Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Paso 1: identificación de los casos de uso y el modelo de datos lógico
Una empresa automotriz desea crear un sistema de administración de componentes transaccional para almacenar y buscar todas las piezas de automóviles disponibles y establecer relaciones entre los distintos componentes y piezas. Por ejemplo, un automóvil contiene varias baterías, cada batería contiene varios módulos de alto nivel, cada módulo contiene varias celdas y cada celda contiene varios componentes de bajo nivel.
Por lo general, para crear un modelo de relación jerárquica, utilizar una base de datos de gráficos como Amazon Neptune es una mejor opción. Sin embargo, en algunos casos, Amazon DynamoDB es una mejor opción para el modelado jerárquico de datos debido a su flexibilidad, seguridad, rendimiento y escalabilidad.
Por ejemplo, puede crear un sistema en el que entre el 80 y el 90 por ciento de las consultas sean transaccionales, en el que DynamoDB se adapta bien. En este ejemplo, entre el 10 y el 20 por ciento restante de las consultas son relacionales, donde una base de datos de gráficos como Neptuno se adapta mejor. En este caso, incluir una base de datos adicional en la arquitectura para atender solo entre un 10 y un 20 por ciento de las consultas podría aumentar el costo. También añade la carga operativa que implica el mantenimiento de varios sistemas y la sincronización de los datos. En su lugar, puede modelar ese 10 o 20 por ciento de consultas relacionales en DynamoDB.
Crear un diagrama de un árbol de ejemplo para los componentes de un automóvil puede ayudarlo a trazar la relación entre ellos. El siguiente diagrama muestra un gráfico de dependencia con cuatro niveles. CM1 es el componente de nivel superior del propio coche de ejemplo. Tiene dos subcomponentes para dos baterías, por ejemplo, y CM2 . CM3 Cada batería tiene dos subcomponentes, que son los módulos. CM2 tiene módulos CM4 y CM5, y CM3 tiene módulos CM6 y CM7. Cada módulo tiene varios subcomponentes, que son las celdas. El CM4 módulo tiene dos celdas, CM8 y CM9. CM5 tiene una celda, CM10. CM6 y aún CM7 no tiene ninguna celda asociada.
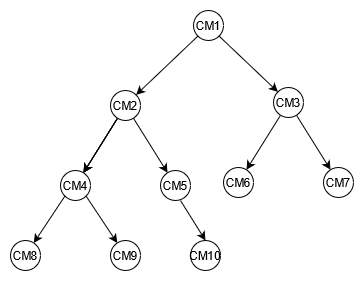
En esta guía, se utilizará este árbol y los identificadores de sus componentes como referencia. Un componente superior se denominará principal y un subcomponente se denominará secundario. Por ejemplo, el componente superior CM1 es el padre de CM2 y CM3. CM2 es el padre de CM4 y CM5. Esto representa de forma gráfica las relaciones entre principales y secundarios.
En el árbol, puede ver el gráfico de dependencia completo de un componente. Por ejemplo, CM8 depende de CM4, cuál depende de CM2, cuál depende de CM1. El árbol define el gráfico de dependencia completo como la ruta. Una ruta describe dos cosas:
-
La gráfica de dependencia
-
La posición en el árbol
Rellenar las plantillas para los requisitos empresariales:
Facilite información sobre sus usuarios:
Servicio |
Descripción |
Empleado |
Empleado interno de la empresa automotriz que necesita información sobre los automóviles y sus componentes |
Facilite información sobre las fuentes de datos y sobre cómo se van a ingerir los datos:
Origen |
Descripción |
Servicio |
Sistema de gestión |
Sistema que almacenará todos los datos relacionados con las piezas de automóviles disponibles y sus relaciones con otros componentes y piezas. |
Empleado |
Facilite información sobre cómo se consumirán los datos:
Consumidor |
Descripción |
Servicio |
Sistema de gestión |
Recuperación todos los componentes secundarios inmediatos de un ID de componente principal. |
Empleado |
Sistema de gestión |
Recuperación de una lista recursiva de todos los componentes secundarios de un ID de componente. |
Empleado |
Sistema de gestión |
Ver los antecesores de un componente. |
Empleado |
