Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Migración in situ
La migración in situ elimina la necesidad de volver a escribir todos los archivos de datos. En su lugar, los archivos de metadatos de Iceberg se generan y se vinculan a los archivos de datos existentes. Este método suele ser más rápido y rentable, especialmente para conjuntos de datos o tablas de gran tamaño que tienen formatos de archivo compatibles, como Parquet, Avro y ORC.
nota
La migración in situ no se puede utilizar al migrar a Amazon S3 Tables.
Iceberg ofrece dos opciones principales para implementar la migración in situ:
-
Se utiliza el procedimiento de captura
de pantalla para crear una nueva tabla de Iceberg y, al mismo tiempo, mantener la tabla de origen sin cambios. Para obtener más información, consulte la tabla de instantáneas en la documentación de Iceberg. -
Uso del procedimiento de migración
para crear una nueva tabla de Iceberg como sustitución de la tabla de origen. Para obtener más información, consulte Migrate Table en la documentación de Iceberg. Aunque este procedimiento funciona con Hive Metastore (HMS), actualmente no es compatible con. AWS Glue Data Catalog El procedimiento de replicación de la tabla, que se describe más AWS Glue Data Catalog adelante en esta guía, proporciona una solución alternativa para lograr un resultado similar con el catálogo de datos.
Después de realizar la migración in situ mediante uno snapshot o varios archivos de datosmigrate, es posible que algunos archivos de datos permanezcan sin migrar. Esto suele ocurrir cuando los escritores siguen escribiendo en la tabla de origen durante o después de la migración. Para incorporar los archivos restantes a la tabla Iceberg, puede utilizar el procedimiento add_files
Supongamos que tiene una products tabla basada en Parquet que se creó y rellenó en Athena de la siguiente manera:
CREATE EXTERNAL TABLE mydb.products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; INSERT INTO mydb.products VALUES (1001, 'Smartphone', 'electronics'), (1002, 'Laptop', 'electronics'), (2001, 'T-Shirt', 'clothing'), (2002, 'Jeans', 'clothing');
En las siguientes secciones se explica cómo puede utilizar los migrate procedimientos snapshot y con esta tabla.
Opción 1: procedimiento de captura de pantalla
El snapshot procedimiento crea una nueva tabla Iceberg con un nombre diferente, pero que replica el esquema y la partición de la tabla de origen. Esta operación deja la tabla de origen completamente inalterada durante y después de la acción. De forma eficaz, crea una copia ligera de la tabla, que resulta especialmente útil para probar escenarios o explorar datos sin correr el riesgo de modificar la fuente de datos original. Este enfoque permite un período de transición en el que tanto la tabla original como la tabla Iceberg permanecen disponibles (consulte las notas al final de esta sección). Una vez finalizadas las pruebas, puede pasar la nueva mesa Iceberg a la de producción haciendo la transición de todos los grabadores y lectores a la nueva tabla.
Puede ejecutar el snapshot procedimiento mediante Spark en cualquier modelo de implementación de Amazon EMR (por ejemplo, Amazon EMR en EC2, Amazon EMR en EKS, EMR Serverless) y. AWS Glue
Para probar la migración in situ con el procedimiento de Spark, siga estos pasossnapshot:
-
Abre una aplicación de Spark y configura la sesión de Spark con los siguientes ajustes:
-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Ejecute el
snapshotprocedimiento para crear una nueva tabla de Iceberg que apunte a los archivos de datos de la tabla original:spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False)El marco de datos de salida contiene
imported_files_count(el número de archivos que se agregaron). -
Valide la nueva tabla consultándola:
spark.sql(f""" SELECT * FROM mydb.products_iceberg LIMIT 10 """ ).show(truncate=False)
Notas
-
Tras ejecutar el procedimiento, cualquier modificación del archivo de datos en la tabla de origen desincronizará la tabla generada. Los archivos nuevos que añada no estarán visibles en la tabla Iceberg y los archivos que elimine afectarán a las capacidades de consulta de la tabla Iceberg. Para evitar los problemas de sincronización:
-
Si la nueva tabla Iceberg está destinada a ser utilizada en producción, detenga todos los procesos que escriban en la tabla original y redirija los procesos a la nueva tabla.
-
Si necesita un período de transición o si la nueva tabla de Iceberg es para realizar pruebas, consulte Mantener sincronizadas las tablas de Iceberg tras una migración local, más adelante en esta sección, para obtener instrucciones sobre cómo mantener la sincronización de las tablas.
-
-
Al utilizar
snapshoteste procedimiento, lagc.enabledpropiedad se establecefalseen las propiedades de la tabla Iceberg creada. Esta configuración prohíbe acciones comoexpire_snapshotsremove_orphan_files, oDROP TABLEcon laPURGEopción, que eliminarían físicamente los archivos de datos. Las operaciones de eliminación o fusión tipo iceberg, que no afectan directamente a los archivos fuente, siguen estando permitidas. -
Para que su nueva tabla Iceberg sea completamente funcional, sin límites en cuanto a las acciones que eliminan físicamente los archivos de datos, puede cambiar la propiedad de la
gc.enabledtabla a.trueSin embargo, esta configuración permitirá realizar acciones que afecten a los archivos de datos de origen, lo que podría dañar el acceso a la tabla original. Por lo tanto, cambie lagc.enabledpropiedad solo si ya no necesita mantener la funcionalidad de la tabla original. Por ejemplo:spark.sql(f""" ALTER TABLE mydb.products_iceberg SET TBLPROPERTIES ('gc.enabled' = 'true'); """)
Opción 2: procedimiento de migración
El migrate procedimiento crea una nueva tabla Iceberg que tiene el mismo nombre, esquema y partición que la tabla de origen. Cuando se ejecuta este procedimiento, bloquea la tabla de origen y le cambia el nombre a <table_name>_BACKUP_ (o a un nombre personalizado especificado en el parámetro del backup_table_name procedimiento).
nota
Si establece el parámetro de drop_backup procedimiento entrue, la tabla original no se conservará como copia de seguridad.
En consecuencia, el procedimiento de la migrate tabla requiere que se detengan todas las modificaciones que afecten a la tabla de origen antes de realizar la acción. Antes de ejecutar el migrate procedimiento:
-
Detenga todos los grabadores que interactúen con la tabla fuente.
-
Modifique los lectores y escritores que no sean compatibles de forma nativa con Iceberg para habilitar la compatibilidad con Iceberg.
Por ejemplo:
-
Athena sigue trabajando sin modificaciones.
-
Spark requiere:
-
Archivos Iceberg Java Archive (JAR) que se incluirán en la ruta de clases (consulte las secciones Cómo trabajar con Iceberg en Amazon EMR y Trabajar con Iceberg AWS Glue en las secciones anteriores de esta guía).
-
Las siguientes configuraciones del catálogo de sesiones de Spark (se utilizan
SparkSessionCatalogpara añadir compatibilidad con Iceberg y, al mismo tiempo, mantener las funcionalidades de catálogo integradas para tablas que no son de Iceberg):-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Tras ejecutar el procedimiento, puedes reiniciar las grabadoras con su nueva configuración de Iceberg.
Actualmente, el migrate procedimiento no es compatible con el AWS Glue Data Catalog, porque el catálogo de datos no admite la RENAME operación. Por lo tanto, le recomendamos que utilice este procedimiento únicamente cuando trabaje con Hive Metastore. Si utiliza el catálogo de datos, consulte la siguiente sección para ver un enfoque alternativo.
Puede ejecutar el migrate procedimiento en todos los modelos de implementación de Amazon EMR (Amazon EMR en EC2, Amazon EMR en EKS, EMR Serverless) y AWS Glue, pero requiere una conexión configurada a Hive Metastore. Amazon EMR en EC2 es la opción recomendada porque proporciona una configuración integrada de Hive Metastore, que minimiza la complejidad de la configuración.
Para probar la migración in situ con el procedimiento migrate Spark desde un clúster de Amazon EMR en EC2 configurado con Hive Metastore, siga estos pasos:
-
Inicie una aplicación de Spark y configure la sesión de Spark para usar la implementación del catálogo de Iceberg Hive. Por ejemplo, si utiliza la
pysparkCLI:pyspark --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive -
Cree una
productstabla en Hive Metastore. Esta es la tabla de origen, que ya existe en una migración típica.-
Cree la tabla Hive
productsexterna en Hive Metastore para que apunte a los datos existentes en Amazon S3:spark.sql(f""" CREATE EXTERNAL TABLE products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; """ ) -
Agregue las particiones existentes mediante el comando:
MSCK REPAIR TABLEspark.sql(f""" MSCK REPAIR TABLE products """ ) -
Confirme que la tabla contiene datos ejecutando una
SELECTconsulta:spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)Código de salida de ejemplo:

-
-
Utilice el procedimiento de Iceberg:
migratedf_res=spark.sql(f""" CALL system.migrate( table => 'default.products' ) """ ) df_res.show()El marco de datos de salida contiene
migrated_files_count(el número de archivos que se agregaron a la tabla Iceberg):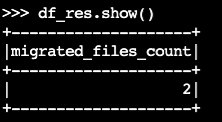
-
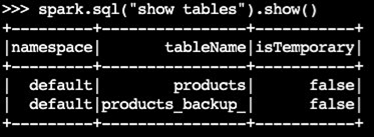
Confirme que se creó la tabla de respaldo:
spark.sql("show tables").show()Código de salida de ejemplo:
-
Valide la operación consultando la tabla de Iceberg:
spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)
Notas
-
Tras ejecutar el procedimiento, todos los procesos actuales que consultan o escriben en la tabla de origen se verán afectados si no están configurados correctamente con el soporte de Iceberg. Por lo tanto, le recomendamos que siga estos pasos:
-
Detenga todos los procesos utilizando la tabla de origen antes de la migración.
-
Realice la migración.
-
Reactive los procesos utilizando la configuración de Iceberg adecuada.
-
-
Si se producen modificaciones en los archivos de datos durante el proceso de migración (se añaden archivos nuevos o se eliminan archivos), la tabla generada no estará sincronizada. Para ver las opciones de sincronización, consulte Mantener sincronizadas las tablas de Iceberg tras una migración local más adelante en esta sección.
Replicar el procedimiento de migración de tablas en AWS Glue Data Catalog
Puede replicar el resultado del procedimiento de migración AWS Glue Data Catalog (haciendo una copia de seguridad de la tabla original y sustituyéndola por una tabla Iceberg) siguiendo estos pasos:
-
Utilice el procedimiento de captura de pantalla para crear una nueva tabla de iceberg que apunte a los archivos de datos de la tabla original.
-
Haga una copia de seguridad de los metadatos de la tabla original en el catálogo de datos:
-
Utilice la GetTableAPI para recuperar la definición de la tabla de origen.
-
Usa la GetPartitionsAPI para recuperar la definición de partición de la tabla fuente.
-
Utilice la CreateTableAPI para crear una tabla de respaldo en el catálogo de datos.
-
Utilice la BatchCreatePartitionAPI CreatePartitiono para registrar las particiones en la tabla de respaldo del catálogo de datos.
-
-
Cambie la propiedad de la tabla
gc.enabledIcebergfalsea para habilitar todas las operaciones de la tabla. -
Elimine la tabla original.
-
Localice el archivo JSON de metadatos de la tabla Iceberg en la carpeta de metadatos de la ubicación raíz de la tabla.
-
Registre la nueva tabla en el catálogo de datos mediante el procedimiento register_table
con el nombre de la tabla original y la ubicación del metadata.jsonarchivo que se creó mediante el procedimiento:snapshotspark.sql(f""" CALL system.register_table( table => 'mydb.products', metadata_file => '{iceberg_metadata_file}' ) """ ).show(truncate=False)
Mantener sincronizadas las tablas de Iceberg tras la migración in situ
El add_files procedimiento proporciona una forma flexible de incorporar los datos existentes en las tablas de Iceberg. En concreto, registra los archivos de datos existentes (como los archivos Parquet) haciendo referencia a sus rutas absolutas en la capa de metadatos de Iceberg. De forma predeterminada, el procedimiento agrega archivos de todas las particiones de tabla a una tabla de Iceberg, pero puede agregar archivos de particiones específicas de forma selectiva. Este enfoque selectivo es particularmente útil en varios escenarios:
-
Cuando se agregan nuevas particiones a la tabla de origen después de la migración inicial.
-
Cuando se agregan o eliminan archivos de datos de las particiones existentes después de la migración inicial. Sin embargo, si se vuelven a añadir particiones modificadas, primero se debe eliminar la partición. Más adelante en esta sección se proporciona más información al respecto.
Estas son algunas consideraciones para utilizar el add_file procedimiento después de realizar (snapshotomigrate) la migración in situ, a fin de mantener la nueva tabla de Iceberg sincronizada con los archivos de datos de origen:
-
Cuando se agreguen nuevos datos a las nuevas particiones de la tabla de origen, utilice el
add_filesprocedimiento con lapartition_filteropción de incorporar estas adiciones de forma selectiva en la tabla de Iceberg:spark.sql(f""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False)o bien:
spark.sql(f""" CALL system.add_files( source_table => '`parquet`.`s3://amzn-s3-demo-bucket/products/`', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False) -
El
add_filesprocedimiento busca archivos en toda la tabla de origen o en particiones específicas cuando se especifica lapartition_filteropción e intenta añadir todos los archivos que encuentre a la tabla de Iceberg. De forma predeterminada, la propiedad delcheck_duplicate_filesprocedimiento está establecida entrue, lo que impide que el procedimiento se ejecute si los archivos ya existen en la tabla Iceberg. Esto es importante porque no hay una opción integrada para omitir los archivos agregados anteriormente y, al deshabilitarlos, los archivos secheck_duplicate_filesañadirán dos veces, lo que generará duplicados. Cuando se agreguen nuevos archivos a la tabla de origen, siga estos pasos:-
Para particiones nuevas,
add_filesutilícelo conpartition_filtera para importar solo los archivos de la nueva partición. -
En el caso de las particiones existentes, elimine primero la partición de la tabla de Iceberg y, a continuación, vuelva a ejecutarla
add_filespara esa partición, especificando la.partition_filterPor ejemplo:# We initially perform in-place migration with snapshot spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False) # Then on the source table, some new files were generated under the category='electronics' partition. Example: spark.sql(""" INSERT INTO mydb.products VALUES (1003, 'Tablet', 'electronics') """) # We delete the modified partition from the Iceberg table. Note this is a metadata operation only spark.sql(""" DELETE FROM mydb.products_iceberg WHERE category = 'electronics' """) # We add_files from the modified partition spark.sql(""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ) """).show(truncate=False)
-
nota
Cada add_files operación genera una nueva instantánea de la tabla de Iceberg con datos adjuntos.
Elegir la estrategia de migración local adecuada
Para elegir la mejor estrategia de migración local, tenga en cuenta las preguntas de la siguiente tabla.
Pregunta |
Recomendación |
Explicación |
|---|---|---|
¿Desea realizar una migración rápida sin tener que volver a escribir los datos y, al mismo tiempo, mantener accesibles las tablas de Hive e Iceberg para realizar pruebas o realizar una transición gradual? |
|
Utilice el |
¿Utiliza Hive Metastore y desea reemplazar la tabla de Hive por una tabla de Iceberg inmediatamente, sin tener que volver a escribir los datos? |
|
Utilice Nota: Esta opción es compatible con Hive Metastore, pero no con. AWS Glue Data Catalog Utilice el |
¿Está utilizando la tabla Hive por una tabla Iceberg AWS Glue Data Catalog y desea sustituirla inmediatamente, sin tener que volver a escribir los datos? |
Adaptación del |
Replicar
Nota: Esta opción requiere la gestión manual de las llamadas a la AWS Glue API para la copia de seguridad de los metadatos. Utilice el |
