Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Exportación de datos mediante AWS Glue
Puede archivar los datos de MySQL en Amazon S3 mediante AWS Glue, que es un servicio analítico sin servidor en los casos de macrodatos. AWS Glue funciona con Apache Spark, un marco de computación en clústeres distribuido muy utilizado que admite muchos orígenes de bases de datos.
La descarga de los datos archivados de la base de datos a Amazon S3 se puede hacer con unas pocas líneas de código en un trabajo de AWS Glue. La mayor ventaja que ofrece AWS Glue es la escalabilidad horizontal y un pay-as-you-go modelo, que proporciona eficiencia operativa y optimización de costos.
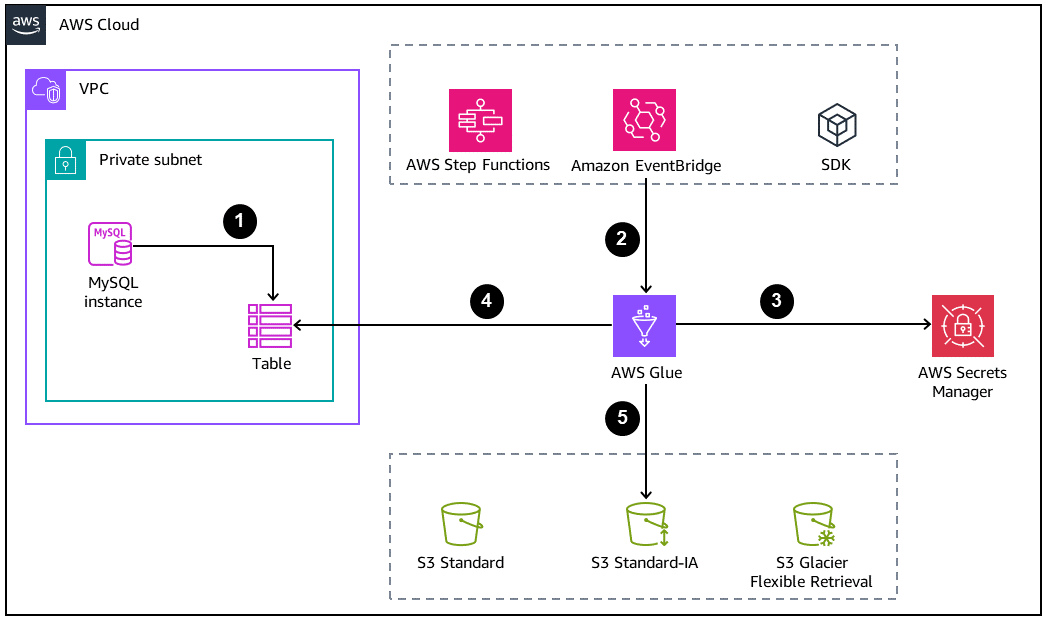
En el diagrama siguiente se muestra una arquitectura básica para archivar bases de datos.
-
La base de datos de MySQL crea el archivo o la tabla de respaldo que se descargará en Amazon S3.
-
Un trabajo de AWS Glue se inicia mediante alguna de los enfoques siguientes:
-
De manera sincrónica como un paso en una máquina de estados de AWS Step Functions
-
A través de una solicitud manual mediante la AWS CLI o un AWS SDK
-
-
Las credenciales de bases de datos se obtienen de AWS Secrets Manager.
-
El trabajo de AWS Glue utiliza una conexión de conectividad de bases de datos de Java (JDBC) para acceder a la base de datos y leer la tabla.
-
AWS Glue escribe los datos de Amazon S3 en formato Parquet, que es un formato de datos abierto, en columnas y que ahorra espacio.
Configuración del trabajo de AWS Glue
Para funcionar según lo previsto, el trabajo de AWS Glue requiere los componentes y configuraciones siguientes:
-
Conexiones de AWS Glue: se trata de un objeto del catálogo de datos de AWS Glue que se adjunta al trabajo para acceder a la base de datos. Un trabajo puede tener varias conexiones para hacer llamadas a varias bases de datos. Las conexiones contienen las credenciales de la base de datos almacenadas de forma segura.
-
GlueContext— Se trata de un contenedor personalizado sobre SparkContext
la GlueContext clase que proporciona operaciones de API de orden superior para interactuar con Amazon S3 y las fuentes de bases de datos. Permite la integración con Catálogo de datos. También elimina la necesidad de depender de los controladores para la conexión a la base de datos, que se gestiona en la conexión de Glue. Además, la GlueContext clase proporciona formas de gestionar las operaciones de la API de Amazon S3, lo que no es posible con la SparkContext clase original. -
Políticas y roles de IAM: dado que AWS Glue interactúa con otros servicios de AWS, debe configurar los roles adecuados con los privilegios mínimos necesarios. A continuación se muestran algunos de los servicios que requieren los permisos adecuados para interactuar con AWS Glue:
-
Amazon S3
-
AWS Secrets Manager
-
AWS Key Management Service (AWS KMS)
-
prácticas recomendadas
-
Para leer tablas enteras que tengan que descargar un gran número de filas, le recomendamos utilizar el punto de conexión de réplica de lectura para aumentar el rendimiento de la lectura sin degradar el rendimiento de la instancia de escritor principal.
-
Para lograr eficiencia en la cantidad de nodos que se utilizan para procesar el trabajo, active el escalado automático en AWS Glue 3.0.
-
Si el bucket de S3 forma parte de la arquitectura de un lago de datos, recomendamos descargar los datos: Para ello, organícelos en particiones físicas. El esquema de particiones debe basarse en los patrones de acceso. La partición según los valores de fecha es una de las prácticas más recomendadas.
-
Guardar los datos en formatos abiertos, como Parquet u Optimized Row Columnar (ORC), ayuda a que los datos estén disponibles para otros servicios analíticos, como Amazon Athena y Amazon Redshift.
-
Para que otros servicios distribuidos optimicen la lectura de los datos descargados, se debe controlar la cantidad de archivos de salida. Casi siempre es beneficioso tener un número menor de archivos grandes en lugar de un gran número de archivos pequeños. Spark cuenta con archivos de configuración y métodos integrados para controlar la generación de archivos parciales.
-
Los datos archivados, por definición, son conjuntos de datos a los que se accede con frecuencia. Para lograr la rentabilidad del almacenamiento, la clase de Amazon S3 debe pasar a niveles menos costosos. Existen dos métodos para hacerlo:
-
Transición sincrónica del nivel durante la descarga: si sabe de antemano que los datos descargados deben transferirse como parte del proceso, puede utilizar el GlueContext mecanismo transition_s3_path en el mismo trabajo de AWS Glue que escribe los datos en Amazon S3.
-
Transición asíncrona mediante el ciclo de vida de S3: configure las reglas del ciclo de vida de S3 con los parámetros adecuados para la transición y el vencimiento de las clases de almacenamiento de Amazon S3. Una vez que se configure en el bucket, persistirá de manera permanente.
-
-
Cree y configure una subred con un rango de direcciones IP suficiente
en la nube privada virtual (VPC) en la que se implementa la base de datos. Esto evitará errores en las tareas de AWS Glue causados por un número insuficiente de direcciones de red cuando se configura una gran cantidad de unidades de procesamiento de datos (DPUs).
