Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Lagos de datos modernos
Casos de uso avanzados en lagos de datos modernos
La evolución del almacenamiento de datos ha pasado de las bases de datos a los almacenes y lagos de datos, donde cada tecnología responde a requisitos empresariales y de datos únicos. Las bases de datos tradicionales se destacaban en el manejo de datos estructurados y cargas de trabajo transaccionales, pero se enfrentaban a desafíos de rendimiento a medida que aumentaban los volúmenes de datos. Los almacenes de datos surgieron para abordar los problemas de rendimiento y escalabilidad, pero al igual que las bases de datos, dependían de formatos patentados dentro de sistemas integrados verticalmente.
Los lagos de datos ofrecen una de las mejores opciones para almacenar datos en términos de costo, escalabilidad y flexibilidad. Puede utilizar un lago de datos para conservar grandes volúmenes de datos estructurados y no estructurados a un bajo coste y utilizar estos datos para distintos tipos de cargas de trabajo analíticas, desde la elaboración de informes de inteligencia empresarial hasta el procesamiento de macrodatos, la analítica en tiempo real, el aprendizaje automático y la inteligencia artificial generativa (IA), para ayudar a tomar mejores decisiones.
A pesar de estas ventajas, los lagos de datos no se diseñaron inicialmente con capacidades similares a las de las bases de datos. Un lago de datos no admite la semántica de procesamiento de atomicidad, coherencia, aislamiento y durabilidad (ACID), que podría necesitar para optimizar y administrar sus datos de manera eficaz a escala para cientos o miles de usuarios mediante el uso de muchas tecnologías diferentes. Los lagos de datos no ofrecen soporte nativo para las siguientes funciones:
-
Realizar actualizaciones y eliminaciones eficientes a nivel de registros a medida que los datos cambian en su empresa
-
Gestione el rendimiento de las consultas a medida que las tablas crecen hasta convertirse en millones de archivos y cientos de miles de particiones
-
Garantizar la coherencia de los datos entre varios escritores y lectores simultáneos
-
Prevenir la corrupción de los datos cuando las operaciones de escritura fallan a mitad de la operación
-
Los esquemas de tablas evolucionan a lo largo del tiempo sin reescribir (parcialmente) los conjuntos de datos
Estos desafíos se han vuelto particularmente frecuentes en casos de uso, como la gestión de la captura de datos modificados (CDC) o los casos de uso relacionados con la privacidad, la eliminación de datos y la ingesta de datos en streaming, lo que puede dar lugar a que las tablas no sean óptimas.
Los lagos de datos que utilizan las tablas tradicionales con formato HIVE solo admiten operaciones de escritura para archivos completos. Esto hace que las actualizaciones y eliminaciones sean difíciles de implementar, además de llevar mucho tiempo y ser costosas. Además, los controles y garantías de simultaneidad que ofrecen los sistemas compatibles con ACID son necesarios para garantizar la integridad y la coherencia de los datos.
Estos desafíos dejan a los usuarios ante un dilema: elegir entre una plataforma totalmente integrada pero propia, u optar por un lago de datos autoconstruido y autónomo, independiente del proveedor, que requiera un mantenimiento y una migración constantes para aprovechar su valor potencial.
Introducción a Apache Iceberg
Apache Iceberg es un formato de tabla de código abierto que proporciona funciones en las tablas de lagos de datos que anteriormente solo estaban disponibles en bases de datos o almacenes de datos. Está diseñado para ofrecer escalabilidad y rendimiento, y es ideal para administrar tablas de más de cientos de gigabytes. Algunas de las principales características de las mesas Iceberg son:
-
Eliminar, actualizar y combinar.Iceberg admite comandos SQL estándar para el almacenamiento de datos para su uso con tablas de lagos de datos.
-
Planificación rápida del escaneo y filtrado avanzado. Iceberg almacena metadatos, como estadísticas a nivel de partición y columna, que los motores pueden utilizar para acelerar la planificación y la ejecución de las consultas.
-
Evolución completa del esquema. Iceberg permite añadir, eliminar, actualizar o cambiar el nombre de columnas sin efectos secundarios.
-
Evolución de particiones. Puede actualizar el diseño de particiones de una tabla a medida que cambien el volumen de datos o los patrones de consulta. Iceberg permite cambiar las columnas en las que se divide una tabla, así como añadir columnas o eliminar columnas de las particiones compuestas.
-
Particiones ocultas.Esta función evita la lectura automática de particiones innecesarias. Esto elimina la necesidad de que los usuarios entiendan los detalles de las particiones de la tabla o agreguen filtros adicionales a sus consultas.
-
Reversión de versiones. Los usuarios pueden corregir rápidamente los problemas volviendo al estado anterior a la transacción.
-
Viaje en el tiempo. Los usuarios pueden consultar una versión anterior específica de una tabla.
-
Aislamiento serializable. Los cambios en las tablas son atómicos, por lo que los lectores nunca ven cambios parciales o no confirmados.
-
Escritores simultáneos. Iceberg utiliza una simultaneidad optimista para permitir que varias transacciones tengan éxito. En caso de conflictos, uno de los redactores debe volver a intentar la transacción.
-
Formatos de archivo abiertos. Iceberg admite varios formatos de archivo de código abierto, incluidos Apache Parquet
, Apache Avro y Apache ORC.
En resumen, los lagos de datos que utilizan el formato Iceberg se benefician de la coherencia transaccional, la velocidad, la escala y la evolución del esquema. Para obtener más información sobre estas y otras funciones de Iceberg, consulte la documentación de Apache
AWS soporte para Apache Iceberg
Apache Iceberg es compatible Servicios de AWS con Amazon EMR
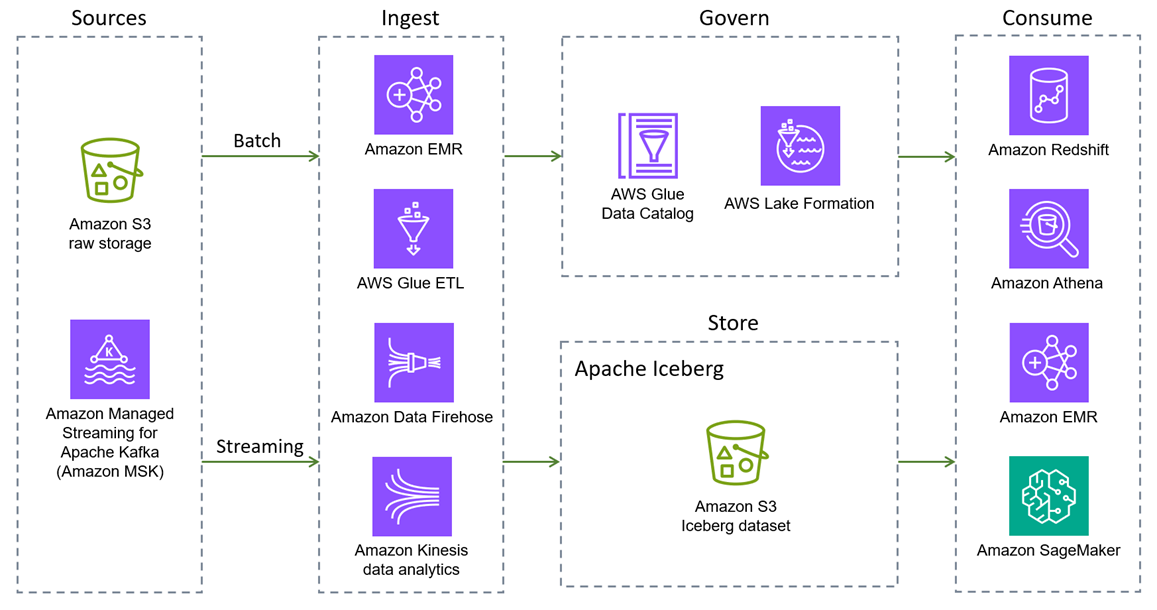
A continuación, se Servicios de AWS proporcionan integraciones nativas de Iceberg. Hay otras Servicios de AWS que pueden interactuar con Iceberg, ya sea de forma indirecta o empaquetando las bibliotecas de Iceberg.
-
Amazon S3 es el mejor lugar para crear lagos de datos debido a sus capacidades de durabilidad, disponibilidad, escalabilidad, seguridad, conformidad y auditoría. Iceberg se diseñó y creó para interactuar con Amazon S3 sin problemas y proporciona soporte para muchas de las funciones de Amazon S3, tal como se indica en la documentación de Iceberg
. Además, Amazon S3 Tables ofrece el primer almacén de objetos en la nube con soporte Iceberg integrado y agiliza el almacenamiento de datos tabulares a escala. Gracias a la compatibilidad con S3 Tables para Iceberg, puede consultar fácilmente sus datos tabulares mediante motores de consulta populares AWS y de terceros. -
La próxima generación de SageMaker
se basa en una arquitectura abierta que unifica el acceso a los datos en los lagos de datos de Amazon S3, los almacenes de datos de Amazon Redshift y las fuentes de datos federadas y de terceros. Estas capacidades le ayudan a crear AI/ML aplicaciones y análisis potentes en una sola copia de los datos. Lakehouse es totalmente compatible con Iceberg, por lo que tiene la flexibilidad de acceder a los datos y consultarlos in situ mediante la API REST de Iceberg. -
Amazon EMR es una solución de big data para el procesamiento de datos a escala de petabytes, el análisis interactivo y el aprendizaje automático que utiliza marcos de código abierto como Apache Spark, Flink, Trino y Hive. Amazon EMR puede ejecutarse en clústeres personalizados de Amazon Elastic Compute Cloud EC2 (Amazon), Amazon Elastic Kubernetes Service (Amazon EKS) AWS Outposts o Amazon EMR Serverless.
-
Amazon Athena es un servicio de análisis interactivo sin servidor que se basa en marcos de código abierto. Admite formatos de archivos y tablas abiertas y proporciona una forma simplificada y flexible de analizar petabytes de datos allí donde se encuentran. Athena proporciona soporte nativo para consultas de lectura, viaje en el tiempo, escritura y DDL para Iceberg y utiliza el AWS Glue Data Catalog metaalmacén de Iceberg.
-
Amazon Redshift es un almacén de datos en la nube a escala de petabytes que admite opciones de implementación basadas en clústeres y sin servidor. Amazon Redshift Spectrum puede consultar tablas externas que estén registradas y almacenadas en Amazon S3. AWS Glue Data Catalog Redshift Spectrum también admite el formato de almacenamiento Iceberg.
-
AWS Gluees un servicio de integración de datos sin servidor que facilita el descubrimiento, la preparación, el traslado y la integración de datos de múltiples fuentes para el análisis, el aprendizaje automático (ML) y el desarrollo de aplicaciones. Está totalmente integrado con Iceberg. En concreto, puede realizar operaciones de lectura y escritura en las tablas de Iceberg mediante AWS Glue tareas, gestionar las tablas a través de ellas AWS Glue Data Catalog(compatibles con la metatienda de Hive), detectar y registrar las tablas automáticamente mediante AWS Glue rastreadores y evaluar la calidad de los datos de las tablas de Iceberg mediante la función de calidad de los datos. AWS Glue AWS Glue Data Catalog También permite recopilar estadísticas de columnas, calcular y actualizar el número de valores distintos (NDVs) para cada columna de las tablas Iceberg y optimizaciones automáticas de las tablas (compactación, retención de instantáneas, eliminación de archivos huérfanos). AWS Glue también admite integraciones sin ETL a partir de listas y aplicaciones de terceros en tablas de Iceberg Servicios de AWS .
-
Amazon Data Firehose es un servicio totalmente gestionado para entregar datos de streaming en tiempo real a destinos como Amazon S3, Amazon Redshift, Amazon Service, OpenSearch Amazon Serverless, OpenSearch Splunk, tablas de Apache Iceberg y cualquier punto de enlace HTTP o HTTP personalizado propiedad de proveedores de servicios externos compatibles, incluidos Datadog, Dynatrace LogicMonitor, MongoDB, New Relic, Coralogix y Elastic. Con Firehose, no necesitas escribir aplicaciones ni administrar recursos. Configure los productores de datos para que envíen datos a Firehose y este entrega inmediatamente los datos al destino que usted especificó. También puede configurar Firehose para transformar los datos antes de entregarlos.
-
Amazon Managed Service for Apache Flink es un servicio de Amazon totalmente gestionado que te permite utilizar una aplicación Apache Flink para procesar datos de streaming. Soporta tanto la lectura como la escritura en tablas de Iceberg, y permite procesar y analizar datos en tiempo real.
-
Amazon SageMaker AI admite el almacenamiento de conjuntos de funciones en Amazon SageMaker AI Feature Store mediante el formato Iceberg.
-
AWS Lake Formationproporciona permisos de control de acceso básicos y detallados para acceder a los datos, incluidas las tablas Iceberg utilizadas por Athena o Amazon Redshift. Para obtener más información sobre el soporte de permisos para las tablas Iceberg, consulte la documentación de Lake Formation.
AWS cuenta con una amplia gama de servicios compatibles con Iceberg, pero cubrir todos estos servicios va más allá del alcance de esta guía. Las siguientes secciones tratan sobre Spark (streaming estructurado y por lotes) en Amazon EMR y AWS Glue Athena SQL. En la siguiente sección se ofrece un vistazo rápido al soporte de Iceberg en Athena SQL.
