Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Patrón de dispersión y recopilación
Intención
El patrón de dispersión y recopilación es un patrón de enrutamiento de mensajes que implica transmitir solicitudes similares o relacionadas a varios destinatarios y volver a agrupar sus respuestas en un solo mensaje mediante un componente denominado agregador. Este patrón ayuda a lograr la paralelización, reduce la latencia del procesamiento y gestiona la comunicación asincrónica. Es sencillo implementar el patrón de dispersión y recolección mediante un enfoque sincrónico, pero un enfoque más eficaz implica implementarlo como enrutamiento de mensajes en la comunicación asincrónica, con un servicio de mensajería o sin este.
Motivación
En el procesamiento de solicitudes, una solicitud que puede tardar mucho tiempo en procesarse de manera secuencial se puede dividir en varias solicitudes que se procesan en paralelo. También puede enviar solicitudes a varios sistemas externos mediante llamadas a la API para obtener una respuesta. El patrón de dispersión y recopilación es útil cuando se necesita información de varios orígenes. La dispersión y recopilación agregan los resultados para ayudar a tomar una decisión informada o a seleccionar la mejor respuesta para la solicitud.
El patrón de dispersión y recopilación consta de dos fases, como su nombre lo indica:
-
La fase de dispersión procesa el mensaje de la solicitud y lo envía a varios destinatarios en paralelo. Durante esta fase, la aplicación dispersa las solicitudes por la red y continúa ejecutándose sin esperar respuestas inmediatas.
-
Durante la fase de recopilación, la aplicación recopila las respuestas de los destinatarios y las filtra o combina en una respuesta unificada. Una vez recopiladas todas las respuestas, se pueden agregar en una sola respuesta o se puede elegir la mejor para su procesamiento posterior.
Aplicabilidad
Utilice el patrón de dispersión y recopilación cuando suceda lo siguiente:
-
Planea agregar y consolidar datos de varios APIs para crear una respuesta precisa. El patrón consolida la información de orígenes dispares en un todo cohesivo. Por ejemplo, un sistema de reservas puede hacer una solicitud a varios destinatarios para obtener cotizaciones de varios socios externos.
-
La misma solicitud se debe enviar a varios destinatarios de manera simultánea para completar una transacción. Así, por ejemplo, puede utilizar este patrón para consultar los datos del inventario en paralelo para verificar la disponibilidad de un producto.
-
Desea implementar un sistema fiable y escalable en el que se pueda lograr el equilibrio de cargas mediante la distribución de las solicitudes entre varios destinatarios. Si se produce un error en un destinatario o este tiene una carga alta, los demás destinatarios pueden seguir procesando las solicitudes.
-
Desea optimizar el rendimiento al implementar consultas complejas que impliquen varios orígenes de datos. Puede dispersar la consulta en las bases de datos correspondientes, recopilar los resultados parciales y combinarlos en una respuesta completa.
-
Está implementando un tipo de procesamiento map-reduce en el que la solicitud de datos se enruta a varios puntos de conexión de procesamiento de datos para su partición y replicación. Los resultados parciales se filtran y combinan para crear la respuesta correcta.
-
Desea distribuir las operaciones de escritura en un espacio de claves de partición en las cargas de trabajo de escritura intensiva en bases de datos de clave-valor. El agregador lee los resultados: Para ello, consulta los datos de cada partición y, a continuación, los consolida en una sola respuesta.
Problemas y consideraciones
-
Tolerancia a errores: este patrón se basa en varios receptores que funcionan en paralelo, por lo que es esencial gestionar los errores de manera adecuada. Para mitigar el impacto de los errores de los destinatarios en todo el sistema, puede implementar estrategias como la redundancia, la replicación y la detección de errores.
-
Límites de escalado horizontal: a medida que aumenta el número total de nodos de procesamiento, también aumenta la sobrecarga de red asociada. Cada solicitud que implique la comunicación a través de la red puede aumentar la latencia y afectar de manera negativa a las ventajas de la paralelización.
-
Obstáculos en el tiempo de respuesta: en el caso de las operaciones para las que es necesario que se procesen todos los destinatarios antes de completar el procesamiento final, el rendimiento del sistema en general se ve limitado por el tiempo de respuesta del destinatario más lento.
-
Respuestas parciales: cuando las solicitudes se distribuyen entre varios destinatarios, es posible que se agote el tiempo de espera de algunos destinatarios. En estos casos, la implementación debe comunicar al cliente que la respuesta está incompleta. También puede mostrar los detalles de agregación de respuestas mediante una interfaz de usuario de frontend.
-
Coherencia de datos: cuando procese datos de varios destinatarios, debe considerar con detenimiento las técnicas de sincronización de datos y resolución de conflictos para garantizar que los resultados agregados finales sean precisos y coherentes.
Implementación
Arquitectura de alto nivel
El patrón de dispersión y recopilación utiliza un controlador raíz para distribuir las solicitudes a los destinatarios que las procesarán. Durante la fase de dispersión, este patrón puede utilizar dos mecanismos para enviar mensajes a los destinatarios:
-
Dispersión por distribución: la aplicación tiene una lista conocida de destinatarios a los que hay que llamar para obtener los resultados. Los destinatarios pueden ser procesos distintos que tienen funciones únicas o un solo proceso que se escaló horizontalmente para distribuir la carga de procesamiento. Si alguno de los nodos de procesamiento agota el tiempo de espera o presenta demoras en la respuesta, el controlador puede redistribuir el procesamiento a otro nodo.
-
Dispersión por subasta: la aplicación difunde el mensaje a los destinatarios interesados mediante un patrón de publicación y suscripción. En este caso, los destinatarios pueden suscribirse al mensaje o anular la suscripción en cualquier momento.
Dispersión por distribución
En el método de dispersión por distribución, el controlador raíz divide la solicitud entrante en tareas independientes y las asigna a los destinatarios disponibles (la fase de dispersión). Cada destinatario (proceso, contenedor o función de Lambda) trabaja de manera independiente y paralela en su computación y produce una parte de la respuesta. Cuando los destinatarios finalizan sus tareas, envían sus respuestas a un agregador (la fase de recopilación). El agregador combina las respuestas parciales y devuelve el resultado final al cliente. En el diagrama siguiente se ilustra este flujo de trabajo.
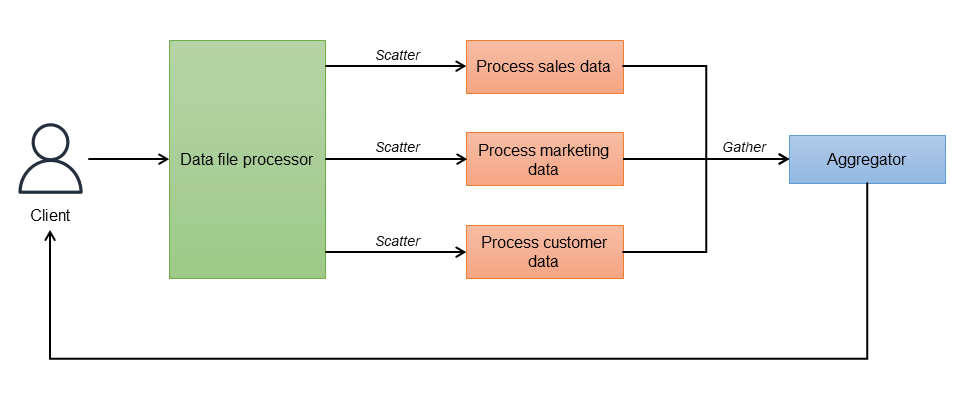
El controlador (procesador de archivos de datos) orquesta todo el conjunto de invocaciones y conoce todos los puntos de conexión de reserva a los que se debe llamar. Este puede configurar un parámetro de tiempo de espera para ignorar las respuestas que tardan demasiado. Una vez enviadas las solicitudes, el agregador espera a que lleguen las respuestas de cada punto de conexión. Para implementar la resiliencia, cada microservicio se puede implementar con varias instancias para equilibrar la carga. El agregador obtiene los resultados, los combina en un solo mensaje de respuesta y elimina los datos duplicados antes de continuar con su procesamiento. Se ignoran las respuestas que superan el tiempo de espera. El controlador también puede actuar como un agregador en lugar de utilizar un servicio de agregación independiente.
Dispersión por subasta
Si el controlador no sabe cuáles son los destinatarios o si los destinatarios están acoplados de manera débil, puede utilizar el método de dispersión por subasta. En este método, los destinatarios se suscriben a un tema y el controlador publica la solicitud en dicho tema. Los destinatarios publican los resultados en una cola de respuestas. Como el controlador raíz no conoce a los destinatarios, el proceso de recopilación utiliza un agregador (otro patrón de mensajería) para recopilar las respuestas y resumirlas en un solo mensaje de respuesta. El agregador utiliza un id. exclusivo para identificar un grupo de solicitudes.
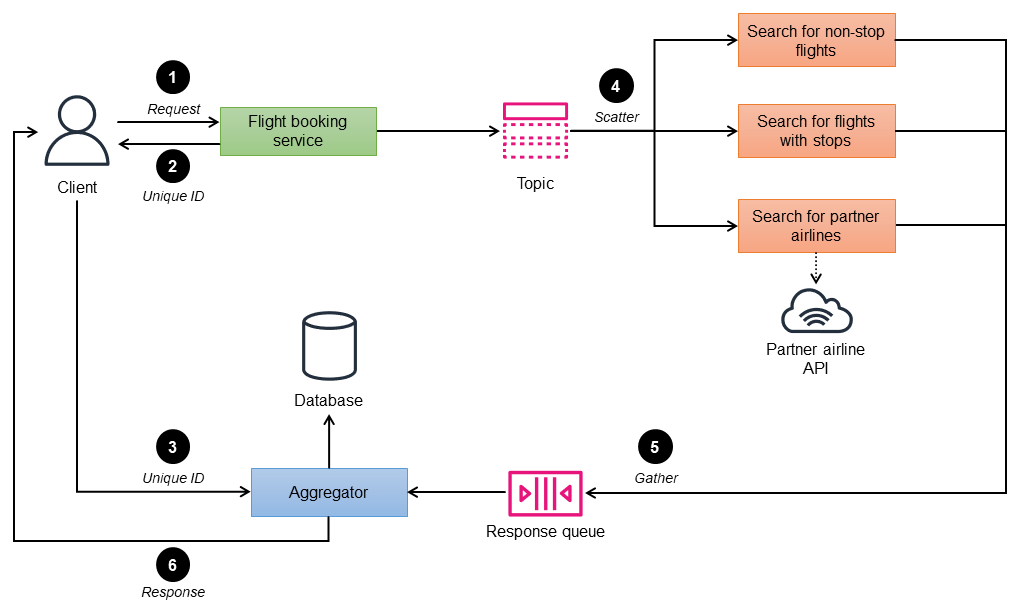
Así, por ejemplo, en el diagrama siguiente, el método de dispersión por subasta se utiliza para implementar un servicio de reserva de vuelos para el sitio web de una aerolínea. El sitio web permite a los usuarios buscar y mostrar los vuelos de la propia aerolínea y de las empresas asociadas. Además, debe mostrar el estado de la búsqueda en tiempo real. El servicio de reservas de vuelos consta de tres microservicios de búsqueda: vuelos sin escalas, vuelos con escalas y aerolíneas asociadas. La búsqueda de aerolíneas asociadas llama a los puntos de conexión de la API del socio para obtener las respuestas.
-
El servicio de reserva de vuelos (controlador) toma los criterios de búsqueda como datos del cliente y procesa y publica la solicitud relacionada con el tema.
-
El controlador utiliza un id. exclusivo para identificar cada grupo de solicitudes.
-
El cliente envía el id. exclusivo al agregador para el paso 6.
-
Los microservicios de búsqueda de reservas que se suscribieron al tema de reserva reciben la solicitud.
-
Los microservicios procesan la solicitud y devuelven la disponibilidad de asientos a una cola de respuesta según los criterios de búsqueda indicados.
-
El agregador recopila todos los mensajes de respuesta almacenados en una base de datos temporal, agrupa los vuelos por un id. exclusivo, crea una sola respuesta unificada y la devuelve al cliente.
Implementación mediante Servicios de AWS
Dispersión por distribución
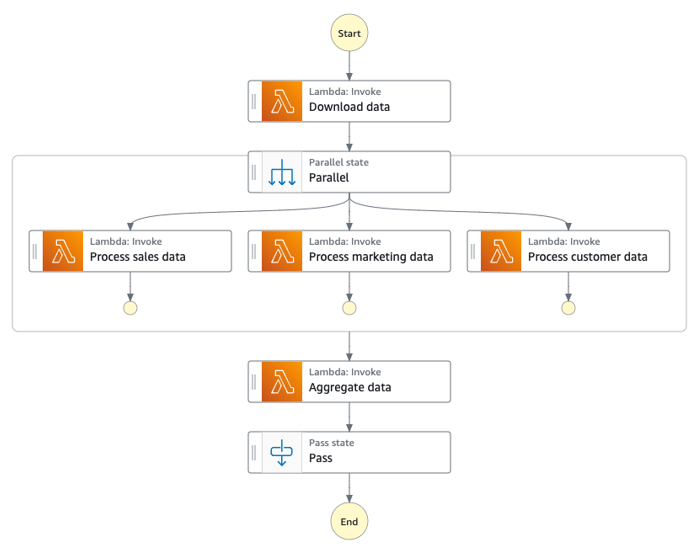
En la siguiente arquitectura, el controlador raíz es un procesador de archivos de datos (Amazon ECS) que divide los datos de las solicitudes entrantes en depósitos individuales de Amazon Simple Storage Service (Amazon S3) e inicia un flujo de trabajo. AWS Step Functions El flujo de trabajo descarga los datos e inicia el procesamiento de los archivos en paralelo. El estado Parallel espera a que todas las tareas devuelvan una respuesta. Una AWS Lambda función agrega los datos y los guarda en Amazon S3.
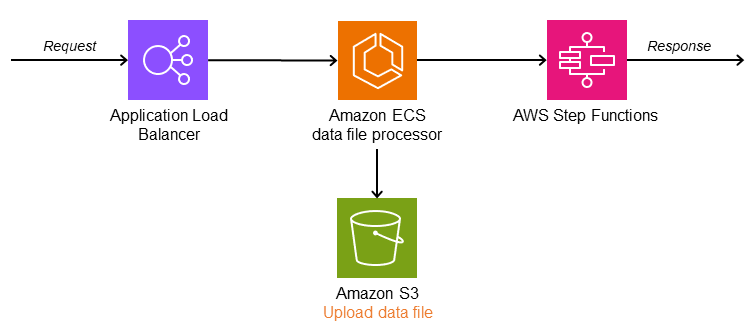
En el diagrama siguiente se ilustra el flujo de trabajo de Step Functions con el estado Parallel.
Dispersión por subasta
El siguiente diagrama muestra una AWS arquitectura para el método de dispersión por subasta. El servicio de reserva de vuelos del controlador raíz dispersa la solicitud de búsqueda de vuelos en varios microservicios. El canal de publicación y suscripción se implementa con Amazon Simple Notification Service (Amazon SNS), que es un servicio de mensajería administrado para las comunicaciones. Amazon SNS admite mensajes entre aplicaciones de microservicios desacopladas o comunicaciones directas con los usuarios. Puede implementar los microservicios del destinatario en Amazon Elastic Kubernetes Service (Amazon EKS) o Amazon Elastic Container Service (Amazon ECS) para mejorar la administración y escalabilidad. El servicio de resultados de vuelos devuelve los resultados al cliente. Se puede implementar en AWS Lambda u otros servicios de organización de contenedores, como Amazon ECS o Amazon EKS.
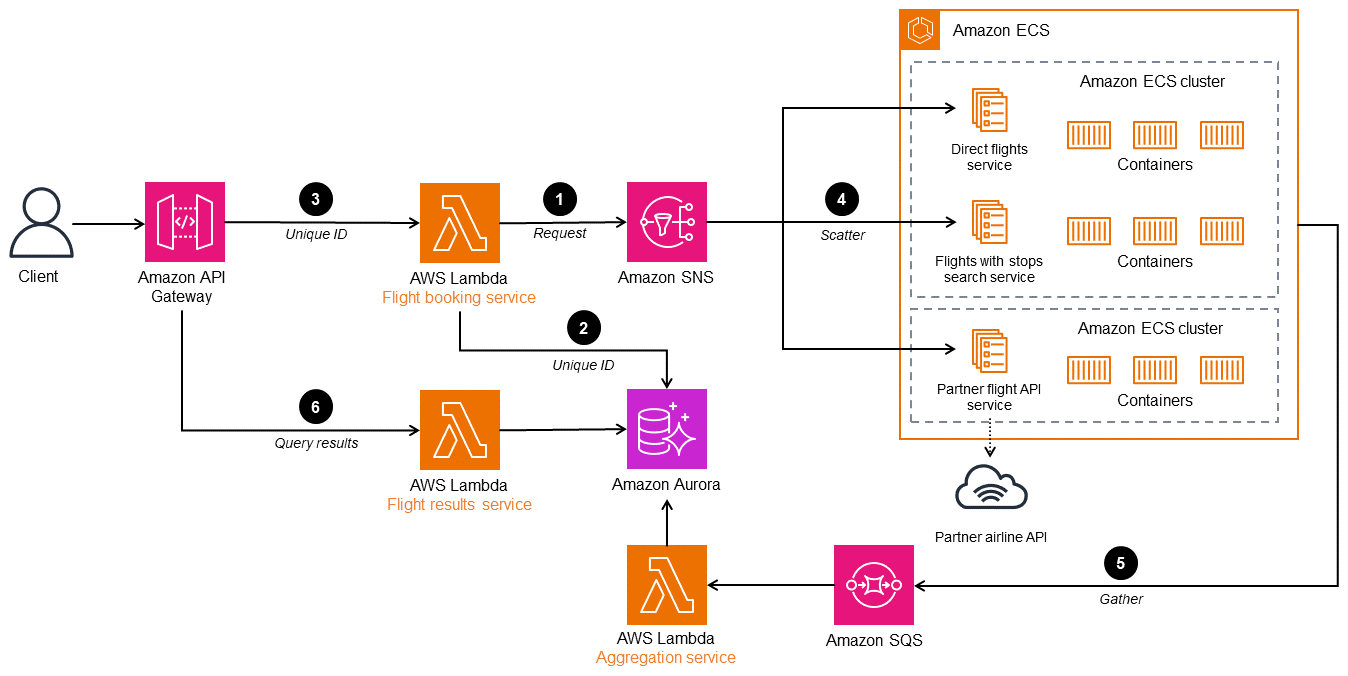
-
El servicio de reserva de vuelos (controlador) toma los criterios de búsqueda como datos del cliente y procesa y publica la solicitud relacionada con el tema de SNS.
-
El controlador publica el id. exclusivo en una base de datos de Amazon Aurora para identificar la solicitud.
-
El cliente envía el id. exclusivo al cliente para el paso 6.
-
Los microservicios de búsqueda de reservas que se suscribieron al tema de reserva reciben la solicitud.
-
Los microservicios procesan la solicitud y devuelven la disponibilidad de asientos a una cola de respuestas en Amazon Simple Queue Service (Amazon SQS) según los criterios de búsqueda indicados. El agregador recopila todos los mensajes de respuesta y los almacena en una base de datos temporal.
-
El servicio de resultados de vuelos agrupa los vuelos por un id. exclusivo, crea una sola respuesta unificada y la envía al cliente.
Si quiere agregar otra búsqueda de aerolíneas a esta arquitectura, agregue un microservicio que se suscriba al tema de SNS y lo publique en la cola de SQS.
En resumen, el patrón de dispersión y recopilación permite a los sistemas distribuidos lograr una paralelización eficiente, reducir la latencia y gestionar sin problemas la comunicación asincrónica.
GitHub repositorio
Para obtener una implementación completa de la arquitectura de ejemplo para este patrón, consulte el GitHub repositorio en https://github.com/aws-samples/asynchronous-messaging-workshop/tree/master/code/lab-3
Taller
-
Scatter-gather lab
en el taller Decoupled Microservices
Referencias de blogs
Contenido relacionado
-
Publish-subscribe pattern
