedores, recomendamos considerar cambiar el destino del registro para utilizar Standard Out y Standard Error. Esto le permite capturar todos los resultados en los CloudWatch registros sin tener que gestionar el tamaño y el rendimiento del almacenamiento de registros. Para obtener más información sobre el inicio de sesión en Amazon ECS, consulte Uso del controlador de registros awslogs en la documentación de Amazon ECS.
-
Amazon Simple Storage Service (Amazon S3): Amazon S3 es más económico que Amazon EFS y admite un ancho de banda mayor que Amazon EFS, pero Amazon S3 requiere un cambio de código de aplicación más amplio que Amazon EFS. Esto se debe a que Amazon S3 no es un sistema de archivos.
5. Proceso de creación e implementación
El proceso de organización en contenedores implica cambiar y ampliar el proceso de entrega de las aplicaciones. En los entornos tradicionales, el proceso de entrega de aplicaciones incluye principalmente artefactos de Java (por ejemplo, archivos .war y .ear). En un entorno de contenedores, la imagen del contenedor es la unidad de entrega. Además del proceso de creación de los artefactos de Java existentes, debe crear un proceso para crear y entregar contenedores de Docker. Para obtener más información sobre el proceso de canalización, consulte Crear e implementar automáticamente una aplicación Java en Amazon EKS mediante una CI/CD canalización en la documentación de la Guía AWS prescriptiva.
6. Acceso a la base de datos
La organización en contenedores de aplicaciones tradicionales suele ir acompañada de la migración de bases de datos. Para reducir el riesgo de migración, recomendamos seguir la estrategia de migración para bases de datos relacionales (guíaAWS prescriptiva). Los entornos en contenedores requieren una configuración externalizada, incluidas las cadenas de conexión de bases de datos. Puede utilizar herramientas como Spring Cloud Config
