Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Flujo de trabajo para evaluadores y ciclos de reflexión y refinamiento
Este flujo de trabajo proporciona un circuito de retroalimentación en el que un LLM genera un resultado y otro evalúa o critica el resultado. Esto promueve la autorreflexión, la optimización y las mejoras iterativas.
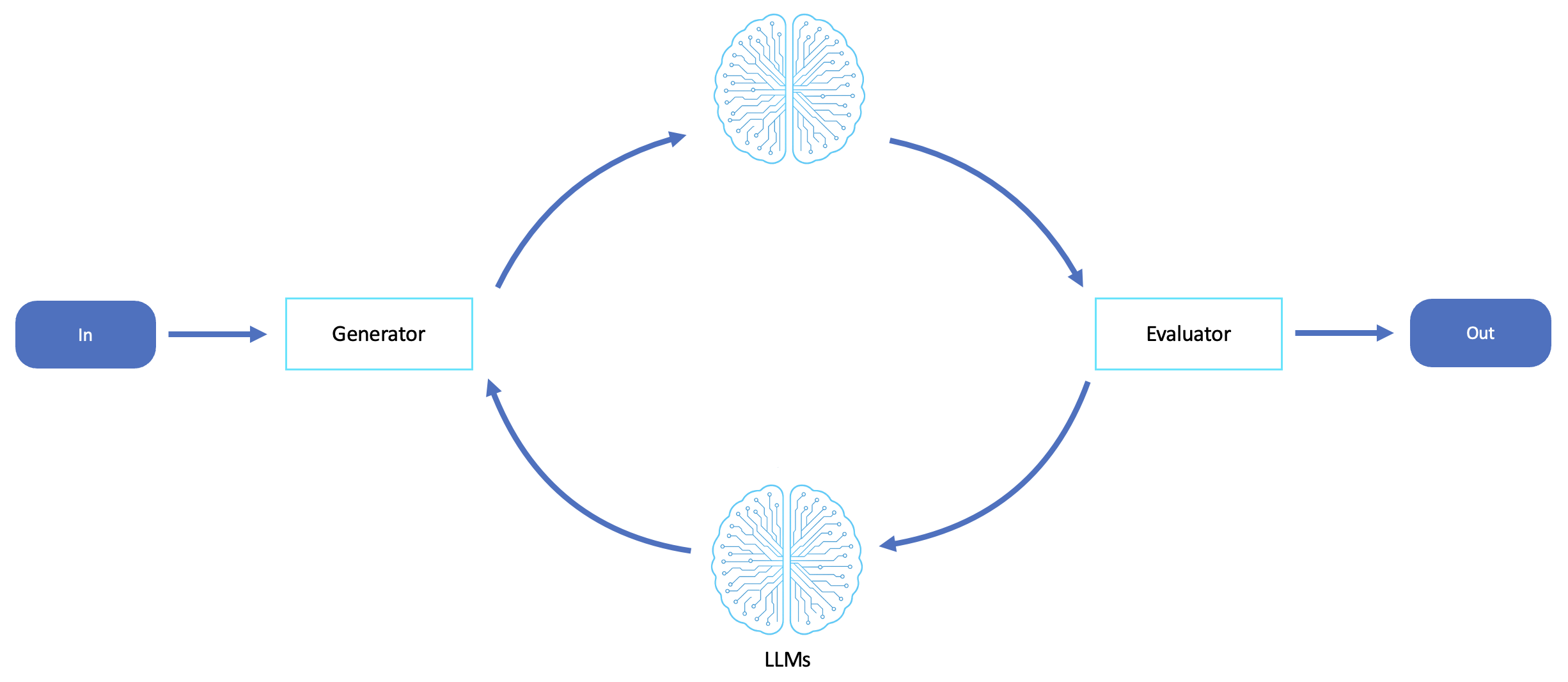
El flujo de trabajo del evaluador es ideal para escenarios en los que la calidad, la precisión y la alineación de los resultados son importantes y en los que la generación de una sola pasada no es fiable o insuficiente. Este flujo de trabajo destaca cuando los agentes deben autocriticarse, repetir y refinar sus resultados, ya sea para cumplir con un estándar más alto de corrección o para explorar alternativas mejoradas en función de los comentarios.
Este flujo de trabajo es particularmente eficaz cuando:
-
El resultado incluye métricas de calidad subjetivas (por ejemplo, estilo, tono y legibilidad) o criterios objetivos (por ejemplo, corrección, seguridad y rendimiento).
-
El agente debe razonar haciendo concesiones, evaluar las limitaciones u optimizar la búsqueda de una meta.
-
Necesita redundancia y garantía de calidad integradas, especialmente en los ámbitos regulados, orientados al cliente o creativos.
-
Human-in-the-loop la revisión es cara o no está disponible, y se desea una validación autónoma.
Este flujo de trabajo se utiliza para la generación de contenido, la síntesis y revisión del código, la aplicación de políticas, la comprobación de la alineación, el ajuste de las instrucciones y el posprocesamiento del RAG. También es útil para los agentes que se mejoran a sí mismos, ya que la retroalimentación continua ayuda a dar forma a mejores respuestas a lo largo del tiempo para crear ciclos de decisión autónomos y confiables.
Casos de uso comunes
-
Los agentes del equipo rojo se comparan con los del equipo azul
-
Agentes que generan, evalúan y revisan códigos o planes
-
Control de calidad, detección de alucinaciones y control del estilo
Capacidades
-
Soporta la generación y la evaluación disociadas utilizando diferentes modelos (por ejemplo, Claude para la generación y Mistral para la evaluación)
-
La retroalimentación está estructurada y se utiliza para generar resultados revisados
-
Soporta múltiples iteraciones o umbrales de convergencia
